����Ŀ¼
���ҵ���һƪ���� ����ͼģ����,�н���һЩ�����ĸ���ͼģ�͡������ճ�������,��ͷִ�Ҳ�dz��õ����ķִʰ�,������ʹ����HMMģ��,��� ����ͼģ���е�����֪ʶ,���������ǽ�һ���˽�HMM�㷨(��Ȼ�������ڴ�)��
��ͷִʼ��
����,����ͨ��readme������ͷִ��ܹ���ʲô:
�ִ�:
�ٷ�������ʹ�õķִ��㷨:
�ؼ��ʳ�ȡ:


���Ա�ע:
������,���Ƿ�����С�ڷֱ�������ǡ�
�ִ�
Ϊ���ܹ����õ�����,��һ��ʵ������:
ȥ������ѧ��
����ǰ�ʵ�ʵ�ָ�Ч�Ĵ�ͼɨ��,���ɾ����к������п��ܳɴ���������ɵ�������ͼ
����ǰ�ʵ�
����֪��,��ͷִʺ����Դ��Ĵʵ�,Ҳ����֧���û��Լ����Ӵʵ䡣���øôʵ乹��ǰ�ʵ�,��ǰ�ʵ䱻���ڹ���DAG���ʵ����ʽ����:
�ʵ��ʽ�� dict.txt һ��,һ����ռһ��;ÿһ�з�������:�����Ƶ(��ʡ��)������(��ʡ��),�ÿո����,˳�ɵߵ���
���ݴʵ�,���ǿ��Թ���ǰ�ʵ�,��ʾ����ȥ������ѧ�桱,��ǰ�ʵ����ʽ����:
������ѧ 2053
������ 0 # ������ǰ��,��ƵΪ0
���� 34488
�� 17860
�� 6583
��ѧ 20025
�� 144099
ѧ 17482
ȥ 123402
�� 4207
Դ������:
# f������ͳ�ƵĴʵ��ļ����
def gen_pfdict(self, f):
# ��ʼ��ǰ�ʵ�
lfreq = {}
ltotal = 0
f_name = resolve_filename(f)
for lineno, line in enumerate(f, 1):
try:
# �������ߴʵ��ı��ļ�
line = line.strip().decode('utf-8')
# �ʺͶ�Ӧ�Ĵ�Ƶ
word, freq = line.split(' ')[:2]
freq = int(freq)
lfreq[word] = freq
ltotal += freq
# ��ȡ�ô����е�ǰ��
for ch in xrange(len(word)):
wfrag = word[:ch + 1]
# ���ijǰ�ʲ���ǰ�ʵ���,��Ӧ��Ƶ����Ϊ0
if wfrag not in lfreq:
lfreq[wfrag] = 0
except ValueError:
raise ValueError(
'invalid dictionary entry in %s at Line %s: %s' % (f_name, lineno, line))
f.close()
return lfreq, ltotal
����������ͼ
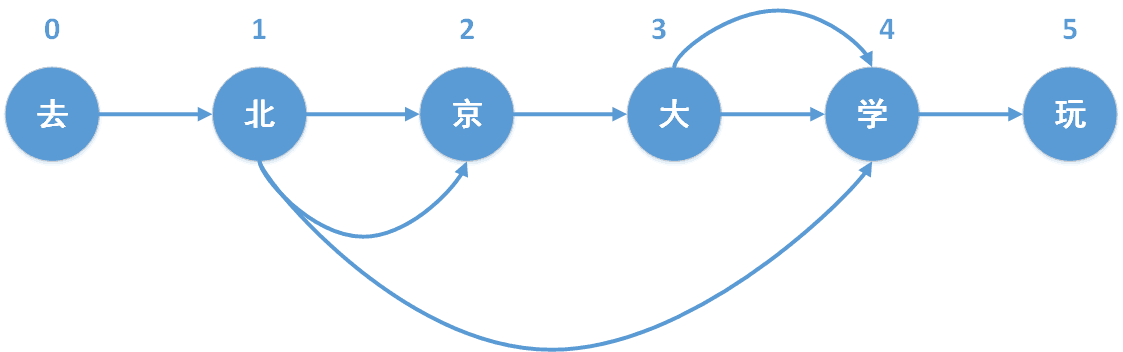
��jieba�ִ���,ÿ���ֶ������ھ����е�λ��ȥ��ǡ������ջ�����һ��dict,key����ÿ���ʵĿ�ͷ,value������ÿ���ʵĽ�β(�����ж��)����ʾ����ȥ������ѧ�桱����,��DAG�������:
{
0: [0] # key=0,value=[0]���� �����Ϊ[0:0]����ȥ��
1: [1,2,4] # key=1,value=[1,2,4]������������,�ֱ�Ϊ[1:1],[1:2],[1:4],������������������ѧ
