面试官考查的最近邻搜索,不仅属于机器学习基础理论KNN的范畴,并且在实际工作比如 召回ANN 检索中也经常用到,如果小明当初能早些看到并行世界中我总结的这个图谱,肯定会有不一样的结果。
这次我们就先来总结下 最近邻算法(NN)中的KD树的相关知识点。

问题的产生
最近邻搜索(Nearest Neighbor Search)是指在一个确定的距离度量和一个搜索空间内寻找与给定查询项距离最小的元素。暴力搜索的解法时间复杂度是O(n), 使用KD-tree 能降低时间复杂度。
由于维数灾难,我们很难在高维欧式空间中以较小的代价找到精确的最近邻。近似最近邻搜索(Approximate Nearest Neighbor Search)则是一种通过牺牲精度来换取时间和空间的方式从大量样本中获取最近邻的方法。
KD-tree
KD-tree 是K-dimension tree的缩写,是对数据点在k维空间中划分的一种数据结构。
本质上,k-d树是一种空间划分树,是一种平衡二叉树。将整个k维的向量空间不断的二分,从而划分为若干局部空间,然后搜索的时候,不断进行分支判断,选择其中的局部子空间,避免了全局空间搜索。
举个例子,当k=3 的时间,KD-tree 就会将三维空间分割成如下图的形式:

KD-tree的构建
1. 选择维度:KD树建树采用的是从m个样本的n维特征中,分别计算n个特征的取值的方差,用方差最大的第k维特征𝑛𝑘来作为根节点。
2.选择中位数:对于这个特征,我们选择特征𝑛𝑘的取值的中位数𝑛𝑘v对应的样本作为划分点。
3. 分割数据:对于所有第k维特征的取值小于𝑛𝑘v的样本,我们划入左子树,对于第k维特征的取值大于等于𝑛𝑘v的样本,我们划入右子树。
4. 递归迭代:对于左子树和右子树,我们采用和刚才同样的办法来找方差最大的特征来做更节点,将空间和数据集进一步细分,如此直到所有点都被划分。

举个例子,当k=2 时,空间有?6 个二维数据点 {(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},构建KD树的具体步骤为:
1). 确定分割维度:?
6个数据点在x,y维度上的数据方差分别为39,28.63,在x轴上方差更大,所以分割维度为x。
2). 确定分割数据点:
根据x维上的值将数据排序,6个数据的中值(即中间大小的值)为7,所以分割数据点为(7,2)。这样,该节点的分割超平面就是直线x=7。
3). 左子空间和右子空间分别递归:
分割超平面x=7将整个空间分为两部分:x<=7的部分为左子空间,包含3个节点={(2,3),(5,4),(4,7)};另一部分为右子空间,包含2个节点={(9,6),(8,1)};然后左右子空间分别重复进行上述过程。

对于n个实例的k维数据来说,建立KD-tree的时间复杂度为O(n*logn)
KD树的插入
元素插入到一个K-D树的方法和二叉检索树类似。比如上面k=2的例子,实质就是在偶数层比较 x 坐标值,而在奇数层比较 y 坐标值。当到达了树的底部(也就是当一个空指针出现),也就找到了结点将要插入的位置。
给定N个点,插入节点的时间复杂度是O(logN)
KD树的最近邻查找
输入:构造完的KD-tree 和目标点 t
输出:距离 t 最近的点
算法过程:
1. 在KD树中找出包含目标点 t 的叶结点。即从根结点出发,递归地向下搜索二叉树。若在当前划分维度, t 的坐标值小于切分点,则移动到左子结点,否则移动到右子结点,直到走到叶结点为止。
2. 以此叶结点为“当前最近点”,递归的向上回溯,在每个结点进行以下操作:
i) 如果该结点保存的实例点比当前最近点距离目标点更近,则更新“当前? ? ? 最近点”,也就是说以该实例点为“当前最近点”。
ii)当前最近点一定存在于该结点一个子结点对应的区域,检查子结点的父结点的另一子结点对应的区域是否有更近的点。具体做法是,检查另一子结点对应的区域是否以「目标点为球心,以目标点与“当前最近点”?间的距离为半径的超球体」相交。
? ? a) 如果相交,可能在另一个子结点对应的区域内存在距目标点更近的点,移动到另一个子结点,接着,继续递归地进行最近邻搜索;
? ? b) 如果不相交,向上回溯。
当回退到根结点时,搜索结束,最后的“当前最近点”即为x 的最近邻点。
举个例子,在上文的KD树中查找目标点(2, 4.5)的最近邻,具体步骤如下:
1.先进行二分查找到叶节点。?
