opencv操作与实战
文章目录
第一讲 图像基本操作
数据读取――图像
import cv2
import matplotlib.pyplot import plt
import numpy as np
#%matplotlib.inline # 在notebook中可以直接展示图片,省略plt.show()
img=cv2.imread('cat.jpg')
dtype=unit8 代表取值在0~255.
注意:cv2的读取方式默认是BGR而不是RGB
cv.imshow('image',img)
cv2.waitKey(0) # 0表示任意键消失,非零值代表xxxms后消失
cv2.destroyAllWindows()
一般而言,也可以定义一个函数
def cv_show(name,img):
cv2.imshow(name,img)
cv2.waitKey(0)
cv2.destroyAllWindows()
改变读取图像的方式,例如读入成为灰度图
img=cv2.imread('cat.jpg',cv2.IMREAD_GRAYSALE)
常见的图片属性 shape size dtype
数据读取――视频
vc=cv2.VideoCapture('test.mp4')
#该函数也可以调用摄像头
#检查能否打开
if vc.isOpened():
open,frame =vc.read()
else:
open=False
while open:
ret,frame=vc.read()
if frame is None:
break
if ret==True:
gray=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY) #每一帧都转化为灰度图
cv2.imshow('result',gray)
if cv2.waitKey(10)&0xFF==27:
#自己指定一个帧转换的速率,27是退出键
break
vc.release()
cv2.destroyAllWindows()
截取部分区域
img=cv2.imread('cat.jpg')
cat=img[0:50,0:200] # 50是height,200是width
颜色通道提取和合并
b,g,r=cv2.split(img) b=img[:,:,0]
img=cv2.merge((b,g,r))
边界填充
类似于卷积中的pooling
top_size,bottom_size,left_size,right_size=(50,50,50,50) #指定上下左右的填充大小
#几种不同的填充方法
# 复制法,反射法,不包含最边缘像素的反射法,外包装法,常量法(指定value)
数值计算
img=img+10 相当于在每一个像素点都加10
多个图像相加,必须像素对齐,如果超过255会自动取余
图像融合
一般先进行resize操作,img_dog=cv2.resize(img_dog,(500,500))
也可以通过指定放缩的倍数 img_dog=cv2.resize(img_dog,(0,0),fx=5,fy=4) 相当于横向放大5倍,纵向放大4倍
当然也可以指定
两个图像融合的权重,
R
=
α
x
+
β
y
R=\alpha x+\beta y
R=αx+βy res=cv2.addWeighted(img_dog,0.4,img_cat,0.6,0)
图像阈值
ret,dst=cv2.threshold(src,thresh,maxval,type)
#src 输入只能是灰度图,dst 输出图像
#thresh 阈值 maxval 超过阈值之后所赋予的值,由type决定
type常用的有五种方法:
- THRESH_BINARY 超过阈值部分取maxval,小于阈值部分为0(黑色)
- THRESH_BINARY_INV 超过阈值的部分取0,小于阈值的部分取maxval
- THRESH_BINARY_TRAUNC 截断,大于阈值的部分设置为阈值,小于阈值的不改变
- THRESH_BINARY_TOZERO 大于阈值的部分不变,小于阈值的部分变成0
- THRESH_BINARY_TOZERO_INV 大于阈值的部分不变,小于阈值的部分变成255
图像平滑
#均值滤波
#实际通过归一化卷积模板实现,卷积核大小为3*3
blur=cv2.blur(img,(3,3))
#方框滤波
#基本与均值滤波相同,但是可以选择是否归一化
box=cv2.boxFilter(img,-1,(3,3),normalize=True)
#高斯滤波
ass=cv2.GaussionBlur(img,(2,2),1)
#中值滤波
med=cv2.medianBlur(img,5)
#可以显示几种方法
res=np.hstack((box,ass,med)) #水平放置
res=np.vstack((box,ass,med)) #竖直放置
形态学-腐蚀操作
kernel=np.ones((5,5),np.uint8)
erosion=cv2.erode(img,kernel,iteration=1)
形态学-膨胀操作
kernel=np.ones((5,5),np.uint8)
erosion=cv2.dilate(erosion,kernel,iteration=1)
**开运算:先腐蚀后膨胀 **不带刺
opening=cv2.morphologyEx(img,cv2.MORPH_OPEN,kernel)
闭运算:先膨胀后腐蚀 保留毛刺细节
closing=cv2.morphologyEx(img,cv2.MORPH_CLOSE,kernel)
梯度运算
gradient=cv2.morphologyEx(img,cv2.MORPH_GRADIENT,kernel)
#实际中就是膨胀减去腐蚀
礼帽 与 黑帽
# 礼帽:原始输入减去开运算,只保留毛刺信息
img=cv2.morphologyEx(img,cv2.MORPH_TOPHAT,kernel)
# 黑猫:闭运算减去原始输入
img=cv2.morphologyEx(img,cv2.MORPH_BLACKHAT,kernel)
提取边缘
import cv2
img = cv2.imread("./test.jpg")
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret, binary = cv2.threshold(gray,127,255,cv2.THRESH_BINARY)
contours, hierarchy =cv2.findContours(binary,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
cv2.drawContours(img,contours,-1,(0,0,255),3)
cv2.imshow("img", img)
cv2.waitKey(0)
参考文章 opencv2利用cv2.findContours()函数来查找检测物体的轮廓
图像梯度的运算
Sobel算子
G x = [ ? 1 0 + 1 ? 2 0 + 2 ? 1 0 + 1 ] ? A ? G_x=\left[ \begin{matrix} -1&0&+1\\-2&0&+2\\-1&0&+1\end{matrix} \right]*A \space Gx?=????1?2?1?000?+1+2+1?????A?
