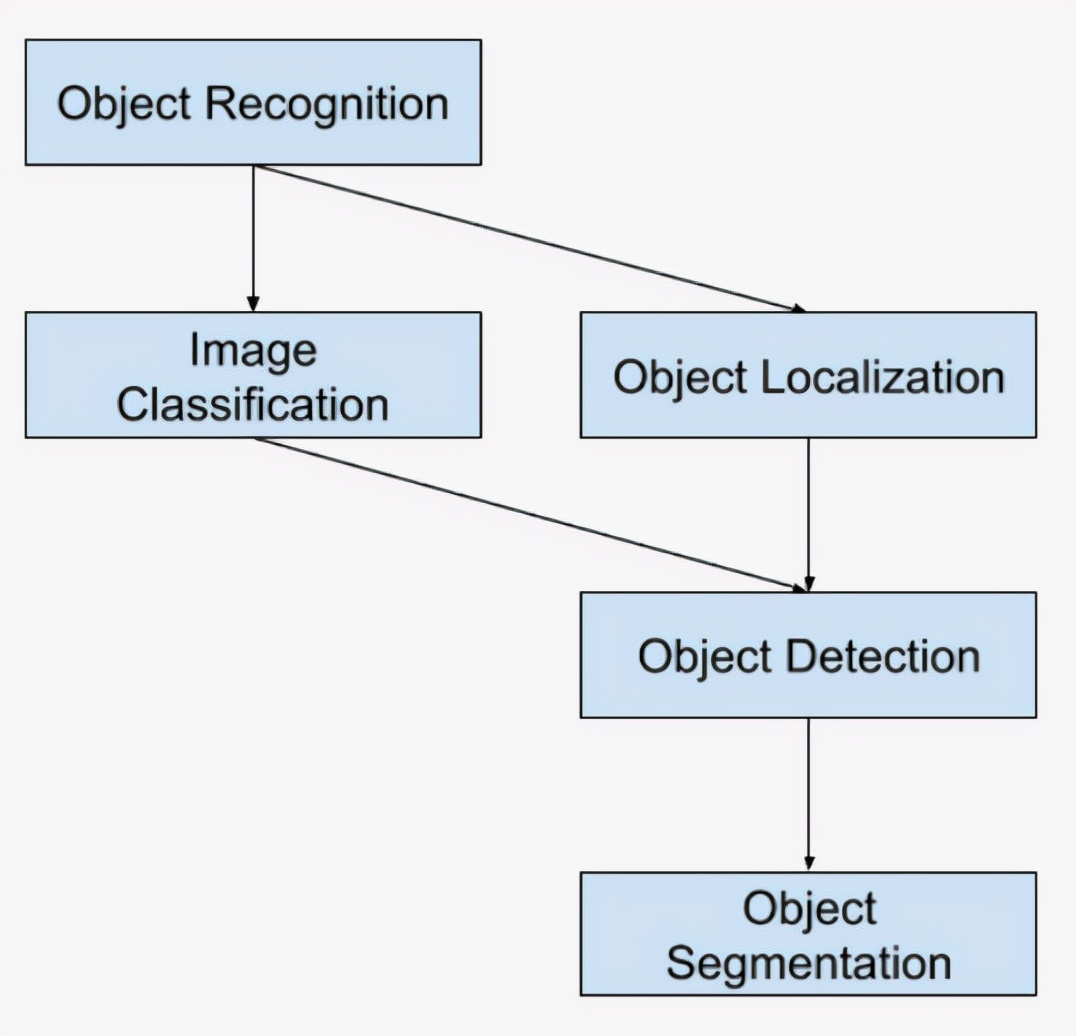
初学者区分不同的相关计算机视觉任务可能具有挑战性。例如,图像分类比较易于理解,但目标定位和目标检测之间的差异可能会令人困惑,尤其是当所有三个任务都可以等同地称为目标识别时。

图像分类涉及为图像分配类标签,而目标定位涉及在图像中的一个或多个对象周围绘制边界框。目标检测更具挑战性,它结合了这两个任务,并在图像中的每个感兴趣的目标周围绘制一个边界框,并为它们分配一个类标签。所有这些问题统称为目标识别。
在这篇文章中,你将发现对目标识别问题和旨在解决该问题的最先进深度学习模型的详细介绍。看完这篇文章,你就会知道:
- 物体识别是指用于识别数码照片中物体的相关任务的集合。
- 基于区域的卷积神经网络或 R-CNN 是一系列用于解决目标定位和识别任务的技术,专为提高模型性能而设计。
- You Only Look Once,或 YOLO,是为速度和实时使用而设计的第二类对象识别技术。
什么是物体识别?
