Introduction
�������Щ���Ѿ������ೡ���еõ���Ӧ��,����һЩ������Ļ������Ի�û�б�����,��Ҳ�ǽ�Щ���о����ص㡣��������˵,������Ը�������perturbation��robustness�ܵ��˺ܴ�Ĺ�ע��ͼ1����������������small additive perturbation�Ĵ�����:
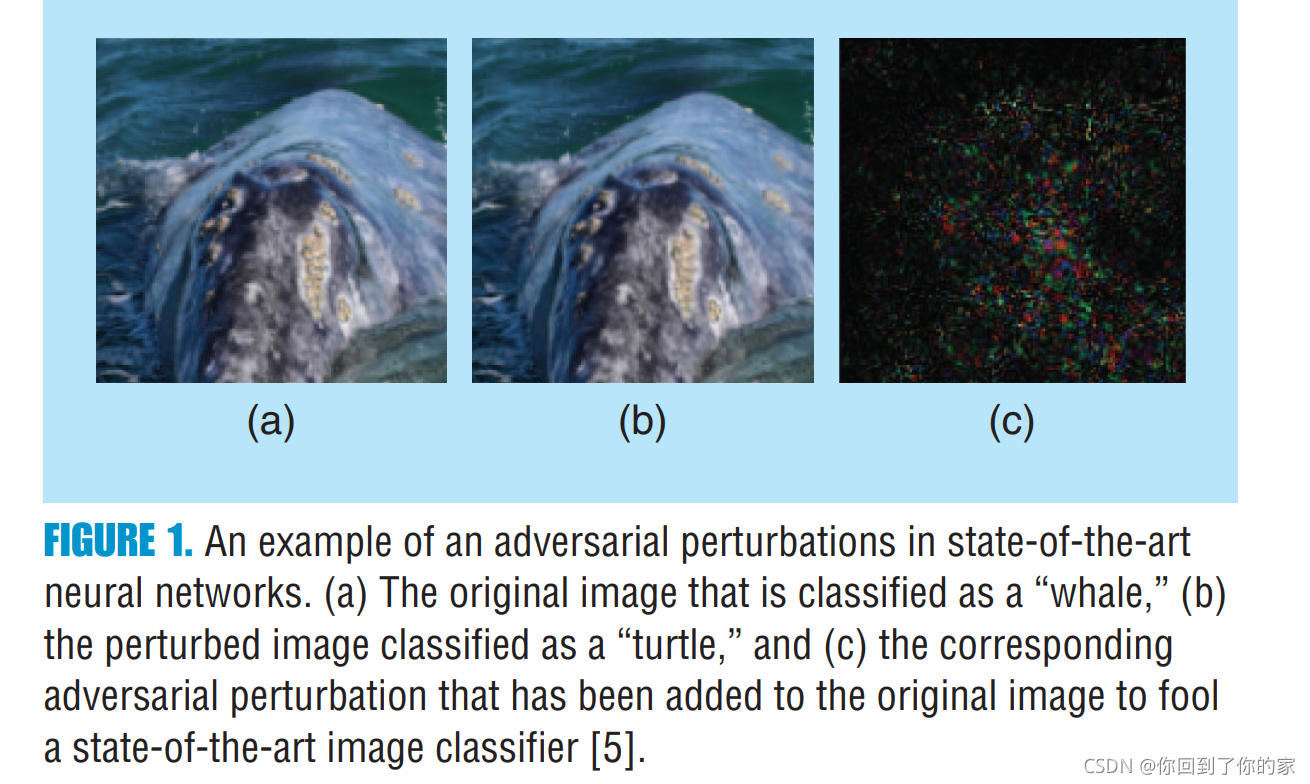
A dual phenomenon was observed in [3],��ʱ������ʶ���ͼƬ�ᱻ����������Ժܸߵ�confidence���з��ࡣ
The fundamental challenges raised by the robustness of deep networks to perturbation�Ѿ���������������Ҫ�Ĺ�������Щ������ʵ���Ϻ������϶���������ڲ�ͬ�����perturbation�ϵ�robustness�������о�,��Щperturbation����adversarial perturbations,additive random noise,structured transformations����universal perturbation��The robustness is usually measured as the sensitivity of the discrete classification function(��the function that assigns a label to each image)to such perturbation�����ܶ���robustness�ķ���������һ���µ�����,we provide an overview of the recent works that propose to assess the vulnerability of deep network architectures�����������ڸ���perturbations�������robustness,����robustness�ķ���has further contributed to developing important insights on the geometry of the complex decision boundary of such classifier, which remain hardly understood due to the very high dimensionality of the problems that they address��ʵ����,һ����������robustness���ʺ;��߽߱�ļ��������ǽ�����صġ�����,the high instability of ���������to �Կ��Ŷ���ʾ�����ݵ�reside extremely close to the classifier��s decision boundary������robustness���о���˲����ܰ������Ǵ�ʵ�ʽǶ�����ϵͳ���ȶ���,�����������������������ļ�����������ʹ������derives insight toward the improvement of current architectures��
��ƪ�����ж��Ŀ�ġ�First, it provides an accessible review of the recent works in the analysis of the robustness of deep neural network classifiers to different forms of perturbations, with a particular emphasis on image analysis and visual understanding applications. Second, it presents connections between the robustness of deep networks and the geometry of the decision boundaries of such classifiers. Third, the article discusses ways to improve the robustness in deep networks architectures and finally highlights some of the important open problems.
