����ѧϰ����֪ʶ��
����ѧϰ��Ҫ��Ϊ�ලѧϰ���ලѧϰ��
- �мලѧϰ:�Ծ��б�ǵ�ѵ����������ѧϰ,�Ծ����ܶ�ѵ��������������ݽ��з���Ԥ�⡣(LR��SVM��BP��RF��GBRT)
- �ලѧϰ:��δ��ǵ���������ѵ��ѧϰ,�ȷ�����Щ�����еĽṹ֪ʶ��(KMeans��DL)
�ලѧϰ
�ع�
���Իع�
��ν�����Իع�,����Ҫ��һ�����Եij�ƽ��,ȥ�����ܵ���ϸ��������㡣��һά�������,��ͼ��ʾ:

����ҪѰ��һ��ֱ��,���������ܵش�����Щ�㡣�������ܡ�������һЩ����,����˵�����ƽ������С��
�������ֱ�ߵķ�������С���˷����ȡ�
���Իع���һ�ּ�ȴʹ�õĻع鼼����
���ع�����(Multicollinearity)��ָ���Իع�ģ���е��Ա���֮�����ڴ��ڸ߶���ع�ϵ��ʹģ�͵�Ȩ�ز�������ʧ������Թ���ȷ��һ������,������ָһ���Ա����������������Ա���֮�������ع�ϵ�������Բ�Ӱ��ģ�͵�Ԥ�����Ӱ���ģ�͵Ľ��͡����������ɽ����ԾͲ�,�Ͳ��������ֹ����Ե����⡣
��ع�
lasso�ع�
����
k����ڷ���
��ν�������,����Ⱥ��,���Ȧ�ӻ������������״̬�����ǿ�������Χ���ھ����ж��Լ������,�������˼��,������k-NN�㷨��k�����㷨�����������ڷ���,Ҳ�������ڻع�,�����ォ�������˷������Ŀ�¡�
����������,һ������ķ����������ھӵġ�����������ȷ����,k������ھ�(kΪ������,ͨ����С)������ķ�������˸���ö���������k=1,��ö�������ֱ���������һ���ڵ㸳�衣�����Ƿ���ǻع�,�����ھӵ�Ȩ�ض��dz�����,ʹ�Ͻ��ھӵ�Ȩ�رȽ�Զ�ھӵ�Ȩ�ش�����,һ�ֳ����ļ�Ȩ�����Ǹ�ÿ���ھ�Ȩ�ظ�ֵΪ1/d,����d�ǵ��ھӵľ��롣���������һЩ�����������������⡣
k ������ѡ�����ʹ�ý�����֤���������ȵȡ�
k-�����㷨��ȱ���Ƕ����ݵľֲ��ṹ�dz����С�
��Ҫ��:
- k ֵ��ѡ��
- ����Ķ���(�����ľ��������ŷʽ����,���Ͼ����)
- ������߹��� (������������)
k ֵ��ѡ��
k ֵԽС����ģ��Խ����,����������ϡ�k ֵԽ��,ģ��Խ��,���������� k=N ��ʱ��ͱ�������ʲô�㶼��ѵ��������������Ǹ��ࡣ����һ�� k ��ȡһ����С��ֵ,Ȼ���ù�������֤��ȷ����������ν�Ľ�����֤���ǽ���������һ���ֳ���ΪԤ������,���� 95% ѵ��,5% Ԥ��,Ȼ�� k �ֱ�ȡ1,2,3,4,5֮���,����Ԥ��,�������ķ������,ѡ�������С�� k������˵,������һ�ԡ�
KNN �Ļع�
���ҵ������ k ��ʵ��֮��,���Լ����� k ��ʵ����ƽ��ֵ��ΪԤ��ֵ���������Ը��� k ��ʵ������һ��Ȩ������ƽ��ֵ,���Ȩ�����������ɷ���(����Խ��,Ȩ��Խ��)��
��ȱ��:
KNN�㷨���ŵ�:˼���,���۳���,�ȿ�������������Ҳ�����������ع�;�����ڷ����Է���;ѵ��ʱ�临�Ӷ�ΪO(n);ȷ�ȸ�,������û�м���,�� outlier �����С�
KNN�㷨��ȱ��:��������;������ƽ������(����Щ�������������ܶ�,��������������������);��Ҫ�������ڴ档
KNN �㷨�� KD ����Ӧ��
����֪�������� KNN �ļ�����,����Ҫ��һ����� k ����,����Ҫ��������㵽���е�ľ���,��ȡС��һ���֡��������������KD tree ����Ϊ�˽���������ġ�˳�� KD tree ȥ����,���ǿ��Ժܿ���ҵ�һ����������,������Ҫ��������㵽���е�ľ��롣
��������ֲ���ʱ��,�����ĸ��Ӷ�Ϊ
log
?
(
N
)
\log(N)
log(N),N Ϊʵ���ĸ���,KD �����������ڵ��
����Զ���ڿռ�ά�ȵ� KNN ����,����ռ�ά�����������ʱ,����Ч�ʻ��ڵ�������ɨ�衣
���� KD ���Ĺ���,������ KNN ����,�����кܶ�����,����Ͳ������ˡ�
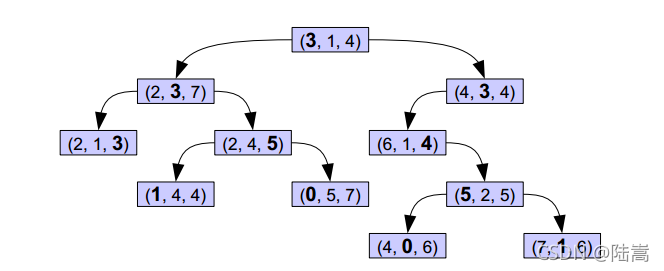
���Թ۲쵽 KD-tree ������һ�� tree�����ĵ�һ��ĵ�һ��Ԫ�ش����������ĵ�һ��Ԫ��,С���������ĵ�һ��Ԫ�ء��ڶ���ĵڶ���Ԫ�ش����������ĵڶ���Ԫ��,С���������ĵڶ���Ԫ�ء��� i ��ĵ� i%k ��Ԫ�ش����������ĵ� i%k ��Ԫ��,С����������,�������ơ�
���ر�Ҷ˹����
���ر�Ҷ˹��ĺ�����,�õ��Ľ���ֻ�DZ�Ҷ˹��ʽ���Զ�����Ϊ��,������������Ĵ���ǩ������,���¸�һ������ʱ,������Ҫ�ж���������һ�ࡣ
����ͨ���Ƚ����������µ���������
P
(
��ǩ1
�O
{
����1,����2,����3
}
)
P(\text{��ǩ1}|\{\text{����1,����2,����3}\})
P(��ǩ1�O{����1,����2,����3})��
P
(
��ǩ2
�O
{
����1,����2,����3
}
)
P(\text{��ǩ2}|\{\text{����1,����2,����3}\})
P(��ǩ2�O{����1,����2,����3})��С��������ࡣ�������ʵļ����ͨ����Ҷ˹��ʽ������,��
P
(
��ǩi
�O
{
����1,����2,����3
}
)
=
P
(
{
����1,����2,����3
}
�O
��ǩi
)
?
P
(
��ǩi
)
P
(
{
����1,����2,����3
}
)
P(\text{��ǩi}|\{\text{����1,����2,����3}\}) = \frac{P(\{\text{����1,����2,����3}\}|\text{��ǩi} )* P(\text{��ǩi})}{P(\{\text{����1,����2,����3}\})}
P(��ǩi�O{����1,����2,����3})=P({����1,����2,����3})P({����1,����2,����3}�O��ǩi)?P(��ǩi)?
���Ǽ�������֮���Ƕ�����,��ô����
P
(
{
����1,����2,����3
}
�O
��ǩi
)
=
P
(
����1
�O
��ǩi
)
?
P
(
����2
�O
��ǩi
)
?
P
(
����3
�O
��ǩi
)
P
(
{
����1,����2,����3
}
)
=
P
(
����1
)
?
P
(
����2
�O
��ǩi
)
?
P
(
����3
)
\begin{aligned} P(\{\text{����1,����2,����3}\}|\text{��ǩi} ) &=& P(\text{����1}|\text{��ǩi} )*P(\text{����2}|\text{��ǩi} )*P(\text{����3}|\text{��ǩi} ) \\ P(\{\text{����1,����2,����3}\} ) &=& P(\text{����1})*P(\text{����2}|\text{��ǩi} )*P(\text{����3} )\end{aligned}
P({����1,����2,����3}�O��ǩi)P({����1,����2,����3})?==?P(����1�O��ǩi)?P(����2�O��ǩi)?P(����3�O��ǩi)P(����1)?P(����2�O��ǩi)?P(����3)?
��Щ����**P(��ǩi)**���ǿ���ͨ��ͳ�����е���������,��Ƶ�������ʵõ���
ע��Ҫ,ʹ�����ر�Ҷ˹�����,���Ǽ���������֮�������,���������о��ޡ���ʵ��,�����ڴ����ı����ݵ�ʱ��,�����õ����ַ�����
��Ҫ�������ñ�Ҷ˹��ʽ,��ij�������²���ij����ǩ�ĸ��ʽ����˲��,��һ����������õ�������֮��IJ�����ԡ�
������������:
- �������������� x = ( a 1 , a 2 , a 3 , �� a n ) x=\left(a_{1}, a_{2}, a_{3}, \ldots a_{n}\right) x=(a1?,a2?,a3?,��an?) ����������� (����Ϊ x x x �������������)��
- �ټ��������з���Ŀ�� Y = { y 1 , y 2 , y 3 , y 4 . . y n } Y=\left\{y_{1}, y_{2}, y_{3}, y_{4} . . y_{n}\right\} Y={y1?,y2?,y3?,y4?..yn?}��
- ��ô max ? { P ( y 1 �O x ) , P ( y 2 �O x ) , P ( y 3 �O x ) �� P ( y n �O x ) } \max \left\{P\left(y_{1} \mid x\right), P\left(y_{2} \mid x\right), P\left(y_{3} \mid x\right) \ldots P\left(y_{n} \mid x\right)\right\} max{P(y1?�Ox),P(y2?�Ox),P(y3?�Ox)��P(yn?�Ox)} �������յķ������
- �����ݱ�Ҷ˹��ʽ P ( y i �O x ) = P ( x �O y i ) ? P ( y i ) P ( x ) P\left(y_{i} \mid x\right)=\frac{P\left(x \mid y_{i}\right) * P(y i)}{P(x)} P(yi?�Ox)=P(x)P(x�Oyi?)?P(yi)?��
- ��Ϊ x x x ����ÿ������Ŀ����˵��һ��, ���Բ��ùܷ���,������ max ? { P ( x �O y i ) ? p ( y i ) } \max \left\{P\left(x \mid y_{i}\right) * p\left(y_{i}\right)\right\} max{P(x�Oyi?)?p(yi?)}��
- P ( x �O y i ) ? P ( y i ) = P ( y i ) ? �� j = 1 n ( P ( a j �O y i ) ) P\left(x \mid y_{i}\right) * P\left(y_{i}\right)=P\left(y_{i}\right) * \prod\limits_{j=1}^n\left(P\left(a_{j} \mid y_{i}\right)\right) P(x�Oyi?)?P(yi?)=P(yi?)?j=1��n?(P(aj?�Oyi?))
- ������� P ( a j �O y i ) P\left(a_{j} \mid y_{i}\right) P(aj?�Oyi?) �� P ( y i ) P\left(y_{i}\right) P(yi?) �����ܴ�ѵ��������ͳ�Ƴ���: p ( a j �O y i ) p\left(a_{j} \mid y_{i}\right) p(aj?�Oyi?) ��ʾ������¸��������ֵĸ���, p ( y i ) p\left(y_{i}\right) p(yi?) ��ʾȫ������������������ֵĸ��ʡ�
����ô������Ϊ��ɢֵʱֱ��ͳ�Ƽ���(��ʾͳ�Ƹ���)������Ϊ����ֵ��ʱ��ٶ��������ϸ�˹�ֲ���
������˹У��
��ij�������ij����������û�г���ʱ,����
P
(
a
�O
y
)
=
0
P(a \mid y)=0
P(a�Oy)=0, ���ǵ��·�������������, ���Դ�ʱ���� Laplace У��,���Ƕ�ÿ����������л��ֵļ�����1��
��������������
�ο��Ľ��ı�Ҷ˹����,ʹ��������ͼ�����и���ͼ��������
��ȱ��
- �ŵ�: ��С��ģ�����ݱ��ֺܺ�,�ʺ϶��������,�ʺ�����ʽѵ����
- ȱ��:���������ݵı�����ʽ������ (��ɢ������, ֵ����С֮���) ��
logistic�ع�
���ع�����Щ����Ҳ�ж������ʻع�,�����ڷ�������,�ر��Ƕ��������⡣���ع������Իع��һ������,���ڶ���������,������Ҫ���ع������ֵ�����ɢֵ,���������ǿ����Ƿ�����㡣��ô�������ѡȡ��?��ν�����ع�,����������ԭ�е����Իع�Ļ�����,����һ��Sigmoid������Ϊȡֵ�ĸ���(ȷ����˵,Ӧ����ȡֵΪ������ 1 �ĸ���),��ʵ��Ҳ����:
p ( y = 1 �O x ) = e w T x + b 1 + e w T x + b p ( y = 0 �O x ) = 1 1 + e w T x + b \begin{aligned} &p(y=1 \mid \boldsymbol{x})=\frac{e^{\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}+b}}{1+e^{\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}+\boldsymbol{b}}} \\ &p(y=0 \mid \boldsymbol{x})=\frac{1}{1+e^{\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}+b}} \end{aligned} ?p(y=1�Ox)=1+ewTx+bewTx+b?p(y=0�Ox)=1+ewTx+b1??
����ͨ�������Ȼ���������Ʋ���,�����Ȼ���ƾ���д���ڲ����³����������ĸ���(Ϊ�˼��㷽��,һ��ȡ������),Ȼ����ڲ�������,�����������ֵ,һ�����ֱ�ӶԲ���ֱ������ʵ,Ҳ���Ǽ������µ���Ȼ������
? ( w , b ) = �� i = 1 m ln ? p ( y i �O x i ; w , b ) \ell(\boldsymbol{w}, b)=\sum_{i=1}^{m} \ln p\left(y_{i} \mid \boldsymbol{x}_{i} ; \boldsymbol{w}, b\right) ?(w,b)=i=1��m?lnp(yi?�Oxi?;w,b)
��ν��Sigmoid����,���ı���ʽ��ͼ����ͼ��ʾ,ͼ���Ҷ� y y y��ȡֵ��ʾ�����Իع������ֵ�������ɢ����

���ع�IJ��л�����Ҫ�ľ��Ƕ�Ŀ�꺯���ݶȼ���IJ��л������ع�������ֲ��Dz�Ŭ���ֲ�,�����Իع���Ǹ�˹�ֲ������ع���Ϊ��������ʷ��Ӳ�Ŭ���ֲ�,����д��ָ����ֲ�����ʽ,����ǿ����Ƶ��õ� sigmoid ����,��Ҳ�������������ԭ��
���ع����ڶ����:
���ڶ��������,���ǿ����� softmax,��ʱ���Ż��IJ���,��������,���Ǿ��� �� \theta �������������Ժ�������һ�� softmax ��Ϊÿ���� j �����ȡֵ�ĸ���:
p j = e �� j T x �� s = 1 k e �� s T x p_{j}=\frac{e^{\theta_{j}^{T} x}}{\sum_{s=1}^{k} e^{\theta_{s}^{T} x}} pj?=��s=1k?e��sT?xe��jT?x?
��Ĺ�����һ���ġ�
��ȱ��:
�ŵ�
- ʵ�ּ�
- ����ʱ�������dz�С,�ٶȺܿ�,�洢��Դ�͡�
ȱ��
- ����Ƿ���,һ��ȷ�Ȳ�̫�ߡ�
- ֻ�ܴ�������������(�ڴ˻��������������� softmax�������ڶ����),�ұ�����
�Կɷ֡�
֧��������
֧��������,������˵���Ե����,�ԿɷֵĶ�ά�Ķ���������Ϊ��,����ʵ�Ͼ���Ѱ��һ��ֱ��,��ƽ���ϵ����ݵ���ȷ�ط�Ϊ����,������ָ�ļ���ﵽ�����ͼ��ʾ,

Ҫ�ָ�(a)��ʾ�����ݵ�,��Ȼ(b)�ķָ���Ҫ����?�ķָ���������ɱ�����Ƿָ���(�������桱)��б�ʺͽؾࡣ��ν�ļ�����Ƿָ������������ݼ��ϵľ���,���������������һ�����������ġ�����������ƽ���ڷָ��ߵ���,�����������ݼ�,��ô���γ���һ����϶�������϶�ڲ������κε����ݵ㡣��϶��Ե�ϵĵ����֧��������
�����ֱ�߱�ʾΪ
w
?
T
x
?
+
b
?
