����Ŀ¼
1 ����
Yoloϵ�е�ģ���Ǵ������Ŀ�����ͼ���㷨����ʦ����ʹ�õ�,ʹ��ʱ����Ҳ�������˿���Ч����˵,���Ч������,��ʱ���ٻ�ͷ���о�һ��ģ��,��ʱ���������˻ع�ͷ��ϸ������ƪ���¾���һ����ͷ�IJ��
Yolo��ÿһ��ϵ�ж����˾���,�����ۺ���ԭʼ���ĺ����ϸ��ҵ�һЩ˵��,��Yoloÿ��ϵ�о���������һЩʲô��һ��ϵͳ������,Ҳ�������Ժ���ٻ�ͷ��
���Yolo֮�����˼���������ȥ,����Ҳ�ᾡ�������������¡�
���е�ͼƬ�����Բο�����,�DZ���ԭ����
2 Yoloϵ��ģ��
2.1 ��ʯ - Yolov1
Yolov1��Ŀ������one-stage�����Ŀ�ɽ֮��,����ͬ��two-stage��Ҫ�ȹ�һ��RPN����õ���ѡ����ķ���,yoloֱ��������ͼ��feature map�Ͻ���Ŀ��Ķ�λ�ͷ���,����ٶ�Ҳ�ȵ�ʱ�����Fast R-CNN��ܶࡣ����,Ҳ������Ϊyolo������ȫ�ֵ���Ϣ,yolo�ѱ������г�Ŀ��Ĵ����ʱ�ֻ��proposals��Fast R-CNN�ͺܶ������������ȷ��,����Fast R-CNN�ߡ�
2.1.1 Yolov1������ṹ
Yolov1������ṹ����ͼ��ʾ,��������,������
448
��
448
��
3
448\times448\times3
448��448��3��ͼƬ,�����һ��
7
��
7
��
30
7\times7\times30
7��7��30��feature map�������й���24��ȫ������β����2��ȫ����,�����õ��˴�����
1
��
1
1\times1
1��1���������ı�ͨ����,��ȻҲ���ں�ͨ��֮����������������������õ�����ȫ������ʵ���쿴���е㲻��,����İ汾��û�����ˡ��������ṹ���Ǵ���������Darknet��
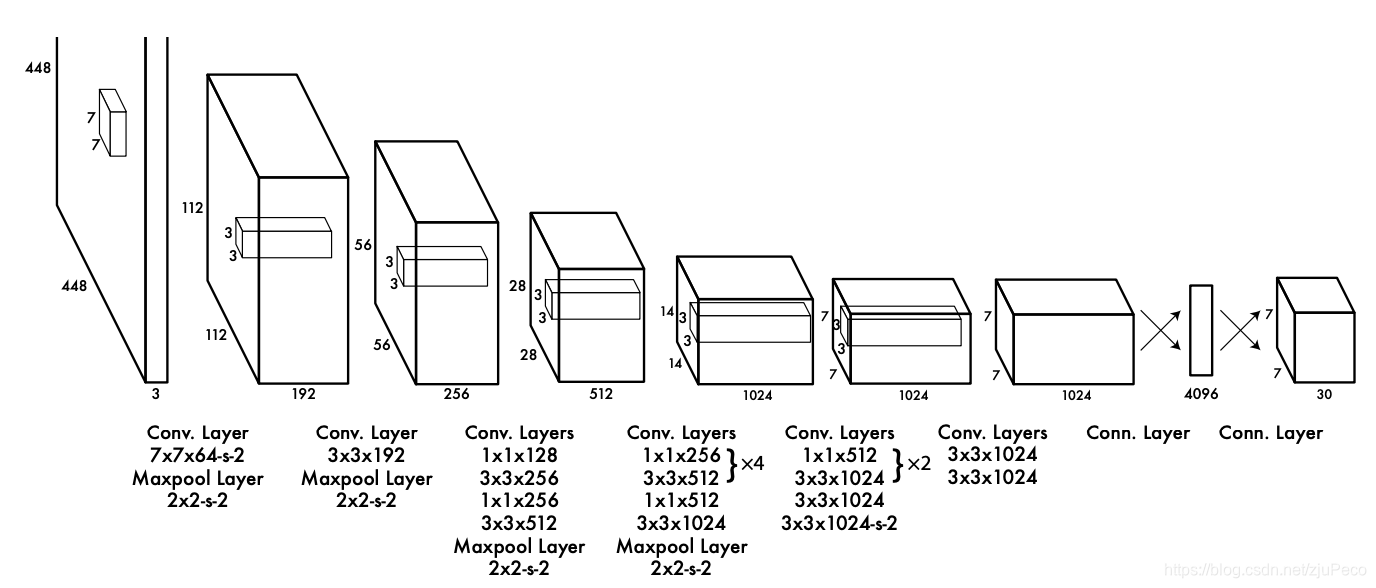
����ľ�������ImageNet���÷������������Ԥѵ��,ʹ�þ�������Գ鵽�ȽϺõ�ͼ������,����Ԥѵ��ʱ������ͼ��Ϊ 224 �� 224 224\times224 224��224��,����ʵ���е�����,��ѵ�����ģ��ʱ,����Ϊ 448 �� 448 448\times448 448��448,ģ����Ҫȥ��Ӧ���ֱַ��ʵ�ת��,�Խ������Ӱ���,�����֮��İ汾���Ż���
2.1.2 Yolov1��feature map
������������Yolov1����� 7 �� 7 �� 30 7\times7\times30 7��7��30��feature map,���� 7 �� 7 7\times7 7��7�Ǿ������ȫ������ȫ����֮���²����õ��Ľ��,ÿ��grid��Ӧ��ԭͼ����Ӧλ�õ�һ������,��������Ϊ�� 448 �� 448 448\times448 448��448�����볤�����ȷ�Ϊ��7��,����49��grids��
ÿ��grid����Ӧ��һ������Ϊ30������,ȷ��˵Ӧ����һ�� 2 �� 5 + 20 2\times5+20 2��5+20������,����2��ʾ2��Ԥ���;5��ʾÿ��Ԥ���� [ x c e n t e r , y c e n t e r , w , h , c o n f i d e n c e ] [x_{center}, y_{center}, w, h, confidence] [xcenter?,ycenter?,w,h,confidence], c o n f i d e n c e confidence confidenceָ�������Ԥ�����Ŀ������Ŷ� P r ( O b j e c t ) �� I O U p r e d t r u t h Pr(Object) \times IOU_{pred}^{truth} Pr(Object)��IOUpredtruth?,��û������ʱ, P r ( O b j e c t ) = 0 Pr(Object)=0 Pr(Object)=0, c o n f i d e n c e = 0 confidence=0 confidence=0,��������ʱ, c o n f i d e n c e = I O U p r e d t r u t h confidence=IOU_{pred}^{truth} confidence=IOUpredtruth?;20��ʾ20��Ŀ���������Ŷ�,��ʾΪ P r ( C l a s s i �O O b j e c t ) Pr(Class_i|Object) Pr(Classi?�OObject)��
��Ԥ��ʱ,����ij�����ڱ�ʾ��ij��Ŀ������Ŷ�Ϊ
c
o
n
f
i
d
e
n
c
e
��
P
r
(
C
l
a
s
s
i
�O
O
b
j
e
c
t
)
confidence \times Pr(Class_i|Object)
confidence��Pr(Classi?�OObject)��
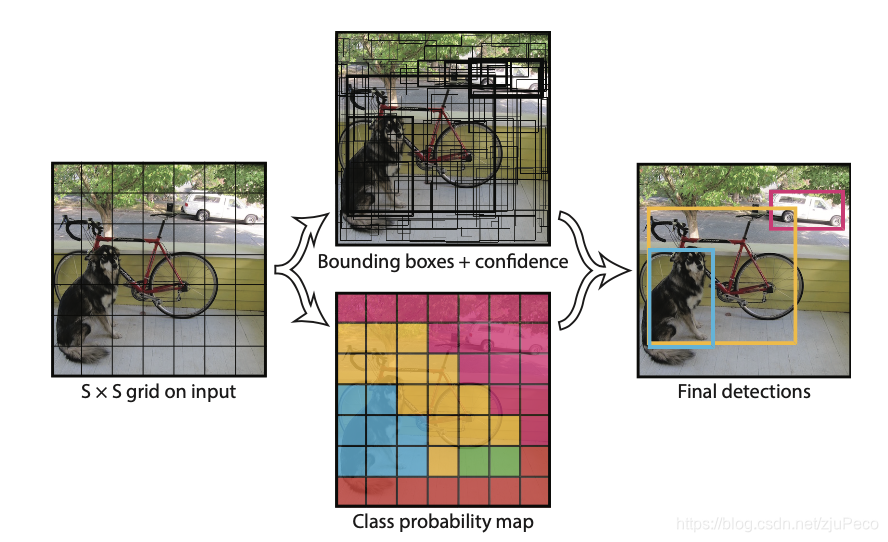
дһ��һĿ��Ȼ��ľ���ij��grid��30ά����Ϊ
[
x
c
1
,
y
c
1
,
w
1
,
h
1
,
c
o
n
f
i
d
e
n
c
e
1
,
x
c
2
,
y
c
2
,
w
2
,
h
2
,
c
o
n
f
i
d
e
n
c
e
2
,
c
a
t
e
1
,
.