Robustness of classifiers
�ڴ�����ķ����趨��,�������ݼ��������ı������������۷���������Ҫperformance metric��The empirical test error�ṩ�˹��ڷ�������risk, defined as the probability of misclassification,when considering samples from the data distribution����ʽ����,�� �� \mu �� ����Ϊa distribution defined over images�������� f f f��risk�ȼ���:
R ( f ) = P x �� �� ( f ( x ) �� y ( x ) ) ( 1 ) R(f)=\mathbb{P}_{x\sim\mu}(f(x)\ne y(x))\quad\quad\quad\quad\quad\quad(1) R(f)=Px����?(f(x)��?=y(x))(1)
x x x�� y ( x ) y(x) y(x)�ֱ��Ӧ��ͼƬ��ͼƬ��label��While the risk captures the error of f f f on the data distribution �� \mu ��,����û�в���the robustness to small arbitrary perturbations of data points�����Ӿ�����������,����һ���Ƚ����е�������ѧϰ��classifiers that achieve robustness to small perturbation to images��
���ﶨ��һЩ����,�� X \mathcal{X} X��ʾthe ambient space where images live���� R \mathcal{R} R��ʾ�������������Ŷ����ϡ�����,������geometric perturbationʱ, R \mathcal{R} R is set to be the group of geometric(�� affine)transformation under study�����������Ҫ����������additive perturbation�µ�robustness,��ô�����趨 R = X \mathcal{R}=\mathcal{X} R=X���� r �� R r\in\mathcal{R} r��R,���Ƕ��� T r : X �� X T_r:\mathcal{X}\to\mathcal{X} Tr?:X��Xto be the perturbation operator by r r r,����һ�����ݵ� x �� X x\in\mathcal{X} x��X, T r ( x ) T_r(x) Tr?(x)��ʾ�� r r r�Ŷ����ͼƬ x x x��ʹ��������Щnotations,���ǽ��ı��б�������ͼƬ x x x��label����Сperturbation����Ϊ:
r ? ( x ) = arg?min ? r �� R �� r �� R s u b j e c t ? t o f ( T r ( x ) ) �� f ( x ) ( 2 ) r^*(x)=\argmin\limits_{r\in\mathcal{R}}\Vert r\Vert_{R}\quad\quad\quad\quad\quad\quad\quad\quad\quad\\subject\ to\quad f(T_r(x))\ne f(x)\quad\quad\quad\quad\quad\quad\quad\quad\quad(2) r?(x)=r��Rargmin?��r��R?subject?tof(Tr?(x))��?=f(x)(2)
���� �� ? �� R \Vert \cdot\Vert_R ��?��R? �� R \mathcal{R} R �ϵ�metric��Ϊ��notation simplicity,����ʡ����the dependence of r ? ( x ) r^*(x) r?(x) on f f f, R \mathcal{R} R, �� \delta ��and operator T T T��Moreover,��ͼƬ x x x is clear from the context,we will use r ? r^* r? to refer to r ? ( x ) r^*(x) r?(x)��ͼ2���Ŷ����̽����˲���:
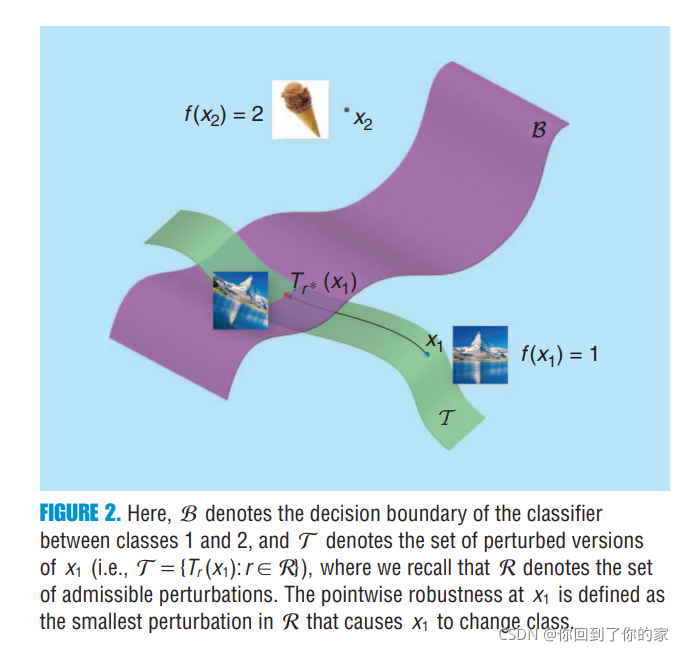
The pointwise robustness of
f
f
f at
x
x
x ���ͨ��
��
r
?
(
x
)
��
R
\Vert r^*(x)\Vert_{\mathcal{R}}
��r?(x)��R?���к�����ע��
��
?
��
R
\Vert\cdot\Vert_{\mathcal{R}}
��?��R?ֵԽ�����
x
x
x����robustnessԽ�ߡ���������robustness�Ķ��忼�ǵ���ʹ�÷�����
f
f
f�ı����Ľ����smallest perturbation
r
?
(
x
)
r^*(x)
r?(x),�����Ĺ���ȴ������һЩ����ͬ�Ķ���,��Щ������a ��sufficiently small�� perturbation is sought(instead of the minimal one)[7-9]��Ϊ�˺���������
f
f
f��global robustness,���ǿ��Լ���
��
r
?
(
x
)
��
R
\Vert r^*(x)\Vert_{\mathcal{R}}
��r?(x)��R?�����ݷֲ��ϵ������������global robustness
��
(
f
)
\rho(f)
��(f)����ͨ�����µķ�ʽ���ж���:
�� ( f ) = E x �� �� ( �� r ? ( x ) �� R ( 3 ) \rho(f)=\mathbb{E}_{x\sim\mu}(\Vert r^*(x)\Vert_{\mathcal{R}}\quad\quad\quad\quad\quad\quad(3) ��(f)=Ex����?(��r?(x)��R?(3)
��Ҫע��ıȽ���Ҫ��һ����,�����ǵ�robustness setting��,the perturbed point T r ( x ) T_r(x) Tr?(x) need not belong to the support of the data distribution�����,����the focus of the risk in(1)is the accuracy on typical images(�� �� \mu ���н��в���),the focus of the robustness computed from (2)is instead on the distance to the ��closest�� image(potentially outside the support of �� \mu ��)that changes the label of the classifier��The risk and robustness hence capture two fundamentally different properties of the classifier,����������:

Observe that classification robustness��֧��������classifier�н�ǿ�Ĺ���,���ߵ�Ŀ�������robustness,defined as the margin between support vectors. Importantly, the max-margin classifier in a given family of classifiers might, however, still not achieve robustness (in the sense of high
��
(
f
)
\rho(f)
��(f)). An illustration is provided in ��Robustness and Risk: A Toy Example,�� where a no zero-risk linear classifier��in particular, the max-margin classifier�� achieves robustness to perturbations. Our focus in this article is turned toward assessing the robustness of the family of deep neural network classifiers that are used in many visual recognition tasks.