物体识别是一个通用术语,用于描述涉及识别照片中的物体的相关计算机视觉任务的集合。
图像分类涉及预测图像中一个目标的类别。 目标定位是指识别图像中一个或多个对象的位置并在其范围周围绘制边界框。 目标检测结合了这两个任务,并对图像中的一个或多个对象进行定位和分类。

因此,我们可以区分这三个计算机视觉任务:
图像分类:预测图像中对象的类型或类别。
- 输入:具有单个物体的图像,例如照片。
- 输出:一个类标签(例如一个或多个映射到类标签的整数)。
目标定位:定位图像中存在的对象并用边界框指示它们的位置。
- 输入:包含一个或多个物体的图像,例如照片。
- 输出:一个或多个边界框(例如由一个点、宽度和高度定义)。
目标检测:使用边界框定位目标的存在以及图像中所定位物体的类型或类别。
- 输入:包含一个或多个物体的图像,例如照片。
- 输出:一个或多个边界框(例如由一个点、宽度和高度定义),以及每个边界框的类标签。
对这种计算机视觉任务细分的进一步扩展是目标分割,也称为“目标实例分割”或“语义分割”,其中通过突出显示物体的特定像素而不是粗边界框来指示已识别物体的实例。从这个细分中,我们可以看到对象识别是指一组具有挑战性的计算机视觉任务。
大多数图像识别问题的最新创新都是参与 ILSVRC 任务的一部分。这是一年一度的学术竞赛,针对这三种问题类型中的每一种都有单独的挑战,目的是在可以更广泛地利用的每个级别上促进独立和单独的改进。例如,请参阅以下三种相应任务类型的列表:
- 图像分类:算法生成图像中存在的目标类别列表。
- 单目标定位:算法生成图像中存在的目标类别列表,以及一个轴对齐的边界框,指示每个目标类别的一个实例的位置和比例。
- 目标检测:算法生成图像中存在的目标类别列表以及轴对齐的边界框,指示每个目标类别的每个实例的位置和比例。
我们可以看到“单目标定位”是更广泛定义的“目标定位”的更简单版本,将定位任务限制在图像中的一种类型的目标上,我们可以假设这是一个更容易的任务。下面是一个比较单个对象定位和对象检测的示例,取自 ILSVRC 论文。
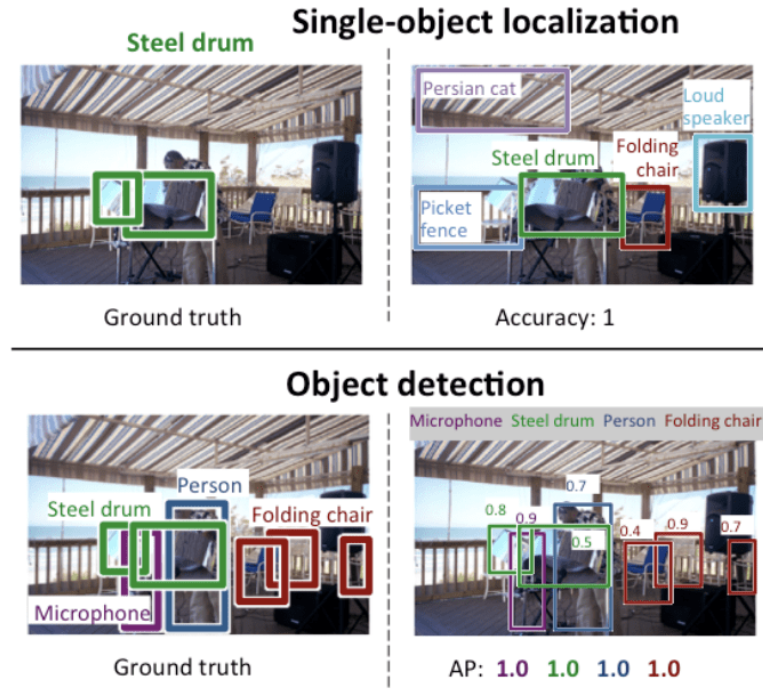
