2021SC@SDUSC
前几篇文章,我们分析了finalseg中的代码。
首先,我们先看一下jieba分词的工作流程(图片来自网络):
 ?
?
jieba的三种分词模式及其进入条件:
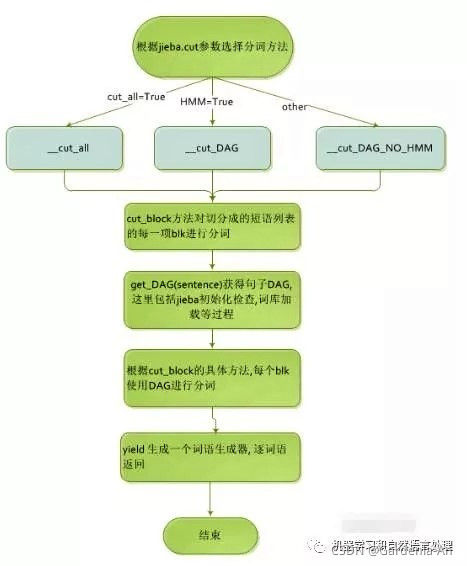
这三种模式有一个共同点,第一步都是先构造DAG,也就是构造有向无环图。
DAG有向无环图,就是后一句中的生成句子中汉字所有可能成词情况所构成的有向无环图,这个是说,给定一个待分词的句子,将它的所有词匹配出来,构成词图,即是一个有向无环图DAG。
下面我们对jieba中的__init__.py中的get_DAG方法进行分析:
def get_DAG(self, sentence):
self.check_initialized()
DAG = {}
N = len(sentence)
for k in xrange(N):
tmplist = []
i = k
frag = sentence[k]
while i < N and frag in self.FREQ:
if self.FREQ[frag]:
tmplist.append(i)
i += 1
frag = sentence[k:i + 1]
if not tmplist:
tmplist.append(k)
DAG[k] = tmplist
return DAG通过jieba目录下,dict.txt文件来产生的self.FREQ,方法如下:
dict.txt共有349046行,每一行格式为:
一举三反 3 i
一举三得 13 i
一举两全 3 i
一举两得 67 i
一举中标 3 l
一举之劳 3 i
一举千里 3 i
一举四得 4 i
一举多得 9 i
一举成名 204 i
・・・・・・第一部分为词语,第二部分为该词出现的频率,第三部分为该词的词性。
以读取’一举两得‘为例子,首先执行self.FREQ['一举两得']=67,然后会检查’一‘、’一举‘、’一举两‘、’一举两得‘之前是否在self.FREQ中存储过,如果之前存储过,则跳过,否则执行self.FREQ['一']=0,self.FREQ['一举']=0,self.FREQ['一举两']=0
所以self.FREQ中不止存储了正常的词语和它出现的次数,同时也存储了所有词语的前缀,并将前缀出现的次数设置为0,以和正常词语区别开。
对于DAG的实现,在源码中,作者记录的是句子中某个词的开始位置,从0到n-1(n为句子的度),设置一个python的字典,每个开始位置作为字典的键,tmplist是个python的list,其中保存了可能的词语的结束位置(通过查字典得到词,然后将词的开始位置加上词语的长度得到结束位置)。例如:{0:[1,2,3]}这样一个简单的DAG,就是表示0位置开始,在1,2,3位置都是某个词的结束位置,就是说0 ~ 1, 0 ~ 2,0 ~ 3这三个位置范围之间的字符,在dict.txt中都是词语。
举个例子,如果sentence是‘我在山东济南上大学’,那么DAG为:
{0: [0], 1: [1], 2: [2,3], 3: [3], 4: [4,5], 5: [5], 6: [6], 7: [7, 8], 8: [8]}