Perturbation forms
Robustness to additive perturbations
We first start by considering the case where the perturbation operator is simply additive,�� T r ( x ) = x + r T_r(x)=x+r Tr?(x)=x+r�������������, the magnitude of the perturbation can be measured with the l p l_p lp? norm of the minimal perturbation that is necessary to change the label of a classifier. According to (2), the robustness to additive perturbations of a data point x is defined as:
min ? r �� R �� r �� p s u b j e c t ? t o f ( x + r ) �� f ( x ) ( 4 ) \min\limits_{r\in\mathcal{R}}\Vert r\Vert_p\quad\quad\quad\quad\quad\quad\quad\quad\\subject\ to\quad f(x+r)\ne f(x)\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad(4) r��Rmin?��r��p?subject?tof(x+r)��?=f(x)(4)
Depending on the conditions that one sets on the set R \mathcal{R} R that supports the perturbations, the additive model leads to different forms of robustness.
Adversarial perturbations
�������ȿ���additive perturbations�������Ƶ����,�� R = X \mathcal{R}=\mathcal{X} R=X��ͨ�����(4)�õ���perturbationͨ��������adversarial perturbation, as it corresponds to the perturbation that an adversary (having full knowledge of the model) would apply to change the label of the classifier, while causing minimal changes to the original image.
The optimization problem in (4) is nonconvex, as the constraint involves the (potentially highly complex) classification function f f f. Different techniques exist to approximate adversarial perturbations. In the following, we briefly mention some of the existing algorithms for computing adversarial perturbations:
Regularized variant[1]: ���ַ�ʽͨ�����a regularized variant of the problem in (4)����ȡadversarial perturbation,�������������������µĹ�ʽ��������:
min ? r c �� r �� p + J ( x + r , y ~ , �� ) ( 5 ) \min\limits_{r}c\Vert r\Vert_p+J(x+r,\tilde{y},\theta)\quad\quad\quad\quad\quad(5) rmin?c��r��p?+J(x+r,y~?,��)(5)
���� y ~ \tilde{y} y~?��perturbed sample��target label, J J J��loss function, c c c��һ��regularization ����, �� \theta ����ģ�Ͳ�������[1]����ԭʼ�Ĺ�ʽ��,������һ������ı�����������֤ x + r �� [ 0 , 1 ] x+r\in[0,1] x+r��[0,1],����(5)��Ϊ�˼��Խ�����ʡ�ԡ�Ϊ�˽��(5)�е��Ż�����,a line search is performed over c c c to find the maximum c > 0 c>0 c>0 for which the minimizer of (5) satisfies f ( x + r ) = y ~ f(x+r)=\tilde{y} f(x+r)=y~?�����ܿ��Բ����dz����Ĺ���,���ַ���can be costly to compute on high-dimensional and large-scale datasets��Moreover,it computes targeted adversarial perturbation,where the target label is known��
Fast gradient sign(FGS)[11]:���ַ�ʽͨ��going in the direction of the sign of gradient of the loss function������an untargeted adversarial perturbation,loss function��������:
? s i g n ( ? x J ( x , y ( x ) , �� ) ) \epsilon sign(\nabla_xJ(x,y(x),\theta)) ?sign(?x?J(x,y(x),��))
���� J J J��loss function,����ѵ�������粢�� �� \theta ����ʾģ�Ͳ���������ʮ�ָ�Ч,����one-step���㷨�����ṩa coarse approximation to the solution of the optimization problem in (4) for p = �� p=\infty p=��
DeepFool[5]: ����㷨ͨ��һ�������IJ�������С��(4),where each iteration involves the linearization of the constraint��The linearized (constrained)problem is solved in closed form at each iteration,and the current estimate is updated;�Ż����̵���ǰ��estimate of the perturbation fools the classifierʱ��ֹ��In practice,DeepFool provides a tradeoff between the accuracy and efficiency of the two previous approaches��
In addition to the aforementioned optimization methods, several other approaches have recently been proposed to compute adversarial perturbations, see, e.g., [9], [12], and [13]. Different from the previously mentioned gradient-based techniques, the recent work in [14] learns a network (the adversarial transformation network) to efficiently generate a set of perturbations with a large diversity, without requiring the computation of the gradients.
ʹ����ǰ�ἰ������Щ����, one can compute the robustness of classifiers to additive adversarial perturbations. Quite surprisingly, deep networks are extremely vulnerable to such additive perturbations; i.e.,
small and even imperceptible adversarial perturbations can be computed to fool them with high probability. For example, the average perturbations required to fool the CaffeNet [15] and GoogleNet [16] architectures on the ILSVRC 2012 task [17] are 100 times smaller than the typical norm of natural images [5] when using the
l
2
l_2
l2? norm. The high instability of deep neural networks to adversarial perturbations, which was first highlighted in [1], shows that these networks rely heavily on proxy concepts to classify objects, as opposed to strong visual concepts typically used by humans to distinguish between objects.
