K-Means

K-means算法的一些特性





K-Means++

Expectation Maximization(EM)
http://ai.stanford.edu/~chuongdo/papers/em_tutorial.pdf
https://zhuanlan.zhihu.com/p/57679630

- E-step: Compute a distributionon the labels of the points, using current parameters
- M-step:Update parameters using current guess of label distribution.






EM 与 Mixture of Gaussian






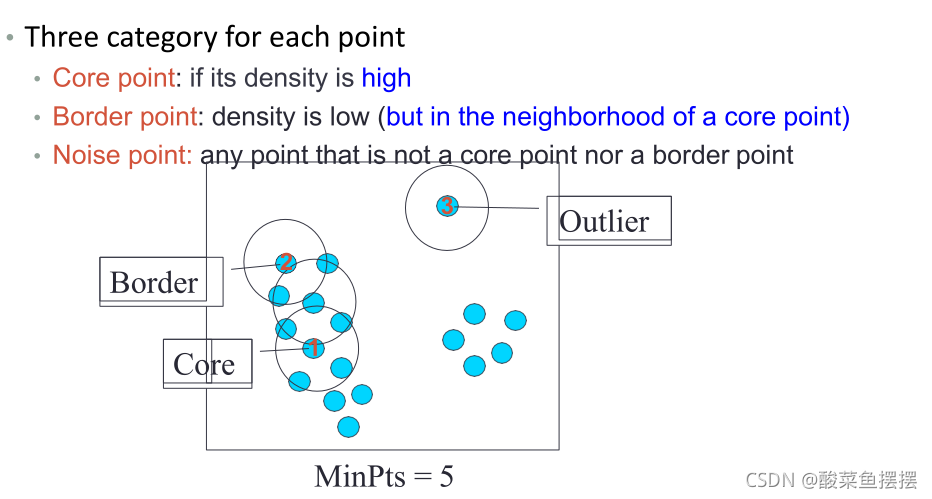
DBSCAN




总结优缺点
优点
- 1.相比K-Means,DBSCAN 不需要预先声明聚类数量。
- 2.DBSCAN 可以找出任何形状的聚类,甚至能找出一个聚类,它包围但不连接另一个聚类,另外,由于MinPts参数,single-link effect (不同聚类以一点或极弱的线相连而被当成一个聚类)能
有效地被避免。 - 3.DBSCAN 能分辨噪音(局外点)。
- 4.DBSCAN 只需两个参数,且对数据库内的点的次序几乎不敏感(两个聚类之间边缘的点有机会受次序的影响被分到不同的聚类,另外聚类的次序会受点的次序的影响)。
- 5.DBSCAN 被设计成能配合可加速范围访问的数据库结构。
- 6.如果对数据有足够的了解,可以选择适当的参数以获得最佳的分类。
缺点
- DBSCAN 不是完全决定性的:在两个聚类交界边缘的点会视乎它在数据库的次序决定加入哪个聚类,幸运地,这种情况并不常见,而且对整体的聚类结果影响不大――DBSCAN 对核心点和噪音都是决定性的。
- 2.DBSCAN 聚类分析的质量受函数regionQuery(P ,ε) 里所使用的度量影响,最常用的度量是欧几里得距离,尤其在高维度资料中,由于受所谓“维数灾难”影响,很难找出一个合适的ε ,但事实上所有使用欧几里得距离的算法都受维数灾难影响。
- 3.如果数据库里的点有不同的密度,而该差异很大,DBSCAN 将不能提供一个好的聚类结果,因为不能选择一个适用于所有聚类的minPts-ε 参数组合。
- 4.如果没有对资料和比例的足够理解,将很难选择适合的ε 参数
== 参考贪心科技机器学习高阶班==