1 背景
自从有人基于指针网络解决组合优化问题以来,基于ML的组合优化问题求解模型逐渐被关注。基于深度强化学习的组合优化求解带来了较高的模型准确度和泛化性。但是目前基于DRL的CO求解准确度和训练效率一般,简单来说就是模型不是很成熟。针对模型的表现性能和训练效率,同时本着万物皆可基于transformer进行改进的思想,本文提出了一种面向VRP系列组合优化问题的改进的‘transformer’,作者称其为’Attention Model’。到现在2021年10月,这篇文章已经在谷歌学术上有了325次的引用。
论文原文:Attention, Learn to Solve Routing Problems!
代码仓库:https://github.com/wouterkool/attention-learn-to-route
2 模型结构
花了半个晚上和半个上午的时间研读了一下这篇文章的模型结构,发现作者非常有想法。
整篇文章的写作风格还是很像NLP领域的,以TSP问题为例,整个模型想要拟合的概率分布模型可以表示为:
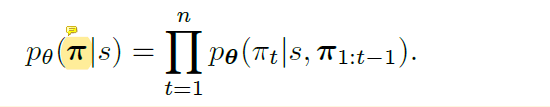
其中,
π
\pi
π是一个序列,表示从初始点到终止点(对于TSP问题就是初始点)的一个序列,
s
s
s代表了一个instance,我理解这个
i
n
s
t
a
n
c
e
instance
instance就是一个episode。一个episode
s
s
s下由每一步的选择概率相乘得到,很好理解。上面这个公式看似很简单,但是这实际上就是一个建模的过程,将一个TSP的CO问题建模成了一个序列决策问题。那么整个模型的目的就是通过神经网络拟合上面这个公式。
模型的整个结构借鉴了transformer模型(之前看的一篇Reinforcement Learning for Solving the Vehicle Routing Problem借鉴的Seq2Seq模型,可以看出NLP领域的进步对于CO还是影响很大),但是不同于transformer的是编码器和解码器都没有任何RNN结构:1)是为了降低计算复杂度;2)是为了实现对于input的排序不变性。
首先介绍encoder部分:
输入还是不同位置的二维坐标值(
d
x
=
2
d_x=2
dx?=2):
x
1
,
x
2
,
.
.
.
,
x
n
x_1,x_2,...,x_n
x1?,x2?,...,xn?, encoder先处理一下这几个值:
首先将每个
x
i
x_i
xi?都进行嵌入为128维度的向量:
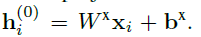
h
i
(
0
)
h_i^{(0)}
hi(0)?就是迁入后的向量(128维度),然后再将
h
i
(
0
)
h_i^{(0)}
hi(0)?经过8个attention layer,每个attention layer都有一个8头注意力层(MHA,M=8)和一个FC层组成了2 sublayers:
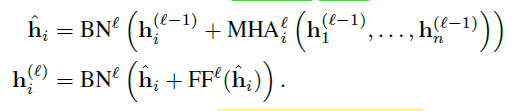
MHA处理的是整个
h
1
,
.
.
h
n
h_1,..h_n
h1?,..hn?的嵌入,共处理的N次,N次处理用的MHA参数不共享,上面公式代表每一层MHA的处理。BN代表批归一化,第二个公式的加号代表了跳连接。
如下图所示,经过了N层attention layer之后,我们就从
x
1
,
x
2
,
.
.
.
,
x
n
x_1,x_2,...,x_n
x1?,x2?,...,xn?得到了
h
1
(
N
)
,
h
2
(
N
)
,
.
.
.
,
h
n
(
N
)
h_1^{(N)},h_2^{(N)},...,h_n^{(N)}
h1(N)?,h2(N)?,...,hn(N)?,按照神经网络的层数来说,这个变化中间经历了
2
N
+
1
2N+1
2N+1层,包括1层embedding,N层MHA,以及N层FC。至于MHA是如何处理
h
1
,
.
.
.
h
n
h_1,...h_n
h1?,...hn?的,本文附录中给出了公式:

至此,我们获得了
h
1
(
N
)
,
h
2
(
N
,
.
.
.
,
h
n
(
N
)
h_1^{(N)},h_2^{(N},...,h_n^{(N)}
h1(N)?,h2(N?,...,hn(N)?,并对其求平均值得到了
h
g
(
N
)
h_g^(N)
hg(?N)称为graph embedding,整个encoder可以看成是graph attention。后面要用的就是
h
g
(
N
)
h_g^(N)
hg(?N)以及
h
1
(
N
)
,
h
2
(
N
,
.
.
.
,
h
n
(
N
)
h_1^{(N)},h_2^{(N},...,h_n^{(N)}
h1(N)?,h2(N?,...,hn(N)?。
其次介绍decoder部分:
encoder得到了整个图的embedding
h
g
(
N
)
h_g^(N)
hg(?N),可以看做是可以用于图分类的特征;以及经过N伦aggregating的node embeddings
h
1
(
N
)
,
h
2
(
N
,
.
.
.
,
h
n
(
N
)
h_1^{(N)},h_2^{(N},...,h_n^{(N)}
h1(N)?,h2(N?,...,hn(N)?。decoder的目的就是依据总体图的特征
h
g
(
N
)
h_g^(N)
hg(?N)以及当前决策步骤的特征,选择一个合适的节点作为下一步。
作者摒弃了原始transformer中的RNN结构,搞了一个手工简化的‘RNN结构’:用一个context node 节点来解码。
整个解码器的输入由三个部分构成:
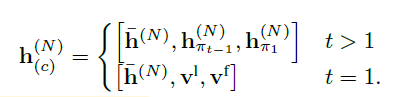
t
=
1
t=1
t=1的时候是初始化的placeholder。其中
t
>
1
t>1
t>1是三个拼接的张量分别代表了encoder得到的graph embedding, 上一步
t
?
1
t-1
t?1时刻选择的节点的编码,以及t=1时刻选择的节点编码(因为每次t-1的都会变,所以说是手动RNN)。
得到了
h
(
c
)
(
N
)
h^{(N)}_{(c)}
h(c)(N)?之后,将其与encoder得到的
h
1
(
N
)
,
h
2
(
N
,
.
.
.
,
h
n
(
N
)
h_1^{(N)},h_2^{(N},...,h_n^{(N)}
h1(N)?,h2(N?,...,hn(N)?再来N个MHA层(下图中黄色的就是一直在用的MHA),用
h
(
c
)
(
N
)
h^{(N)}_{(c)}
h(c)(N)?作为query,
h
1
(
N
)
,
h
2
(
N
,
.
.
.
,
h
n
(
N
)
h_1^{(N)},h_2^{(N},...,h_n^{(N)}
h1(N)?,h2(N?,...,hn(N)?作为key和value:
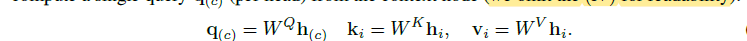
有了query,就开始对每个节点的embeddings
h
1
(
N
)
,
h
2
(
N
,
.
.
.
,
h
n
(
N
)
h_1^{(N)},h_2^{(N},...,h_n^{(N)}
h1(N)?,h2(N?,...,hn(N)?进行查询,用的还是attention的经典公式:
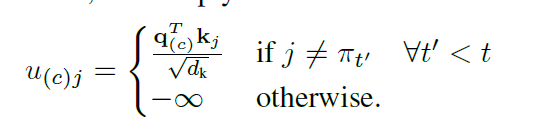
其中
j
j
j是节点(不知道为什么之前用
i
i
i代表节点现在又用
j
j
j)。
?
∞
-\infty
?∞表示这个节点走过了被mask。

OK,走到了这一步,我们已经获得了各个TSP节点的一个值
u
(
c
)
j
u_{(c)j}
u(c)j?,然后再次通过MHA的计算公式,我们得到了context node在MHA之后的embedding
h
(
c
)
(
N
+
1
)
h_{(c)}^{(N+1)}
h(c)(N+1)?,我们基于这个
h
(
c
)
(
N
+
1
)
h_{(c)}^{(N+1)}
h(c)(N+1)?和
h
1
(
N
)
,
h
2
(
N
,
.
.
.
,
h
n
(
N
)
h_1^{(N)},h_2^{(N},...,h_n^{(N)}
h1(N)?,h2(N?,...,hn(N)?再进行一个single head attention得到:
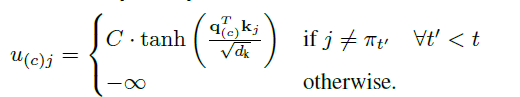
其中
u
(
c
)
j
u_{(c)j}
u(c)j?为每个node的类似于概率值的一个value,我们再对其进行softmax操作之后,就得到了最后想要的
p
i
p_i
pi?:
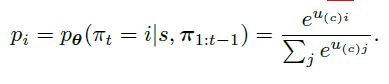
p
i
p_i
pi?代表了选择节点
i
i
i的概率,完整应该是
p
i
,
t
p_{i,t}
pi,t?,即在
t
t
t时刻选择节点
i
i
i的概率。
有了在
t
t
t时刻选择各个节点的概率分布之后,可以有两种方式获得下一步到底选择哪个。一个是贪婪greedy,选择概率最大的;另一个是采样。
至此模型结构结束。
训练采用的是带有baseline的REINFORCE进行的训练,细节不再赘述

3 实验
作者的实验在6个问题上进行了求解,并且附录给出了在每个问题上求解时的细节embeddings。
 文章还和指针网络进行了对比
文章还和指针网络进行了对比

4 特点总结
1、本文其实是基于transformer的思想对于CO问题的适应性改进,模型结构很大胆也很有想法,文章目的作者直接说为了泛化地解决CO问题并提升其表现。
2、模型以坐标点为输入,先用MHAb编码N层aggregating之后的节点信息,然后用其平均值代表整个地图的特征,在解码阶段依据手动变化的上一个节点信息区分不同步的特征。其实在整个TSP问题固定之后,训练稳定的情况下编码器的输出是不变的,然后解码器开始从初始点经过
n
n
n步遍历
n
n
n个节点,生成问题的解。(有一点不懂的是为什么解码器要用两层attention,直接在第一层MHA处采样不行吗?)
3、整个模型的核心其实是在于对transformer attention的使用和理解上,尤其是如何根据query构建整个attention。但是文章摒弃了transformer里的RNN,而是采用了dnn做embedding,context node做查询。不仅取得了很好的效果,并且计算复杂度也很低。
.