=
0
\vec{w}^T\vec{x}+\vec{b}={0}
wTx+b=0,��ô�����ķָ���ͼ��
ͨ����ѧ�Ƶ�,���ǿ���֪��,���������ʵ����������µ�һ���Ż�����(
w
?
\vec{w}
w��
b
?
\vec{b}
b�Ǵ������):
KaTeX parse error: Unknown column alignment: @ at position 70: ��\begin{array}{r@?{\quad}r@{}l@{\��

���� y i �� { ? 1 , 1 } y_i\in \{-1,1\} yi?��{?1,1},��ʾ���������ı�ǩ��ͨ�����Ż��Ļ�������(�������ն�ż,KKT����,SMO�㷨��),���ǿ����������Ż����⡣
һ�������,���ݵ㲻һ������ͨ��һ�����Եij�ƽ�潫��ֿ�����ô���ǿ��Խ���ӳ�䵽����ά�Ŀռ���,ʹ���ڸ�ά�������ռ������Կɷ�,ͨ������SVM��������ֿ���
���������,���ľ�����ı���ʽ���Ա�ʾΪ
f
(
x
)
=
��
i
=
1
n
��
i
y
i
<
x
i
,
x
>
+
b
f(\textbf{x}) =\sum\limits_{i=1}^n \alpha_iy_i\left<\textbf{x}_i,\textbf{x}\right>+b
f(x)=i=1��n?��i?yi??xi?,x?+b,�����
��
i
\alpha_i
��i?��ԭ�����������ճ���ϵ������Ӧ�ڸ�ά�����ռ�,ʹ������SVM����,��������ı���ʽΪ:
f
(
x
)
=
��
i
=
1
n
��
i
y
i
<
��
(
x
i
)
,
��
(
x
)
>
+
b
f(\textbf{x}) =\sum\limits_{i=1}^n \alpha_iy_i\left<\Phi(\textbf{x}_i),\Phi(\textbf{x})\right>+b
f(x)=i=1��n?��i?yi??��(xi?),��(x)?+b,Ҳ����˵,������ߺ���ֻ����������x��ѵ��������������ڻ���
����� �� \Phi ����ԭʼ�ռ䵽��ά�ռ��һ��ӳ��,����˵�������� ( x , y ) �� ( x , y , x 2 + y 2 ) (x,y)\rightarrow(x,y,x^2+y^2) (x,y)��(x,y,x2+y2)����Ϊ��ά������ɼ���������,����Ѱ��һ�ַ�������ֱ�Ӽ����ڻ� < �� ( x i ) , �� ( x ) > \left<\Phi(\textbf{x}_i),\Phi(\textbf{x})\right> ?��(xi?),��(x)?,��Ѱ��һ������ k ( x i , x ) k(x_i,x) k(xi?,x)����ʾ < �� ( x i ) , �� ( x ) > \left<\Phi(\textbf{x}_i),\Phi(\textbf{x})\right> ?��(xi?),��(x)?,�����滻���ɽ����˼��ɡ���Ϊ�˺��������Ĵ���,ʹ�ø�ά�ռ��е������������ڻ�����ֱ�Ӽ���,�������˼�������
��ά�ռ�ľ���ƽ���ú˺���������,��ô��ά�ռ��еĶ�ż�����Ҳ�����ú˺���������,��ʹ��SMO�㷨�������ʱ,�������ͻ����С����˵,�˷���ͨ���ú˺�����ʾ��ά�ռ����������ڻ�,��ԭ�ռ���ά����ά�ռ���ڸ�ά�ռ���ʹ������SVM������������ϳ���һ�����衣��ν����ά,Ҳ��������Ϊ��ԭ�����Ի��Ļ�����,����һЩ�����ԵĻ�����,ʹ�÷ָ��߲�����ֱ�ߡ�
���õĺ˺���Ϊ���������,���ı���ʽΪ:
��
(
x
1
,
x
2
)
=
e
?
�O
�O
x
1
?
x
2
�O
�O
2
2
��
2
\kappa(x_1,x_2) = e^{\frac{-||x_1-x_2||^2}{2\sigma^2}}
��(x1?,x2?)=e2��2?�O�Ox1??x2?�O�O2?
�� \sigma ��ԽС,�����Ի��̶�Խ�ߡ���� �� \sigma ��ѡ�ú�С,����Խ����������ӳ��Ϊ���Կɷ֡����п��ܻ��������⡣
���ú˺�����:����ʽ�˺�������˹�˺������ַ����˺�����
��ѧ�Ƶ�:
���ڵ�һ������ѧ�Ƶ�,����ֻ��Ҫ�����µļ���������֪:
- ����������ˮƽ������ z = w T x + b z = \boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}+b z=wTx+b����ˮƽ�� w T x + b = 0 \boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}+b=0 wTx+b=0����ʾ�����档
- �㵽������ľ�����:
r = �O w T x + b �O �� w �� . r=\frac{\left|\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}+b\right|}{\|\boldsymbol{w}\|} . r=��w���O�O?wTx+b�O�O??.
����� �� w �� \|\boldsymbol{w}\| ��w��ʵ�����DZ�ʾ���ˮƽ��������б�ʡ� - ��Ϊб���б�ʲ�Ӱ�������,��ô�Ͳ�Ӱ�����Ľ��,��ô������������,��ʵ�ϾͶ���һ�����ɶȡ���ô���ǾͿ������� w \boldsymbol{w} w,�ǵ�֧�������ľ��� $d = \frac{1} {|\boldsymbol{w}|} $����ôԼ����Ŀ�꺯��ʵ���Ͼ����ˡ�
- ����Լ��,��ʵҲ����Ϊ��,���ھ��ߵ�
�O
w
T
x
+
b
�O
=
1
\left|\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}+b\right| = 1
�O�O?wTx+b�O�O?=1,��ôҪ����������ȷ�ط���,��Ȼ��Ȼ�ؾ���:
{ w T x i + b ? + 1 , y i = + 1 w T x i + b ? ? 1 , y i = ? 1 \begin{cases}\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b \geqslant+1, & y_{i}=+1 \\ \boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b \leqslant-1, & y_{i}=-1\end{cases} {wTxi?+b?+1,wTxi?+b??1,?yi?=+1yi?=?1?
��ȱ��:
�ŵ�:
- ʹ�ú˺����������ά�ռ����ӳ��,���Խ�������Եķ��ࡣ
- ����˼��ܼ�,���ǽ������������ļ�����
- ����Ч���Ϻá�
ȱ��:
- �Դ��ģ����ѵ���Ƚ����ѡ�
- ��ֱ��֧�ֶ����,һ��ʹ�ü�ӵķ���������ֱ�ӷ���������Ŀ�꺯�����¹���,���������Ƚϴ�ӷ�������,һ����һ�Զ�,��ȡ��һ����Ϊһ��,����� N-1 ����Ϊһ��,��һ�ζ�����,�����ڷֵõ��������ظ�����������ڶ�����һ��һ,������֮�䶼����һ�η���,�����һ�౻�ֵ��Ĵ������,��ѡ��һ��(vote ��˼��,libsvm,������ѭ��ͼ����)��
����
����ݶ��½�
����֪��,�����мල��������,��һ����ʧ����,��������ģ�͵ĺû����ڻع�������,��������Ѿ�֪�����̵���ʽ,���ǿ��������������ʧ��������ô����Ҫ���ľ���Ѱ�ҷ��̵���Ѳ���,��Ѱ�Ҳ���,ʹ����ʧ���������ﵽ��С��էһ��,����Ǹ��Ż����⡣��Ȼ���ԶԲ����ĸ���������,���ⷽ���顣������,����ȷ�����ķ�����ý�?һ�����ֵ�ⷨ���ݶ��½�����ţ�ٷ�����ţ�ٷ����Լ��������ȵȡ�
�ݶ��½�����������,���ǵ��������Ƚϴ�ʱ,�ݶ��½��ļ�����ر��Ϊ��������������Ż����,����һ����Բ�������ݶ��½���
��ν������ݶ��½�,��������ݶ��½�,���Dz�ѡ��ȫ�������ݵ�,����ÿ�����ѡ��һ���������ɸ����ݵ���������ʧ����,���������ݶ��½�������⡣�������ܲ���������,��ʵ�϶��������������,���ǿ������������Ž��ij������ġ�
����ݶ��½������ݶ��½�:
- ���Ա���ֲ���ֵ
- �����ٶȿ�
- �ײ���
˵������ݶ��½�,˳����һ�� Adam����,Adamʹ�ö���������Ӧѧϰ�����ӿ������ٶȡ�����SGD�����ϼ�����һ����������
AdaGrad �ܹ�ʵ��ѧϰ�ʵ��Զ����ġ��������ݶȴ�,��ôѧϰ����˥���ľͿ�һЩ;�������ݶ�С,��ôѧϰ����˥���ľ���һЩ��
��������
��ν�������б����(LDA),ʵ������һ���мල�Ľ�ά������֮���������ڷ���ı�����,����Ϊ����ͨ�����ַ�ʽ,�ھ��������˸��ߵ����ֶ�,Ҳ����˵��Ϊ�����ķ������˽�ά������
�����б����,�Զ�ά���ݵ����,����Ҫһ��ֱ��,ʹ�����ݵ������ֱ���ϵ�ͶӰ�������ڷ������С,�����뾡���ܴ�,��ͼ��ʾ��
ͶӰ���ѡ��,������Ӱ�����ڷ���,�������롣��Ȼͼ��ʾ���ұ�һ��ͼ�����������ǵ�Ҫ��


���ǽ�������Ķ�����Ϊ����,���ھ���Ķ�����Ϊ��ĸ,�γ�һ��Ŀ�꺯��,����Ҫ���ľ���������Ŀ�꺯�������ù��������̵�һЩ������֪ʶ,���Ǿͽ�����ת��Ϊ��������ֵ�����⡣
������
������,����˼���������һ�����Ϸ�֧�����Ƕ�ÿ������,ѡ��һ�������������ж�,�Ϳ��Խ����ݲ��ϵط���,ֱ�����Ҷ�ӽڵ�����һ��������,����˵��ͬһ����ǩ,��ô�����һ�þ��������ٸ�����,����˵���Ϻû����ж�,��������,���ǿ��ܻ�ѧϰ����ͼ��ʾ��һ�þ�������

��������,�����Ǹ�������������,ÿ��������һЩ�����ͱ�ǩ����Ҫ��һ�þ�����,ʹ��ÿ�����ݰ��վ�����·����,����ܵ����ߵ�ʹ����ȷ�����Ҷ�ӽڵ��С�һ����˵,�������������ľ������кܶ�,�������ж�����ѡ��Ĵ���������ж�����(��ֵ�趨��ͬ��)�IJ�ͬ���ᵼ�����IJ�ͬ,����Ҫ���ľ�����һ����õ������ڲ�ͬ���㷨��,���á��ı�������ͬ��
�Ƚϳ��õľ�������ID3��C4.5�ͷ���ع���(CART),���Ƿֱ�ʹ����Ϣ���桢��Ϣ�����ʺͻ���ָ������Ϊ��������ѡ��û��ı���C4.5��Ϊ���ID3��ƫ��ϸС�ָ���ɵĹ���������,CART�����Ĺ���������ɼ�֦������������
- ID3 ѡ����Ϣ��������������Ϊ��ǰ�ڵ�ľ���������
- C4.5 ѡ����Ϣ�����ʴ����Ϊ����������
- CART ѡ���Ǹ�ʹ�û��ֺ����ָ����С��������Ϊ���Ż������ԡ�
��ȱ��:
�ŵ�:
- ��������,�ɽ�����ǿ,�Ƚ��ʺϴ�����ȱʧ����ֵ������,�ܹ���������ص���
����
ȱ��:
2. ���þ���������������,���Ҷ�����ֵ�������Դ�����
3. �������(�������������ɭ��,��С�˹��������)��
��������:
��Ϣ��:
Ent
?
(
D
)
=
?
��
k
=
1
�O
Y
�O
p
k
log
?
2
p
k
\operatorname{Ent}(D)=-\sum_{k=1}^{|\mathcal{Y}|} p_{k} \log _{2} p_{k}
Ent(D)=?k=1���OY�O?pk?log2?pk?
��Ϣ����:
Gain
?
(
D
,
a
)
=
Ent
?
(
D
)
?
��
v
=
1
V
�O
D
v
�O
�O
D
�O
Ent
?
(
D
v
)
\operatorname{Gain}(D, a)=\operatorname{Ent}(D)-\sum_{v=1}^{V} \frac{\left|D^{v}\right|}{|D|} \operatorname{Ent}\left(D^{v}\right)
Gain(D,a)=Ent(D)?v=1��V?�OD�O�ODv�O?Ent(Dv)
������:
Gain
?
_
ratio
?
(
D
,
a
)
=
Gain
?
(
D
,
a
)
IV
?
(
a
)
\operatorname{Gain}\_{\operatorname{ratio}}(D, a)=\frac{\operatorname{Gain}(D, a)}{\operatorname{IV}(a)}
Gain_ratio(D,a)=IV(a)Gain(D,a)?
IV
?
(
a
)
=
?
��
v
=
1
V
�O
D
v
�O
�O
D
�O
log
?
2
�O
D
v
�O
�O
D
�O
\operatorname{IV}(a)=-\sum_{v=1}^{V} \frac{\left|D^{v}\right|}{|D|} \log _{2} \frac{\left|D^{v}\right|}{|D|}
IV(a)=?v=1��V?�OD�O�ODv�O?log2?�OD�O�ODv�O?
����ֵ:
Gini
?
(
D
)
=
��
k
=
1
�O
Y
�O
��
k
��
��
k
p
k
p
k
��
=
1
?
��
k
=
1
�O
Y
�O
p
k
2
\begin{aligned} \operatorname{Gini}(D) &=\sum_{k=1}^{|\mathcal{Y}|} \sum_{k^{\prime} \neq k} p_{k} p_{k^{\prime}} \\ &=1-\sum_{k=1}^{|\mathcal{Y}|} p_{k}^{2} \end{aligned}
Gini(D)?=k=1���OY�O?k����?=k��?pk?pk��?=1?k=1���OY�O?pk2??
���� a ����ָ��:
KaTeX parse error: Expected '}', got '_' at position 14: \text { Gini_?index }(D, a)=\��
����˵���Ƿֶ���֮��˼�롣
Cart : ����ģ��:���û���ϵ���Ĵ�С���������������ֵ�����ӡ��ع�ģ��:�������ƽ���Ͷ�����
�ලѧϰ
����
k��ֵ
��ν��k-mean�㷨,����Ҫ�ҵ����һ������(����ֳ�k��),ʹ������ƽ���ʹﵽ��С������ѧ����������Ҫ�����ʽ��ʾ���Ż����⡣
arg
?
min
?
S
��
i
=
1
k
��
x
��
S
i
�O
�O
x
?
��
i
�O
�O
2
\mathop {\arg \min }\limits_S \sum\limits_{i = 1}^k {\sum\limits_{x \in {S_i}} {||x - {\mu _i}|{|^2}} }
Sargmin?i=1��k?x��Si?��?�O�Ox?��i?�O�O2
�㷨�Ļ���˼���ǵ���������ѡ��k������Ϊk��������,�����е㰴�������ĵ�Զ�������k���ࡣ���ż���k�����������Ϊ�µ�������,����ǰ���ķ������,ֱ�����IJ��ٸı�,��ô����Ҳ���ٸı䡣
�����뵽,��������Ϊ���IJ���,���ھ���ƽ���Dz�����,���·����IJ������Ҳ�Dz���,����ƽ�������½�,�ʶ��㷨��Ȼ�������ġ�
��ʵ��,�㷨��������������һ���ֲ�����ֵ,��ʼ��ѡ��ò�ͬ,��ô�����������Ľ�����ܾͲ�ͬ��
��ʼ���ѡ��:
-
�������ѡȡһ������Ϊ��ʼ��,Ȼ��ѡ�������õ���Զ���Ǹ�����Ϊ���ĵ�,��ѡ�������ǰ��������Զ�ĵ���Ϊ���������ĵ�,�Դ�����,ֱ��ѡȡ�� k ����
-
ѡ�ò�ξ������ Canopy �㷨���г�ʼ���ࡣ
kmeans ���Ż�:ʹ�� kd ���������еĹ۲�ʵ��������һ�� kd ��,֮ǰÿ���������Ķ�����Ҫ��ÿ���۲�������ξ������,������Щ�������ĸ��� kd ��ֻ��Ҫ���㸽����һ���ֲ����ɡ�
k ��ôѡ?