To illustrate this idea, we consider once again the toy classification example (see ��Robustness and Risk: A Toy Example��), where the goal is to classify images based on the orientation of the stripe. In this example, linear classifiers could achieve a perfect recognition rate by exploiting the imperceptibly small bias that separates the two classes. While this proxy concept achieves zero risk, it is not robust to perturbations: one could design an additive perturbation that is as simple as a minor variation of the bias, which is sufficient to induce data misclassification. On the same line of thought, the high instability of classifiers to additive perturbations observed in [1] suggests that deep neural networks potentially capture one of the proxy concepts that separate the different classes. Through a quantitative analysis of polynomial classifiers, [10] suggests that higher-degree classifiers tend to be more robust to perturbations, as they capture the ��stronger�� (and more visual) concept that separates the classes (e.g., the orientation of the stripe in Figure S1 in ��Robustness and Risk: A Toy Example��). For neural networks, however, the relation between the flexibility of the architecture (e.g., depth and breadth) and adversarial robustness is not well understood and remains an open problem.
Random noise
������
Geometric insights from robustness
��robustness���о��������ǻ�ù���classifier��insights,��ȷ�ؽ�,�ǹ���the geometry of the
classification function acting on the high-dimensional input space.
f
:
X
��
{
1
,
]
��
,
C
}
f:\mathcal{X}\to\{1,]\dots,C\}
f:X��{1,]��,C}ָ�����ǵ�C-class������, ����������
g
1
,
��
,
g
c
g_1,\dots,g_c
g1?,��,gc? ��ʾ��������
C
C
C�����е�ÿ���ж��ĸ��ʡ��ر��,����һ��������
x
��
X
x\in\mathcal{X}
x��X,
f
(
x
)
f(x)
f(x) is assigned to the class having a maximal score,��
f
(
x
)
=
a
r
g
m
a
x
i
{
(
g
i
(
x
)
}
f(x)=argmax_i\{(g_i(x)\}
f(x)=argmaxi?{(gi?(x)}���������������,����
g
i
g_i
gi?�������������һ������(ͨ��ָsoftmax��)��Note that the classifier
f
f
f can be seen as a mapping that partitions the input space
X
\mathcal{X}
X into classification regions, each of which has a constant estimated label (i.e.,
f
(
x
)
f(x)
f(x) is constant for each such region). The decision boundary
B
\mathcal{B}
B of the classifier is defined as the union of the boundaries of such classification regions (see Figure 2).
Adversarial perturbations
�������Ⱦ۽���adversarial perturbation����highlight��Щ�Ŷ��;��߽߱缸�νṹ�Ĺ�ϵ�����ֹ�ϵrelies on the simple observation shown in ��Geometric Properties of Adversarial Perturbations.���������������ʶ���ͼ6�н�����չʾ:
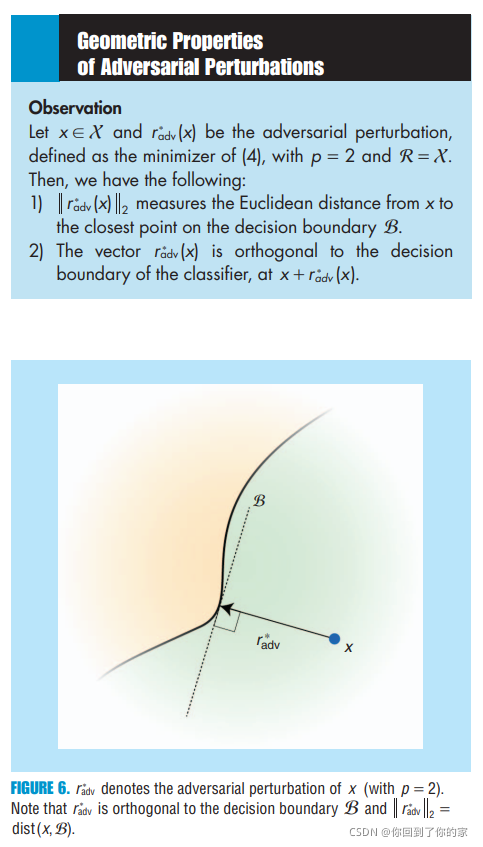
ע����Щ��������are specific to the
l
2
l_2
l2?���� The high instability of classifiers to adversarial perturbations, which we highlighted in the previous section, ��ʾ����ȻͼƬ��λ�ڷdz��ӽ��ھ��߽߱��λ�á�����������������the geometry of the data points with regard to the classifier��s���߽߱�Ĺؼ�,����û���ṩ�κ��й��ھ��߽߱���״��insight . һ�����ھ��߽߱��local geometric���� (λ��
x
x
x����Χ����) is rather capturedͨ��
r
a
d
v
?
