前言
目标检测任务的目标是识别图像中物体的类别并且定位物体所在位置用矩形框框出。目标检测领域的深度学习方法的发展主要分为两大类:两阶段(Two-stage)目标检测算法和单阶段(One-stage)目标检测算法。
1)两步模型:分成两个步骤。第一,提取候选区域提取过程,即先在输入图像上筛选出一些可能存在物体的候选区域,然后针对每个候选区域提取特征,判断其是否存在物体。经典算法模型有R-CNN、SPPNet、Fast R-CNN、Faster R-CNN、R-FCN、Mask R-CNN等。
缺点: 耗时耗力,而且没有考虑到图像的全局信息,比如人坐在车上,这种关系很难被捕捉到。
2)单步模型: end-to-end,直接将图像输入到网络,输出得到物体的类别和位置信息。将分类问题转换成回归问题,图像先被裁剪到同一尺寸,并以网格(grid cell)划分成N*N,模型仅需输入图像,输出就能得到位置和分类结果。经典算法模型有MultiBox、OverFeat、YOLO、SSD等。
总结:单步模型大大提高了计算效率,两步模型在检测精度上有优势。
一、YOLOv1介绍
论文链接: http://arxiv.org/abs/1506.02640
2016年CVPR,由华盛顿大学Joseph Red提出。与原来RCNN等两步模型(先提取候选框,再用分类器筛选)不同,yolov1将目标检测当作回归问题,预测一系列数值,预测的数值包括图像的位置信息和类别信息。
YOLO优点:由于输入是一整张图片,所以对图片的全局信息捕获能力强,背景错误(把背景错认为物体)比较少,隐式的学习图像中物体之间的关系。迁移能力泛化能力强,速度快,可以实时处理视频流。
缺点:与滑窗的方法相比,检测小物体的能力弱。
二、YOLOv1框架
24层卷积层提取图像特征, 2层全连接层,最后输出7×7×30的tensor。

实现方法:
1、将输入image分成S×S(论文里是7×7)个grid cell,如果某个object的中心落在grid cell中,则由这个grid cell产生的bounding box预测该object。(注意:每个grid cell只能预测一类物体,所以7×7最对预测49类物体。)
2、每个grid cell产生预测的B个(论文中是2个)bounding box,每个bounding box除了要预测四个位置坐标(x,y,w,h),还需要预测一个置信度(confidence),confidence计算公式如下图。Pr(object) 非0即1,表示box 包含物体的概率。IOU(truth上,pred下)表示人工标框和预测框的交并比,两者相乘为confidence。这个confidence代表了所预测的box中含有object的置信度和这个box预测的有多准。
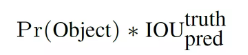
3、测试阶段:
Pr(classi|Object)表示BBox负责预测物体的条件下是某一类别的概率,由条件概率公式得到如下等式,最后等式右边为每一类得分(包分类和位置信息):
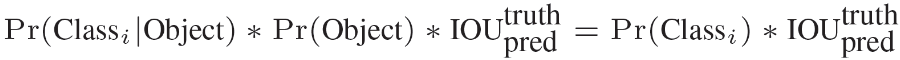
4、图中框的粗细代表置信度,每个grid cell生成两个BBox,由与实际GT的IOU最大的BBox去拟合,另一个被舍弃(依据NMS方法舍弃)。模型输出的tensor尺寸为7×7×30,7×7表示49个grid cell,30包括(x,y,w,h,confidence)×2,以及20个类别。

4、训练阶段:


图片转自https://blog.csdn.net/c20081052/article/details/80236015?ops_request_misc=&request_id=&biz_id=102&utm_term=yolov1&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-0-80236015.first_rank_v2_pc_rank_v29&spm=1018.2226.3001.4187
总共分为三种BBox:1)负责检测物体的,且与GT的IOU最大的。2)负责检测物体,但IOU小的。3)不负责检测物体的。
损失函数共分为五部分:1)负责检测物体的BBox中心点定位误差。2)负责检测物体的宽高定位误差,取根号使对小框更敏感。3)负责检测物体的置信度误差。4)不负责检测物体的置信度误差。5)类别预测误差。
三、总结
1)YOLOv1提取全局信息,隐式编码尺寸、关系、形状、位置。
2)单阶段模型,速度快,可以实时检测。
3)小目标检测效果差,密集物体检测效果差(因为只有两个框),但把背景误认为物体的概率低。