- ����ר�ҡ���ҵ������������ж�
- ���ڱ仯���㷨:������һ������,���� k �ĸı�,��Ϊ����ȷ�� k ʱ�������ֵ��
- ���ڽṹ���㷨:���Ƚ����ھ���,��������ȷ�� k����Ҳ�DZȽϳ��õķ���,��ʹ��ƽ������ϵ��,Խ������1,����Ч��Խ�á�
- ����һ���Ծ�����㷨:����Ϊ����ȷ�� k ʱ,��ͬ�ξ���Ľ�������,�Դ�ȷ�� k��
- ���ڲ�ξ���:�����ںϲ�����ѵ�˼��,��һ�������ֹͣ�Ӷ���� k��
- ʹ�� BIC �㷨���г�ʼ���֡�
- ���ڲ������㷨:������������,�ֱ������ࡣ������Щ�����������ȷ�� k��
- ʹ�� Canopy Method �㷨���г�ʼ���֡�
�ֲ�ξ���
����
��˹���ģ��
EM�㷨��������ر���������,�������Ĺ��̡�EM �������������ĸ���ģ�͵ļ�����Ȼ���ơ���һ���Ϊ����:
- ��һ��������(E)
- �ڶ�����(M)
�������ģ�͵ı������ǹ۲����,��ô��������֮��Ϳ���ֱ��ʹ�ü�����Ȼ������
��Ҷ˹����ģ�Ͳ��������ǵ�ģ�ͺ�������������ʱ��Ͳ��ܼ�����Щ����������,EM ����һ�ֺ������������ĸ���ģ�Ͳ����ļ�����Ȼ���Ʒ���
Ӧ�õ��ĵط�:��ϸ�˹ģ�͡�������ر�Ҷ˹ģ�͡����ӷ���ģ�͡�
��ά
PCA��ά
��ν�����ɷַ���,�������ڸ�ά�Ŀռ���Ѱ��һ����ά����������ϵ,����˵����ά�ռ���Ѱ��һ����ά��ֱ������ϵ����ô�����ά��ֱ������ϵ�ͻṹ��һ��ƽ��,����ά�ռ��еĸ������������άƽ������ͶӰ,�͵õ��˸������ڶ�ά�ռ��е�һ����ʾ,�ɴ����ݵ�ʹ���ά�����˶�ά��
������̵Ĺؼ�����,�������ѡȡ�����ά������ϵ,������ϵԭ������?�����ᳯ�ĸ�����?һ��ԭ�����ʹ�ø����㵽�����ƽ��ľ���ƽ���ʹﵽ��С���ɴ�,ͨ������ѧ�Ƶ�,���ܵõ�ԭ��ı��﹫ʽ������ϵ�ĸ����������ı��﹫ʽ��
�����Ի��ھ�����ӽ�д��PCA�㷨���㷨����,����Ϊp*N����X,���Ϊd*N����Y�������ÿһ�ж���ʾһ������,ÿһ�ж���ʾ�����һ��������ʾ��
ѡȡ��2000x1680�����ݼ������˲���,ѡȡ��ά��ά��Ϊ20,�併άǰ���ͼ��(��ά���ͼ��ָ����ͶӰ�㻹ԭ��ԭ�ռ��Ӧ������ֵ�ع�����ͼ��)������ʾ(ѡȡ��һ����Ϊ����):


LLE��ά
�����ݾ߱�ijЩ�����Խṹ,�����νṹʱ,����ϣ����ά���������Ȼ������Щ�ṹ����ô�������LLE��ά�㷨��
LLE (Locally linear embedding):�����ݽ�ά����Ȼ����ԭʼ��ά���ݵ����˽ṹ,�������˽ṹ����Ϊ���ݵ�ľֲ��ڽӹ�ϵ��
���㷨��������ҪѰ��ÿ�����ݵ��k�������,Ȼ��ǰ���ݵ���k����������Ա���,��ô������Ե�Ȩ��ϵ����
����ϣ�������ڽ�ά�����ݵ�֮����Ȼ�ܱ����������Ա����Ĺ�ϵ,��������������һЩԼ��������ǰ����,���Ǻ�������ý�ά������ݡ�
����ԭ����ʽ�������кܶ��������úܺ�,���ﲻ���ˡ�
����ʱLLE�㷨���㷨����,����Ϊp*N����X,���Ϊd*N����Y�������ÿһ�ж���ʾһ������,ÿһ�ж���ʾ�����һ��������ʾ��

MDS��t-SNE
�����ɷַ���
�����ɷַ����ľ��������ǡ���β�ƻ����⡱(cocktail party problem)���������������Ǹ�������ź�,��η������β�ƻ���ͬʱ˵����ÿ���˵Ķ����źš�����N���ź�Դʱ,ͨ������۲��ź�Ҳ��N��(����N����˷����¼����)��
�Ⱦ�����ӳ��
��Ƕ��
���ѧϰ(һЩ��������)
���������������,�Ǿ��������;������˷�,�Եõ���������һ��ƫ�ú�,��Ƕ��һ�������,�õ�һ���µ����������µ������������Ϲ���,�͵õ��µ�һ�����硭�����Ľ�������ı�ǩ��ƫ��,����ͨ����ʽ����ȷ�ʽ,����Ȩֵ����,ʹƫ��ﵽ��С��ѵ�����������Ĺ���һ��ͽ������ѧϰ��
��������Ҫ���ǵ�ϸ�ھ��Ǿ���Ĺ�ģ,�����ѡʲô,�ڴ洦���ȵ����⡣
���ѧϰ�е�һЩ�������
һά����(��ɢ)
����һά����������,����һ������ʱ����ν��һά����,�Ǿ������л��������,��ͷ��ͷ,��β��β�Ĺ��̡����ǰ����������������л�,������Ԫ�ر���ÿ������,��ô���������������õ���ֵ��ÿ���������Ǽ���ÿ��ʱ�̻��ص����ֵĵ��,��ν�ĵ��,���Ƕ�Ӧλ�����˷������͡�����һ��ʱ������һ��gif����:
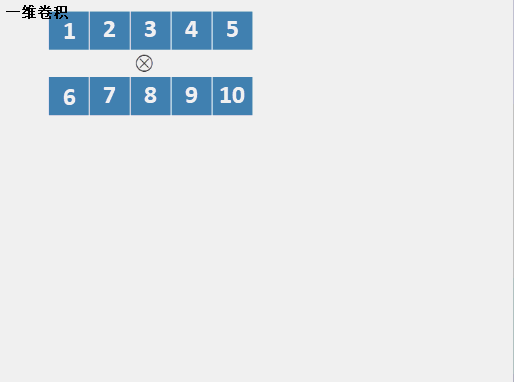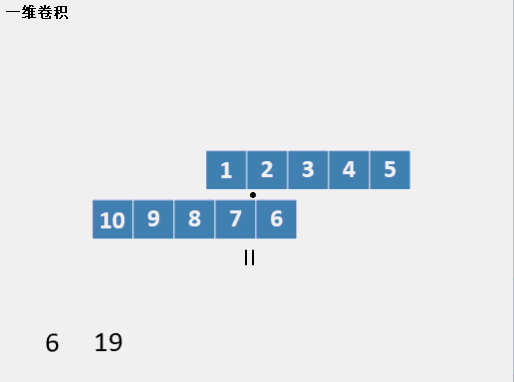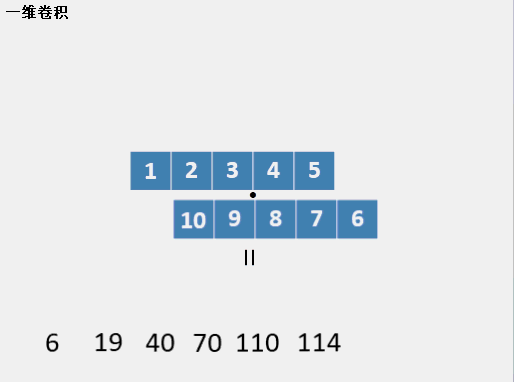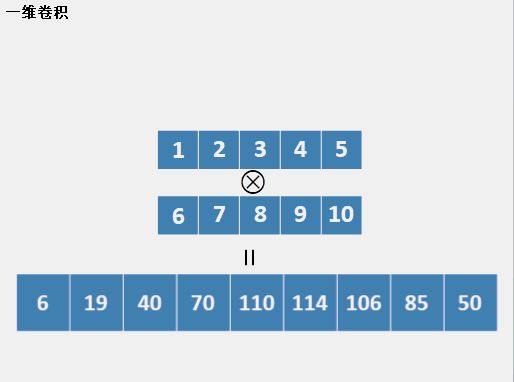
������Ҫע�����,���лij��Ȳ���,����һ���ȳ�,����ֻ��һ�ڳ���,Ҳ������һ�л������л��������ȡ�����,�����ij���=���ij�����+�̻ij�����-1����Ȼ,Ҳ�е�һά����ֻ���Ǽ���̻ͳ����ص����ְ����̻�ʱ��,����ν��û��padding����Ȼ,��������Ҳ���Բ���1��
��ά����(��ɢ)
������һά����,��ά��������ֻ����һά�����Ļ�����,��һά���ά���������䡣����һ����ν��С����(�����ˡ��˲���)ȥ��һ����˳��ȥɨԭ����,ÿ����ʱ�̡�����������һ�����,�õ�һ����ֵ������ͼ��ʾ:
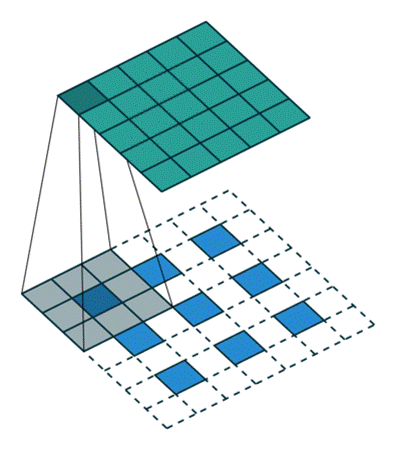
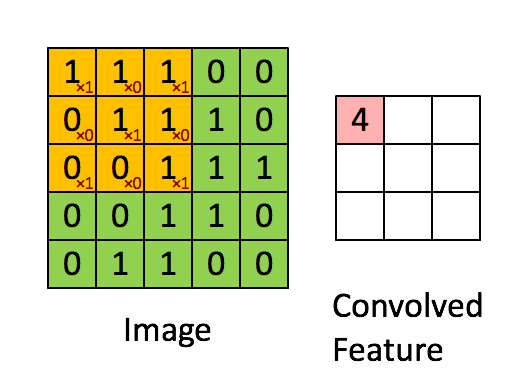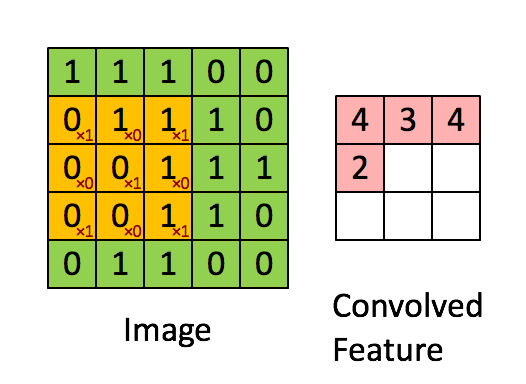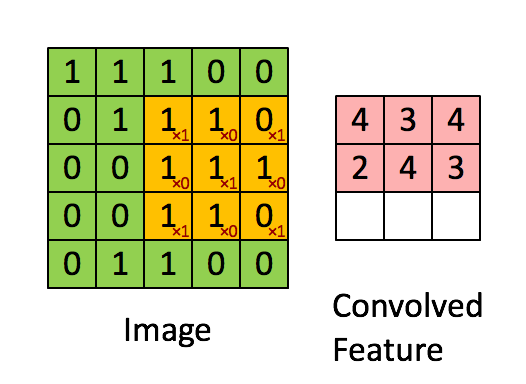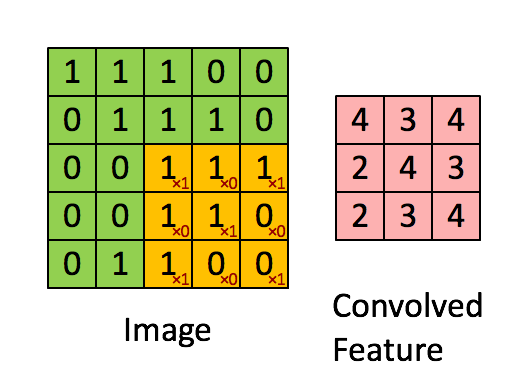
���Կ���,�ڴ������ֵĵط���ʼ��(û��padding)�Ļ�,�Ҳ���Ϊ1�Ļ�,�������ľ���߳�=�����߳�-С����߳�+1��
��ô,��ô����ʲô������?�ٸ�������,��������ȡ��Ե,����:
padding
��������,����˵padding,��ô��ν��padding����ʲô��˼��?һ����˵,Ϊ�˼�����Ϣ�Ķ�ʧ����������һЩĿ�ġ�padding��ʾ��ԭ���������߾���ı�Ե������ز�һЩ��,����˵��0(zero padding)��padding������ģʽ,valid��same��full��ʲô��˼��?