使用预测类标签的平均分类误差来评估图像分类模型的性能。使用预期类的预期边界框和预测边界框之间的距离来评估单对象定位模型的性能。而使用图像中已知对象的每个最佳匹配边界框的精度和召回率来评估对象识别模型的性能。
现在我们已经熟悉了对象定位和检测的问题,让我们来看看一些最近表现最好的深度学习模型。
R-CNN 模型
R-CNN 系列方法指的是 R-CNN,它可能代表“具有 CNN 特征的区域”或“基于区域的卷积神经网络”,由 Ross Girshick 等人开发。
这包括为目标定位和目标识别而设计和演示的 R-CNN、Fast R-CNN 和 Faster-RCNN 技术。
1)卷积神经网络(R-CNN)
R-CNN 在 Ross Girshick 等人论文中有所描述。它可能是卷积神经网络在目标定位、检测和分割问题上的首次大规模成功应用之一。该方法在基准数据集上得到了证明,在 VOC-2012 数据集和 200 类 ILSVRC-2013 对象检测数据集上取得了当时最先进的结果。
他们提出的 R-CNN 模型由三个模块组成; 他们是:
- 模块 1:区域提案。生成和提取类别独立区域提议,例如:候选边界框。
- 模块 2:特征提取器。从每个候选区域中提取特征,例如:使用深度卷积神经网络。
- 模块 3:分类器。将特征分类为已知类别之一,例如:线性 SVM 分类器模型。
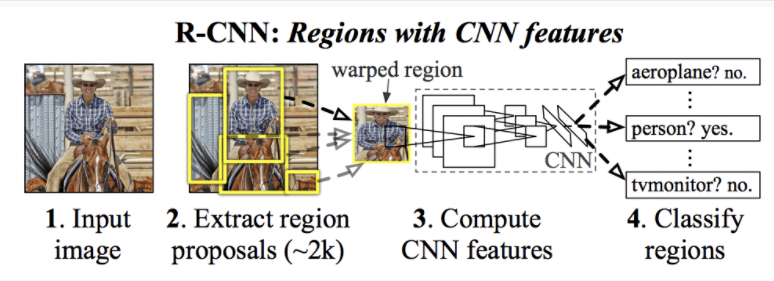
计算机视觉技术用于在称为“选择性搜索”的图像中提出候选区域或潜在目标的边界框,尽管设计的灵活性允许使用其他区域提议算法。
该模型使用的特征提取器是在 ILSVRC-2012 图像分类竞赛中获胜的 AlexNet deep CNN。 CNN 的输出是一个 4,096 元素的向量,它描述了图像的内容,该向量被馈送到线性 SVM 进行分类,具体而言,每个已知类别训练一个 SVM。
这是CNNs在物体定位和识别问题上的一个相对简单直接的应用。该方法的缺点是速度较慢,需要对区域提议算法生成的每个候选区域进行基于 CNN 的特征提取。这是一个问题,因为该论文描述了在测试时对每个图像大约 2,000 个提议区域进行操作的模型。

2)Fast R-CNN