?从(7,2)查找到(5,4)节点,在进行查找时是由y = 4为分割超平面的,由于查找点为y值为4.5,因此进入右子空间查找到(4,7),形成搜索路径<(7,2),(5,4),(4,7)>,“当前最近点”为(4,7),计算(4,7)与目标点的距离为3.202。
2. 回溯搜索路径。
搜索路径为<(7,2),(5,4),(4,7)>,回溯到(5,4),其与目标点之间的距离为3.041,所以更新(5,4)为最最近邻点。
2.1 检查另一子节点区域是否有更近的。
以(2,4.5)为圆心,以3.041为半径作圆,如下图所示。可见该圆和y = 4超平面交割,所以需要进入(5,4)左子空间进行查找,也就是将(2,3)节点加入搜索路径中得<(7,2),(2,3)>;
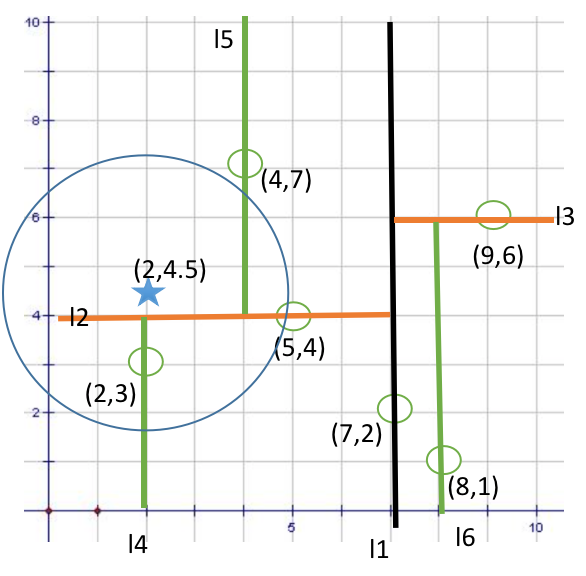
2.2. 搜索另一个子空间。
于是接着搜索至(2,3)叶子节点,(2,3)距离(2,4.5)比(5,4)要近,所以最近邻点更新为(2,3),最近距离更新为1.5;
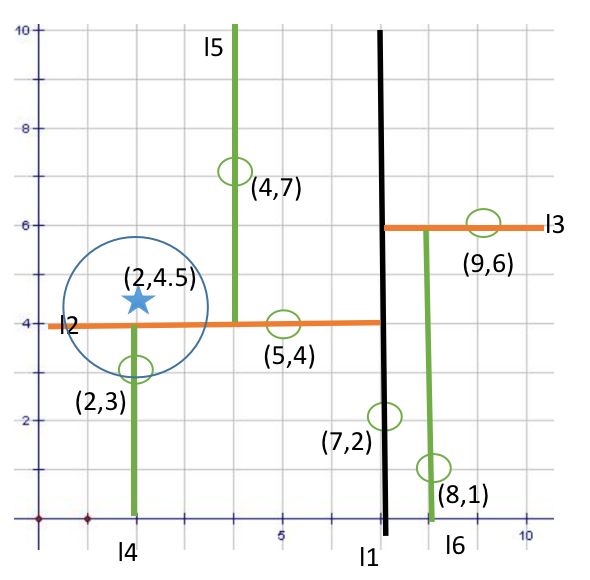
3 最后回溯到根结点
回溯到(7,2)的时候,以(2,4.5)为圆心1.5为半径作圆,并不和x = 7分割超平面交割,如下图所示。至此,搜索路径回溯完,返回最近邻点(2,3),最近距离1.5。
从上面的描述可以看出,KD树划分后可以大大减少无效的最近邻搜索,很多样本点所在的超矩形体和超球体不相交,根本不需要进入到其子空间进行检索,大大节省了计算时间。