(
x
)
r^*_{adv}(x)
radv??(x)�ķ���,due to adversarial perturbation�Ĵ�ֱ��. In [18] and [25], ��Щadversarial perturbation�ļ������ʱ����������������ݵ����Χ�������ӻ����߽߱��typical cross sections. �ر��,a two-dimensional normal section of the decision boundary is illustrated, where the sectioning plane is spanned by the adversarial perturbation (��ֱ�ھ��߽߱�) and a random vector in the tangent space. Examples of normal sections of decision boundaries are illustrated in Figure 7:
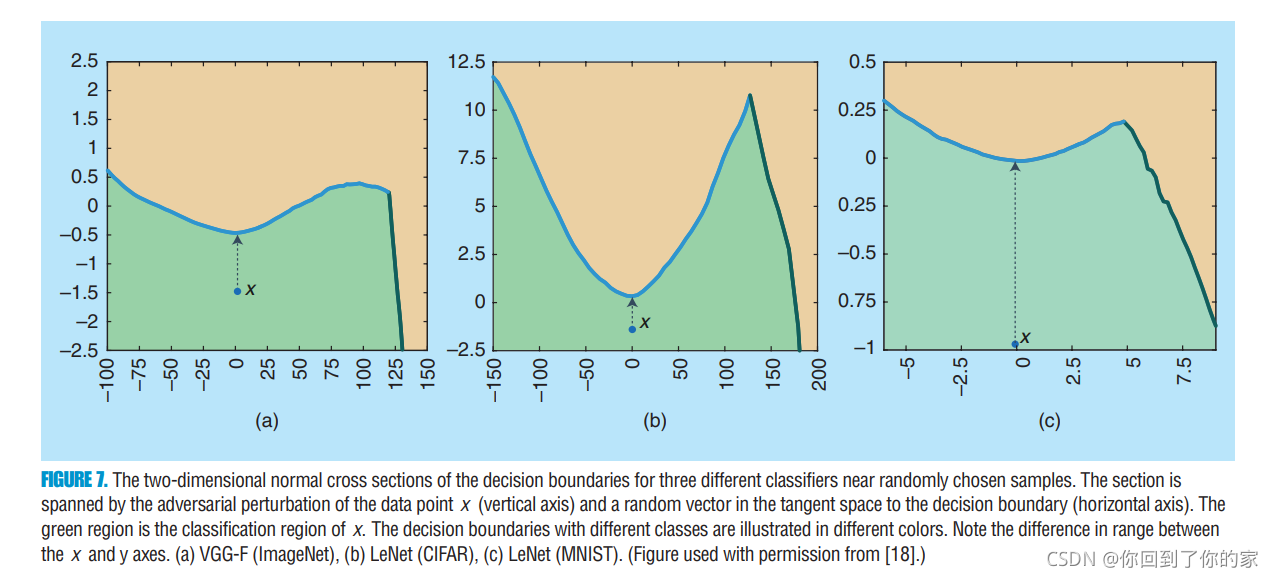
���ǿ��Թ۲쵽SOTA���������ľ��߽߱�on these two-dimensional cross sections��һ���dz��͵�curvature (ע��x���y�������n)�����仰˵,��Щͼ����ʾ��
x
x
x����λ�õľ��߽߱�can be locally well approximated by a hyperplane passing through
x
+
r
a
d
v
?
(
x
)
x+r^*_{adv}(x)
x+radv??(x) with the normal vector
r
a
d
v
?