G y = [ ? 1 ? 2 ? 1 0 0 0 + 1 + 2 + 1 ] ? A G_y=\left[ \begin{matrix} -1&-2&-1\\0&0&0\\+1&+2&+1\end{matrix} \right]*A Gy?=????10+1??20+2??10+1?????A
sobel=cv2.Sobel(src,ddepth,dx,dy,ksize)
ddepth :图像的深度 ksize : Sobel算子的大小 dx=0 dy=1 计算竖直方向的梯度
但是会出现,白减黑等于白,但是黑减白会成为负数,此时如果要展示另外一边
dst=cv2.convertScaleAbs(dst) 需要全部转为正数 这一步在Scharr算子和Laplacian算子中也会有
cv2提供了Gx和Gy的权重之和,sobel=cv2.addWeighted(sobelx,0.5,sobley,0.5,0)
不建议直接将dx和dy直接设置为1 融合的不够好,结果会有些模糊
Scharr算子
G x = [ ? 3 0 3 ? 10 0 10 ? 3 0 3 ] ? A G_x=\left[ \begin{matrix} -3&0&3\\-10&0&10\\-3&0&3\end{matrix} \right]*A Gx?=????3?10?3?000?3103?????A
更加敏感
Laplacian算子
G x = [ 0 1 0 1 ? 4 1 0 1 0 ] ? A G_x=\left[ \begin{matrix} 0&1&0\\1&-4&1\\0&1&0\end{matrix} \right]*A Gx?=???010?1?41?010?????A
对于噪声更加敏感,往往要结合其他方法
Canny边缘检测
步骤
- 使用高斯滤波器,平滑图像,消除噪声
- 计算图像中每个点的梯度强度和方向
- 应用非极大值(Non-Maximum Suppression)抑制,以消除边缘检测带来的杂散响应
- 应用双阈值(Double-Threshold)检测来确定真实和潜在的边缘
- 通过抑制孤立的弱边缘,最终完成边缘检测
非极大值抑制
方法1:线性插值法,对于两个亚像素点Q,Z的梯度,可以用Q到旁边的像素点的加权梯度;
方法2:把一个像素点的梯度分解到八个方向,如果该点的梯度是周围八个点中最大的,则保留下来
双阈值检测
梯度值>maxval,则处理为边界
梯度值<minval,则舍弃
minval<梯度值<maxval,连接到边界则保留,否则则舍弃
图像金字塔
高斯金字塔
向下采样,downsample 注意:特征图越来越小

步骤:
- 将图像与高斯核卷积;
- 然后去掉偶数行和偶数列
向上采样 upsample
- 将图像在每个方向扩大为原来的两倍,新增的部分用0补充;
- 用高斯核与扩零后的图像卷积
up=cv2.pyrUp(img)
down=cv2.pyrdown(img)
#默认缩小/扩大为原来的两倍
同时展示两个图像
cv2.show(np.hstack(img,up_down),'img')
拉普拉斯金字塔
L i = G i ? P y r U p ( P y r D o w n G i ) L_i=G_i-PyrUp(PyrDownG_i) Li?=Gi??PyrUp(PyrDownGi?)
