ИХТЪЭМФЃаЭЈCБДвЖЫЙЭјТч ЈC ХЫЕЧЭЌбЇЕФMachine LearningБЪМЧ
ИХТЪЭМФЃаЭ
ЪВУДЪЧИХТЪЭМ
ИХТЪЭМжЛЪЧвЛИіПђМм, ЪЧвЛжжЗНЗЈТл, ИњМЦЫуЛњжаЕФ
ЭђЮяНдПЩЖЏЙцЕФЫМТЗвЛбљ;
ИХТЪЭМЪЧИХТЪТлгыЭМТлЕФНсКЯВњЮя, ЮЊЭГМЦЭЦРэКЭбЇЯАЬсЙЉСЫвЛИіЭГвЛСщЛюЕФПђМм;
ИХТЪЭМФЃаЭЬсЙЉСЫвЛИіУшЪіПђМм, ЪЙЮвУЧФмЙЛНЋВЛЭЌСьгђЕФжЊЪЖГщЯѓЮЊИХТЪФЃаЭ, НЋИїжжгІгУжаЕФЮЪЬтЖМЙщНсЮЊМЦЫуИХТЪФЃаЭРяФГаЉБфСПЕФИХТЪЗжВМ, ДгЖјНЋжЊЪЖБэЪОКЭЭЦРэЗжПЊРД
ЦфЪЕЭМТлвВВЛЪЧБивЊЕФ, жЛЪЧНшгУСЫЭМЕФвЛаЉЬиЕуРДУшЪіИХТЪФЃаЭ, ШчЙћФуЖдЭМТлИааЫШЄ, ФЧУДФуПЩвдШЅПЕПЕХЫЕЧЭЌбЇЕФЭМТлБЪМЧ
ИХТЪЭМФЃаЭЕФШ§вЊЫиЈCБэЪОЁЂЭЦРэЁЂбЇЯА
ИХТЪЭМФЃаЭЕФБэЪО
ЭМжаНкЕу: БэЪОБфСП
ЭМжаБп: БэЪООжВПБфСПМфЕФИХТЪвРРЕЙиЯЕ
-
ИХТЪЭМФЃаЭЕФБэЪОПЬЛСЫФЃаЭЕФЫцЛњБфСПдкБфСПВуУцЕФвРРЕЙиЯЕ, ЗДгІГіЮЪЬтЕФИХТЪНсЙЙ, ЮЊЭЦРэЫуЗЈЬсЙЉСЫЪ§ОнНсЙЙ, ИХТЪЭМФЃаЭЕФБэЪОЗНЗЈжївЊгаБДвЖЫЙЭјТч, ТэЖћПЦЗђЫцЛњГЁ, вђзгЭМЕШ;
- БДвЖЫЙЭјТч

- ТэЖћПЦЗђЫцЛњГЁ

- вђзгЭМ

-
ИХТЪЭМФЃаЭБэЪОжївЊбаОПЕФЮЪЬтЪЧ, ЮЊЪВУДСЊКЯИХТЪЗжВМПЩвдБэЪОЮЊ
ОжВПЪЦКЏЪ§ЕФСЊГЫЛ§аЮЪН, ШчКЮдкЭМФЃаЭНЈФЃжав§ШыЯШбщжЊЪЖ;
ИХТЪЭМФЃаЭЕФЭЦРэ
-
ЧѓНтБпдЕИХТЪ
p ( x a ) = ЁЦ x Јv x ІС p(\bf{x_a}) = \sum_{\bf{x \diagdown x_{\alpha}}} p(xa?)=xЈvxІС?ЁЦ? -
ЧѓзюДѓКѓбщИХТЪзДЬЌ
X ? = arg?max ? x ЁЪ Іж p ( x ) X^{*} = \argmax_{\bf{x}\in \chi} p(\bf{x}) X?=xЁЪІжargmax?p(x) -
ЧѓЙщвЛЛЏвђзг
Z = ЁЦ x ЁЧ c ? c ( x c ) Z = \sum_{\bf{x}} \prod_{c} \phi_c(\bf{x}_c) Z=xЁЦ?cЁЧ??c?(xc?)