- **valid:**��ʾ�����,��ô�ڶ�ά�����,��ô�������size�Ϳ��Ա�ʾΪ:
out_height = ceil(float(in_height - filter_height + 1) / float(strides[1]))
out_width = ceil(float(in_width - filter_width + 1) / float(strides[2]))
�������ʽ�е� out_height ��ʾ����ĸ߶�,in_height��ʾ����ĸ߶�,filter_height ��ʾ�˲����ĸ߶�,strides��ʾ����(����ά��)��width�����ǡ�
Ҳ����˵������Ϊ1ʱ,�����valid(�����),��ô�������֮��,����ıߵij��Ⱦͻ��С �˲����ij���-1�����������Ϊ1,����������������Ļ�,�����Ҳ�����,ֱ��drop����
�ٸ�����,һά,���볤��Ϊ13,�˲�������Ϊ6,����Ϊ5��������������,�����˲�������,ֱ��drop����

- **same:**��ν����ͬ,�����,ʹ�����������ͼ�Ŀռ�ά�Ⱥ����������ͼ�Ŀռ�ά������ͬ��(��������ͼ�ĸ������ὲ��)����ʵ��,��仰ֻ�ǶԲ���Ϊ1��ʱ���������ȷ�ġ�
���������������������ȵı���ʽ,����������ͼ��ˡ�
out_height = ceil(float(in_height) / float(strides[1]))
out_width = ceil(float(in_width) / float(strides[2]))
��������Ҫ���ľ���,�����߾��ȵ����,ʹ�þ��������������������ȡ�һ������,���Ƕ��Ǿ����ܾ��ȵ����������,���Ҫ���ĸ���Ϊ������,ʵ�������ȵ����ػ�,����һ��ѡ�����ұ߶����һ����
��������õ�,������Ҫ������Ϊ,�Կ�Ϊ��:max{filter_width-in_width%strides[2],0},�ٷֺű�ʾȡ��,�ر��,in_width%1��ֵΪ1,����������֮��,ƽ�����䵽���ߡ�
����ټ�������:
1������Ϊ1,�������Ĺ�ģ��ԭ������ͬ,������same�ĺ��塣

����Ҳ���Կ���,�������Ϊ1�Ļ�,����������һ�����þ����˵����ķŵ������һ����ʼ��,�����Ļ�,�ܱ��־������Ĺ�ģ��ԭ����һ�����������������Ϊ1�Ļ��Ͳ�һ����,���Կ�����һ�����ӡ�
2��һά,���볤��Ϊ13,�˲�������Ϊ6,����Ϊ5����Ϊ13/6ȡ�Ͻ�Ϊ3,����Ҫ��һЩ���,ʹ�þ������Ķ�������Ϊ3����Ҳ��������ν��same��

- **full:**��ͼ��ʾ,������Ĵ�С��7x7,filter�Ĵ�С��3x3,full�͵�padding�����þ����������ľ����ڲ���ȫʧȥԭ����Ϣ�Ļ����Ͼ����ܴ�,��ν�IJ���ȫʧȥ,���������������˺�ԭ����������һ����ظ���
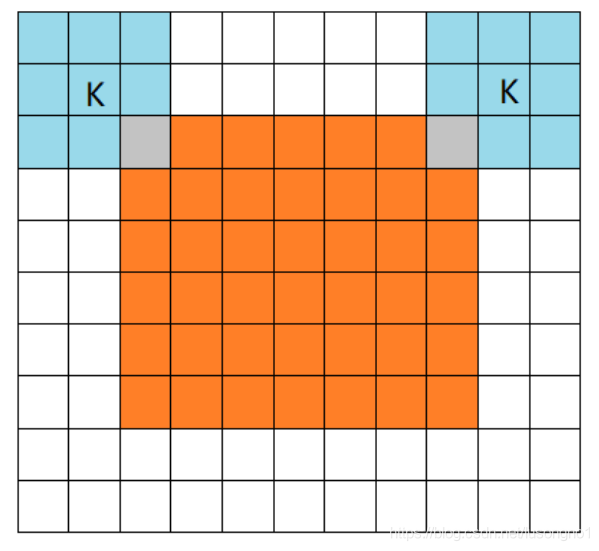
��ɫ����Ϊ����, ��ɫ����Ϊfilter��fullģʽ����˼��,��filter�����������ཻ��ʼ��������,��ɫ����Ϊ��0��
������(ת�þ���)
����Ҫ˵���������������ر��������顣һ�仰���;���:����������ھ���,����һ�������,ע��,����˵����,ֻ�ǹ�ģ�ϵ���,���������������»ָ�ԭ���������,������Ҳ�Dz����ܵġ�
ת�þ���,�Ѿ�����������������ȽϺ����⡣�ٸ�����:4x4������,����KernelΪ3x3, û��Padding / Stride, �����Ϊ2x2����ʱ,��������չ��Ϊ16ά����,���� x x x,��������չ��Ϊ4ά����,���� y y y����ô��������ɱ�ʾΪ y = C x y = Cx y=Cx����ʵ��, C C C���Ա�ʾΪ����:
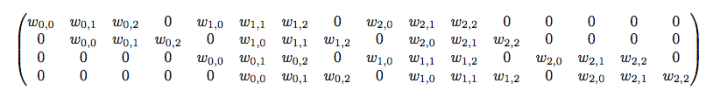
��ô,ת�þ�����ʲô��?û��,���� x ^ = C T y ^ \hat x = C^T\hat y x^=CTy^?��
������������ȷʵ��������,��������ԭ����(����)ʱ,������ô��һ�ֱ�����?�ܷ���ӻ�һ��?��ά�Ƚϳ���,��һά�ٸ����ӡ�����no padding,����Ϊ1�ľ���,�������ķ�������ʲô����Ϊ:
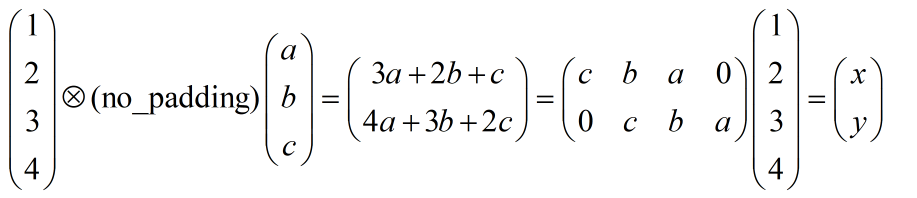
��������,��֪:
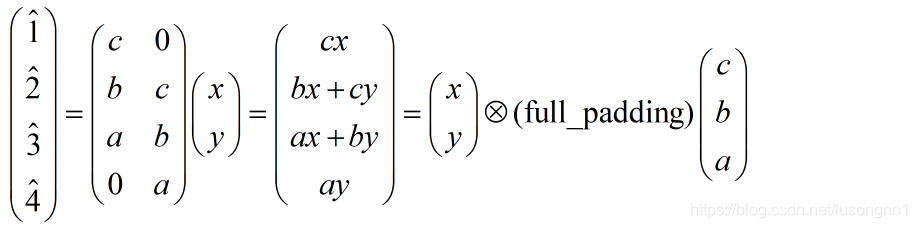
���Կ��ó���,��������µķ�����,��ʵ���ǰѾ����˵�����,Ȼ���������full_padding�ľ���������û�в��������,�������������в�������������貽����2,��Ȼ��û��padding�ľ���,������������������
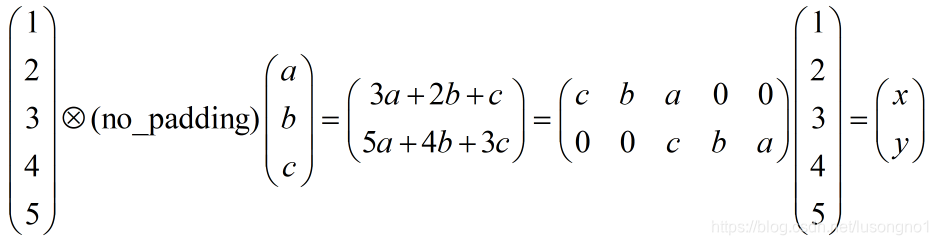
��������ʾΪ:
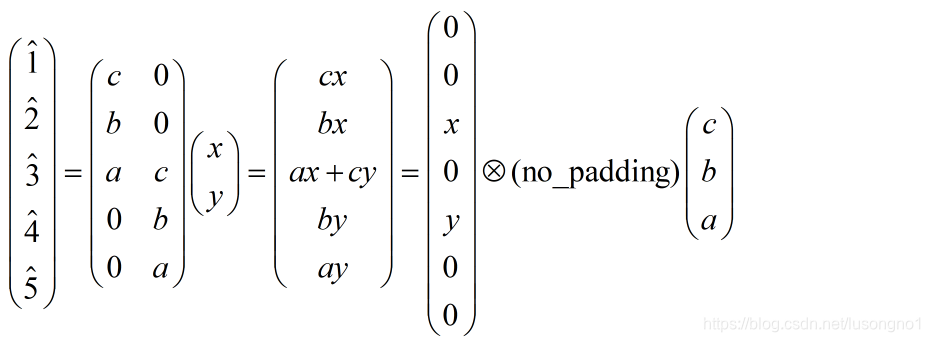
������һ��������������Ĺ���,������ν�ķ�����,���ǰѾ����˵�һ��,�����������һЩ0ֵ�ò岹,�����������ʽ�ľ���(same��full��)�����ǰ�����ƹ㵽��ά,����һ�¹�������:
- �����ǽ������˷�ת(������ת��,�����������ҷ�����е������)��
- �ٽ����������Ϊ����,����0�������,����ÿһ��Ԫ�غ��油0����һ���Ǹ��ݲ�������,����ÿ��Ԫ�����Ų�������(����-1)��0������,����Ϊ1�Ͳ��ò�0�ˡ�
- ������������������ٶ����岹0����ԭʼ�����shape��Ϊ���,����ǰ����ܵľ���padding����,����pading�IJ�0��λ�ü�����,�õ���0��λ�ü�����,�õ���0��λ��Ҫ���º����Ҹ��Եߵ�һ�¡�
- ����0��ľ��������Ϊ����������,��ת��ľ�����Ϊfilter,���в���Ϊ1�ľ���������
ע��:����padding������0ʱ,ͳһ����padding=��SAME��������Ϊ1*1�ķ�ʽ�����㡣
ͨ�����ϵĽ���,�����Ѿ������˽��˷����������Ĺ���,�����漸��ͼ�ܹ����õذ������⡣
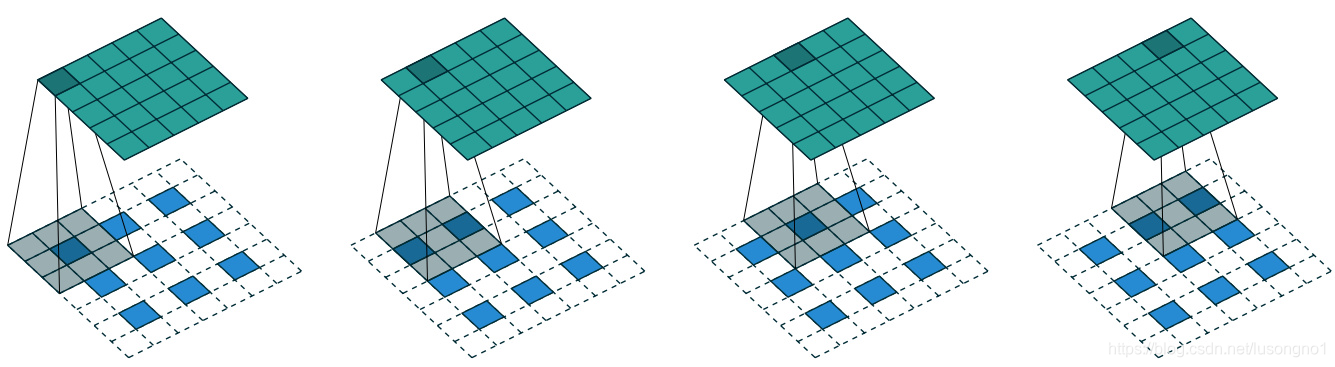
��ͼ�Dz���Ϊ2�ķ�������һ��ͼʾ,����ɫ�ڲ�����0��,��Ҫ����5��same padding,������Ҫ����ɫ�ⲿҲҪ��padding�������ɫ�Ǹ��Ǿ�����,��ʾԭ�����˵�һ�����µߵ�,���ҵߵ�����Ȼ,���������кܶ��һ������,�ܽ�����Ϊһ�¼���:
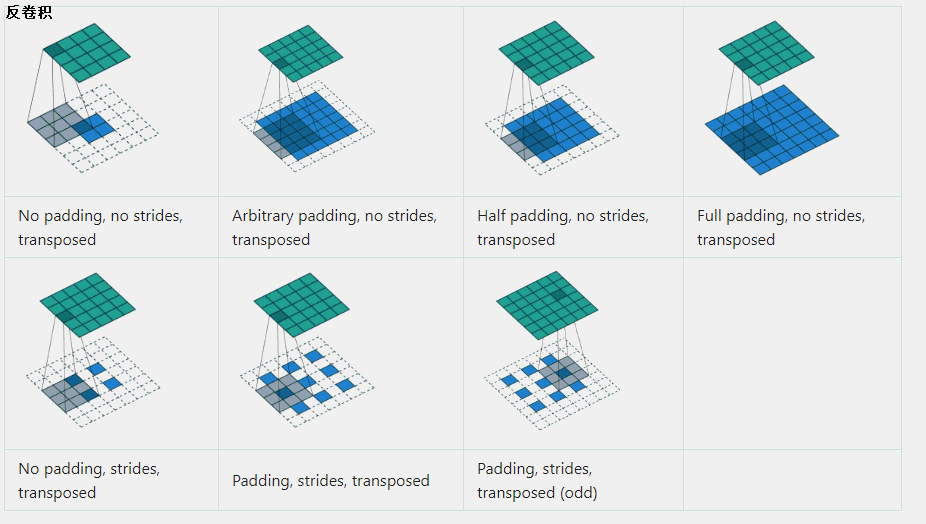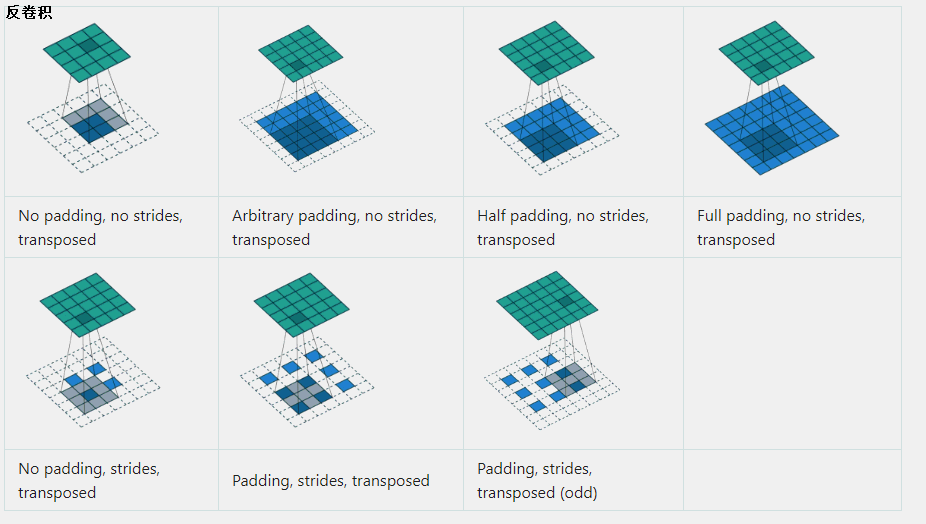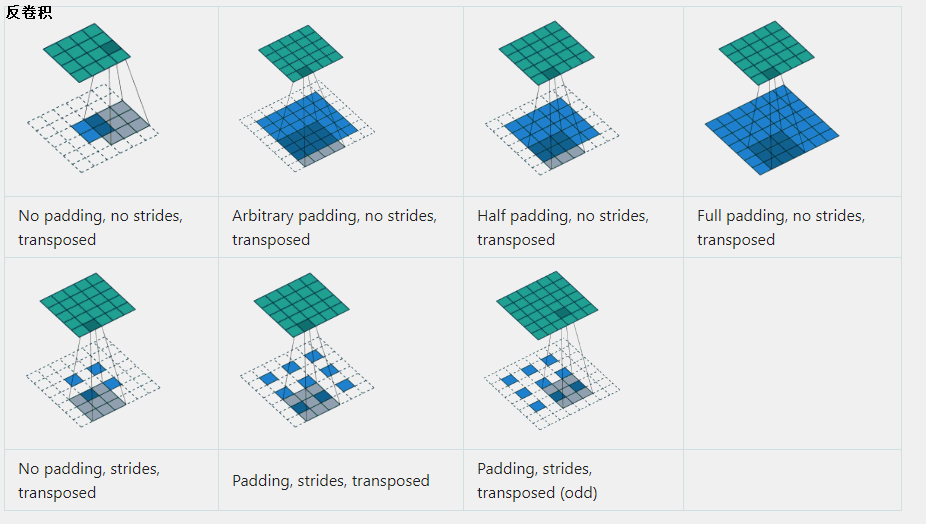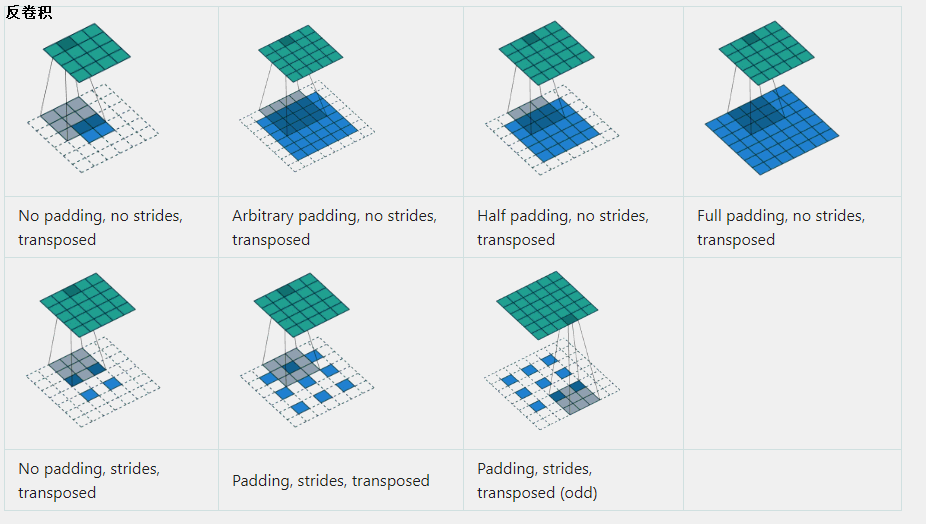
������,��������Ϊ���������������㡣ǧ��Ҫ���ɷ������������Ը�ԭ��������������ֵ,��������û���Ǹ�����,�������ǽ������任�����еIJ��跴��任һ�ζ���,ͨ����������ת��,�������Ľ������һ�����,���������и����ֽ�ת�þ�����
��Ȼ�����ܻ�ԭ��ԭ������������,�����������Ͼ������Ƶ�Ч��,���Խ�����С����ȱʧ����Ϣ��ָ�,Ҳ���������ָ����������ɺ��ԭʼ���롣
ѧϰ��
�����ݶ��½��IJ�����
����
Ӧ���ݶ��½�����,��Ҫ����,�����ķ���,�з���,��ʵ������ʽ����
����
��������Թ���϶������,��������ģ�Ͳ��������ķ���,��Ϊ�˽���ģ�͵ĸ��Ӷȡ�һ����Ż�����ֻ����С���������,�������ڴ˻����ϼ���ģ���Ӷ���һ�����һ���ı�����������һ���ϵ����������һ��,���Է�ֹģ��ѵ�����ȸ���,��Ч�Ľ�����ϵķ��ա�
��������,��߷��������ķ�����:
- L1��L2����
- ���ֹͣѵ��
- ���ݼ�����
- dropout
- ����
����(Regularization)����L1����L2����������ʵ������ԭ�е�loss funtion�������Ȩ�ء�
L2����(Ȩ��˥��)Ϊ:
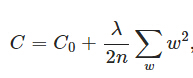
��Ȩ����,�ɵ�:
 ����������Ȩ�ص�һ��˥����
����������Ȩ�ص�һ��˥����
L1����Ϊ:
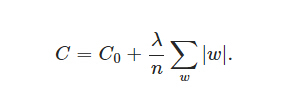
���Ҳ���������Ƶ���
L����,�е㷣������ζ��,������Ϊ��Ȩ�ؼ��뵽��ʧ������,�;���ʹ��Ȩ�ؾ���С�ˡ������ձ���Ϊ:��С��Ȩֵw,��ij��������˵,��ʾ����ĸ��Ӷȸ���,�����ݵ���ϸոպ�(�������Ҳ�����¿�ķ�굶)��
��������������˹�ֲ����� L1 ����,�������Ӹ�˹�ֲ�,���� L2 ����
softmax
softmax��һ�ֹ�һ��,���ĺô�����ʹ�ü����Ϸdz�����,˭��˭֪����
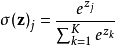
Softmax�����,Ч������,�dz����á���Ҳ�ܻ���ֲ���ֵ�����⡣
dropout
��ν��dropout,������һ���ĸ���p(����˵0.5)�Ȱ����ز�IJ��ֽڵ������(֮���Խв�����,����Ϊ��֮��ص�Ȩ��һֱ����,ֻ�Dz�����,��һ��ѡ���ʱ��,������صĽڵ���ʾ������,��֮��ص�Ȩ�ػ��DZ���ԭ����Ȩ��),���һ���Ƚ�С������,��������Ƚ�С������ѵ��,ѵ����һ���̶Ⱥ�,��Щ��ʾ�ڵ��Ȩ������������,��ʱ����ʾ���ؽڵ�,�����Ը���p����ѡ�����������������,֪��ѵ����һ�����硣���Ե�ʱ��,�õ������еĽڵ�,ֻ����Ȩ�صó���p��
���Ļ�����������:
- �������(��ʱ)ɾ��������һ���������Ԫ(���ݱ�ɾ����Ԫ�IJ���),���������Ԫ���ֲ���(ͼ������Ϊ������ʱ��ɾ������Ԫ)��
- �����ĺ������,ʹ��һС��ѵ������ȥѵ��,������ݶ��½������¶�Ӧ�IJ�����
- �ָ����ص���Ԫ,�����ָ�������ص�ԭ���IJ���,�ظ���������(��ʱ��ɾ������Ԫ����ԭ��,��û�б�ɾ������Ԫ�Ѿ���������)��
dropout��һ����Ч�ķ�ֹ����ϵķ���,����Ҳ��Ϊ�˼��ټ����������ǻ������ϵļ���֮һ��
dropoutҲ��һ�ּ���,��ͼ:
���൱��ѵ��ʱ�������������Ԫ,����ʱ����������Ԫ��dropoutΪʲô��work��?�����Ҷ�û��һ���ܺõĽ��͡�������,��ʱ��,�ϰ彻��������,�����˵������������,�ܱ�������һ�������Ҫ��,�е㡰��������ûˮ�ȡ�����˼,��Ҳ���Ǿ��Եġ�
��ʷ

����ݶ��½�(mini-batch)
����֪��,�����мල��������,��һ����ʧ����,��������ģ�͵ĺû����ڻع�������,��������Ѿ�֪�����̵���ʽ,���ǿ��������������ʧ��������ô����Ҫ���ľ���Ѱ�ҷ��̵���Ѳ���,��Ѱ�Ҳ���,ʹ����ʧ���������ﵽ��С��էһ��,����Ǹ��Ż����⡣��Ȼ���ԶԲ����ĸ���������,���ⷽ���顣������,����ȷ�����ķ�����ý�?һ�����ֵ�ⷨ���ݶ��½�����ţ�ٷ�����ţ�ٷ����Լ��������ȵȡ��ݶ��½�����������,���ǵ��������Ƚϴ�ʱ,�ݶ��½��ļ�����ر��
Ϊ��������������Ż����,����һ����Բ�������ݶ��½�����ν������ݶ��½�,��������ݶ��½�,���Dz�ѡ��ȫ�������ݵ�,����ÿ�����ѡ��һ���������ɸ����ݵ�(һ�����ݵ�)��������ʧ����,���������ݶ��½�������⡣�������ܲ���������,��ʵ�϶��������������,���ǿ������������Ž��ij������ġ�
���бƽ�����
-
���һ����������㹻�����Ԫ,����ǰ��������(����-����
-���)�������⾫�ȱƽ�����Ԥ�������������� -
�������㹻��ʱ,˫�����֪��(����-����1-����2-���)���Ա�
���������������:���Խ���κθ��ӵķ������⡣
���ּ����
���ü��������:
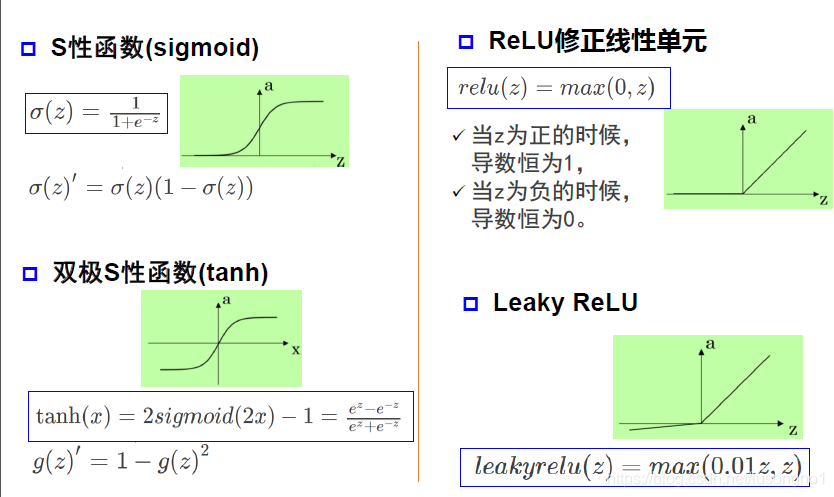
��
����Ŀ����ȥ���������ݵ�������Ϣ������ѵ��������ͼ��,����ͼ������������֮����к�ǿ�������,��������ѵ��ʱ����������ġ�����Ŀ�ľ��ǽ�������������ԡ�
��ν��,���Ƕ��������ݷֲ��任����ֵΪ0,����Ϊ1����̬�ֲ�,��ô������Ͽ�������BNҲ��Դ������뷨��
��������

�ݶ��½�,һ�������ŵ�ǰ��ĸ��ݶȷ�����һС��,����һ��,�����Ǹ��Ǹ���ĸ��ݶȷ�����һ��,��ô��������ͣͣ,�������ߵú�����
 ])
])
��һ��������С����½�Ҫ�����������,��A�������B���ʱ��,С�����һ���ij��ٶ�,�ڵ�ǰ���ٶ��¼��������½�,С���Խ��Խ��,����ı���ȵס�momentum����������ģ����һ������������������Ż��ġ�
���Ļ����㷨����:
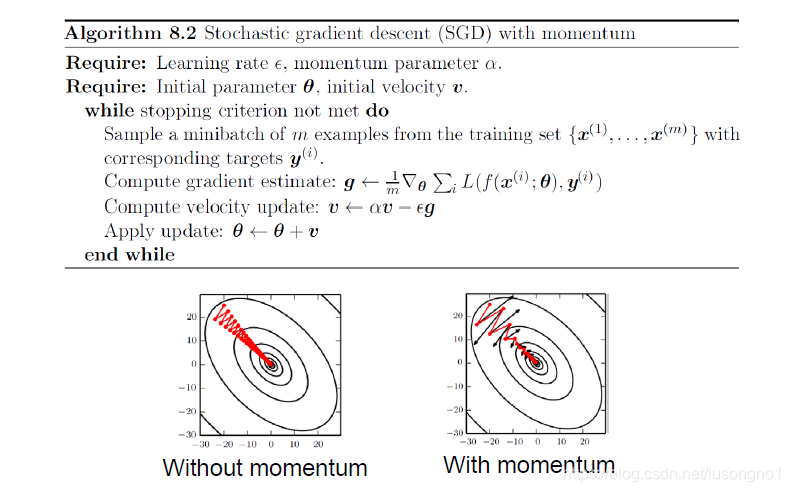
��Ϊ�ؼ���һ������,�ߵIJ��� v n v_n vn?(��Ϊ�ٶ�)���ɵ�ǰ�ĸ��ݶȷ����ǰһ�����ٶ� v n ? 1 v_{n-1} vn?1?��������ϵõ��ġ�ǰһ�����ٶ��ֺ�ǰǰ�����ٶ��й�,�Դ�����,�Ͱ��ٶȻ��������ˡ�Ҳ����˵,��ǰ�����ߵķ���Ͳ���,��Ҫ�ۺϿ���֮ǰ���е��߹��IJ��ķ���Ͳ���������֪��,������������Ҷ��������������ٵ���,��ϰ�߰�֮ǰ��ֵ������Ȩƽ��,���������ͻ��ܶ�,monmentum������е������˼������Ϊ�˽��һ��SGD����һֱ���ٳٲ������������
���������е���CG,Ҫ���֮ǰ����Ϣ��
�����غ�KLɢ��
�����غ�KLɢ���Լ�JSɢ�ȶ��Ǻ��������ֲ�(����)�ľ����һ�ֶ�����
������:
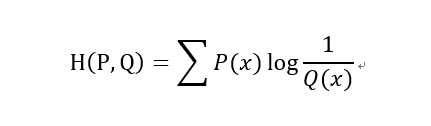
KLɢ��(KL����,�����):
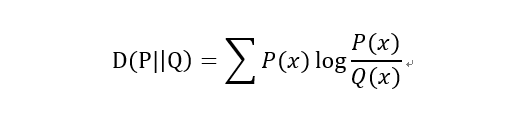
JSɢ��(JS����,KLɢ�ȵı���):
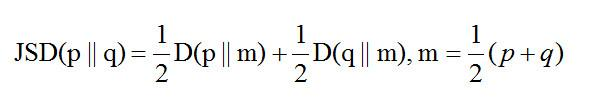
batch normalization
��ν��batch normalization(������һ������������)���ǡ���ȥ��ֵ,���Է���ı�������,����һ����̬�ֲ���ɱ���̬�ֲ�������˼�������ÿ������ڵ�ļ�������ֲ��̶�����,������ѵ���ٶȡ�
����ʲô����?����Ҫ��Ϊ��**�����ݶ���ʧ,����������**�����������������ص���ֵΪ0,����Ϊ1������,������ÿ�����������(-1,1)����,��θպ��Ǽ����������õ��������Ƿֲ���ø��Ӿ���,�Ӷ��ݶȷ�����ӽ���ֵ�㷽��,����ͼ:
����,��Ҳ�˷��������ܲ�ͬ��ֵӰ��ϴ��ȱ�㡣�ٽ��������ȶ��Է�չ:ʹ��ͬ����Զ���,ÿһ�����רע�����������⡣
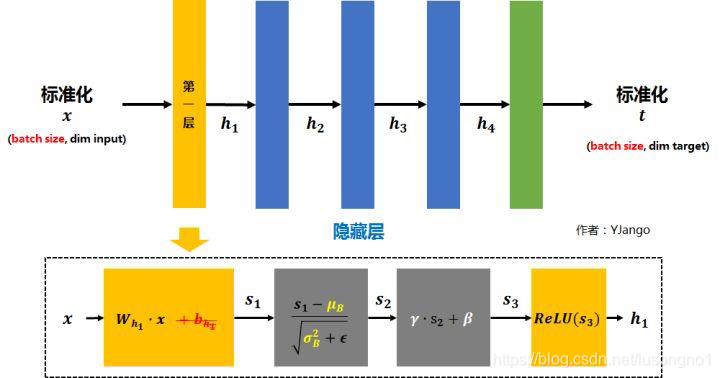
maxout
maxout��һ�����͵ļ����,�ܹ������ݶ���ʧ,�����ReLU��Ԫ���������,�����ӵIJ����ͼ�����������ʵ������ԭ�м���Ļ�����,ȡ�����ֵ,������ʾ:
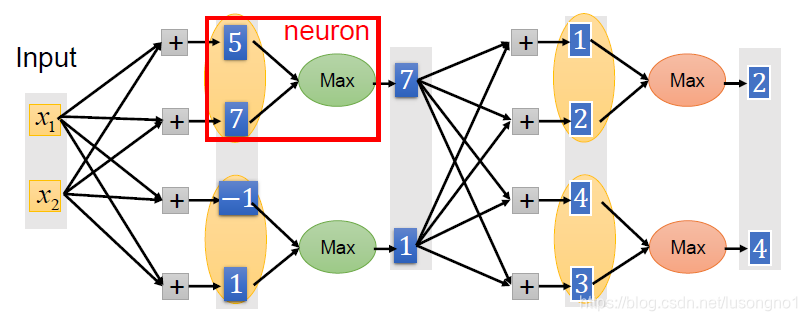
��Ȼmaxout��һ������,��ô��������,�����ʲô?����ͼ���������?
�����������maxout�IJ���k=5,maxout���������ʾ:
�൱����ÿ�������Ԫǰ���ֶ���һ�㡣��һ����5����Ԫ,��ʱmaxout�����������㹫ʽΪ:
z1=w1*x+b1
z2=w2*x+b2
z3=w3*x+b3
z4=w4*x+b4
z5=w5*x+b5
out=max(z1,z2,z3,z4,z5)
���������Ϊʲô����maxout��ʱ��,����������k�����ӵ�ԭ��������ֻ��Ҫһ���������,����maxout��,����Ҫ��k�������
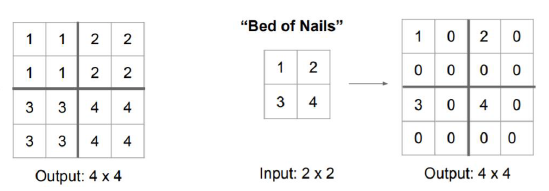
�ϲ������²���
�²������DZ�С����,�ϲ������Ǿ��DZ�����,�е㡰��ֵ������˼��
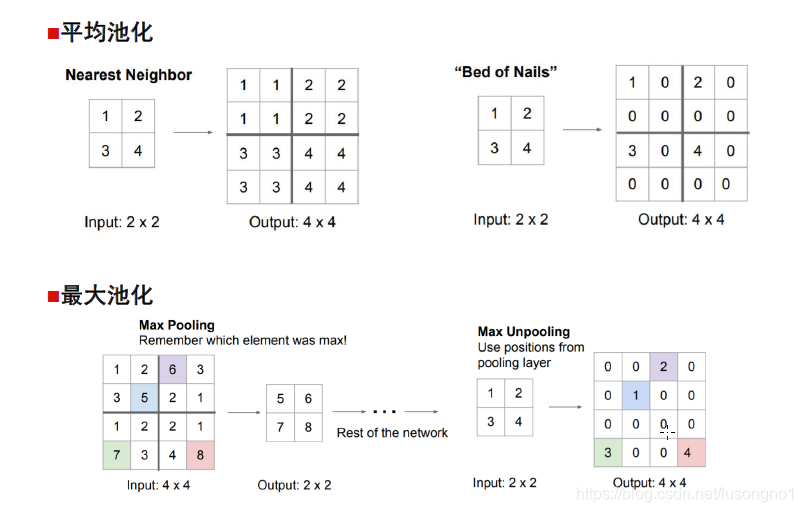
һ����˵�²���ָ�ľ��dzػ����ϲ�������unpooling��ת�þ���(transpose convolution)��һ��IJ�ֵ�ȡ�unpooling���Ƿ��ػ�,�ڳػ�������,��¼��max-pooling�ڶ�Ӧkernel�е�����,�ڷ��ػ�������,��һ��Ԫ�ظ���kernel���зŴ�,����֮ǰ�����꽫Ԫ����д��ȥ,����λ�ò�0 ��
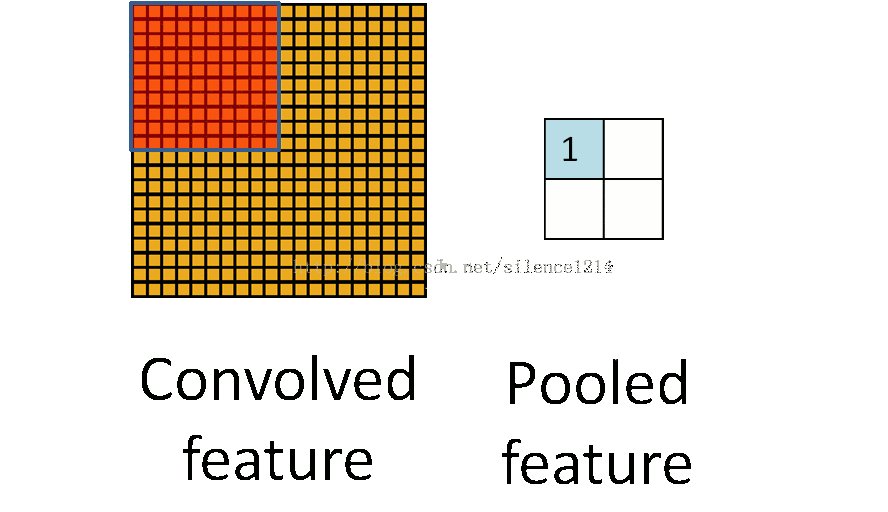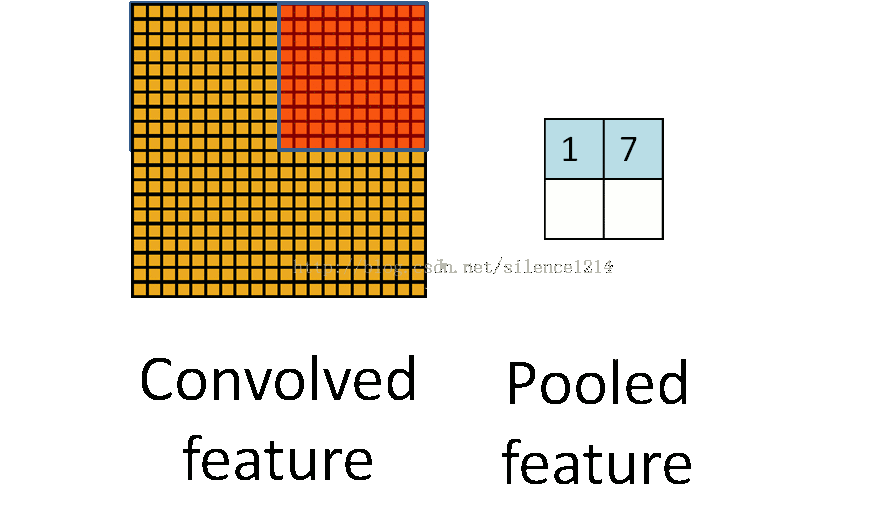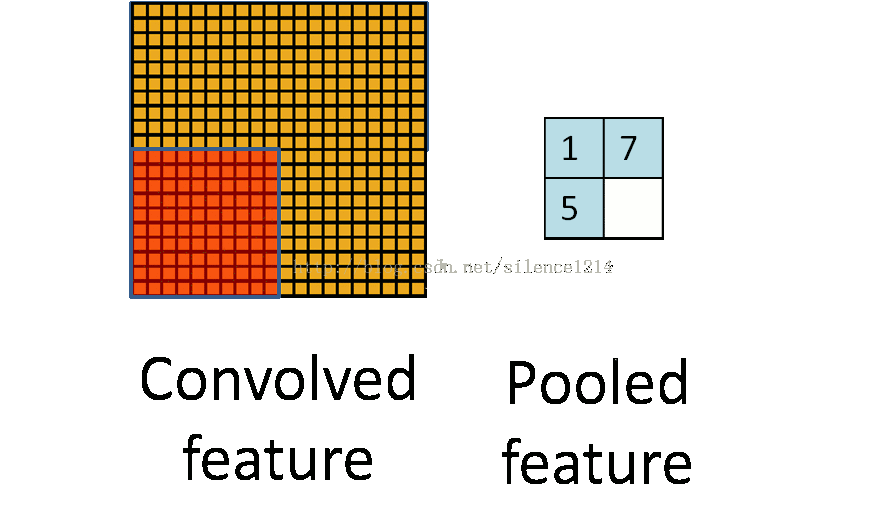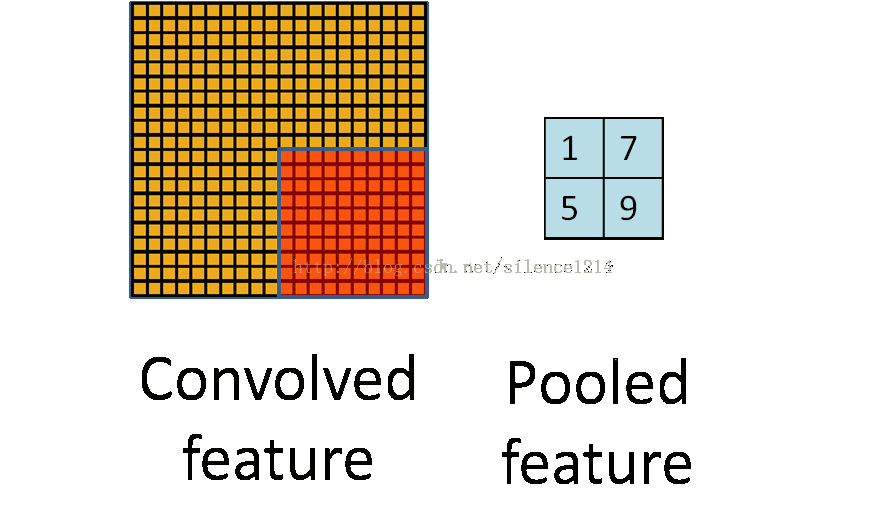
�ػ�
�ػ�������ͼ��ÿ����������²���,��Ϊ�������ĸ������ػ�����ƽ���ػ�mean-pooling�����ػ�max-pooling����ν�ijػ�,��ʵ���ǽ�����ֿ�,��ÿ��ȥƽ��ֵ�������ֵ��
Ԥѵ��
��������Ҫ���һ�����ӵ�����,��û��̫��ı�ǵ�ѵ������,�����ҵ���,�㲻���ҵ�һ�����Ƶ�����ѵ��ģ�͡� ��Ҫʧȥ����ϣ��! ����,�㵱ȻӦ�ó����ռ�������б�ǩ��ѵ������,���������̫�ѻ�̫����,����Ȼ���Խ����ල��ѵ���� Ҳ����˵,������кܶ�δ��ǵ�ѵ������,����Գ������ѵ����,����Ͳ㿪ʼ,Ȼ������,ʹ���ල����������㷨,�����Ʋ���������(RBM)���Զ��������� ÿ���㶼��ѵ������ǰѵ�����IJ�����(���˱�ѵ���IJ�֮������в㶼������)�� һ�����в㶼�����ַ�ʽ������ѵ��,�Ϳ���ʹ�üලʽѧϰ(������)�������������
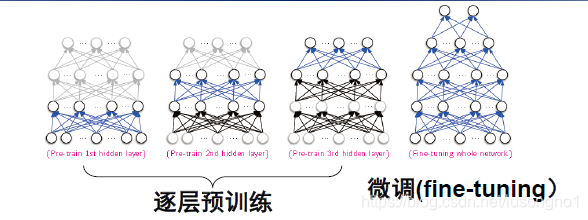
Ȼ��,ò�����������ѧϰƽ̨��������֧��RBM��Ԥѵ��������,�������
Ԥѵ����û��̫��ߵ������,�ܹ�����ݶ���ʧ�;ֲ���ֵ,ѵ������,ѵ��ʱ�䳤�����⡣����������������ݶ���ʧ�����⡣
�Ա����
�Ա�������ʵ��ͨ��������,ѧ���ع��Լ��Ĺ��̡�
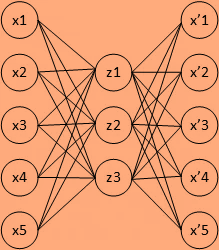
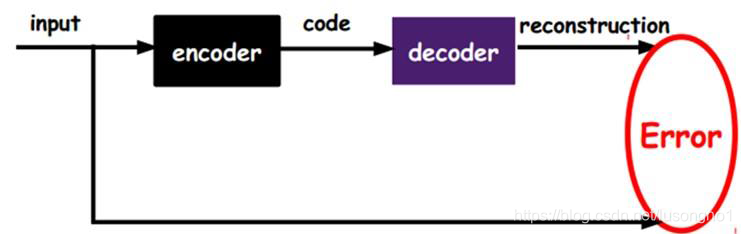
�Ա�����(autoencoder)���������������ͬ(target=input),��һ�־����ܸ��������źŵ������硣��input����һ��encoder������,�ͻ�õ�һ��code,��һ��decoder������,�����Ϣ��ͨ������encoder��decoder�IJ���,ʹ���ع������С������һ�ַǼලѧϰ,��Ϊ�ޱ�ǩ����,������Դ��ֱ���ع����ź���ԭ������ȵõ���
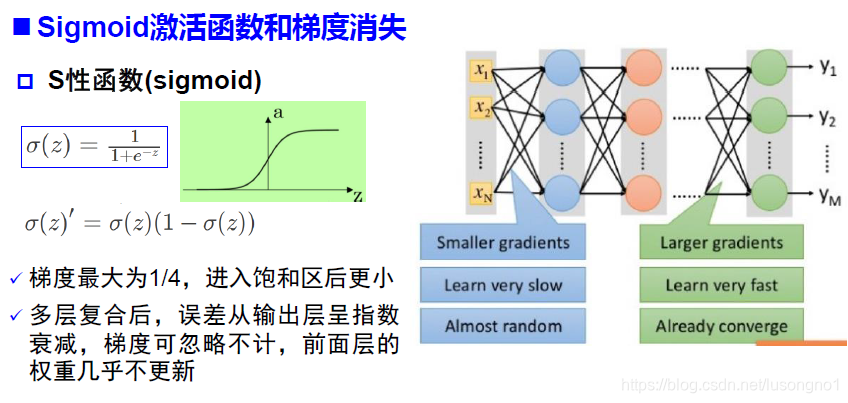
�ݶ���ʧ(��ը)�;ֲ���ֵ
��ν���ݶ���ʧ,������˵,��������ݹ�����,sigmoid���´��ݵ��ݶȰ�����һ��f��(x) ����(sigmoid��������ĵ���),���һ���������뱥����,f��(x) �ͻ��ýӽ���0,��������ײ㴫�ݵ��ݶ�Ҳ��÷dz�С����ʱ,����������ѵõ���Чѵ������������Ϊ�ݶ���ʧ��һ����˵, sigmoid ������5 ��֮�ھͻ�����ݶ���ʧ����Relu����������Ч�������������
��֮,��μ�����������Ժܴ��������Ȩ�ز���w,��ô��Ϊ�˻�����1,�ͻᷢ���ݶȱ�ը����
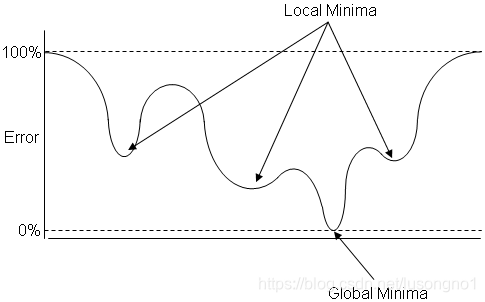
�ֲ���Сֵ�ܺ�����,��Ϊ���Ƶĺ�����,����������ֲ���ֵ��
Flatten
Flatten�����������롰ѹƽ��,���Ѷ�ά������һά��,�����ڴӾ����㵽ȫ���Ӳ�Ĺ��ɡ���ʵ���ǰѾ�������һ����
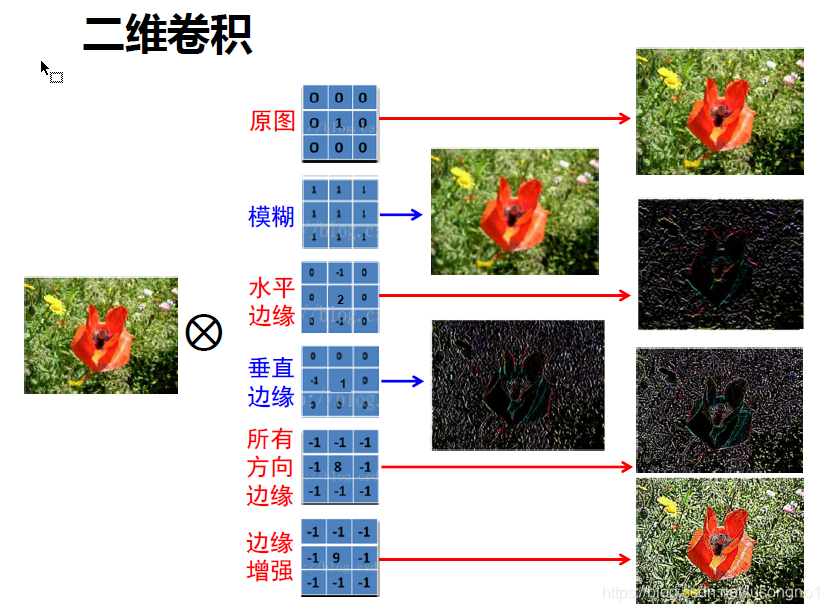
����ͼ
������ά������,���˲�����һ�εõ��Ľ������һ������ͼ,��ͬ���˲���,����ξ��������ͻ�õ��������ͼ���˲������Ǿ����ˡ�
ǿ��ѧϰ
ǿ��ѧϰ������ʲô?���������˽�ǿ��ѧϰ��ŵ���˼�Ͳ���,����һ������֪ʶ,�����������о�,����ƪ���¾ͺܹ��ˡ�
��������
Ԫ�ؼ��
ǿ��ѧϰ������Ƕ���һ������(������),��һ��״ִ̬��ij�ֶ�������һ��״̬,�������������,����һ���Ľ��ͻ��߳ͷ�,�������������õķ���ȥ����������Ϸ�ŵ�ѱ��ʦ,�������,������ֺ�,����һ��Ե�,������ֲ���,�ͳ���������,ʹ�������,�ܹ���һϵ�г�ɫ�ı��֡�
Ϊ��˵����������,������Ҫ����һ��״̬�ռ� S S S�������� A A A��״̬ת�Ƹ��� P P P�ͽ��� R R R��
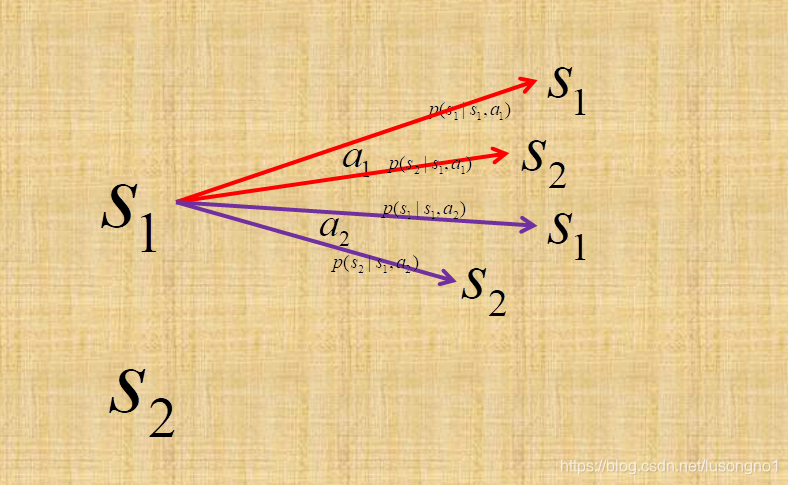
��ͼ��ʾ,״̬�ռ��ʾ����״̬��һ������,��������ʾ���ж�����һ�����ϡ�
״̬ת�Ƹ�����һ������,��ʾ�ڵ�ǰ״̬ s s s��,ִ��ij������ a a a֮��,ת�Ƶ�ij��״̬�ĸ���,�� P : S �� A �� S ? R P : S \times A \times S \mapsto \mathbb{R} P:S��A��S?Rָ����ת�Ƹ��ʡ���������˵״̬ s 1 s_1 s1?��,ִ�ж��� a 1 a_1 a1?,����ת�Ƶ� s 1 s_1 s1?,Ҳ����ת�� s 2 s_2 s2?,���߸��ʲ�ͬ��ͼʾ s 2 s_2 s2?Ҳ�ǿ�����һ���ĸ���ִ����Ӧ�Ķ���,ִ����Ӧ�Ķ���,����һ���ĸ���ת�Ƶ���ͬ��״̬,Ϊ��ͼʾ����,û�л�������
R : S �� A �� S ? R R : S \times A \times S \mapsto \mathbb{R} R:S��A��S?Rָ���˽��͡�������Ͳ�������ʼ״̬�Ͷ����й�,Ҳ�Ͷ���ִ�к�ﵽ��״̬�йء�
����һ���Dz��Ժ��� �� \pi ��,����ʾ����һ��״̬,��Ӧ��Ҫִ��ʲô����,��Ȼ,�����ִ�еĶ�����ȷ��,������һ������ִ����Ӧ�Ķ���,��ô �� \pi ����ʵ���Ƕ�Ӧ�ڶ����ĸ��ʺ���,���� �� ( s , a ) \pi(s,a) ��(s,a)��ʾ��״̬s��ѡ����a�ĸ��ʡ�Ҫ�� �� a �� ( s , a ) = 1 \sum_{a} \pi(s, a)=1 ��a?��(s,a)=1��
�Ż�Ŀ��:״ֵ̬����
����һ������ �� \pi ��(������Բ�һ�������ŵ�),��ô����ִ�ж����IJ�������(��Ϊ T T T��)������ʱ��,���Ƿֱ���״ֵ̬����:
{ V T �� ( s ) = E �� [ 1 T �� t = 1 T r t �O s 0 = s ] V �� �� ( s ) = E �� [ �� t = 0 + �� �� t r t + 1 �O s 0 = s ] \left\{\begin{array}{l}{V_{T}^{\pi}(s)=\mathbb{E}_{\pi}\left[\frac{1}{T} \sum_{t=1}^{T} r_{t} | s_{0}=s\right]} \\ {V_{\gamma}^{\pi}(s)=\mathbb{E}_{\pi}\left[\sum_{t=0}^{+\infty} \gamma^{t} r_{t+1} | s_{0}=s\right]}\end{array}\right. {VT��?(s)=E��?[T1?��t=1T?rt?�Os0?=s]V����?(s)=E��?[��t=0+��?��trt+1?�Os0?=s]?