2: [2]
3: [3,4]
4: [4]
5: [5]
}
ʵ�ַ�ʽ����(����α�������ʽ����,����Ȥ�����ѿ���ȥGitHub������Դ��):
def get_DAG(self, sentence):
dag = {} # �������ɵ�dag
for k in range(len(sentense)):
end_lst = [] # ���position list
# ��ÿ��position�����Ը�position��ͷ���Ӵ�
for j in range(k+1,len(sentence)):
term = sentence[k:j]
if term ��ǰ�ʵ�,�Ҵ�Ƶ>0:
end_lst.append(j-1)
elif term ��ǰ�ʵ�,�Ҵ�Ƶ=0:
continue
elif term ����ǰ�ʵ���:
# ˵����δ��¼��
break
dag[k] = end_lst
return dag
��̬�滮����������·��, �ҳ����ڴ�Ƶ������з����
�ڵõ����п��ܵ��зַ�ʽ���ɵ�������ͼ��,���Ƿ��ִ���㵽�յ���ڶ���·��,����·��Ҳ����ζ�Ŵ��ڶ��ִַʽ��,����:
# ·��1
0 -> 1 -> 2 -> 3 -> 4 -> 5
# �ִʽ��1
ȥ / �� / �� / �� / ѧ / ��
# ·��2
0 -> 1 , 2 -> 3 -> 4 -> 5
# �ִʽ��2
ȥ / ���� / �� / ѧ / ��
# ·��3
0 -> 1 , 2 -> 3 , 4 -> 5
# �ִʽ��3
ȥ / ���� / ��ѧ / ��
# ·��4
0 -> 1 , 2 , 3 , 4 -> 5
# �ִʽ��4
ȥ / ������ѧ / ��
...
��һ�ڹ����DAG�Ǵ�Ȩ��,��Ȩ��Ϊ�ô���ǰ�ʵ��еĴ�Ƶ�����ǵ�Ŀ����,���һ��·��,ʹ����Ȩ�����
��Դ����Կ���,���ö�̬�滮�ķ�ʽ����������(Դ��λ��):

����,logtotalΪ����ǰ��Ƶʱ���еĴ�Ƶ֮�͵Ķ���ֵ,Ŀ����Ϊ�˷�ֹ�������⡣route����Ϊ:(�����ʶ���,�����ʶ�����Ӧ�Ĵ�������һ��λ��)��
��״̬ת�Ʒ���Ϊ:
r
i
=
m
a
x
(
l
o
g
w
i
��
j
Z
+
r
j
)
,
i
��
j
��
D
A
G
r_i = max(log \frac {w_{i \rightarrow j}}{Z}+r_j),i \rightarrow j \in DAG
ri?=max(logZwi��j??+rj?),i��j��DAG
����,
Z
Z
Z�ǹ�һ������,
i
��
j
i \rightarrow j
i��j��ʾλ��i��λ��j�Ĵ�,
w
w
w��ʾ�ôʵĴ�Ƶ��
HMMʶ��δ��½��
����HMM��ԭ��,����ҵIJ���:����ͼģ����
���衰ȥ������ѧ�桱�а���δ��½��,��ô������ʵ����ͼ�������µ����б�ע:
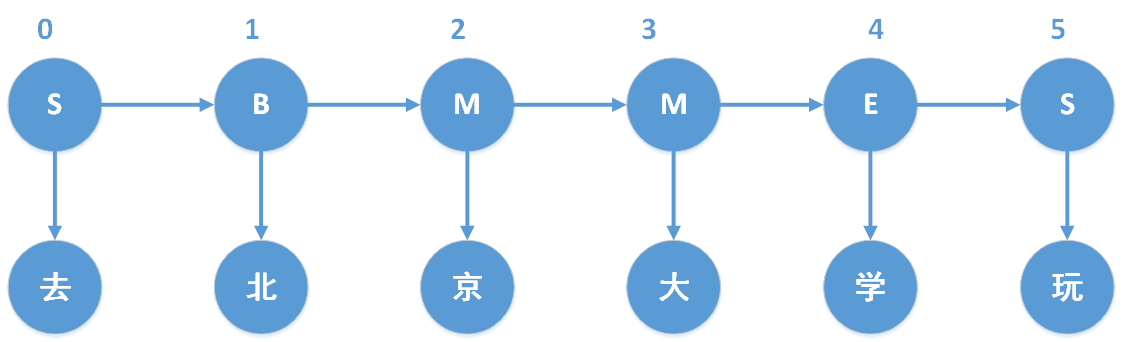
����,B��M��E��S,�ֱ��ʾBegin(����ִ��ڴʵĿ�ʼλ��)��Middle(����ִ��ڴʵ��м�λ��)��End(����ִ��ڴʵĽ���λ��)��Single(������ǵ��ֳɴ�)��
��Ȼ���ǵ�Ŀ���ǻ�ȡ���б�ע,��ô��Ȼ�Dz���ά�ر��㷨��⡣
