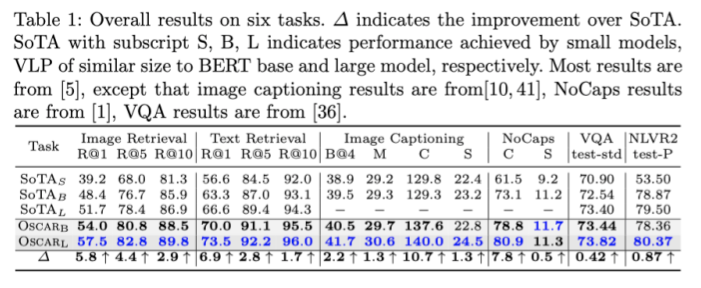
将(单词嵌入,物体标签,图像区域)三元组作为输入
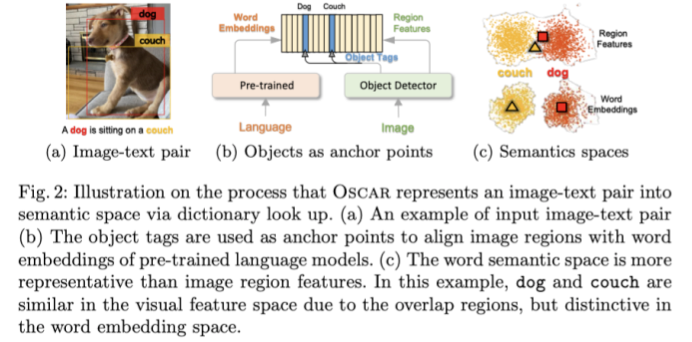
OSCAR引入物体标签用来缓解图像文本对齐学习
从两个方面来进行预训练(模态角度和字典角度)
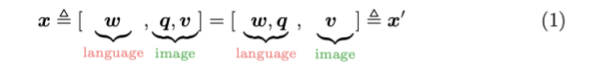
A Dictionary View: Masked Token Loss.
将tag或者文本特征mask掉,然后用周围的token和图像特征来预测mask的token,类似于masked language model

A Modality View: Contrastive Loss
将图像的目标tag替换,作为polluted 图像特征,然后编码文本和图像特征,将输出的cls作为最终的融合特征,输入到一个fc分类器中,判断该图像特征是否是polluted
作者的出发点是,tags可以作为图像的代理,由于tag是从image中检测得到的,通过这种方式,使得文本和它成对的图像更加相似,和polluted的图像更加不相似
![]()
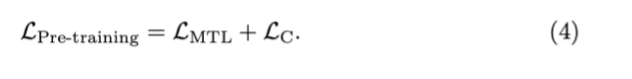
Adapting to V+L Tasks
Image-Text Retrieval(只看了这个)
在训练期间,作者使用binary classification,给定一个对齐的图像文本对,在随机选择一个不同的图像或者不同的文本作为不对齐的对,然后使用最终的[CLS]特征输入到分类器中来预测给定对是否对齐,作者这里说,没有使用ranking loss,是由于发现binary classification loss效果更好