可以显示图像的轮廓
图像轮廓
cv2.findContours(img,mode,method)
mode
RETR_TREE: 检测所有轮廓,并重构嵌套轮廓的层次
mothod 轮廓逼近的方法
CHAIN_APPROX_SIMPLE压缩水平,垂直和倾斜的部分,只保留其终点部分,相当于压缩了图像
绘制轮廓
res=cv2.drawContours(img,countours,-1,(0,0,255),2) -1代表着绘制所有的轮廓,指定其他数值,则为对应序号的边界轮廓,(B,G,R)的格式,2线条的宽度
该函数会改变img,可以使用 draw_img=img.copy()
得到特定轮廓
cnt=contours[2] 第二条轮廓
计算面积
cv2.contourArea(cnt)
轮廓近似
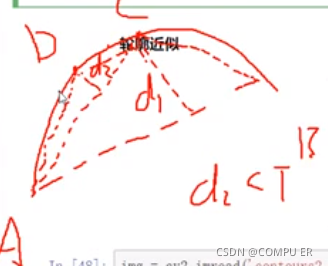
epsilon=0.1*cv2.arcLength(cnt,True)
approx=cv2.approxPolyDP(cnt,epsilon,True)
epsilon 可以控制轮廓的精细程度
实战:多目标检测
KCF方法 岭回归 ,计算量比较小,适用于嵌入式设备
深度方法 检测框架,Faster RCNN 每秒五帧,SSD支持更高检测速度,但是效果较差,YOLO V3 最热的,Mask-RCNN
dlib 里面有一些内置好的学习算法,但是建议通过whl文件下载安装,否则cmake过程中会出现错误
实战:基于面部特征的驾驶员疲劳状态检测
实战:背景建模
前景和背景:背景是基本不发生变化的
1. 帧差法
在时间上的连续两帧图像进行差分运算,不同帧像素点相减,判断灰度差的绝对值,当超过一定阈值时,则指定为255,否则指定为0.
**缺点:**噪声和空洞的问题
2. 混合高斯模型
EM算法也是基于混合高斯模型。
背景的实际分布应当是多个高斯分布混合在一起,每个高斯模型的权重未必相同。
基本假设:每个像素点随时间分布符合高斯分布。
学习方法:
- 初始化每个高斯模型矩阵参数;
- 取视频中T帧数据图像来训练高斯混合模型,得到均值和方差
- 当后面的像素点来时,与前面的高斯均值比较,如果该像素点的均值在3倍方差之内,则属于该分布,并进行参数更新,如果不在3倍方差内,则新创建一个高斯分布
设置3~5个高斯分布,不能太多
测试方法:
? 测试阶段,新来的像素点与混合高斯模型中的每一个均值进行比较,如果其差值在2倍方差内,则认为是背景,否则认为是前景
import cv2
import numpy as np
cap=cv2.VideoCapture('test.avi')
#形态学操作
kernel=cv2.getStructureElement(cv2.MORPH_ELLIPSE,(3,3))
#创建混合高斯模型用于建模
fgbg=cv2.createBackgroundSubtractorMOG2()
while True:
ret,grame=cap.read()
fgmask=fgbg.apply(frame) #返回二值的掩码图像
#形态学开运算去除噪声
fgmask=cv2.morphologyEx(fgmask,cv2.MORPH_OPEN,kernel)
#寻找视频中的轮廓,一般都用的是深度方法
im,contours,hierarchy=cv2.findContours(fgmask,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
for c in contours:
#计算各个轮廓的周长
perimeter=cv2.arcLength(c,True)
if perimeter>188:
#找到一个直矩形
x,y,w,h=cv2.boundingRect(c)
#画出这个矩形
cv2.rectangle(frame,(x,y),(x+w,y+h),(0,255,0),2)
cv.imshow('frame',frame)
cv.imshow('fgmask',fgmask)
k=cv2.waitKey(100)&0xff:
if k==27:
break
cap.release()
cv2.destroyAllWindows()
实战:光流估计
光流:空间运动物体在观测成像平面上的像素运动的瞬间速度。
假设的三个条件
- 亮度恒定:同一点随着时间的变化,其亮度不会发生改变
- 小运动:随着时间的变化不会引起位置的剧烈变化,这样才能用前后帧的单位位置变化引起的灰度变化去近似灰度对位置的偏导数
- 空间一致:一个场景上的临近点投影到其他场景下也是相邻点
Lucas-Kanade算法 卢卡斯-卡纳德算法:
约束方程:
I
(
x
,
y
,
t
)
=
I
(
x
+
d
x
,
y
+
d
y
,
t
+
d
t
)
=
I
(
x
,
y
,
t
)
+
?