.
.
,
c
a
t
e
20
]
[x_{c1}, y_{c1}, w_1, h_1, confidence_1, x_{c2}, y_{c2}, w_2, h_2, confidence_2, cate_1, ..., cate_{20}]
[xc1?,yc1?,w1?,h1?,confidence1?,xc2?,yc2?,w2?,h2?,confidence2?,cate1?,...,cate20?]
���Ҫ֪��ij��grid��һ�����ʾ c a t e 1 cate_1 cate1?���Ŀ��ĸ���,��Ϊ c o n f i d e n c e 1 �� c a t e 1 confidence_1 \times cate_1 confidence1?��cate1?��
��ϸһ��,�ᷢ��ÿ��gridֻ�ܱ�ʾһ������, c o n f i d e n c e i confidence_i confidencei?��������û����������ĸ�Ԥ���, c a t e i cate_i catei?��ʾ������������ĸ�Ŀ�����Ҳ���� 7 �� 7 7\times7 7��7��feature map���ֻ��Ԥ���49��Ŀ��,���СĿ������ڶ�Ŀ��ܲ��Ѻ���
2.1.3 Yolov1��ѵ��
ѵ������ֻ����loss��ص�����,�����ĺ�Yolo������ϵ����,���DZ���pipeline��
ѵ��ʱ,���ǵ�label��ÿ��ͼƬ�����������Ͷ�Ӧ���������ÿ�����嶼������ 7 �� 7 7\times7 7��7��feature map�е�ijһ��������,�䵽�ĸ�������,��ô�Ǹ����������Ԥ��������塣��ÿ����������������,��ȡ���к���ʵ�����bbox��iou�ϴ���Ǹ�Ԥ�����Ϊ������������Ԥ������︺�����˼������loss��ʱ���ø���Ŀ�ȥ��loss��
loss��������������:
(1)���Ķ�λ���
���Ǹ����������ļ�������ĵ���������������ʵ�����ĵ��������١�
L 1 = �� i = 0 S 2 �� j = 0 B I i j o b j ( ( x i ? x ^ i ) 2 + ( y i ? y ^ i ) 2 ) (2-1) L_1 = \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbb{I}_{ij}^{obj} ((x_i - \hat{x}_i)^2 + (y_i - \hat{y}_i)^2)\tag{2-1} L1?=i=0��S2?j=0��B?Iijobj?((xi??x^i?)2+(yi??y^?i?)2)(2-1)
����, S 2 S^2 S2��ʾ 7 �� 7 7\times7 7��7��feature map�ĸ��ӵļ���; B B B��ʾÿ��������bbox�ļ���; I i j o b j \mathbb{I}_{ij}^{obj} Iijobj?��һ��ָʾ����,��ʾ�� i i i�����ӵĵ� j j j������Ԥ����ʵ����ʱ���к���ļ���,����Ϊ0; x i x_i xi?�� y i y_i yi?��ground truth�����ĵ�����; x ^ i \hat{x}_i x^i?�� y ^ i \hat{y}_i y^?i?�Ǹ�����������Ԥ�����������ꡣ
(2)�������
���Ǹ����������ļ���Ŀ��ߺ����������ʵ�Ŀ��߲���١�
L 2 = �� i = 0 S 2 �� j = 0 B I i j o b j ( ( w i ? w ^ i ) 2 + ( h i ? h ^ i ) 2 ) (2-2) L_2 = \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbb{I}_{ij}^{obj} ((\sqrt{w_i} - \sqrt{\hat{w}_i})^2 + (\sqrt{h_i} - \sqrt{\hat{h}_i})^2)\tag{2-2} L2?=i=0��S2?j=0��B?Iijobj?((wi???w^i??)2+(hi???h^i??)2)(2-2)
����, w i w_i wi?�� h i h_i hi?��ground truth�Ŀ���; w ^ i \hat{w}_i w^i?�� h ^ i \hat{h}_i h^i?�Ǹ�����������Ԥ���Ŀ��ߡ��������ź� L 1 L_1 L1?����ͬ��
(3)������confidence���
��֤���������Ԥ����confidence�ӽ�1��
L 3 = �� i = 0 S 2 �� j = 0 B I i j o b j ( C i ? C ^ i ) 2 (2-3) L_3 = \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbb{I}_{ij}^{obj} (C_i - \hat{C}_i)^2\tag{2-3} L3?=i=0��S2?j=0��B?Iijobj?(Ci??C^i?)2(2-3)
����, C i C_i Ci?��ʾ������������������ĵı�ǩ, C ^ i \hat{C}_i C^i?��ʾ������������������ĵ����Ŷȡ�
(4)������confidence���
��֤�����������Ԥ����confidence�ӽ�0��
L 4 = �� i = 0 S 2 �� j = 0 B I i j n o o b j ( C i ? C ^ i ) 2 (2-4) L_4 = \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbb{I}_{ij}^{noobj} (C_i - \hat{C}_i)^2\tag{2-4} L4?=i=0��S2?j=0��B?Iijnoobj?(Ci??C^i?)2(2-4)
����, I i j n o o b j \mathbb{I}_{ij}^{noobj} Iijnoobj?��һ��ָʾ����,��ʾ�� i i i�����ӵĵ� j j j����������Ԥ����ʵ����ʱ���к���ļ���,����Ϊ0��
(5)������
��ʾ����Ԥ��ĸ����ڵ������
L 5 = �� i = 0 S 2 I i o b j �� c �� c l a s s e s ( p i ( c ) ? p ^ i ( c ) ) 2 (2-5) L_5 = \sum_{i=0}^{S^2} \mathbb{I}_{i}^{obj} \sum_{c \in classes}(p_i(c) - \hat{p}_i(c))^2\tag{2-5} L5?=i=0��S2?Iiobj?c��classes��?(pi?(c)?p^?i?(c))2(2-5)