鉴于 R-CNN 的巨大成功,当时在微软研究院工作的 Ross Girshick 在 2015 年的一篇题为“Fast R-CNN”的论文中提出了一个扩展来解决 R-CNN 的速度问题。
该论文首先回顾了 R-CNN 的局限性,总结如下:
- 训练是一个多阶段的管道。涉及三个独立模型的准备和操作。
- 训练在空间和时间上都是昂贵的。在每张图像上训练如此多的区域建议的深度 CNN 非常慢。
- 目标检测很慢。使用深度 CNN 对如此多的区域建议进行预测非常慢。
Fast R-CNN 被提议作为单个模型而不是管道来直接学习和输出区域和分类。
该模型的架构将照片中的一组区域提议作为输入,通过深度卷积神经网络传递。预训练的 CNN,例如 VGG-16,用于特征提取。深度 CNN 的末端是一个自定义层,称为感兴趣区域池化层或 RoI 池化层,它提取特定于给定输入候选区域的特征。
CNN 的输出然后由全连接层解释,然后模型分为两个输出,一个用于通过 softmax 层进行类别预测,另一个用于边界框的线性输出。然后对给定图像中的每个感兴趣区域重复此过程多次。
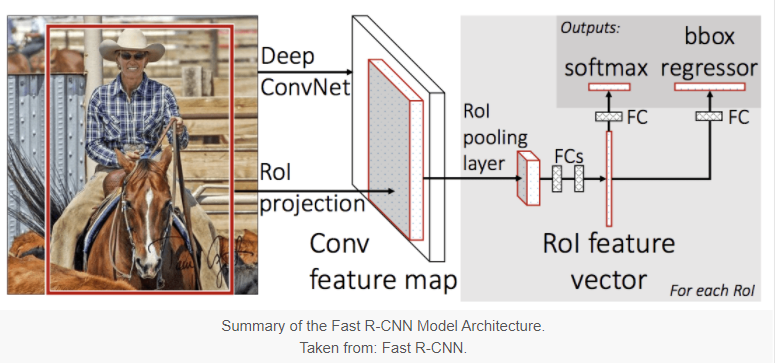
该模型的训练和预测速度明显更快,但仍然需要与每个输入图像一起提出一组候选区域。
3)Faster R-CNN
Shaoqing Ren 等人进一步改进了模型架构,以提高训练速度和检测速度。在 Microsoft Research 的 2016 年论文“Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks”中。
该架构是在 ILSVRC-2015 和 MS COCO-2015 目标识别和检测竞赛任务中获得第一名的基础。该架构旨在作为训练过程的一部分提出和改进区域提案,称为区域提案网络或 RPN。然后,在单个模型设计中,这些区域与 Fast R-CNN 模型一起使用。这些改进既减少了区域提议的数量,又将模型的测试时间操作加速到接近实时,并具有当时最先进的性能。
虽然它是一个单一的统一模型,但该架构由两个模块组成:
- 模块 1:区域提案网络。 用于提议区域和该区域中要考虑的对象类型的卷积神经网络。
