虽然人们普遍认为网络深度是当今深度学习 (DL) 模型高性能的原因,但增加深度也会带来诸如延迟增加和计算负担增加等缺点,这可能会阻碍 DL 的进展。 如果没有深度网络,是否有可能实现类似的高性能?
普林斯顿大学(Princeton University)和英特尔实验室(Intel Labs)的一个研究小组在最新发表的(Non-deep Networks)论文中提出了ParNet (Parallel Networks),这是一种新颖的非深度网络架构,其性能可与最先进的深度网络架构相媲美。

该团队将他们的研究贡献总结为:
- 首次证明,深度仅为 12 的神经网络可以在极具竞争力的基准测试中实现高性能(ImageNet 上为 80.7%,CIFAR10 上为 96%,CIFAR100 上为 81%)。
- 展示了 ParNet 中的并行结构如何用于快速、低延迟的推理。
- 研究了 ParNet 的缩放规则,并展示该缩放规则是有效的。
ParNet 的主要设计特点是它使用并行子网络或子结构(在论文中称为“streams”),以不同的分辨率处理特征。 来自不同streams的特征在用于下游任务的网络的后期融合。 这种方法使 ParNet 能够在只有 12 层的网络深度下有效运行(比 ResNet 模型低几个数量级)。
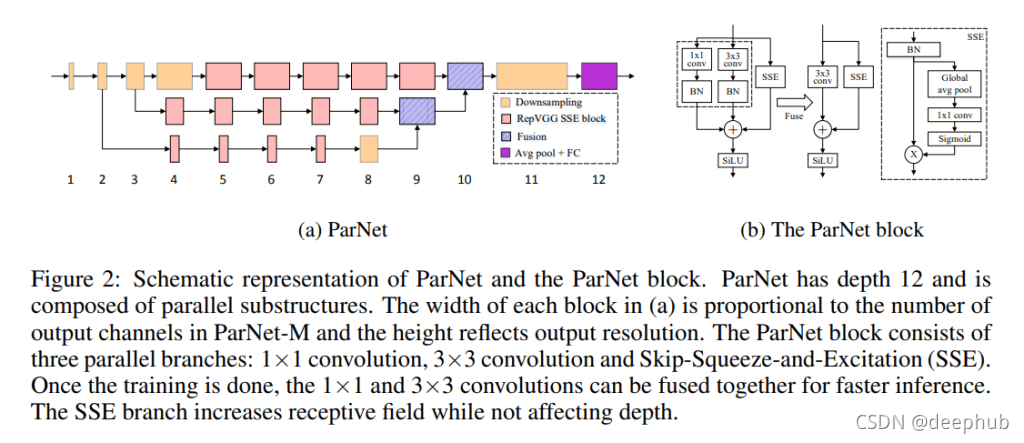
ParNet 的一个关键组件是它的 RepVGG-SSE,这是一个经过修改的 Rep-VGG 块,并带有一个专门构建的 Skip-Squeeze-Excitation 模块。 ParNet 还包含一个降低分辨率并增加宽度以实现多尺度处理的下采样块,以及一个融合多个分辨率信息的融合块。
在他们的实证研究中,该团队在包括 ImageNet、CIFAR 和 MS-COCO 在内的大规模视觉识别基准上,将提议的 ParNet 与最先进的深度神经网络基线(如 ResNet110 和 DenseNet)进行了比较。
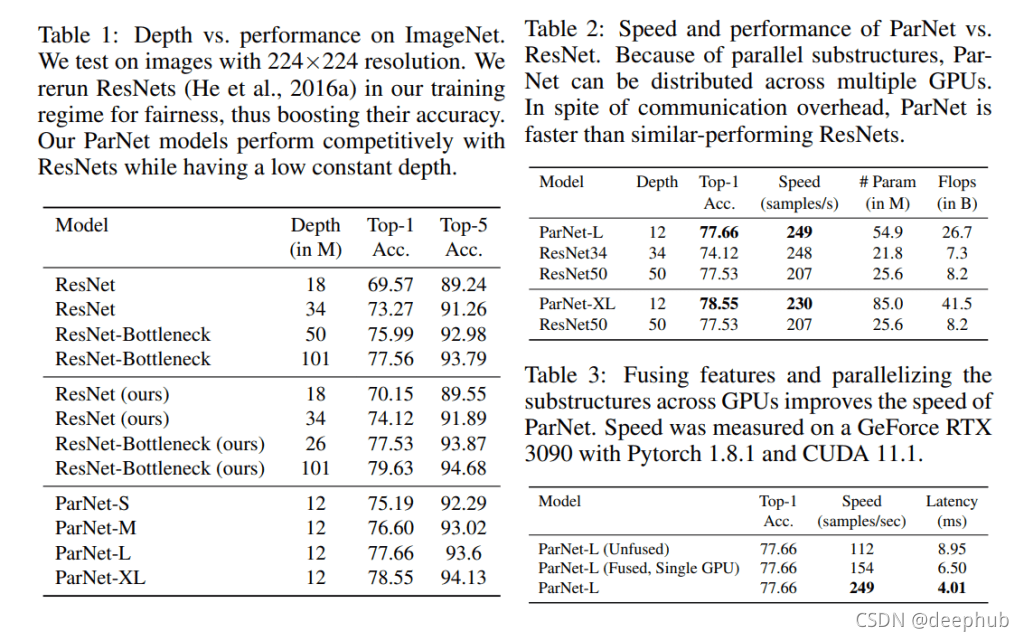
结果表明,只有 12 层深度的 ParNet 能够在 ImageNet 上达到 80% 以上的 top-1 准确率,在 CIFAR10 上达到 96%,在 CIFAR100 上达到 81%。 该团队还展示了一个具有 12 层主干网络的检测网络,该网络在 MS-COCO 大规模对象检测、分割和字幕数据集上实现了 48% 的平均精度。
总体而言,该研究提供了第一个经验证据,证明非深度网络可以在大规模视觉识别基准测试中与深度网络竞争。 该团队希望他们的工作有助于开发更适合未来多芯片处理器的神经网络。
论文地址:arxiv:2110.07641
论文源码:https://github.com/imankgoyal/NonDeepNetworks
本文作者 :Hecate He