����, I i o b j \mathbb{I}_{i}^{obj} Iiobj?��һ��ָʾ����,��ʾ�� i i i�����ӵĸ���Ԥ����ʵ����ʱ���к���ļ���,����Ϊ0; p i ( c ) p_i(c) pi?(c)��ʾ�� i i i�����ӵ� c c c�����ı�ǩ; p ^ i ( c ) \hat{p}_i(c) p^?i?(c)��ʾ�� i i i�����ӵ� c c c���������Ŷȡ�
�ۺ�, ( 2 ? 1 ) ? ( 2 ? 5 ) (2-1)-(2-5) (2?1)?(2?5)����
L = �� c o o r d L 1 + �� c o o r d L 2 + L 3 + �� n o o b j L 4 + L 5 (2-6) L = \lambda_{coord}L_1 + \lambda_{coord}L_2 + L_3 + \lambda_{noobj}L_4 + L_5 \tag{2-6} L=��coord?L1?+��coord?L2?+L3?+��noobj?L4?+L5?(2-6)
����, �� c o o r d \lambda_{coord} ��coord?�� �� n o o b j \lambda_{noobj} ��noobj?�ǿ������������ij�����,Ҳ���Ǹ���loss��Ȩ�ء����ѿ���Yolov1��Ŀ���⿴����һ���ع����⡣
2.1.4 Yolov1��Ԥ��
Ԥ�ⲿ��ûɶ˵��,���ǶԵõ���98��Ԥ������һ����ֵ��ɸѡ֮��,����nms��
2.1.5 Yolov1��
�ŵ�:
(1)�ٶȿ�
(2)����ͼƬ��ȫ������,precision�ϸ�
ȱ��:
(1)ÿ������ֻ��Ԥ��һ������,���ܼ��͵������ⲻ�Ѻ�
(2)�²���������,������ʹ�õ������Ƚϴֲ�
2.2 Yolo9000 - Yolov2
Yolov2��Yolov1�Ļ������кܴ�ĸĶ�,��һ�ھ���ԸĽ���������˵����
2.2.1 Better
2.2.1.1 ������Batch normalization
BN��һ���dz����õ�ģ��,���е�����:
- �ӿ�����
- �����ݶ�,Զ�뱥����
- �������ѧϰ��
- �Գ�ʼ��������
- �൱������,ʹ����BN������붼������ķֲ�
����BN֮��,�Ϳ��Բ���dropout��,����˵������ԭ��һ����dropout��,��ᵼ��ѵ���Ͳ��Եķ���ƫ��,���Բο�����[5]��
2.2.1.2 �߷ֱ��ʵķ�����
Yolov1���ж�backbone��Ԥѵ����ʱ��,�õ��� 224 �� 224 224\times224 224��224������,��yolov1Ϊ�˸߷ֱ����õ��� 448 �� 448 448\times448 448��448������,�����͵�����ģ��Ҫȥ��Ӧ����ֱ��ʵ�ת��������,Yolov2�ɴ�ֱ���� 448 �� 448 448\times448 448��448������Ԥѵ��backbone�ˡ����������˼���4%mAP�����������ּ���Ч�Ҳ�������Ԥ�⸺���ķ�����������ϲ���ġ�
2.2.1.3 ������anchor����
��Yolov1��û��anchor�ĸ���,���� 7 �� 7 7\times7 7��7��feature map��Ԥ�������Ԥ�����Ұ��������,������Ԥ�����п��ܾͳ��IJ��,��������ȥѧϰ��ͬ��״������,��ģ����˵�DZȽ����ѵġ�
����,Yolov2ɾȥ������ȫ���Ӳ�,������anchor���ơ�Yolov2���������� 416 �� 416 416 \times 416 416��416,feature map��СΪ 13 �� 13 13\times13 13��13,ÿ��������5��anchors,ÿ��anchor�ij�����С�ͱ�����ͬ,��˾��ְ,����ͬ��״�����塣����anchor֮��,ģ�;Ͳ���Ҫֱ��ȥԤ�������ij�����,ֻ��ҪԤ��ƫ�����Ϳ�����,�������˵�������Ѷȡ�
������һ��,֮���Դ� 448 �� 448 448 \times 448 448��448��� 416 �� 416 416 \times 416 416��416����Ϊ��ʹ��feature map��size��һ�������������ĺô���,����ͼƬ�����ĵ㶼��ij�����������,������֤�м���һ������,������ż�������ĸ�������ռ���ĵ㡣
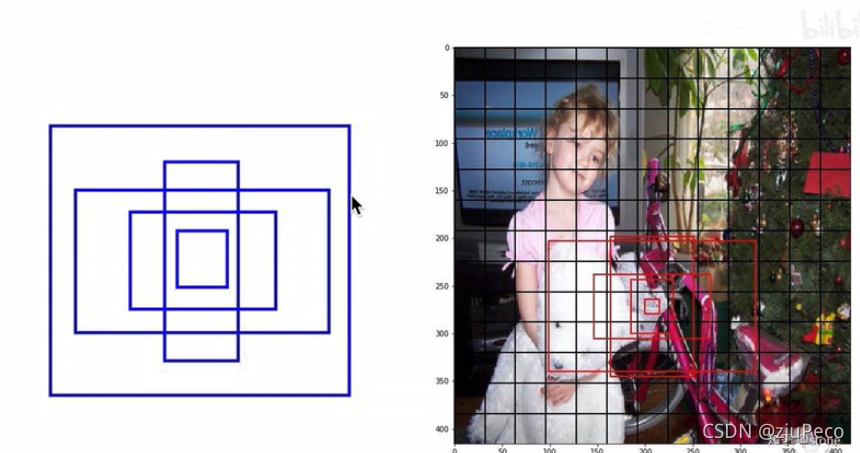
��������anchorҲ�в��õĵط�,��������anchor��ʱ��,Ԥ�����ֻ��98����,������845������,�����ս������,precision�����½���,����recall��������ࡣ
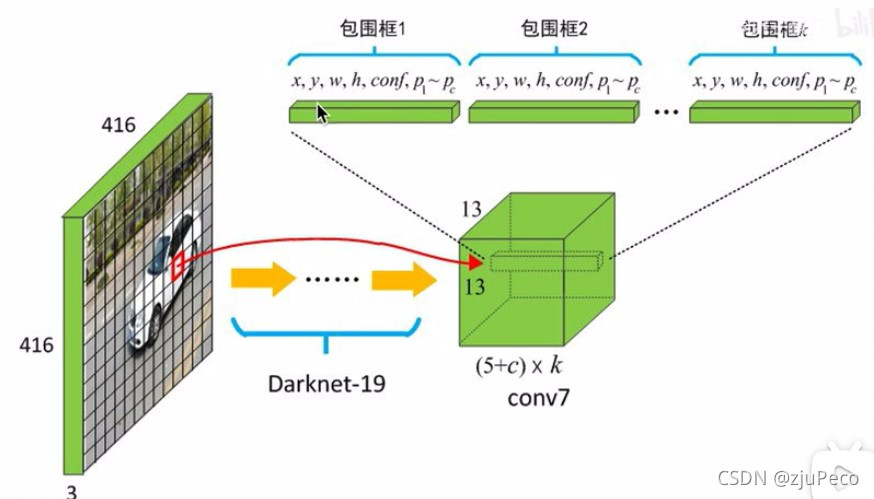
Yolov1�������һ�� 7 �� 7 �� 30 7 \times 7 \times 30 7��7��30��,Yolov2�������һ�� 13 �� 13 �� 125 13 \times 13 \times 125 13��13��125,���� 125 = ( 5 + 20 ) �� 5 125 = (5 + 20) \times 5 125=(5+20)��5��������� 5 5 5��ʾ x i , y i , w i , h i , c o n f i x_i,y_i,w_i,h_i,conf_i xi?,yi?,wi?,hi?,confi?, 20 20 20��ʾÿ�����ĸ���,��20�����,���� 5 5 5��ʾ 5 5 5��Ԥ���ͼ4��ʾ�ķdz�����ˡ�
���Կ���,ͬһ���������ÿ��Ԥ��������ǿ��Բ�ͬ��,һ�����ӿ���Ԥ��5�������ˡ�
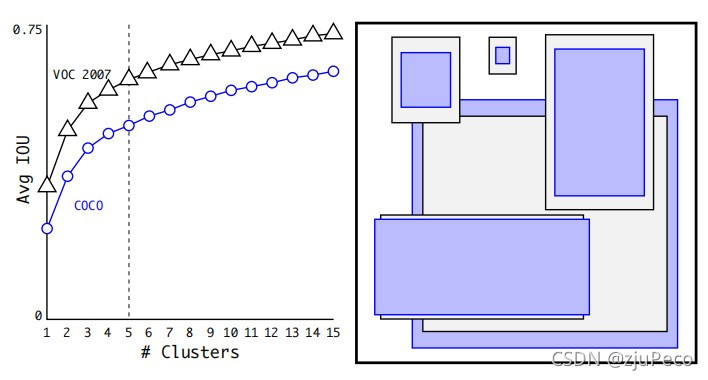
��ô��5��anchor��Ԥê������ôȷ������?����Ϊʲô��5����?��������������,anchor����״����VOC 2007��COCO���ݼ��Ͼ���õ���,�������������1��15���Թ�,������Ч�������ܵ�Ȩ��֮��ѡ����5����۳�����ê����״,ʾ��ͼ����ͼ5��ʾ��
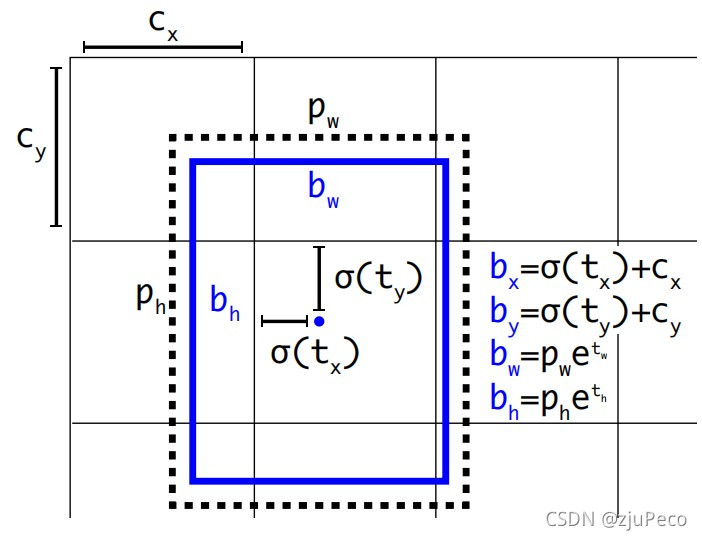
˵�˰���,ģ�;�������ô����offset����?����ͼ6��ʾ,yolov2��anchor�����ڶ��εļ��ģ�͵Ļ��������˸Ľ���ͼ6�� c x c_x cx?�� c y c_y cy?��ÿ�����ӵ����Ͻ�����, t x t_x tx?�� t y t_y ty?��ģ��Ԥ��ê�����ĵ�����ʱ���������,���� �� \sigma ���Ͱ����ĵ��ƫ�������������������,��������ģ����ôԤ��,���ĵ㶼�ɲ���������ӡ� p w p_w pw?�� p h p_h ph?��Ԥê��ij�ʼ����, t w t_w tw?�� t h t_h th?��ģ��Ԥ��ê����ߵ��������,�����û����������ê�����״�� b x b_x bx?, b y b_y by?, b w b_w bw?, b h b_h bh?�����յ�Ԥ�������ĵ�����Ϳ��ߡ��Ұ�ͼ�еĹ�ʽ��һ���������� ( 2 ? 7 ) (2-7) (2?7)��
b x = �� ( t x ) + c x b y = �� ( t y ) + c y b w = p w e t w b h = p h e t h (2-7) \begin{aligned} b_x &= \sigma (t_x) + c_x \\ b_y &= \sigma (t_y) + c_y \\ b_w &= p_w e^{t_w} \\ b_h &= p_h e^{t_h} \\ \end{aligned} \tag{2-7} bx?by?bw?bh??=��(tx?)+cx?=��(ty?)+cy?=pw?etw?=ph?eth??(2-7)
����֮��,����һ���������� t o t_o to?, t o t_o to?��������������������Ŷȵġ�
P r ( o b j e c t ) I O U ( b , o b j e c t ) = �� ( t o ) (2-8) P_r(object)IOU(b, object) = \sigma(t_o) \tag{2-8} Pr?(object)IOU(b,object)=��(to?)(2-8)
2.2.1.4 loss�ĸĶ�
Yolov2��loss��ֱ�����Ӻ�������ͼ��,���Ҳ�������Ǹ���Դ������������,�����в�û��˵����¡�
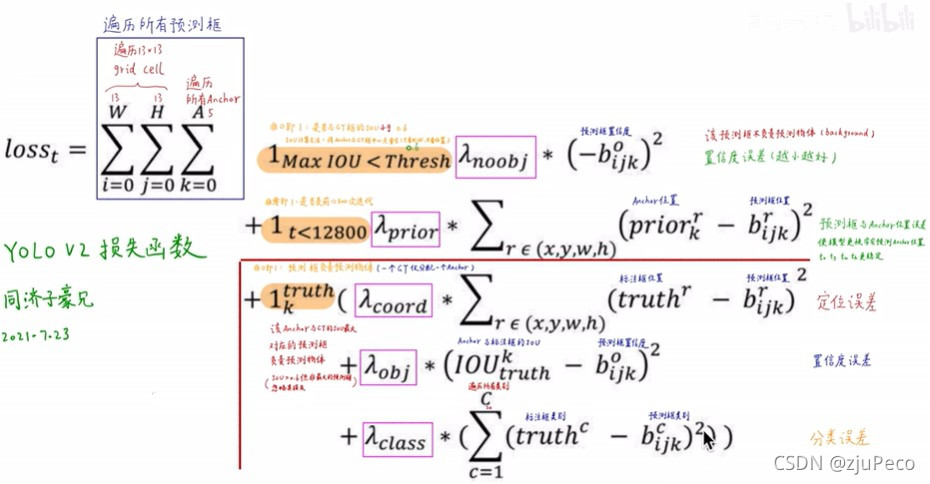
ǰ���������;���ָ����������в������Ƕ�ÿ������ÿ��Ԥ���ֱ�����; I M a x I O U < T h r e s h \mathbb{I}_{MaxIOU<Thresh} IMaxIOU<Thresh?��ʾ845����ֱ�����е�ground truth��IOU,�������IOUҲС����ֵThresh�Ļ�,����Ϊ������DZ���,����������Ŷ� b i j k o b_{ijk}^o bijko?ҪԽСԽ��; I t < 12800 \mathbb{I}_{t<12800} It<12800?��ʾǰ12800�ε���,Ҳ����ģ��ѵ��������ʱ��,������ģ�͵�Ԥ��ê��ӽ�Ԥê��,�е�������һ�µ���˼,���ó�ʼ��ê��̫��������; I k t r u t h \mathbb{I}_k^{truth} Iktruth?��ʾ�Ը���Ԥ��ground truth��ê����е�loss���㡣���е�LossҲ���ǻع����㡣
2.2.1.5 Fine-Grained Features
������ϸ���ȵ�����,�������ǰ�dz���
26
��
26
��
512
26 \times 26 \times 512
26��26��512��������ֳ��ķ�֮��concat��ԭ���������ϡ�
26
��
26
��
512
26 \times 26 \times 512
26��26��512�ֳ��ķݲ�concat�ͱ����
13
��
13
��
2048
13 \times 13 \times 2048
13��13��2048,�����
13
��
13
��
1024
13 \times 13 \times 1024
13��13��1024������concat��һ������
13
��
13
��
3072
13 \times 13 \times 3072
13��13��3072��
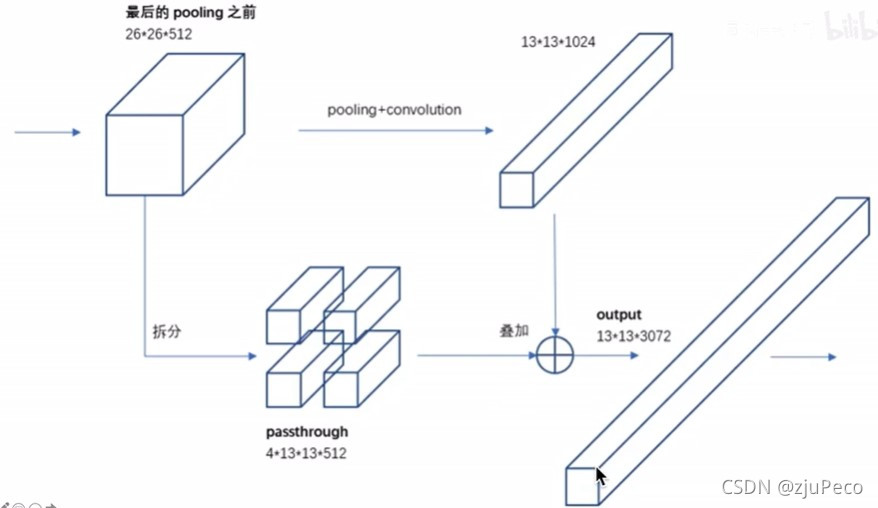
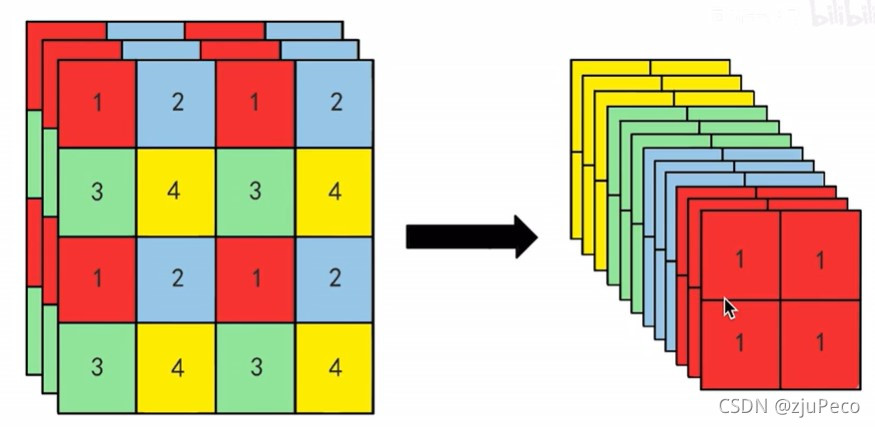
�ķֵķ�ʽ�е�ն���������˼,����ͼ9��ʾ��
2.2.1.6 ��߶�ѵ��
Yolov2ÿ10��batches�ͻỻһ������ij߶�,ʹ��ģ�ͷ����ڲ�ͬ�߶ȵ�����,�������adaptive pooling�㡣�߷ֱ��ʵ������ٶ���,���Ƕ�СĿ��ļ��Ч��Ҫ�úܶ�,�ͷֱ��ʵ������ٶȿ졣
2.2.2 Faster
�ⲿ��ûɶ˵��,���ǰ�backbone��������Darknet-19,���Ǿ������pooling��,���������ˡ�
2.2.3 Stronger
�ⲿ�������߶Գ�������һ�γ���,������Ч��û����ô��,ֻ��һ�����롣
����ѵ�����ģ�͵����ݼ�coco��80�����,10���ͼƬ,��������������ݼ�imagenet��22k�����,140������ݡ�������Ҫ��imagenet�����ݺ����������,���Ǿ��ദ�˲㼶��������취,����ͼ11��ʾ��
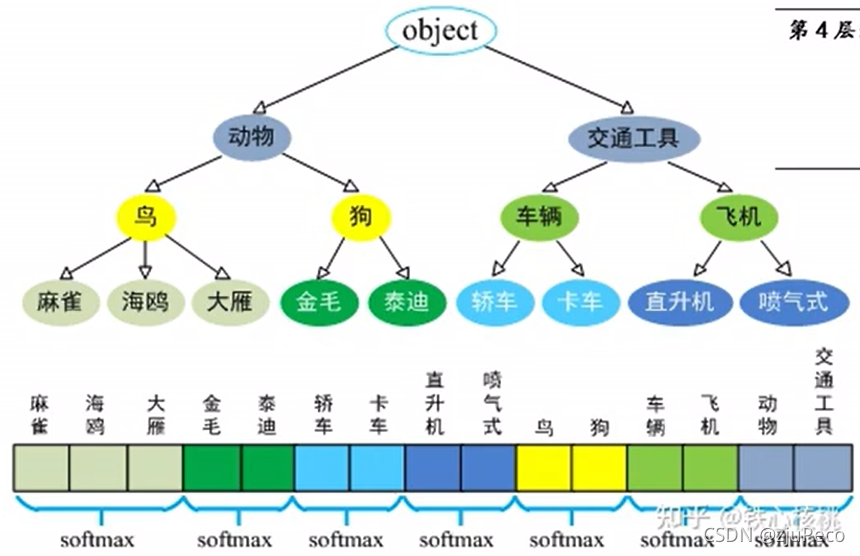
imagenet�е�ÿ���������ȫ���������,����֮�����в㼶��ϵ��,�������߽���wordnet���������˷ֲ�,ͬһ������ֱ����softmax,�����������˶�㼶�ķ��ࡣ���ģ�͵�����ǰ�������Щ���֮�е�,�ٽ���Ӧ�õ����ģ�ͼ��ɡ�
��ֻ��һ������,�˽�һ�¼��ɡ�
2.3 һС�� - Yolov3
Yolov3�����Yolov2û��̫���ĸĽ�,�����ߵĻ�˵����"I managed to make some improvements to YOLO. But, honestly, nothing like super interesting, just a bunch of small changes that make it better."