- 模块 2:Fast R-CNN。 用于从建议区域提取特征并输出边界框和类别标签的卷积神经网络。
两个模块都在深度 CNN 的相同输出上运行。 区域提议网络充当 Fast R-CNN 网络的注意力机制,通知第二个网络看或注意的地方。
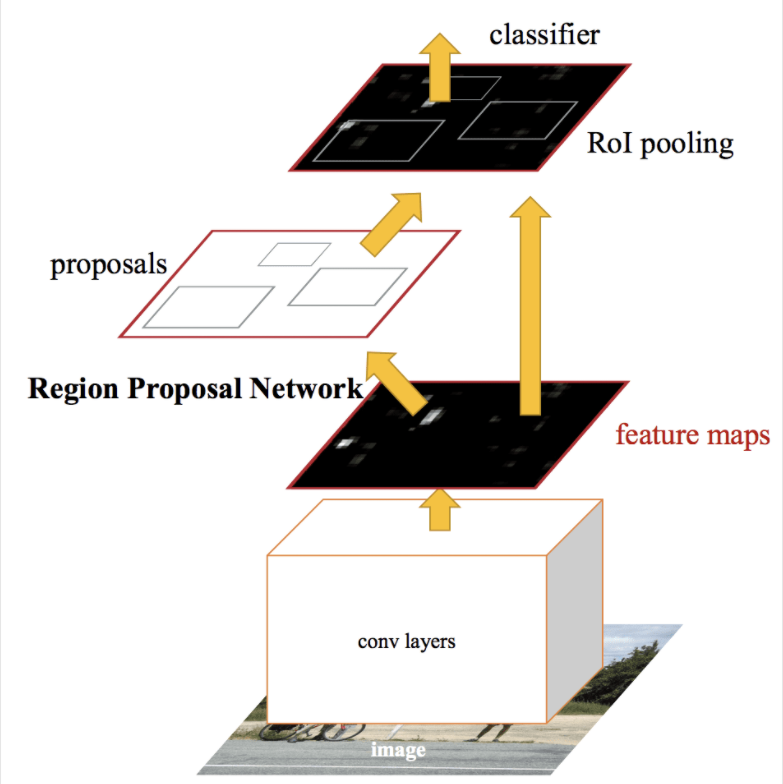
RPN 的工作原理是获取预训练的深度 CNN(例如 VGG-16)的输出,并在特征图上传递一个小网络,并为每个区域建议输出多个区域建议和类别预测。区域提议是边界框,基于所谓的锚框或预定义形状,旨在加速和改进区域提议。类别预测是二元的,表明存在或不存在对象,即提议区域的所谓“对象性”。
在两个子网络同时训练的情况下使用交替训练的过程,尽管是交错的。这允许同时为两个任务定制或微调特征检测器深度 CNN 中的参数。
YOLO 模型系列
另一个流行的对象识别模型系列统称为 YOLO 或“你只看一次(You Only Look Once)”,由 Joseph Redmon 等人开发。
R-CNN 模型通常可能更准确,但 YOLO 系列模型速度快,比 R-CNN 快得多,可以实时实现目标检测。
1)YOLO
YOLO 模型首先由 Joseph Redmon 等人描述。 在 2015 年题为“You Only Look Once:统一的实时目标检测”的论文中。请注意,R-CNN 的开发者 Ross Girshick 也是这项工作的作者和贡献者,然后是 Facebook AI Research。
该方法涉及一个端到端训练的单个神经网络,它将照片作为输入并直接预测每个边界框的边界框和类标签。 该技术提供较低的预测准确度(例如,更多的定位错误),尽管以每秒 45 帧的速度运行,对于速度优化版本的模型,每秒运行速度高达 155 帧。
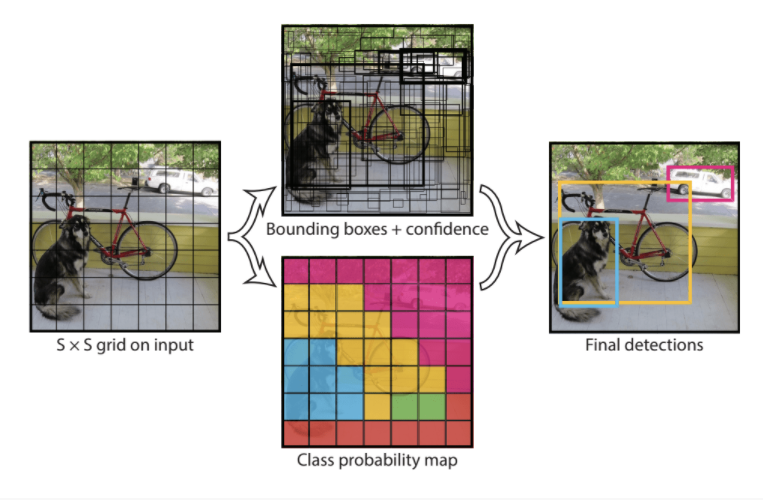
该模型首先将输入图像拆分为一个单元格网格,如果边界框的中心落在单元格内,则每个单元格负责预测边界框。 每个网格单元预测一个包含 x、y 坐标以及宽度和高度以及置信度的边界框。 类别预测也基于每个单元格。