ИХТЪЭМФЃаЭЕФбЇЯА
-
ВЮЪ§бЇЯА: вбжЊЭМФЃаЭЕФНсЙЙ, бЇЯАФЃаЭЕФВЮЪ§;
-
НсЙЙбЇЯА: ДгЪ§ОнжаЭЦЖЯБфСПжЎМфЕФвРРЕЙиЯЕ;
Ш§епЕФСЊЯЕ
БДвЖЫЙЭјТч
ЕЋдкДЫжЎЧАвЊв§ШывЛаЉдЄБИжЊЪЖ;
ЦгЫиБДвЖЫЙ
-
БДвЖЫЙЙЋЪН
P ( A ЈO B ) = P ( B ЈO A ) P ( A ) P ( B ) P(A|B) = \frac{P(B|A)P(A)}{P(B)} P(AЈOB)=P(B)P(BЈOA)P(A)? -
ЛњЦїбЇЯАЯТЕФБДвЖЫЙЙЋЪН
АбBРэНтЮЊОпгаФГжжЬиеїX, АбAРэНтЮЊОпгаФГжжБъЧЉY;ИФаДБДвЖЫЙ:
P
(
Y
ЈO
X
)
=
P
(
X
ЈO
Y
)
P
(
Y
)
P
(
X
)
P(Y|X) = \frac{P(X|Y)P(Y)}{P(X)}
P(YЈOX)=P(X)P(XЈOY)P(Y)?
ЩюПЬРэНт ЩЯУцЕФЙЋЪНзѓБпЪЧвЊЧѓНтЕФЯШбщИХТЪ!!! гвБпЪЧДгРњЪЗЪ§ОнжаЛёШЁЕФ, РњЪЗЪ§ОнМДжЊЕРXКЭYвВФмМЦЫуP(X|Y), ЖјЮвУЧвЊЧѓЕФЪЧ, дквбжЊXЕФЬѕМўЯТYГіЯжЕФИХТЪ(вВОЭЪЧгЩвђЫїЙћ);
зЂвт ЩЯУцЙЋЪНГЩСЂЕФЬѕМў: ЬиеїМфЯрЛЅЖРСЂ
ЦфЪЕИњЮвУЧЕФPCAЕФНсЙћвЛбљ, ЦфЪЕвВИњЖрдЊЯпадЛиЙщЕФМйЩшвЛбљ(ЖрдЊЯпадЛиЙщВЛдЪаэГіЯжЖржиЙВЯпад, вђЮЊЯЕЪ§ВЛФмНтЪЭ, ЖјЛњЦїбЇЯАУЛгаетИіМйЩш, ЕЋЪЧДцдкЯрЙиЙиЯЕЛсШУЛњЦїбЇЯАЕФЪ§ОнжЪСПЯТНЕ, етРяВЛзіЯъЯИЬжТл)
- гЩЬиеїЖРСЂдйИФаДБДвЖЫЙ
дђга:
P
(
X
)
=
P
(
x
1
)
P
(
x
2
)
?
P
(
x
n
)
(
x
i
ЁЪ
X
(
i
=
1
,
2
,
Ё
,
n
)
P(X) = P(x_1)P(x_2)\cdots P(x_n) (x_i\in X(i=1,2,\ldots, n)
P(X)=P(x1?)P(x2?)?P(xn?)(xi?ЁЪX(i=1,2,Ё,n)
Ыљвд:
P
(
X
ЈO
Y
)
=
P
(
x
1
ЈO
Y
)
P
(
x
2
ЈO
Y
)
?
P
(
x
n
ЈO
Y
)
P(X|Y) = P(x_1|Y)P(x_2|Y)\cdots P(x_n|Y)
P(XЈOY)=P(x1?ЈOY)P(x2?ЈOY)?P(xn?ЈOY)
БДвЖЫЙЙЋЪН:
P
(
Y
ЈO
X
)
=
ЁЧ
i
=
1
n
P
(
x
i
ЈO
Y
)
P
(
Y
)
ЁЧ
i
=
1
n
P
(
x
i
)
P(Y|X) = \frac{\prod_{i=1}^{n}P(x_i|Y)P(Y)}{\prod_{i=1}^{n}P(x_i)}
P(YЈOX)=ЁЧi=1n?P(xi?)ЁЧi=1n?P(xi?ЈOY)P(Y)?
