深度学习目标检测的标签数据是以一系列点的形式存储在文件中,输出结果也是以点的形式表示,难以进行目视判读。本代码可以根据检测结果在原始影像上绘制边界框,实现检测结果的可视化。
在OBB的目标检测中,DOTA数据的标签以[x1 y1 x2 y2 x3 y3 x4 y4 class difficult]格式记录在txt文件中,如下所示:
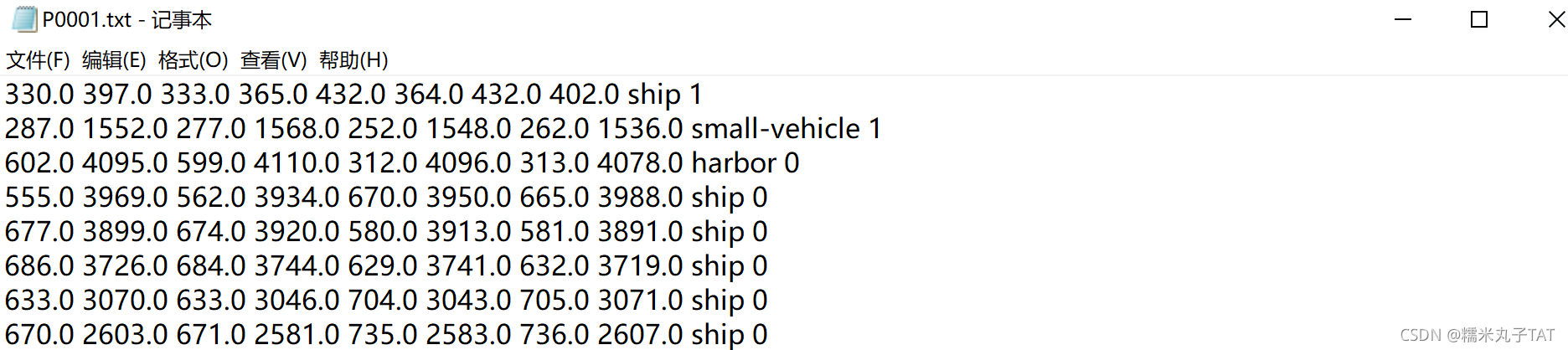
?标签文件与影像文件的名称一一对应:

将标签数据绘制在影像上的可视化代码如下:
# -*- coding: utf-8 -*-
import os, cv2
import numpy as np
import tifffile
# 读取标签文件,返回一系列边界框的坐标点及类别信息
# 文件中一行代表一个边界框,每行由"x1 y1 x2 y2 x3 y3 x4 y4 class difficult"组成
def read_label(label_file):
with open(label_file, 'r') as f:
box_data = [] # 存储坐标点信息
label_data = [] # 存储标类别信息
for line in f.readlines():
curLine = line.strip().split(" ")
x1 = float(curLine[0])
y1 = float(curLine[1])
x2 = float(curLine[2])
y2 = float(curLine[3])
x3 = float(curLine[4])
y3 = float(curLine[5])
x4 = float(curLine[6])
y4 = float(curLine[7])
box = np.array([[x1, y1], [x2, y2], [x3, y3], [x4, y4]], np.int32)
label = curLine[8]
box_data.append(box)
label_data.append(label)
return box_data, label_data
label_dir = './labels/' #存储标签的文件夹
image_dir = './images/' #存储影像的文件夹
out_dir = './labelshow/' #保存输出文件的文件夹
label_files = os.listdir(label_dir)
for label_file in label_files: # 遍历标签文件
if '.txt' in label_file:
label_file = label_dir + label_file # 标签文件路径
image_file = image_dir + label_file.replace('.txt', '.tif') # 影像文件路径(影像与标签文件名对应,替换后缀即可)
im = cv2.imread(image_file)
box_data, label_data = read_label(label_file) # 读取标签文件中的坐标点信息
for i in range(len(box_data)):
x1 = box_data[i][0][0] # 第一个坐标点,为了固定类别标签的位置
y1 = box_data[i][0][1]
bbox = np.array(box_data[i], np.int32)
bbox = bbox.reshape((-1,1,2))
cv2.polylines(im, [bbox], True, (4, 7, 250), 1) # 绘制边界框
font = cv2.FONT_HERSHEY_SIMPLEX
# cv2.putText(im, label_data[i], (x1, y1 - 7), font, 0.5, (6, 230, 230), 1) #可以在边界框上标注类别
label_show_file = out_dir + image_file
cv2.imwrite(label_show_file, im) # 保存可视化后的影像