���״ֵ̬��������˼�����ڵ�ǰ״̬ s s s��,ƽ���ۻ����͵�һ����ѧ����,����һ������,���ڲ�ͬ��״̬ s s s,���в�ͬ��ֵ���������������ʱ��,���Ƕ���һ���ۿ����� �� \gamma ��,ʹ�þ���ԽԶ�ĵط�,���͵Ķ��ۻ�����Ӱ��ԽС���������ѧ����,��ʵ�����㺬��,һ����ָ������֮��,���ܻ��Բ�ͬ�ĸ���ת�Ƶ���ͬ��״̬,������һ����������һ����,����״̬ s s s����,���� �� ( s , a ) \pi(s,a) ��(s,a)�ĸ���ִ�в�ͬ�Ķ���,���ڲ�ͬ�Ķ���������һ��������
����,������Ҫ����,��ʵ������취��һ������,ʹ�����״ֵ̬�����ﵽ����������ǵ�Ŀ�ꡣ
��������Ż�Ŀ��,��������������������Ż�Ŀ�ꡣ
��������ģ����֪�����,��״̬�ռ�,�����ռ�,ת�Ƹ��ʺͽ������Ƕ���֪���ġ���ģ�Ͳ�����֪�������,����˵����Reward�����,���ǿ���ʹ��ģ�ؿ���ķ���,��������������ζ���,�����ۻ��ر�,���ƽ�����õ�������Ҫ�Ľ���ֵ��̰���㷨���ڡ�̽����(exploration)�͡����á�(exploitation)֮��ȡһ������,��ν��̽��,��ʵ������Ƶ���������,��������ʵ��,ȡƽ��ֵ,����Ϊ������Ҫ��ֵ������,��ν������,�����ڲ�����ѡ���������Ķ�����
�����������,����ijһ��ָ���IJ��� �� \pi ��,��Ϊģ����֪,����״ֵ̬����������ѧ�����Ķ�����Խ��в�ֺ�ȫ����չ��:
V T �� ( s ) = E �� [ 1 T �� t = 1 T r t �O s 0 = s ] = E �� [ 1 T r 1 + T ? 1 T 1 T ? 1 �� t = 2 T r t �O s 0 = s ] = �� a �� A �� ( s , a ) �� s �� �� S P ( s �� �O s , a ) ( 1 T R ( s �� �O s , a ) + T ? 1 T E �� [ 1 T ? 1 �� t = 1 T ? 1 r t �O s 0 = s �� ] ) = �� a �� A �� ( s , a ) �� s �� �� S P ( s �� �O s , a ) ( 1 T R ( s �� �O s , a ) + T ? 1 T V T ? 1 �� ( s �� ) ) \begin{aligned} V_{T}^{\pi}(s) &=\mathbb{E}_{\pi}\left[\frac{1}{T} \sum_{t=1}^{T} r_{t} | s_{0}=s\right] \\ &=\mathbb{E}_{\pi}\left[\frac{1}{T} r_{1}+\frac{T-1}{T} \frac{1}{T-1} \sum_{t=2}^{T} r_{t} | s_{0}=s\right] \\ &=\sum_{a \in A} \pi(s, a) \sum_{s^{\prime} \in S} P(s^{\prime}|s,a)\left(\frac{1}{T} R(s'|s,a)+\frac{T-1}{T} \mathbb{E}_{\pi}\left[\frac{1}{T-1} \sum_{t=1}^{T-1} r_{t} | s_{0}=s^{\prime}\right]\right) \\ &=\sum_{a \in A} \pi(s, a) \sum_{s^{\prime} \in S} P(s^{\prime}|s,a)\left(\frac{1}{T} R(s'|s,a)+\frac{T-1}{T} V_{T-1}^{\pi}\left(s^{\prime}\right)\right) \end{aligned} VT��?(s)?=E��?[T1?t=1��T?rt?�Os0?=s]=E��?[T1?r1?+TT?1?T?11?t=2��T?rt?�Os0?=s]=a��A��?��(s,a)s����S��?P(s���Os,a)(T1?R(s���Os,a)+TT?1?E��?[T?11?t=1��T?1?rt?�Os0?=s��])=a��A��?��(s,a)s����S��?P(s���Os,a)(T1?R(s���Os,a)+TT?1?VT?1��?(s��))?
�������������,Ҳ��������չ���õ����½��:
V �� �� ( s ) = �� a �� A �� ( s , a ) �� s �� �� S P ( s �� �O s , a ) ( R ( s �� �O s , a ) + �� V �� �� ( s �� ) ) V_{\gamma}^{\pi}(s)=\sum_{a \in A} \pi(s, a) \sum_{s^{\prime} \in S} P(s^{\prime}|s,a)\left(R(s'|s,a)+\gamma V_{\gamma}^{\pi}\left(s^{\prime}\right)\right) V����?(s)=a��A��?��(s,a)s����S��?P(s���Os,a)(R(s���Os,a)+��V����?(s��))
������������,���Ҿͽ���ֵ�����ݹ鷽��(Ҳ�б���������?)����ֵ�����ݹ鷽���Ͽ�,���ǿ���֪��,��ģ����֪,������֪�������,������ʵ�ǿ��Եݹ������ڸò����¸���ʱ�̵�״ֵ̬������Ҳ����˵,��ֵ�����ij�ʼֵ V 0 �� V^\pi_0 V0��?����,ͨ��һ�ε�����ø���״̬��һ������ V 1 �� V_1^\pi V1��?,������ͨ��һ�ε������ V 2 �� V_2^\pi V2��?����
״̬-����ֵ����
״̬-����ֵ��ʾ������ij״̬��,ִ�ж��� a a a���һ��ƽ���ۻ����͡�����״ֵ̬�������,��Ϊ����������,���Բ��ټ�����ڶ�������������:
{ Q T �� ( s , a ) = �� s �� �� S P ( s �� �O s , a ) ( 1 T R ( s �� �O s , a ) + T ? 1 T V T ? 1 �� ( s �� ) ) Q �� �� ( s , a ) = �� s �� �� S P ( s �� �O s , a ) ( R ( s �� �O s , a ) + �� V �� �� ( s �� ) ) \left\{\begin{array}{l}{Q_{T}^{\pi}(s, a)=\sum_{s^{\prime} \in S} P(s^{\prime}|s,a)\left(\frac{1}{T} R(s'|s,a)+\frac{T-1}{T} V_{T-1}^{\pi}\left(s^{\prime}\right)\right)} \\ {Q_{\gamma}^{\pi}(s, a)=\sum_{s^{\prime} \in S} P(s^{\prime}|s,a)\left(R(s'|s,a)+\gamma V_{\gamma}^{\pi}\left(s^{\prime}\right)\right)}\end{array}\right. {QT��?(s,a)=��s����S?P(s���Os,a)(T1?R(s���Os,a)+TT?1?VT?1��?(s��))Q����?(s,a)=��s����S?P(s���Os,a)(R(s���Os,a)+��V����?(s��))?
����,���ͨ��ֵ�����ݹ鷽�������״ֵ̬����,���ǾͿ���ͨ���������������ÿһʱ�̵�״̬-����ֵ������
���Ե�����ֵ����
���Ե���
ͨ�����ϵ�����,��ش����һ�����뷨���������Ų��ԡ�һ����Ȼ��Ȼ��˼·���Dz��Ե����㷨��
�㷨�Ļ������̾������������һ������,����˵ �� ( s , a ) = 1 �O A ( s ) �O \pi(s, a)=\frac{1}{|A(s)|} ��(s,a)=�OA(s)�O1?,Ȼ��ͨ��ֵ�����ݹ����ʽ,����ò�����ÿһ��ʱ�̵�ֵ����������ֵ����,����ͨ��״̬-����ֵ�����ı���ʽ,�������ÿһ��ʱ�̵�״̬����ֵ������״̬-����ֵ����,���ǿ���ͨ�����ڶ������״̬-����ֵ����,���и��²���: �� �� ( s ) = arg ? max ? a �� A Q �� ( s , a ) \pi^{\prime}(s)=\underset{a \in A}{\arg \max } Q^{\pi}(s, a) ����(s)=a��Aargmax?Q��(s,a)�����˸��º�IJ���,�ظ����Ϲ���,ֱ���������������ν�IJ��Ե����㷨,ͨ�����ϵص�������,���ҵ����Ų��ԡ�����֤��,�����㷨�������ġ�
ֵ����
��һ������ĵ���������ֵ������������ V ? V^* V?�� Q ? Q^* Q?����ʾ���Ų��� �� ? \pi^* ��?�µ�״ֵ̬������״̬-����ֵ������
�����뵽����,ijһʱ��ijһ״̬��,����ֵ������Ȼ�����Ų����µ�״̬-����ֵ�������ڶ�����һ�����,��:
V ? ( s ) = max ? a �� A Q ? ( s , a ) V^{*}(s)=\max _{a \in A} Q^{{*}}(s, a) V?(s)=a��Amax?Q?(s,a)
���������֤���ġ�����,���ij�������µ�ijһ����ֵ�����������ŵ�,��ôһ�����Ըij�״̬-����ֵ��������Ӧ�IJ���,ʹ״ֵ̬����
�����д��,�ͳ���:
{ V T ? ( s ) = max ? a �� A �� s �� �� S P ( s �� �O s , a ) ( 1 T R ( s �� �O s , a ) + T ? 1 T V T ? 1 ? ( s �� ) ) V �� ? ( s ) = max ? a �� A �� s �� �� S P ( s �� �O s , a ) ( R ( s �� �O s , a ) + �� V �� ? ( s �� ) ) \left\{\begin{array}{l}{V_{T}^{*}(s)=\max _{a \in A} \sum_{s^{\prime} \in S} P(s^{\prime}|s,a)\left(\frac{1}{T} R(s'|s,a)+\frac{T-1}{T} V_{T-1}^{*}\left(s^{\prime}\right)\right)} \\ {V_{\gamma}^{*}(s)=\max _{a \in A} \sum_{s^{\prime} \in S} P(s^{\prime}|s,a)\left(R(s'|s,a)+\gamma V_{\gamma}^{*}\left(s^{\prime}\right)\right)}\end{array}\right. {VT??(s)=maxa��A?��s����S?P(s���Os,a)(T1?R(s���Os,a)+TT?1?VT?1??(s��))V��??(s)=maxa��A?��s����S?P(s���Os,a)(R(s���Os,a)+��V��??(s��))?
��ʽ�ǹ�������ֵ������һ��������ʽ,�ͱ���Ϊ�DZ����������Է��̡����Ӧ������״̬-����ֵ����Ϊ:
{ Q T ? ( s , a ) = �� s �� �� S P ( s �� �O s , a ) ( 1 T R ( s �� �O s , a ) + T ? 1 T max ? a �� �� A Q T ? 1 ? ( s �� , a �� ) ) Q �� ? ( s , a ) = �� s �� �� S P ( s �� �O s , a ) ( R ( s �� �O s , a ) + �� max ? a �� �� A Q �� ? ( s �� , a �� ) ) \left\{\begin{array}{l}{Q_{T}^{*}(s, a)=\sum_{s^{\prime} \in S} P(s^{\prime}|s,a)\left(\frac{1}{T} R(s'|s,a)+\frac{T-1}{T} \max _{a^{\prime} \in A} Q_{T-1}^{*}\left(s^{\prime}, a^{\prime}\right)\right)} \\ {Q_{\gamma}^{*}(s, a)=\sum_{s^{\prime} \in S} P(s^{\prime}|s,a)\left(R(s'|s,a)+\gamma \max _{a^{\prime} \in A} Q_{\gamma}^{*}\left(s^{\prime}, a^{\prime}\right)\right)}\end{array}\right. {QT??(s,a)=��s����S?P(s���Os,a)(T1?R(s���Os,a)+TT?1?maxa����A?QT?1??(s��,a��))Q��??(s,a)=��s����S?P(s���Os,a)(R(s���Os,a)+��maxa����A?Q��??(s��,a��))?
�ɱ����������Է���,����֪��,���Dz���Ҫͨ�����Ե���,һ���ԾͿ������Ų��� �� ? \pi^* ��?�µ�ֵ����ͳͳ��������ɴ�,��ν��ֵ�����㷨,�Ͳ��Զ����ˡ���ͨ��������������ʽ,��ͨ���������Ŷ�����ֵ�����������ڶ��������,���ܹ�������Ų��ԡ�����ϸ����
Qѧϰ��SARSA��ʱ����ѧϰ
ǿ��ѧϰ���㷨����ֵ�����Ͳ��Ե���,�ȽϾ���Ļ���Q learning��Sarsa��TD(ʱ����),���µ��㷨����SAC��TD3�ȡ���Щ�㷨��Ŀ�궼�����ֵ����,����ͬС��,���Լ����������ֵ�����ĸ��ֲ�ͬ�ķ���,��ֻ��dz�����ѧϰ,������ϸ���о�,�������ں���Щ�㷨���Ƶ��Լ�������֤��,�ں��ʵ�������ֱ�������þͺ��ˡ�
Qѧϰ
Qѧϰ�㷨,��Ҫ�˽�Q����Q-table ��ʵ���ǰ�״̬�Ͷ���һ����Ϊ�б�,һ����Ϊ�б��ɱ�������Ҫ��״̬-����ֵ����( Q Q Q����)��ʵҲ����Ҫ��취������Ŷ����µ�Q����
������㷨���������ʼ��һ��Q��,Ȼ�������ѡ��״̬ s s s�Ͷ��� a a a,���ݽ��ͺ������������ R R R,Ȼ�������������״̬-����ֵ�����ĵ�����ʽ,����Q������˷���,ֱ��Q�����ٱ仯��
��������������������,�ͺ���������Qѧϰʱ��ô�������ˡ�
SARSA��ʱ����ѧϰ
Sarsa��Qѧϰ�㷨�ĸĽ���Sarsa��Q�Լ�TD�����϶���һ��ͬ���ġ�
�������ߵ�һ����������,���Կ����������
���ǿ��ѧϰ
��ν���ǿ��ѧϰ,ֻ��������������ȥ��ʾ�����Ų����µ�״̬-����ֵ���� Q ? ( s , a ) Q^*(s,a) Q?(s,a)������ Q ? ( s , a ) Q^*(s,a) Q?(s,a)���������ʾ,��������鲻�ͺð���?