ЩЯЪНвВБЛГЦЮЊЦгЫиБДвЖЫЙ
БДвЖЫЙЭјТч
гаЯђЮоЛЗЭМФЃаЭ, ЪЧвЛжжФЃФтШЫРрЭЦРэЙ§ГЬжавђЙћЙиЯЕЕФВЛШЗЖЈДІРэФЃаЭ, ЦфЭјТчЭиЦЫЙЙдьЪЧвЛИігаЯђЮоЛЗЭМ;
БОжЪЛЙЪЧБДвЖЫЙФЧЬз
- ЪОвтЭМ
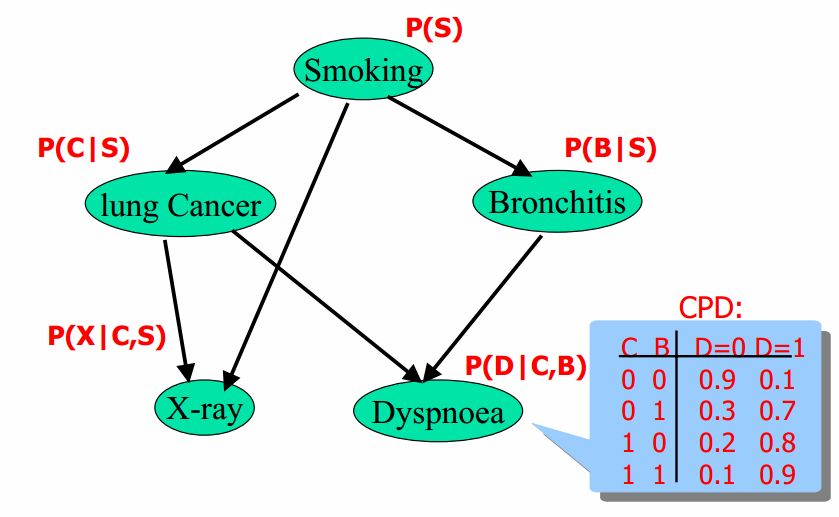
БДвЖЫЙЭјТчгаЯђЮоЛЗЭМжаЕФНкЕуБэЪОЫцЛњБфСП { x 1 , x 1 , Ё , x n } \{x_1, x_1, \ldots, x_n\} {x1?,x1?,Ё,xn?}(ПЩвдЪЧПЩЙлВтЕНЕФБфСПЁЂвўБфСПЁЂЮДжЊВЮЪ§ЕШ); ШЯЮЊгавђЙћЙиЯЕ(ЗЧЬѕМўЖРСЂ)ОЭПЩвдЯрСЌ;
ШчЩЯЭМжаЕФSmokingЛсЕМжТlung Cancer, ОЭПЩвдЯрСЌ, БпШЈжЕОЭЪЧЬѕМўИХТЪ;
ЬсЕНСЫЗЧЬѕМўЖРСЂ, ЮвУЧЯШЫЕЬѕМўЖРСЂ
ЬѕМўЖРСЂ
ЩЯЭМПЩвдБэЪОЮЊ
P
(
S
,
C
,
X
,
B
,
D
)
=
P
(
S
)
P
(
L
ЈO
X
)
P
(
B
ЈO
X
)
P
(
X
ЈO
C
,
S
)
P
(
D
ЈO
C
,
B
)
P(S,C,X,B,D) = P(S)P(L|X)P(B|X)P(X|C,S)P(D|C,B)
P(S,C,X,B,D)=P(S)P(LЈOX)P(BЈOX)P(XЈOC,S)P(DЈOC,B)
ЮЪЬтСЊКЯИХТЪЕФГЫЛ§ЮЊЪВУДФмБэЪООжВПЬѕМўИХТЪБэЕФГЫЛ§?