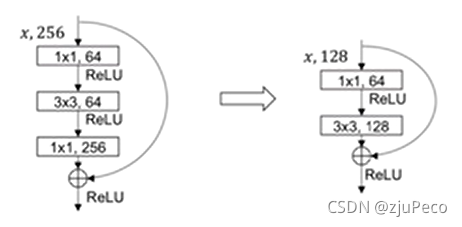
���߶�backbone������ṹ�����˸Ľ�,��Darknet19���Resnet,�����Darknet53�����߰Ѳв����������һ��,����ͼ12��ʾ��
����֮��,�������˶�߶�ѵ������,�����˶�߶�ѵ��������ṹʾ��ͼ����ͼ13��ʾ����������ߴ��feature map,�ֱ���
13
��
13
13 \times 13
13��13,
26
��
26
26 \times 26
26��26��
52
��
52
52 \times 52
52��52����ߴ��feature map��С�ߴ��feature map�ϲ��������dz�������õ��ġ�
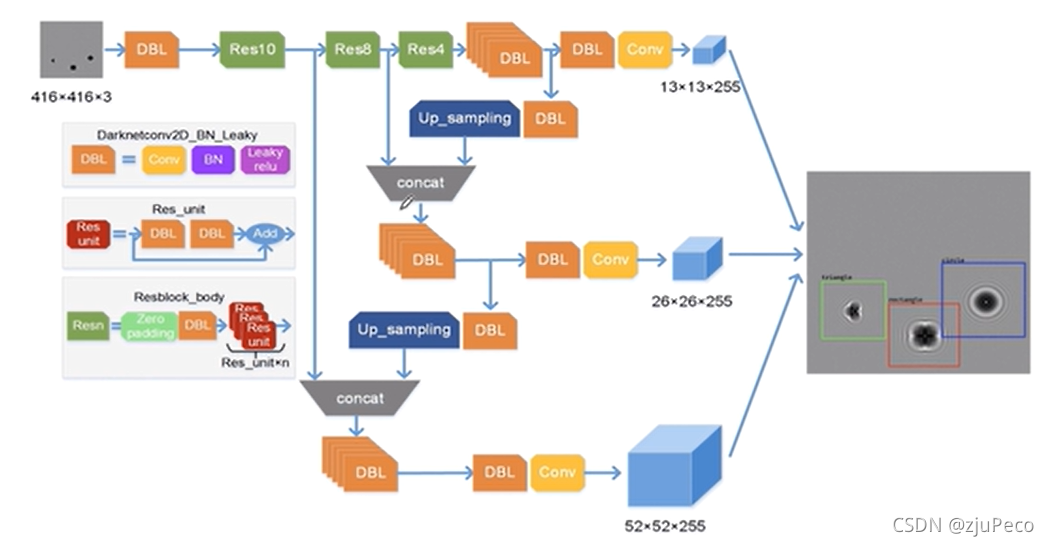
ÿ���ߴ��feature map��˾��ְ, 13 �� 13 13 \times 13 13��13�����Ŀ������, 26 �� 26 26 \times 26 26��26������Ŀ������� 52 �� 52 52 \times 52 52��52����СĿ�����塣ԭ��ܼ�,Խ������ϢԽ����,Խdz���Խ�ֲ�,dz�㻹������С�������Ϣ,���Ͳ�һ�������ˡ�
��ͼ13�п��Կ���feautre map�����channel�����256,�������ΪYolov3��anchor�����9��,ÿ���߶ȵ�feature map��3��,Ȼ���������80��,����ÿ���߶ȵ�feature map��
256
=
3
��
(
4
+
1
+
80
)
256=3 \times (4+1+80)
256=3��(4+1+80)��

Yolov3����Щ��Ҫ�ĸĽ���
2.4 ���� - Yolov4
Yolov4����˵��Ŀ�������С���ɵĴ��ܽ�,�������ɷ�Ϊ��bag of freebies(BoF)��bag of specials(BoS)����,BoFָ����ֻ����ѵ���ijɱ��������������ijɱ��ļ���,ͨ����ǰ����;BoSָ����ֻ����һ�������ɱ�ȴ�����������ģ��Ч���ļ���,ͨ���ǽṹ�ϵı仯��
��ͬ��BoF��BoS��Բ�ͬ����������ݼ��в�ͬ��Ч��,��������ѡ�ɡ�
BoF��BoS����һ���,Ҫ������ȫ����̫��ʱ��,Ҳ����ƪ���µ�Ŀ����㣡�����ֻ��һЩ��Ҫ��,�����յ�Yolov4���ϵļ��ɡ���ͼ15��Yolov4�����õ���һЩ�Ľ���

���ﲻ�����������иĽ�������,ֻ��һЩ��Ҫ�Ľ���
2.4.1 ����ṹ�ĸĽ�
2.4.1.1 backbone�еļ������ΪMish
Yolov3�еľ����춼��CBL�Ľṹ,Yolov4�ij���CBM,Ҳ���ǰѼ�������ij���Mish,��ʾ��ͼ����ͼ16��ʾ��

Leaky Relu�������( a a a�Ǻ�С�ij���)
f ( x ) = { a x , i f ? x < 0 x , o t h e r w i s e (2-9) f(x) = \begin{cases} ax, &if \ x<0 \\ x, &otherwise \end{cases} \tag{2-9} f(x)={ax,x,?if?x<0otherwise?(2-9)
Mish���������
f ( x ) = x ? t a n h ( l o g ( 1 + e x ) ) (2-10) f(x) = x \cdot tanh(log(1+e^x)) \tag{2-10} f(x)=x?tanh(log(1+ex))(2-10)
����˳����˵˵���õļ��������ȱ�㡣
sigmoid���˺����ױ���,������ݶ���ʧ������,�м��ݶȺܴ�,������ݶȱ�ը���⡣��sigmoid�������,�����粻̫��ѵ��������sigmoid�ķ����Ա���������ǿ,��Ϊ��������ô�߽����Ծ��Ƿ����Եġ�
tanh��sigmoid����,����������0Ϊ���ġ�
relu��������,���ĸ�����û�ݶ���,������������dz���,�����Ա��������������������졣������relu������һ�������������,�Դ����ֲ�relu������������������ȱ�ݡ�
leaky relu�����������Ż�,�����Ƿ����Ա�����������
mish�����relu��tanh���ŵ㡣��������,�������Ա�֤û�б�������,�����ݶ���ʧ��������,�ܹ���֤����һ��������������ͬʱ�����Ա�������Ҳ������
2.4.1.2 backbone�еIJв�ģ��ij���CSP
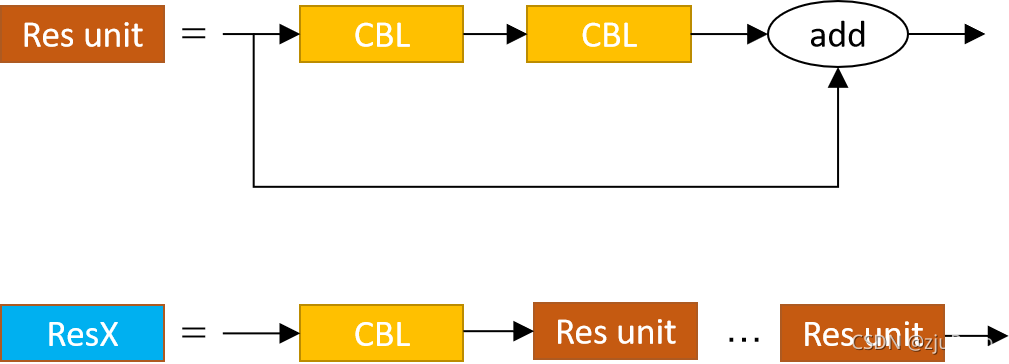
Yolov3�еIJв�ģ������ͼ17��ʾ,resX�е�X��ʾ������X��Res unit��
Yolov4���ǽ��в�ģ���滻Ϊ��CSPģ��,����ͼ18��ʾ,���е�CSPX�е�X��ʾ��X��Res unit��
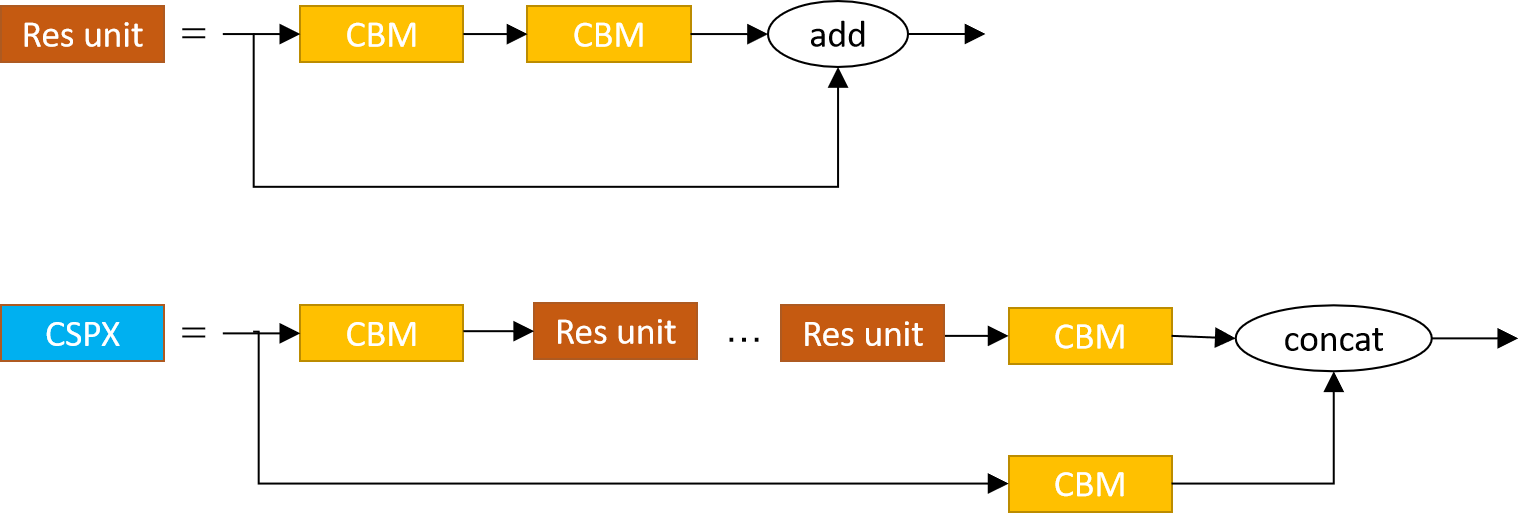
���Կ���CSPXЧ�²в��,�������һ·,������һ·�ж���һ��CBM,����addҲ�����concat���൱��һ�Ѳв�������ٲв���һ�顣����Ӹ�CBMֱ������Ϊ�˸ı�������shape,ʹ�����˳��concat������֮��,����[8]�еIJ�����,����Ϊ��ƽ��������·����Ϣ,�൱�ڼ��˸����衣ÿ���������,���Ǹ���·��״̬,��Ϣ������������,�����������,�Ϳ��Ծ�����ƽ������·����Ϣ����ֻ�Ǹ����롣
2.4.1.3 detector�е�������SPPģ��
SPP���������������Ұ�����ܼ�,����һ��MaxPooling,ÿ��MaxPooling��kernel size��С��ͬ,���в�ͬ����Ұ�Ľ��,�����ȫ��concat��������,��ʾ��ͼ����ͼ19��ʾ��

SPP֮���Բ�����backbone����Ϊ�����ɴ�������Ϣ��ʧ,������detector��ȴ���˽�ά�����á�
2.4.1.4 detector�������߶ȵı仯
Yolov4����detector�еij߶��������˺ܴ����,����ͼ20��ͼ21�ֱ���yolov3��yolov4������ṹͼ��
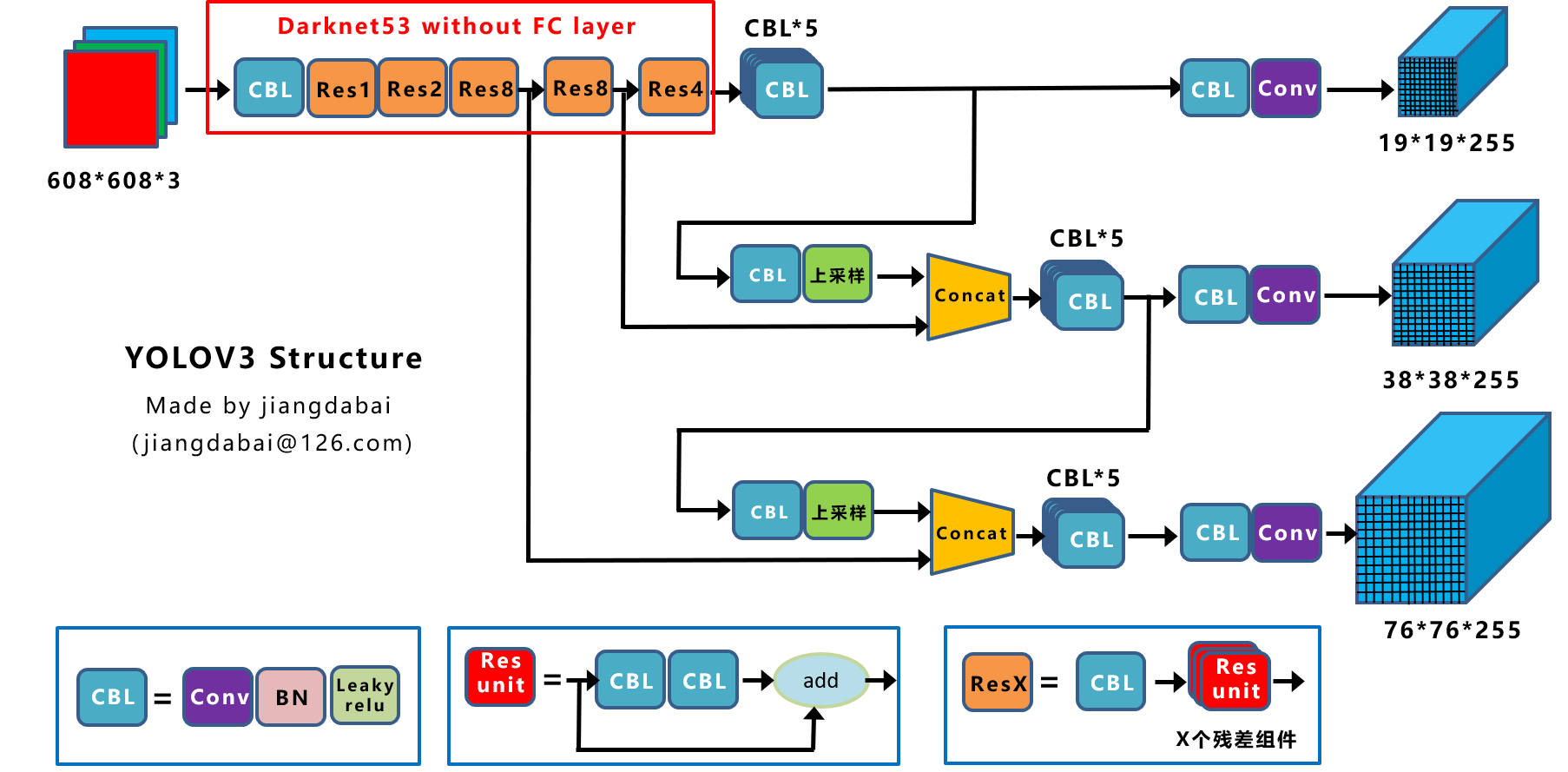
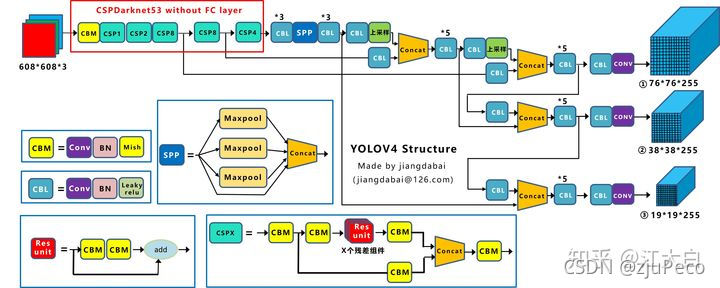
���ѿ���Yolov3�� 19 �� 19 19 \times 19 19��19 -> 38 �� 38 38 \times 38 38��38 -> 76 �� 76 76 \times 76 76��76��,��Yolov4�Ƿ�������,����Ҫ��Ϊ�����������ں���,Ҳ����feature map���ں��˸�������Ϣ���ر��� 19 �� 19 19 \times 19 19��19���feature map,�ںϵ����������,Ҳ���ǶԴ�Ŀ��ļ��Ч�������ˡ�Ӧ��˵���ܴ�СĿ��,���嶼��������
2.4.2 ��ʧ�����ĸĽ�
(1)��Ϊsmoth_L1
֮ǰYolo����ʧ���������д�����L2��ʧ,��Yolov4�иij���smooth L1��smooth L1�����L1��L2��ʧ���ŵ㡣��������L1��L2��ʧ�Ĺ�ʽ
L 1 = 1 n �� i = 1 n �O f ( x i ? y i ) �O L 2 = 1 n �� i = 1 n ( f ( x i ) ? y i ) 2 (2-11) L1 = \frac{1}{n} \sum_{i=1}^{n} |f(x_i - y_i)| \\ L2 = \frac{1}{n} \sum_{i=1}^{n} (f(x_i) - y_i)^2 \tag{2-11} L1=n1?i=1��n?�Of(xi??yi?)�OL2=n1?i=1��n?(f(xi?)?yi?)2(2-11)