(
x
)
r^*_{adv}(x)
radv??(x)�� In [11], it is hypothesized that state-of-the-art classifiers are ��too linear,�� �����˾��߽߱�with very small curvature����һ�������� the high instability of such classifiers to adversarial perturbations. To motivate the linearity hypothesis of deep networks, the success of the FGS method (which is exact for linear classifiers) in finding adversarial perturbations is invoked. Ȼ��,�����һЩ���������Լ�����������ս,����[26], the authors show that there exist adversarial perturbations that cannot be explained with this hypothesis, and, in [27], the authors provide a new explanation based on the tilting of the decision boundary with respect to the data manifold. We stress here that the low curvature of the decision boundary does not, in general, imply that the function learned
by the deep neural network (as a function of the input image) is linear, or even approximately linear. Figure 8 shows illustrative examples of highly nonlinear functions resulting in flat decision boundaries.:
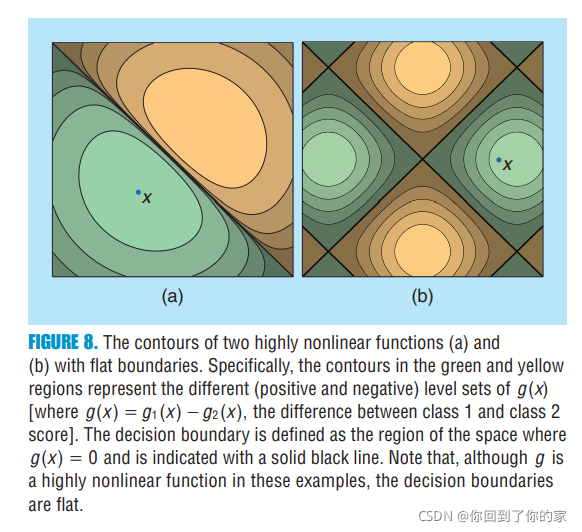
Moreover, it should be noted that, while the decision boundary of deep networks is very flat on random two-dimensional cross sections, these boundaries are not flat on all cross sections. That is, there exist directions in which the boundary is very curved. Figure 9 provides some illustrations of such cross sections, where the decision boundary has large curvature and therefore significantly departs from the first-order linear approximation, suggested by the flatness of the decision boundary on random sections in Figure 7.:
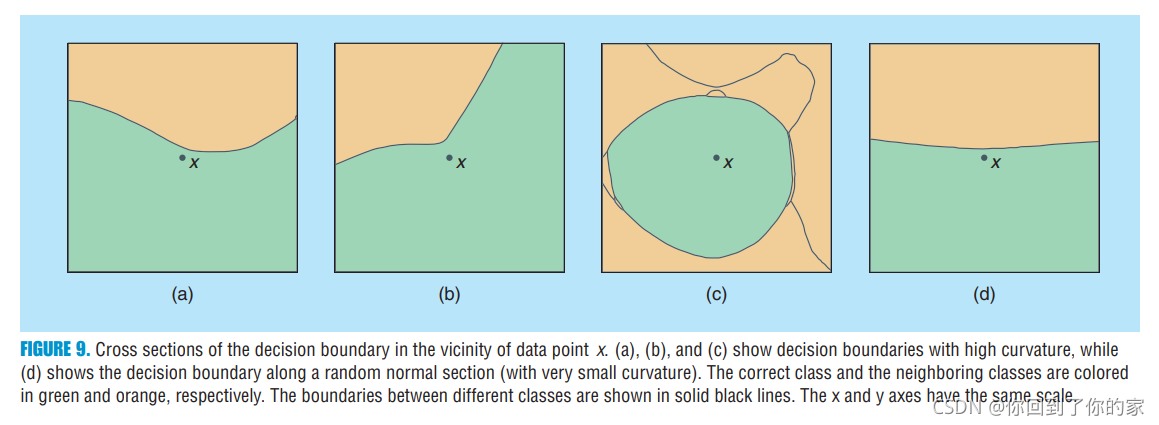
Hence, these visualizations of the decision boundary strongly suggest that the curvature along a small set of directions can be very large and that the curvature is relatively small along random directions in the input space. Using a numerical computation of the curvature, the sparsity of the curvature profile is empirically verified in [28] for deep neural networks, and the directions where the decision boundary is curved are further shown to play a major role in explaining the robustness properties of classifiers. In [29], the authors provide a complementary analysis on the curvature of the decision boundaries induced by deep networks and show that the first principal curvatures increase exponentially with the depth of a random neural network. The analyses of [28] and [29] hence suggest that the curvature profile of deep networks is highly sparse (i.e., the decision boundaries are almost flat along most directions) but can have a very large curvature along a few directions.
Universal perturbations
������