��֪�۲����� O O O�� �� = ( �� , A , B ) \lambda=(\pi,A,B) ��=(��,A,B),������п��ܳ��ֵ�״̬���С�
- ����Ĺ۲�������Ȼ��"ȥ������ѧ��"
- ģ�Ͳ�������ͨ������ѵ�����,�洢��jieba/finalseg/�¡�
prob_start.py �洢���Ѿ�ѵ���õ�HMMģ�͵�״̬��ʼ���ʱ�;
prob_trans.py �洢���Ѿ�ѵ���õ�HMMģ�͵�״̬ת�Ƹ��ʱ�;
prob_emit.py �洢���Ѿ�ѵ���õ�HMMģ�͵�״̬������ʱ�;
������ͼģ�����Ѿ��г�ά�ر��㷨��ԭ��:

��Դ������:
def viterbi(obs, states, start_p, trans_p, emit_p):
V = [{}] # tabular
path = {}
# ʱ��t = 0,��ʼ״̬
for y in states: # init
V[0][y] = start_p[y] + emit_p[y].get(obs[0], MIN_FLOAT)
path[y] = [y]
# ʱ��t = 1,...,len(obs) - 1
for t in xrange(1, len(obs)):
V.append({})
newpath = {}
# ��ǰʱ�������ĸ��ֿ��ܵ�״̬
for y in states:
# ��ȡ�������
em_p = emit_p[y].get(obs[t], MIN_FLOAT)
# �ֱ��ȡ��һʱ�̵�״̬�ĸ���,��״̬����ʱ�̵�״̬��ת�Ƹ���,��ʱ�̵�״̬�ķ������
# ����,PrevStatus[y]�ǵ�ǰʱ�̵�״̬����Ӧ��һʱ�̿��ܵ�״̬
(prob, state) = max(
[(V[t - 1][y0] + trans_p[y0].get(y, MIN_FLOAT) + em_p, y0) for y0 in PrevStatus[y]])
V[t][y] = prob
# ����һʱ�����ŵ�״̬ + ��һʱ�̵�״̬
newpath[y] = path[state] + [y]
path = newpath
# ���һ��ʱ��
(prob, state) = max((V[len(obs) - 1][y], y) for y in 'ES')
# ���������ʶ���������·��
return (prob, path[state])
�ؼ�����ȡ
����tfidf��textrank���йؼ�����ȡ��
TF-IDF
TF-IDF(term frequency�Cinverse document frequency,��Ƶ-�����ļ�Ƶ��)��һ��������Ϣ����(information retrieval)���ı��ھ�(text mining)�ij��ü�Ȩ���������ִʵ���Ҫ�����������ļ��г��ֵĴ�������������,��ͬʱ�������������Ͽ��г��ֵ�Ƶ�ʳɷ����½���
������Ҫ˼����: ���һ������ijƪ�����г��ֵĴ�Ƶ�ܸ�,���������������к��ٳ���,�������Ϊ�ôʾ��кܺõ���������,���������ؼ��ʡ�
tf(term frequency, ��Ƶ):
t
f
i
,
j
=
n
i
,
j
��
k
n
k
,
j
tf_{i,j}=\frac{n_{i,j}}{\sum_k n_{k,j}}
tfi,j?=��k?nk,j?ni,j??