I
?
x
d
x
+
?
I
?
y
d
y
+
?
I
?
t
d
t
=
>
I
x
d
x
+
I
y
d
y
+
I
t
d
t
=
0
\begin{aligned} I(x,y,t)&=I(x+dx,y+dy,t+dt)\\&=I(x,y,t)+\frac{\partial I}{\partial x}dx+\frac{\partial I}{\partial y}dy+\frac{\partial I}{\partial t}dt \end{aligned} => I_xdx+I_ydy+I_tdt=0
I(x,y,t)?=I(x+dx,y+dy,t+dt)=I(x,y,t)+?x?I?dx+?y?I?dy+?t?I?dt?=>Ix?dx+Iy?dy+It?dt=0
当考虑一帧数据之间的差值,第四项等于前后帧的数据差(即dt=0),而且梯度值已知,得到
I
x
u
+
I
y
v
=
?
I
t
?
=
>
[
I
x
I
y
]
?
[
u
v
]
=
?
I
t
I_xu+I_yv=-I_t\space => \left[\begin{matrix} I_x&I_y \end{matrix}\right]\cdot \left[\begin{matrix} u\\v \end{matrix}\right]=-I_t
Ix?u+Iy?v=?It??=>[Ix??Iy??]?[uv?]=?It?
未知量有u和v,还需要借助空间一致条件,对于一个候选框内的所有的点,对应的uv是相同的,不妨假设候选框是5*5的,则有
[
I
x
1
I
y
1
I
x
2
I
y
2
.
.
.
I
x
25
I
y
25
]
?
[
u
v
]
=
[
I
t
1
I
t
2
.
.
.
I
t
25
]
\left[\begin{matrix} I_{x1}&I_{y1}\\I_{x2}&I_{y2}\\...\\I_{x25}&I_{y25} \end{matrix}\right]\cdot\left[\begin{matrix} u\\v \end{matrix}\right]=\left[\begin{matrix} I_{t1}\\I_{t2}\\...\\I_{t25}\end{matrix}\right]
?????Ix1?Ix2?...Ix25??Iy1?Iy2?Iy25????????[uv?]=?????It1?It2?...It25???????
但是这样会导致条件数多于变量数,利用最小二乘法
A
u
=
b
?
=
>
u
=
(
A
T
A
)
?
1
A
T
b
Au=b\space =>u=(A^TA)^{-1}A^Tb
Au=b?=>u=(ATA)?1ATb
问题:系数矩阵一定可逆吗
A
T
A
=
[
∑
I
x
2
∑
I
x
I
y
∑
I
x
I
y
∑
I
y
2
]
A^TA=\left[ \begin{matrix} \sum{I_x^2}&\sum{I_xI_y}\\\sum{I_xI_y}&\sum{I_y^2} \end{matrix}\right]
ATA=[∑Ix2?∑Ix?Iy??∑Ix?Iy?∑Iy2??]
联系角点检测,这个矩阵不一定可逆,只有当Ix和Iy都比较大的时候,可逆的可能性才比较大,因而光流估计需要传入角点,cv2,goodFeaturesToTrack可以返回所有检测特征点,需要传入图像、角点的最大数量(否则速度会比较慢)、品质因子(筛选
λ
1
和
λ
2
\lambda_1和\lambda_2
λ1?和λ2?都比较大的点)、最小距离(在这个范围内只取最好的角点),一般通过非关键字参数聚合打散传入。
摄像头检测人脸代码
# 打开摄像头检测人脸
from keras.layers import Input
from retinanet import Retinanet
from PIL import Image
import numpy as np
import cv2
retinanet=Retinanet()
# 打开摄像头
capture=cv2.VideoCapture(0)
while True:
#读取帧
ref,frame=capture.read()
frame=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
frame=Image.fromarray(np.uint8(frame))
# 检测
frame=np.array(retinanet.detect_image(frame))
# RGB->BGR满足cv2的输入要求
frame=cv2.cvtColor(frame,cv2.COLOR_RGB2BGR)
cv2.imshow('video',frame)
if cv2.waitKey(10) &0xff=="27":
capture.release()
break
retinanet.close_session()