ΪʲôҪ�����ѧϰ��?��Ϊ��״̬�ռ�Ͷ����ռ�ܴ��ʱ��,�����������������,������������,��ֵ�����㷨,����Qѧϰ�㷨,������ Q Q Q����,��������̫������֪��,������պþ������ƽ�һ�����ӵĸ��������ĺ�����,��������ʾ Q Q Q����,������?��������һ���뷨,���������ǿ��ѧϰ��
���ѧϰ��Ҫ�ṩѵ������,��ǩ��ô��?���Խ���һ���� Q Q Qֵ��Ϊ��ǩ��ֱ�����������, Q Q Qֵ�仯������,�����ﵽ�����š�
������ʹ����ͬ��������������һ��Ŀ�� Q Q Qֵ���Ƶ�ǰ Q Q Qֵ,�ᵼ������������ɢ�����о���,���ѧϰҪ������֮���������ͬ�ֲ�,��ǿ��ѧϰ������������������������DQN��ʹ�������������������һϵ������:����ط�,Ŀ�����������Ӧ��ѧϰ�ʵ�������������,���ǿ��ѧϰ������һϵ�п�ѧϰ���о��Ķ�����
�������������������й���DQN�ļ���,����Ҳ�������ˡ�
һЩѧϰ����
�м������۱Ƚ��������鼮,����GitHub��
������ڻ���ѧϰû���˽�,���Կ�һ�����γ���
��־����ʦ����Ƶ�̳�1,��ȡ��aqyf ,��Ƶ�̳�2,��ȡ��777p ,��Ƶ�̳�3,��ȡ��rjgi��
����,Ҳ����������������������־����ʦ�Ļ���ѧϰ�γ��Լ�Ī����python�̡̳�
����ѧϰ
bagging
Bagging���뷨�ܼ�,������ѵ�����о��ȡ��зŻصس�ȡm���Ӽ���Ϊm��ѵ����,�ֱ�ʹ�÷���ع��㷨,���Եõ�m��ģ��,��ͨ��ȡƽ��ֵ��ȡ����Ʊ�ȷ���,�õ�Bagging�Ľ����
Bagging�㷨�����������ࡢ�ع��㷨���,�����ȷ�ʡ��ȶ��Ե�ͬʱ,ͨ�����ͽ���ķ���,�������ϵķ�����
��������:
- �� N �������зŻصIJ��� N ��������
- ���� N ��������ȫ�����Ͻ��������� (CART��SVM)��
- �ظ�����IJ���,���� m ����������
- Ԥ���ʱ��ʹ��ͶƱ�ķ����õ������
���ɭ��
�ڻ���ѧϰ��,���ɭ����һ����������������ķ�����,�����������������ɸ������������������������������������ bagging �뷨������ӿռ��뷨,����������ļ��ϡ����ʹ�����ͳ����ֵø���ռ��Ԥ�������ı�����Ϊ RF �� oob (out-of-bag)����ʡ�ÿ����ѡ���ֵ�������ѵ��,ʣ�µ���Ϊ��֤����������Ҳ����ѡȫ����,Ҳ��ѡ���ֵġ��ع����ƽ��,�������ͶƱ��
ÿ�����İ������¹�������:
- ���ѵ������СΪ N,����ÿ��������,������зŻصش�ѵ�����еij�ȡ N ��ѵ������(���ֲ�����ʽ��Ϊbootstrap sample����),��Ϊ������ѵ���������������ǿ���֪��:ÿ������ѵ�������Dz�ͬ��,������������ظ���ѵ��������
- ���ÿ������������ά��Ϊ M,ָ��һ������ m<<M(ȡ M \sqrt{M} M??)����ش� M ��������ѡȡ m �������Ӽ�,ÿ�������з���ʱ,���� m ��������ѡ�����ŵġ�
- ÿ�����������̶ȵ�����,����û�м�֦���̡�
����Ե�����,ʹ�����ɭ�ֲ�������������,���Ҿ��кܺõÿ�������(����:��ȱʡֵ������)��
���ɭ�ַ���Ч��(������)�����������й�:
- ɭ���������������������:�����Խ��,������Խ��
- ɭ����ÿ�����ķ�������:ÿ�����ķ�������Խǿ,����ɭ�ֵĴ�����Խ�͡�
��С����ѡ����� m,��������Ժͷ�������Ҳ����Ӧ�Ľ��͡�����m,����Ҳ����֮�������Թؼ����������ѡ�����ŵ� m,��Ҳ�����ɭ��Ψһ��һ��������
��ȱ��
- �ܹ��������������ķ���,���һ�����������ѡ��
- ��ѵ�����֮���ܸ�����Щfeature�ıȽ���Ҫ
- ѵ���ٶȺܿ�
- �����ײ���
- ʵ�������˵��Ϊ��,��,���㿪��С
boosting
��������Ƥ�������������,����������ȷ�ʸ���һ��Ȩ����ϳ�һ��ǿѧϰ��,����ƫ��,����� boosting �Ļ���˼�롣һ������������㷨������ AdaBoost��
���þ�������Ϊ�����������ݶ������㷨����Ϊ GBDT��GBDT �ľ�������ѵ����ʱ��������һ�����IJв�ΪĿ��,����в������һ������Ԥ��ֵ����ʵֵ�IJ�ֵ���е������������뷨�������õ��Dzв�,Ҳ�����ۼ�,�������ڷ�������û������ġ�����GBDT�е������ǻع���,���Ƿ�������
GBDT���ŵ�;�����
�ŵ�:
- Ԥ��εļ����ٶȿ�,������֮����Բ��л����㡣
- �ڷֲ����ܵ����ݼ���,�������ܺͱ����������ܺá�
- ���þ�������Ϊ��������ʹ�� GBDT ģ�;��нϺõĽ����Ժ�³����,�ܹ��Զ�����������ĸ߽�ϵ,����Ҳ����Ҫ�����ݽ��������Ԥ�������һ���ȡ�
������:
- �ڸ�άϡ������ݼ���,���ֲ���֧�����������������硣
- �ڴ����ı��������������ϵ����Ʋ�������ֵ�����ԡ�
- ѵ����Ҫ����ѵ��,ֻ���ھ������ֲ�����һЩ�ֲ����е��ֶ����ѵ���ٶȡ�
Boosting ��ѵ����ʱ����������һ��Ȩ��,Ȼ��ʹ loss function ����ȥ������Щ�ִ��������(������ִ����������Ȩ��ֵ�Ӵ�)��Boosting �ĺô�����ÿһ���IJμӾ��DZ����������˷ִ� instance ��Ȩ��,�����Ѿ��Ե� instance ������ 0,������������Ϳ��Ը��ӹ�ע���ֵ� instance ��ѵ���ˡ��൱�ڰѸ����,�ó������¸㡣
Shrinkage ��Ϊ,ÿ����һС���ƽ��Ľ��Ҫ��ÿ����һ�ƽ�����������ױ���
����ϡ�
��ȱ��:
�ŵ�:
- ���ȸ�
- �ܴ�������������
- �ܴ�������������
- �ʺϵ�ά��������
ȱ��:
- �����鷳(��Ϊ��������������ϵ)
- ������ʱ���ӶȺܴ�
ԭʼ�� GBDT �㷨���ھ�����ʧ�����ĸ��ݶ��������µľ�����,ֻ���ھ�����������ɺ��ٽ��м�֦���� XGBoost �ھ����������ξͼ���������
��������
����ͼģ��
����ͼģ������ͼ�۷����Ա������������������֮��ϵ��һ�ֽ�ģ������ͼ�е���һ�ڵ�Ϊ�������,�����ڵ���ޱ��������ζ�˶������˴��������������ֳ����ĸ���ͼģ���Ǿ������Աߵ�ͼ���������Աߵ�ͼ��
����ͼģ��ͨ���������ͼ�ı�����������ά�ռ��ϵĸ��ʷֲ���ͼ�Ľڵ�ͱ������˸÷ֲ���ͬ����֮����е������������ʵļ��ϡ�����ͼ��������,����ͼģ�Ϳ��Էֳ�������,�ֱ��DZ�Ҷ˹����������ɷ����硣������������������ӻ�����������������,���������������ͺͽ��ֲ����ӻ��ķ�ʽ������ͬ������ͼģ����ͼ����Ƶ��������;�ܹ㡣
��Ҷ˹��
һ�����,��Ҷ˹�����������ͼ�еĽڵ��ʾ������������������ڵ�ļ�ͷ������������������Ǿ��������ϵ���Ƿ�����������,�������ڵ����û�м�ͷ�����һ�������ͳ�����������˴˼�Ϊ�����������������ڵ����һ������ͷ������һ��,��ʾ����һ���ڵ��ǡ���(parents)��,��һ���ǡ���(descendants or children)��,���ڵ�ͻ����һ����������ֵ��
������˵,��Ҷ˹�����������ʾ�����������֢״��ĸ��ʹ�ϵ,������֪ij��֢״��,��Ҷ˹����Ϳ�����������ֿ��������֮�������ʡ�
�����Ʒ������
�����ɷ�������Ʊ�Ҷ˹�������ڱ�ʾ������ϵ������,һ���������Ա�ʾ��Ҷ˹��������ʾ��һЩ������ϵ,��ѭ����������һ����,�����ܱ�ʾ��Ҷ˹�����ܹ���ʾ��ijЩ��ϵ,���Ƶ���ϵ��
�����ɷ������Ҫ��һ��������ǰһ��������������,��ǰһ������֮ǰ���б�������������������,Ҳ����Ҫ���������ɷ����ʡ�
�ƹ������
Эͬ���˷�Ϊ User-based CF �� Item-based CF ,�����϶���Ѱ��һ�ֵ��ȱƽ�������������:��ʼ�ľ���ȱʧֵһ���²�,�õ� Z;�� Z �� rank-r ����ֵ�ֽ�,�Դ˵õ�ȱʧֵ�µĹ���;�ظ��������,ֱ��������
�������
ȷ�ʡ���ȷ�ʡ��ٻ��ʡ�F1ֵ��ROC��AUC
�Ҳ�֪��Ϊʲô������ô������ϲ���ù�ʽȥ�����⼸������,�����ܼĶ���,�������ʽ,�һ�Ҫ��������һ���㹫ʽ����ÿ���ַ���ʾ����˼,�ⲻ���˷�ʱ��ô��
ȷ��(accuracy)��������ͨ�������µķ���ֶԵı��ʡ���������Ⱑ������˵ 100 ��������,�� 1 ������,��ô��һ����ȫ���ɺ���,�ǻ��� 0.99 ��ȷ�ʡ�
��ȷ��(precision)�ǶԽ�����Ե�,������ֵ���������������,�ֶԵ�����ռ�İٷֱȡ�
��ν���ٻ��ٻ�,������ʵ�ʵ�����������,���ж϶Եİٷֱ��ж���,Ҳ�������ٻ������������ж��١�
F1 ֵ���Ǿ�ȷ�ʺ��ٻ�����ij�������µ�ƽ���� F 1 = 2 ? p r e c i s i o n ? r e c a l l p r e c i s i o n + r e c a l l F1 = \frac{2*precision*recall }{precision + recall} F1=precision+recall2?precision?recall?��
�ٻ����Ǹ�����Ķ���,�����ù�������������,�ٻ��������������ж�Ϊ 1 �ı���,���ǹ�ע����ж�Ϊ 1 ������,���������ж�Ϊ 1 �����ǽ� FRR���� FPR Ϊ������,���ٻ��������Ȥ�Ķ���Ϊ������,�����������߾ͽ� ROC ���ߡ�AUC(area under curve) ���� ROC �������AUC Խ��Խ��,ROC Խ��Խ�á� ROC �� AUC ͨ������������һ����ֵ�������ĺû���
ROC ����,x ��Ϊ������,y ��Ϊ������(�ٻ���)��������� y=x �ϵ�,��ʾ�Dz�������²�����Ľ����ROC ���߽���:һ��Ĭ��Ԥ�����֮�����һ��������� p,�������Խ��,��ʾ����positive �ĸ���Խ�����ڼ���������һ�� threshold,��� p>threshold,��ô��Ԥ����Ϊpositive,����Ϊnegitive�������ü��� threshold,��ô���ǾͿ��Եõ����������ʺͼ����ʵ�ֵ,�Ϳ��� plot ͼ���ˡ�
AUC:AUC(Area Under Curve) ������Ϊ ROC �����µ����,��Ȼ�������������1(һ�������ROC ���� y=x ���Ϸ�,����0.5<AUC<1)��
�����Լ��е��������������仯ʱ,ROC �����ܻ������ֲ���,���� precision �� recall ���ܾͻ��нϴ�IJ���������,����һ������Ч����һ�������ı���
�ʴ�ģ��
�ʴ�ģ���� NLP �����һ������,����˼����ǰѵ��ʶ���һ���������档����һ�仰,��������ʴ�����ÿ�����ʳ��ֵĴ���,�͵õ���һ����Ƶ������
TF-IDF
TF-IDF �Ǻ���һ���ִ���һ���ļ��е���Ҫ�Եġ��ִʵ���Ҫ�����������ļ��г��ֵĴ�������������,��ͬʱ�������������Ͽ��г��ֵ�Ƶ�ʳɷ����½���һ��������һƪ�����г��ִ���Խ��, ͬʱ�������ĵ��г��ִ���Խ��, Խ�ܹ����������¡�
ͨ�����������,һ�����뷨�����ô�����������ı��ʳ��Դ������Ͽ������ռ��,������������ƪ�����е���Ҫ�ԡ��������Ͽ�̫����,һ��һ��������ʵ��������������ʵ��ļ������Ͽ������ռ����Ϊ�������ѳ���ɳ�,��ȡ�� log ����:
TFIDF ( w ) = ?��ijһ�����д���? w ?���ֵĴ���? ?�����������еĴ�����Ŀ? ? log ? ( ?���Ͽ���ĵ�����? ?��������? w ?���ĵ���? + 1 ) \text{TFIDF}(w) =\frac{\text { ��ijһ�����д��� } w \text { ���ֵĴ��� }}{\text { �����������еĴ�����Ŀ }}*\log \left(\frac{\text { ���Ͽ���ĵ����� }}{\text { �������� } w \text { ���ĵ��� }+1}\right) TFIDF(w)=?�����������еĴ�����Ŀ??��ijһ�����д���?w?���ֵĴ���???log(?��������?w?���ĵ���?+1?���Ͽ���ĵ�����??)
��ĸ֮����Ҫ��1,��Ϊ�˱����ĸΪ 0��
����
����������ָģ�Ͷ�δ֪���ݵ�Ԥ��������
�����
��ν�Ĺ���Ͼ���˵ѵ����̫����,�������ڲ��Լ���Ч�����á�����Ϸ����ڲ�������ѵ��������̫�������¡����һζ��ȥ���ѵ�����ݵ�Ԥ������,��ѡģ�͵ĸ��Ӷ�������ܸ�,���������Ϊ����ϡ�����Խ��,ģ��Խ����,Խ������ϡ�
������ԭ��:
- ��Ϊ����̫��,�ᵼ�����ǵ�ģ���Ӷ�����,������ϡ�(ģ��̫����)
- Ȩֵѧϰ���������㹻��,�����ѵ�������е�������ѵ��������û�д����Ե�������(ѧ̫��)
�������
- L1��L2����
- ��������
- Ȩֵ˥��
- dropout
- ���ݼ�����
- ���ֹͣѵ��
- ������֤��(ѵ�����Ͳ��Լ�����)
����ģ�ͺ��б�ģ��
- ����ģ��:������ѧϰ���ϸ��ʷֲ� P(X,Y),Ȼ������������ʷֲ� P(Y|X) ��ΪԤ���ģ��(���ر�Ҷ˹)������ģ�Ϳ��Ի�ԭ���ϸ��ʷֲ� P(X,Y),�����нϿ��ѧϰ�����ٶ�,������������������ѧϰ,���������ɷ�ģ�� HMM��
- �б�ģ��:������ֱ��ѧϰ���ߺ����������ʷֲ� P(Y|X) ��ΪԤ���ģ��,���б�ģ�͡�ֱ�����Ԥ��,����ȷ�ʽϸߡ�
�б�ʽģ�;���:Ҫȷ��һ������ɽ��������,���б�ģ�͵ķ����Ǵ���ʷ������ѧϰ��ģ��,Ȼ��ͨ����ȡ��ֻ���������Ԥ�����ֻ����ɽ��ĸ���,������ĸ��ʡ�
����ʽģ�;���:��������ģ���Ǹ���ɽ�����������ѧϰ��һ��ɽ���ģ��,Ȼ��������������ѧϰ��һ�������ģ��,Ȼ�����ֻ������ȡ����,�ŵ�ɽ��ģ���п������Ƕ���,�ڷŵ�����ģ���п������Ƕ���,�ĸ�������ĸ���
���Է������ͷ����Է�����
���ģ���Dz��������Ժ���,���Ҵ������Է�����,��ô�������Է�����,�����ǡ�
���������Է�������:LR����Ҷ˹���ࡢ�����֪�������Իع顣�����ķ����Է�����:��������RF��GBDT������֪����SVM ���ֶ���(�����Ժ˻��Ǹ�˹��)��
���Է������ٶȿ졢��̷���,���ǿ������Ч������ܺá������Է�������̸���,����Ч���������ǿ��
������,����ϵ��,�������������Կɷ�,����ѡ�����Է�����,����,����ѡ������Է�������
L1 �� L2 ����
���Ƕ��ǿ��Է�ֹ�����,����ģ���Ӷȡ�
- L1 ���� loss function �������ģ�Ͳ����� 1 ������
- L2���� loss function �������ģ�Ͳ����� 2 ������
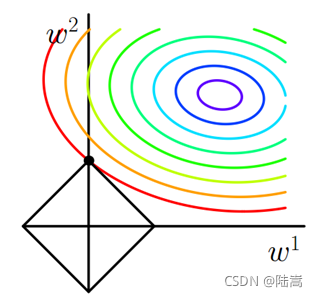
- L1 �����ϡ���������L2 �����������������Ƕ���ӽ��� 0��
- L1 �������ڲ�������������,���������������� 0,�� L2 ��ѡ����������,��Щ��������ӽ��� 0��
- L1 ������ѡ��ʱ��dz�����,�� L2 ��ֻ��һ�ֹ����ѡ�
��һ������
Ϊ��������������֮�������Ӱ��,������Ҫ���������й�һ������,ʹ�ò�ָͬ��֮����пɱ��ԡ�
- scaling ��һ������
- ��ȥ��ֵ,���Է���
- ����ת��,��: y = log ? 10 ( x ) y=\log_{10} (x) y=log10?(x), y = arctan ? x �� / 2 y = \frac{\arctan x}{\pi/2} y=��/2arctanx?
- softmax:ȡ e x i e^{x_i} exi?��,����ռ�ȡ�
������֤
N �۽�����֤��������;:ģ��������ģ��ѡ�����ֲ������ڻ���ѵ�����Ͳ��Լ�,�Ϳ��Խ���ģ�������������ֲ������ڻ���ѵ��������֤��,�Ϳ��Խ���ģ��ѡ��
������֤�ĺ���˼��:�����ݼ����ж�λ���,�Զ�������Ľ��ȡƽ��,�Ӷ��������λ���ʱ���ݻ��ֵò�ƽ�����ɵIJ���Ӱ�졣��Ϊ���ֲ���Ӱ����С��ģ���ݼ��ϸ����׳���,���Խ�����֤������С��ģ���ݼ��ϸ������ֳ����ơ�
���ֹ���Ͽ��ܲ���ģ�͵��µ�,������Ϊ���ݼ����ֲ�������ɵġ������������С��ģ���ݼ�ѵ��ģ��ʱ�����׳���,������С��ģ���ݼ����ý�����֤�ķ�������ģ�������ơ�
������֤������ͬ:������֤ͨ��Ѱ�����ģ�͵ķ�ʽ���������ϡ�����������ͨ��Լ�������ķ������������ϡ�
Bias(ƫ��)��Error(���)��Variance(����)
���=ƫ��+���Bias �������п��ܵ�ѵ�����ݼ�ѵ����������ģ�͵������ƽ��ֵ����ʵģ�͵����ֵ֮��IJ��졣Variance �Dz�ͬ��ѵ�����ݼ�ѵ������ģ�����ֵ֮��IJ��졣Bias �� Variance �Dz��ɼ�õġ�����ϵ������ Bias ��С,���Ƿ���ܴ�,ѵ�����ϸ����,������ Bias ��С��