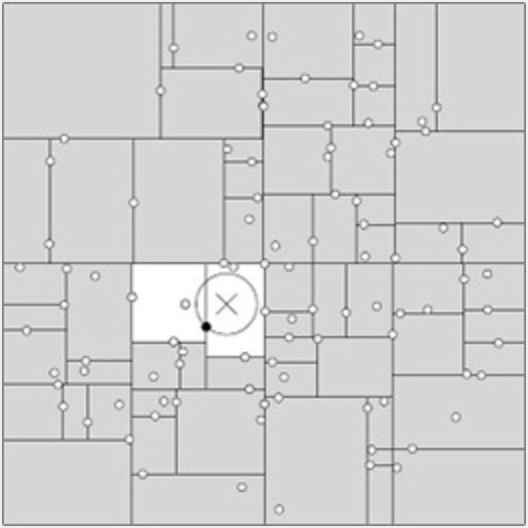
一般来讲,最临近搜索只需要检测几个叶子结点即可,如下图所示:
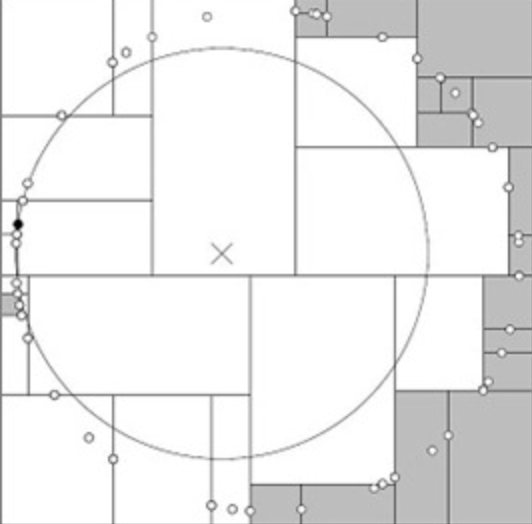
但是,如果当实例点的分布比较糟糕时,几乎要遍历所有的结点,如下所示:
当k=2时,查询时间复杂度最优为O(logn), 最坏为O(√n), 扩展至k维,最坏为O(n1-1/k)。
KD-tree对于低维空间检索效率高,维度不应超过20维。改进的最近邻查询算法――BBF,可适用于高维数据。BBF是以精度为代价来获取速度,其找到的最近邻不一定是最佳的。
查询优化--BBF算法
BBF(Best Bin First)是一种改进的k-d树最近邻查询算法。从上文KD树查询过程可以看出其搜索过程中的“回溯”是由“查询路径”来决定的,并没有考虑查询路径上数据点本身的一些性质。
BBF的查询思路就是将“查询路径”上的节点进行排序,如按各自分割超平面(称为Bin)与查询点的距离排序。回溯检查总是从优先级最高的(Best Bin)的树节点开始。
另外BBF还设置了一个运行超时限制,当优先级队列中的所有节点都经过检查或者超出时间限制时,算法返回当前找到的最好结果作为近似的最近邻。采用了best-bin-first search方法就可以将KD树扩展到高维数据集上。
参考:
-
https://www.cnblogs.com/eyeszjwang/articles/2437706.html
-
https://blog.csdn.net/v_JULY_v/article/details/8203674