L1���ŵ��ǵ������ȶ�,������һ���κ���,�� ( 0 , 0 ) (0,0) (0,0)����һ�����ߡ�L2���ŵ����� ( 0 , 0 ) (0,0) (0,0)���ǿɵ���,������ ( 0 , 0 ) (0,0) (0,0)ԽԶ,����Խ��,�������ը�����Ծ����˽��L1��L2��smooth L1����
s m o o t h ? L 1 = { 0.5 x 2 i f ? �O x �O < 1 �O x �O ? 0.5 o t h e r w i s e (2-12) smooth\ L1 = \begin{cases} 0.5x^2 & if\ |x| < 1 \\ |x| - 0.5 & otherwise \end{cases}\tag{2-12} smooth?L1={0.5x2�Ox�O?0.5?if?�Ox�O<1otherwise?(2-12)
(2)iou loss�Ľ�
������Ҫ�ο�������[10]
��Yolov3�е�IOU loss��ֱ���� ( 1 ? I O U ) 2 (1-IOU)^2 (1?IOU)2�������iou���ǽ������ϲ���,����ͼ22��ʾ��
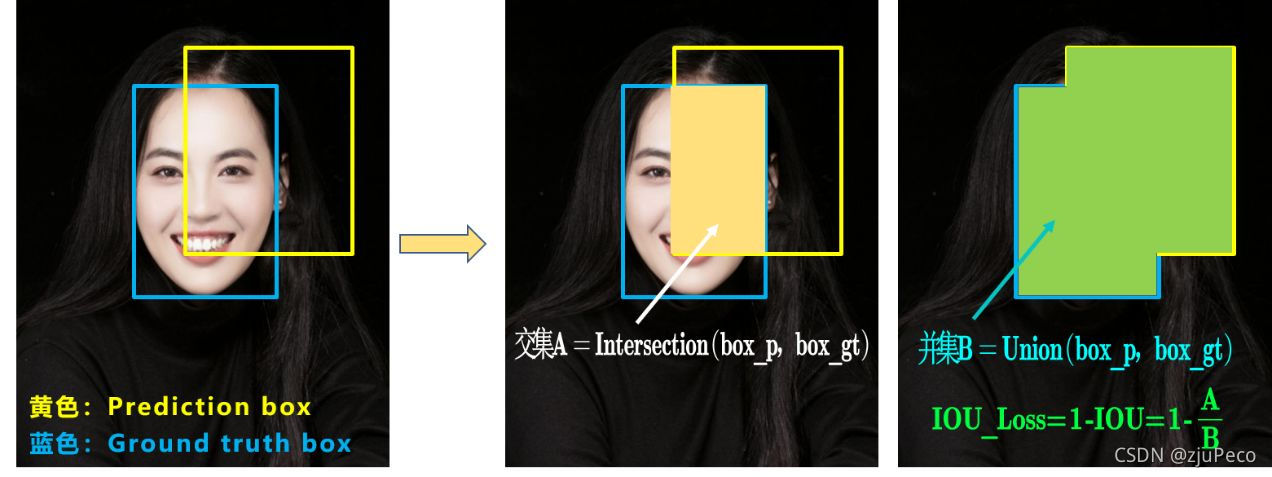
�����IOU�ļ��㷽���ŵ�ȱ��,�ҿ���ͼ23��ȱ��һ������ͼ��ʾ,��Ԥ�������ʵ����ȫû�н���ʱ,����Ԥ�������ʵ���Զ,IOU����һ����,����ʵ����ʵ����ı�����ʵ��Զ��Ҫ��һЩ��ȱ���������ͼ����ͼ��ʾ,�������Ͳ���һ��ʱ,��ͬ�����Ԥ���õ���iou��һ����,����ʵ��ͼ����ͼҪ��һ��,��Ϊ��ͼ�����ĵ������ҪԤ����ˮƽ�ʹ�ֱ�������Ƚϴ�ı仯,����ͼֻ��Ҫˮƽƽ�Ƽ��ɡ�

Ϊ�˽������������ȱ��,����GIOU,��ͼ24��ʾ��

GIOU�Ĺ�ʽΪ
G I O U = I O U ? �� �� / �� С �� �� �� �� (2-13) GIOU = IOU - �/��С��Ӿ��� \tag{2-13} GIOU=IOU?����/��С��������(2-13)
��С��Ӿ��κͲ����˼����ͼ24�е���ͼ����ͼ,���ѿ���,�ղ��ᵽ������ȱ���������Ѿ�����ˡ���������һ������,��ͼ25��ʾ��

��Ԥ�������ʵ���ڲ���ʱ��,����Ԥ������Ǹ�λ��,GIOU����һ����,����ͼ25����ͼ��Ȼ��������ͼ����ͼ��,��Ϊ��ͼ��ˮƽ�ʹ�ֱ����������Ѿ�������,ֻ��Ҫ�ı䳤�����ɡ�
���ʱ��,���ֳ�����һ��DIOU,��ͼ26��ʾ��

DIOU�Ĺ�ʽΪ
D I O U = I O U ? ( D i s t a n c e _ 2 ) / ( D i s t a n c e _ C ) (2-14) DIOU = IOU - (Distance\_2) / (Distance\_C) \tag{2-14} DIOU=IOU?(Distance_2)/(Distance_C)(2-14)
����, D i s t a n c e _ C Distance\_C Distance_C����С��Ӿ��εĶԽ��߾���, D i s t a n c e _ 2 Distance\_2 Distance_2��Ԥ������ʵ�����ĵ��ŷ�Ͼ��롣
����һ���ͽ����ͼ25��ȱ�㡣����,��,����һ��ȱ�㡣DIOUû�п��dz����ȡ�
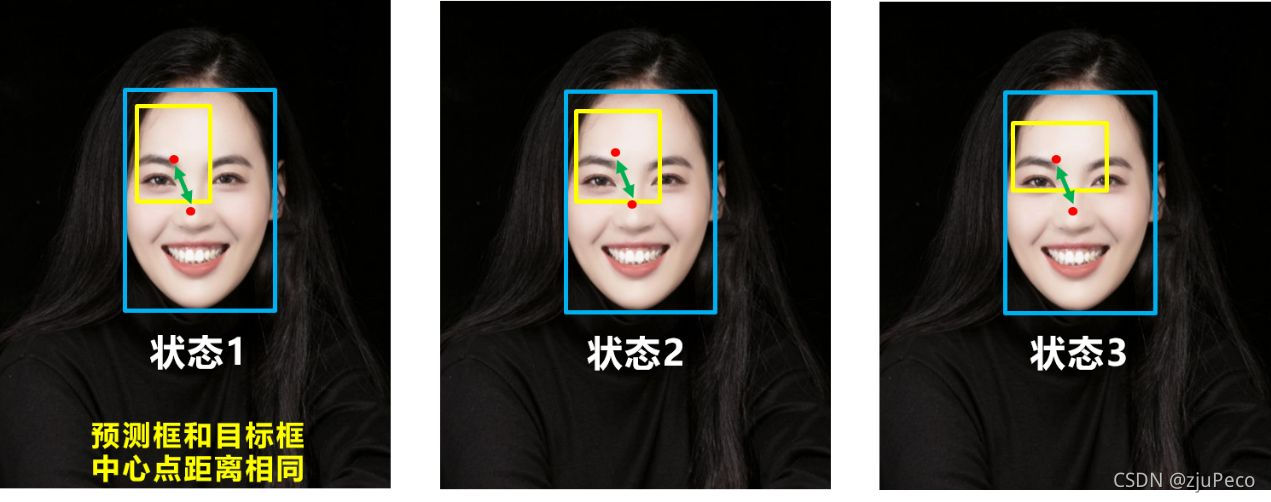
ͼ27�е�Ԥ�����ĵ������ʵ���ĵ�һ��ʱ,Ԥ���ij���������ʵ��ӽ���,��Ȼ�Ǹ��ŵġ�����,�������ռ����CIOU��
CIOU�Ĺ�ʽΪ