вђЮЊЬѕМўЖРСЂ;
3ИіживЊЕФСДНгФЃаЭ
-
head-to-tail(зюживЊ)
- cЮДжЊ
P ( a , b , c ) = p ( a ) p ( c ЈO a ) p ( b ЈO c ) ? p ( a , b ) = p ( a ) p ( b ) P(a,b,c) = p(a)p(c|a)p(b|c) \nRightarrow p(a,b) = p(a)p(b) P(a,b,c)=p(a)p(cЈOa)p(bЈOc)?p(a,b)=p(a)p(b)
Ыљвдa,bВЛЖРСЂ;
- cвбжЊ
P ( a , b ЈO c ) = P ( a , b , c ) P ( c ) = P ( a ) P ( c ЈO a ) P ( b ЈO c ) P ( c ) = P ( a c ) P ( b ЈO c ) P ( c ) = P ( a ЈO c ) P ( b ЈO c ) \begin{aligned} P(a,b|c) &= \frac{P(a,b,c)}{P(c)} \\ &= \frac{P(a)P(c|a)P(b|c)}{P(c)} \\ &= \frac{P(ac)P(b|c)}{P(c)} \\ &= P(a|c)P(b|c) \\ \end{aligned} P(a,bЈOc)?=P(c)P(a,b,c)?=P(c)P(a)P(cЈOa)P(bЈOc)?=P(c)P(ac)P(bЈOc)?=P(aЈOc)P(bЈOc)?
Ыљвдa,b(ЬѕМў)ЖРСЂ;
- cЮДжЊ
-
tail-to-tail
- cЮДжЊ
P ( a , b , c ) = p ( a ) p ( c ЈO a ) p ( b ЈO c ) ? p ( a , b ) = p ( a ) p ( b ) P(a,b,c) = p(a)p(c|a)p(b|c) \nRightarrow p(a,b) = p(a)p(b) P(a,b,c)=p(a)p(cЈOa)p(bЈOc)?p(a,b)=p(a)p(b)
Ыљвдa,bВЛЖРСЂ;
- cвбжЊ
{ P ( a , b ЈO c ) = P ( a , b , c ) P ( c ) P ( a , b , c ) = P ( c ) P ( a ЈO c ) P ( b ЈO c ) ? P ( a ЈO c ) P ( b ЈO c ) \begin{cases} P(a,b|c) = \frac{P(a,b,c)}{P(c)} \\ P(a,b,c) = P(c)P(a|c)P(b|c) \\ \end{cases} \Rightarrow P(a|c)P(b|c) {P(a,bЈOc)=P(c)P(a,b,c)?P(a,b,c)=P(c)P(aЈOc)P(bЈOc)??P(aЈOc)P(bЈOc)
Ыљвдa,b(ЬѕМў)ЖРСЂ;
- cЮДжЊ
-
head-to-head
- ЮоТлcжЊВЛжЊЕР
P ( a , b , c ) = P ( a ) P ( b ) P ( c ЈO a , b ) P(a,b,c) = P(a)P(b)P(c|a,b) P(a,b,c)=P(a)P(b)P(cЈOa,b)
Ыљвдa,bЖРСЂ;
- ЮоТлcжЊВЛжЊЕР
ЩюПЬРэНтЖРСЂгыЬѕМўЖРСЂ
ЖРСЂгыЬѕМўЖРСЂУЛЩЖЙиЯЕ, жЛЪЧзжУцЩЯКмЯрНќ;
-
ЖРСЂгыЬѕМўЖРСЂВЛФмЛЅЭЦ, ПДШчЯТЗДР§:-
ЕквЛИіЗДР§ЪЧЖРСЂЭЦВЛГіЬѕМўЖРСЂ:гаСНУЖе§ЗДИХТЪОљЮЊ 50% ЕФгВБв,ЩшЪТМў A ЮЊЕквЛУЖгВБвЮЊе§Уц,ЪТМў B ЮЊЕкЖўУЖгВБвЮЊе§Уц,ЪТМў C ЮЊСНУЖгВБвЭЌУцЁЃA КЭ B ЯдШЛЖРСЂ,ЕЋШчЙћ C вбОЗЂЩњ,МДвбжЊСНУЖгВБвЭЌУц,ФЧУД A КЭ B ОЭВЛ(ЬѕМў)ЖРСЂСЫЁЃ