例如,一张图像可能被划分为一个 7×7 的网格,网格中的每个单元格可以预测 2 个边界框,从而产生 94 个建议的边界框预测。 然后将类概率图和具有置信度的边界框组合成一组最终的边界框和类标签。 从下面的论文中截取的图像总结了模型的两个输出。
2)YOLOv2 (YOLO9000) and YOLOv3
该模型由 Joseph Redmon 和 Ali Farhadi 在其 2016 年题为“YOLO9000:更好、更快、更强”的论文中更新,以进一步提高模型性能。
尽管该模型的这种变体被称为 YOLO v2,但描述了该模型的一个实例,该实例在两个目标识别数据集上并行训练,能够预测 9,000 个目标类别,因此命名为“YOLO9000”。
对模型进行了许多训练和架构更改,例如使用批量归一化和高分辨率输入图像。
与 Faster R-CNN 一样,YOLOv2 模型使用锚框,这是在训练期间定制的具有有用形状和大小的预定义边界框。图像边界框的选择是使用对训练数据集的 k 均值分析进行预处理的。
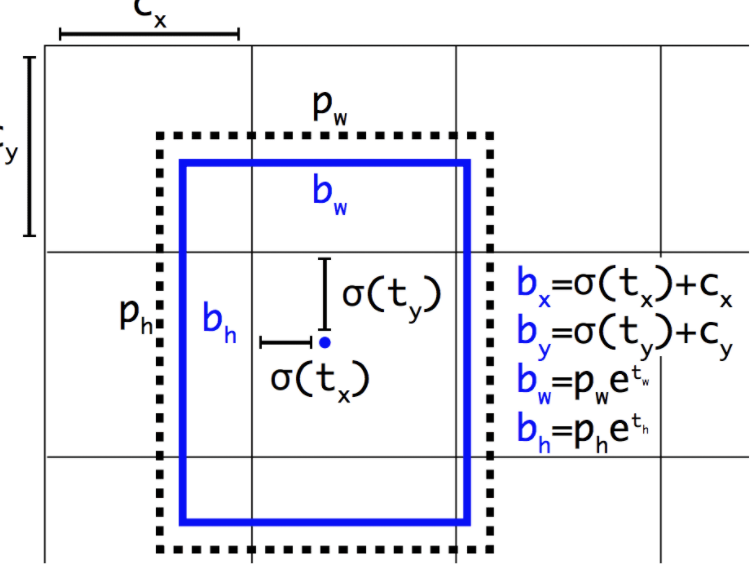
重要的是,边界框的预测表示发生了变化,允许小的变化对预测的影响较小,从而产生更稳定的模型。不是直接预测位置和大小,而是预测偏移以相对于网格单元移动和重塑预定义的锚框,并通过逻辑函数进行抑制。
Joseph Redmon 和 Ali Farhadi 在 2018 年题为“YOLOv3:增量改进”的论文中提出了对该模型的进一步改进。 改进相当小,包括更深的特征检测器网络和较小的表征变化。
总结
人工智能已经走进我们的生活,并应用于各个领域,它不仅给行业带来了巨大的经济效益,也为我们的生活带来了许多改变和便利。
目标检测技术的安防场景示例:
在人工智能技术+视频领域,TSINGSEE青犀视频基于多年视频领域的技术经验积累,也不断研发,将AI检测、智能识别技术融合到各个视频应用场景中,如:安防监控、视频中的人脸检测、人流量统计、危险行为(攀高、摔倒、推搡等)检测识别等。典型的示例如EasyCVR视频融合云服务,具有AI人脸识别、车牌识别、语音对讲、云台控制、声光告警、监控视频分析与数据汇总的能力。