C I O U = I O U ? D i s t a n c e _ 2 2 D i s t a n c e _ C 2 ? v 2 1 ? I O U + v (2-15) CIOU = IOU - \frac{Distance\_2^2}{Distance\_C^2} - \frac{v^2}{1 - IOU + v} \tag{2-15} CIOU=IOU?Distance_C2Distance_22??1?IOU+vv2?(2-15)
����, v v v�dz����ȵ�һ���Բ���,����Ϊ
v = 4 �� ( a r c t a n w g t h g t ? a r c t a n w p r e d h p r e d ) 2 (2-16) v = \frac{4}{\pi}(arctan\frac{w_{gt}}{h_{gt}} - arctan\frac{w_{pred}}{h_{pred}})^2 \tag{2-16} v=��4?(arctanhgt?wgt???arctanhpred?wpred??)2(2-16)
����,iou��������ô��汾,����ȷ��ΪCIOU��
2.4.3 nms�ĸĽ�
��ѵ����ʱ���õ���CIOU,��������nms��ʱ��,����diou-nms����diou-nms����һЩ�ص��ȺܸߵĿ�,����ʾ��ͬ����ĸ���������������Ϊʲô����CIOU,�Ҿ�����û�б�Ҫ,�һ����Ӽ��㸴�Ӷȡ��Ҳ�̫ͬ������[10]��˵��CIOU����nmsʱû����ʵ��, v v vû�������˵��,���������Ա�,�����Ŷȸߵĵ�����ʵ�ɡ�
2.4.4 ����
�����Ƚ���Ҫ�Ŀ��ܾ���cutout,mosaic֮���������ǿ�ķ�����,�������Ͳ�ϸ���ˡ�
2.5 ��һС�� - Yolov5
Yolov5��Yolov4������˵û����̫��ĸĽ�,���������ϸ��Ѻ���һЩ,ʹ������Ҳ���ӷ��㡣
2.5.1 ����ṹ�ĸĽ�
2.5.1.1 ������CSP2ģ��
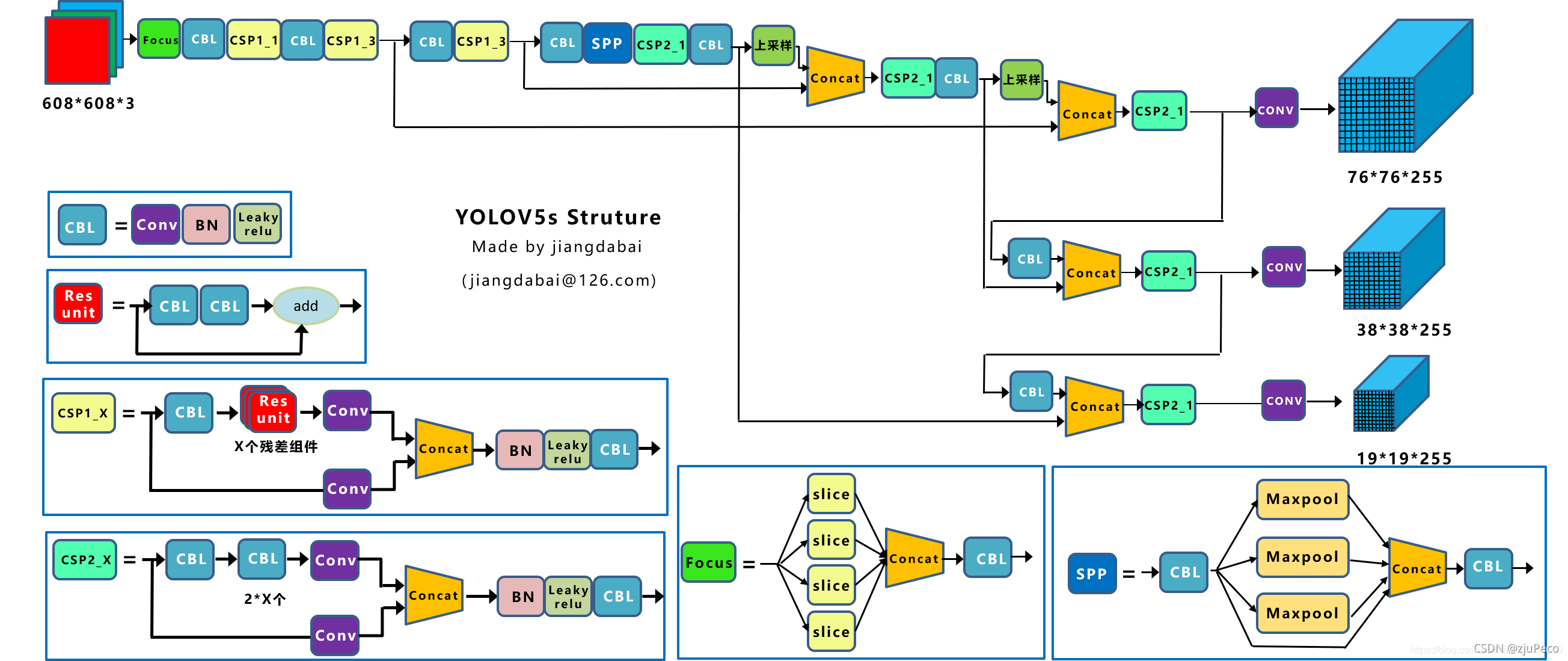
��ͼ28ʱYolov5������ṹͼ,��Yolov4����ʱһ��һ��,����һ���Ľ���
(1)��CBM������CBL,������Ϊ�������ٶȡ�
(2)�����CSP2ģ��,��ͼ28�����½���ʾ,���ǰ�֮ǰCSP�еIJв��ij���CBL��
(3)������Focusģ�顣�����ʵ����Yolov2�е�pass through��
2.5.2 ����
���о���һЩ��������Ķ���,������м����Ƚ����õİɡ�
(1)������ѵ��ǰ�Զ��������Ԥê���ģ�顣
(2)����ӦͼƬ����,����padding��ʱ��,ȥ��һЩû�õĺڱߡ�
3 ������
����������ϸ��ҵ������ܽ��˺ܶ�,����Ҳ��һЩ�Լ�������,���������˽�Yolo�кܴ�İ���,Ҳϣ����������ƪ���͵�����һЩ������
�����
[1] You Only Look Once: Unified, Real-Time Object Detection
[2] ���Ӻ��֡�YOLOV1Ŀ����,���Ҿ���
[3] YOLO9000: Better, Faster, Stronger
[4] ������AI���ġ�YOLO V2Ŀ�����㷨
[5] Understanding the Disharmony between Dropout and Batch Normalization by Variance Shift
[6] YOLOv3: An Incremental Improvement
[7] YOLOϵ���㷨֮YOLOv3�㷨����
[8] 2021�����˹��������ѧϰYOLOv4��YOLOv5�̳�
[9] YOLOv4: Optimal Speed and Accuracy of Object Detection
[10] ����dz��Yoloϵ��֮Yolov3&Yolov4&Yolov5&Yolox���Ļ���֪ʶ��������
[11] ����dz��Yoloϵ��֮Yolov5���Ļ���֪ʶ��������