-
ЕкЖўИіЗДР§ЪЧЬѕМўЖРСЂЭЦВЛГіЖРСЂ:гавЛУЖгВБве§УцЕФИХТЪЮЊ 99%,СэвЛУЖЗДУцЕФИХТЪЮЊ 99%,ЫцЛњФУГівЛУЖЭЖжРСНДЮ,ЪТМў A ЮЊЕквЛДЮЮЊе§Уц,ЪТМў B ЮЊЕкЖўДЮЮЊе§Уц,ЪТМў C ЮЊФУГіЕФЪЧЕквЛУЖгВБвЁЃПЩвдЫуГіРД P(B) = 0.5 ЕЋ P(B|A) = 0.9802,ЫЕУї A КЭ B ВЛЖРСЂ,ЕЋШчЙћ C вбОЗЂЩњ,МДвбжЊСЫФУГіЕФЪЧЕквЛУЖгВБв,ФЧУД A КЭ B ОЭ(ЬѕМў)ЖРСЂСЫЁЃ
-
ЛиЕН СЊКЯИХТЪЕФГЫЛ§БэЪОЮЊОжВПЬѕМўИХТЪБэЕФГЫЛ§
P ( S , C , X , B , D ) = P ( S ) P ( L ЈO X ) P ( B ЈO X ) P ( X ЈO C , S ) P ( D ЈO C , B ) P(S,C,X,B,D) = P(S)P(L|X)P(B|X)P(X|C,S)P(D|C,B) P(S,C,X,B,D)=P(S)P(LЈOX)P(BЈOX)P(XЈOC,S)P(DЈOC,B)
- ЙлВьетвЛЬѕ
ЕБвбжЊBronchitisЪБ, SomkingОЭгыDyspnoeaЯрЛЅЖРСЂСЫ, ЫљвдЫћСЉОЭУЛЩЖЙиЯЕ, DyspnoeaОЭжЛШЁОігкBronchitisСЫ,
ЫљвдОЭПЩвдНЋ
P
(
D
y
s
p
n
o
e
a
ЈO
B
r
o
n
c
h
i
t
i
s
,
S
o
m
k
i
n
g
)
аД
ГЩ
P
(
D
y
s
p
n
o
e
a
ЈO
B
r
o
n
c
h
i
t
i
s
)
P(Dyspnoea|Bronchitis, Somking)аДГЩP(Dyspnoea|Bronchitis)
P(DyspnoeaЈOBronchitis,Somking)аДГЩP(DyspnoeaЈOBronchitis)
ПДЕНСЫАЩ, ИХТЪЭМЕФгХЪЦОЭРДСЫ, ОЭАбдБОСНзщЕФВЮЪ§, ЛЏМђЮЊвЛзщСЫ;
ЯъНтБпШЈжЕ
ЩЯУцЫЕЕФВЮЪ§ОЭЪЧБпШЈжЕ, БпШЈжЕВХЪЧЮвУЧФЃаЭвЊбЕСЗЕФФЃаЭ!!!
ЩЯЭМРЖЩЋПђЕФОЭЪЧВЮЪ§, ШчЕквЛИіВЮЪ§0.9БэЪО: вбжЊC=0,B=0ЪБ, D=0ЕФИХТЪ;
ШчЙћВЛгУЭМНсЙЙРДБэЪОЕФЛА, ОЭЛЙашвЊвЛзщЁЏSЁЏЕФВЮЪ§(вђЮЊSвВМфНгжИЯђD), ФЧУДзѓБпЕФвЊ 2 ЁС 2 ЁС 2 = 8 2\times 2\times 2=8 2ЁС2ЁС2=8, ФЧУДВЮЪ§ЕФИіЪ§ОЭвЊ 8 ЁС 2 = 16 8\times 2=16 8ЁС2=16Иі;
ЫљвдЭМФЃаЭЕФЬѕМўЖРСЂИјЮвУЧМЋДѓЕФМѕЩйСЫФЃаЭЕФВЮЪ§;
дйЫЕЫЕЦгЫиБДвЖЫЙЮЊЩЖНаЦгЫи?
вђЮЊЦгЫиБДвЖЫЙМйЩшЫљгаздБфСПЖМЪЧЖРСЂЕФ, ШчЙћБэЪОдкЭМжаОЭЪЧУЛгаБпЕФЭМ, ШЋЪЧЩЂЕу, КмМђЕЅ, КмЦгЫи,ЫљвдвВНаЦгЫиБДвЖЫЙ;
БДвЖЫЙЭјТчОЭЪЧетбљСЫ, МЬајЯТвЛеТАЩ!pdЕФMachine Learning