����,
n
i
,
j
n_{i,j}
ni,j?��ʾ��
d
j
d_j
dj?�ĵ���,��
i
i
i���ֵĴ���,
��
k
n
k
,
j
\sum_k n_{k,j}
��k?nk,j?��ʾ�ĵ�
d
j
d_j
dj?�дʵ�������
idf(inverse document frequency,���ĵ�Ƶ��):
i
d
f
i
=
l
o
g
�O
D
�O
�O
{
j
:
n
i
��
d
j
}
�O
+
1
idf_i = log \frac{|D|}{|\{j:n_i\in d_j\}|+1}
idfi?=log�O{j:ni?��dj?}�O+1�OD�O?
����,���ӱ�ʾ�ĵ�������(�ж���ƪ�ĵ�),��ĸ��ʾ������
n
i
n_i
ni?���ĵ�����Ŀ����ĸ��1��ҪΪ�˷�ֹ��ĸΪ0�������
tf-idf:
t
f
i
d
f
=
t
f
?
i
d
f
tfidf=tf*idf
tfidf=tf?idf
TextRank
TextRank�㷨��һ�ֻ���ͼ�����ڹؼ��ʳ�ȡ���ĵ�ժҪ�������㷨,�ɹȸ����ҳ��Ҫ�������㷨PageRank�㷨�Ľ�����,������һƪ�ĵ��ڲ��Ĵ����Ĺ�����Ϣ(����)����Գ�ȡ�ؼ���,���ܹ���һ���������ı��г�ȡ�����ı��Ĺؼ��ʡ��ؼ�����,��ʹ�ó�ȡʽ���Զ���ժ������ȡ�����ı��Ĺؼ��䡣
pagerank:
(1)��������:���һ����ҳ��Խ���������ҳ����,˵�������ҳԽ��Ҫ,������ҳ��PRֵ(PageRankֵ)����Խϸ�;
(2)��������:���һ����ҳ��һ��Խ��Ȩֵ����ҳ����,Ҳ�ܱ��������ҳԽ��Ҫ,��һ��PRֵ�ܸߵ���ҳ���ӵ�һ��������ҳ,��ô�����ӵ�����ҳ��PRֵ����Ӧ����˶���ߡ�
����㹫ʽ����:
s
(
v
i
)
=
(
1
?
d
)
+
d
��
��
j
��
i
n
(
v
i
)
1
�O
o
u
t
(
v
j
)
�O
s
(
v
j
)
s(v_i)=(1-d)+d\times \sum_{j\in in(v_i)} \frac{1}{|out(v_j)|} s(v_j)
s(vi?)=(1?d)+d��j��in(vi?)��?�Oout(vj?)�O1?s(vj?)
s
(
v
)
s(v)
s(v)��ʾ��ҳ����Ҫ��,��prֵ,d������ϵ��,һ����0.85,
i
n
(
v
)
in(v)
in(v)����ҳ�����,��ʾ������ָ�����ҳ����ҳ;
o
u
t
(
v
)
out(v)
out(v)��ʾ��ҳ�ij���,
1
�O
o
u
t
(
v
j
)
�O
s
(
v
j
)
\frac{1}{|out(v_j)|} s(v_j)
�Oout(vj?)�O1?s(vj?)˵��,����
v
i
v_i
vi?��prֵ,�����еij��ȷ�̯��
ͬ����,���ǿ���д��textrank�Ĺ�ʽ:
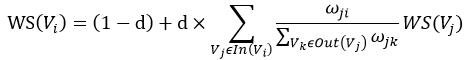
��pagerank��ͬ����,pagerank֮��ı���������Ȩ��,��textrank֮��ı���������Ȩ�ߡ�
��
j
i
\omega_{ji}
��ji?����ʾ��Ȩ��
���ڹؼ��ʳ�ȡ��ϸ��,�������ҵ���һƪ����:�ؼ��ʳ�ȡ �н���������ֻ����һ������ԭ����
���Ա�ע
�������ִʹ�������:
1)����Ǻ���,������ǰ�ʵ乹��������ͼ,Ȼ���������ͼ����������·��,ͬʱ��ǰ�ʵ��в������ֳ��ĴʵĴ���,���û���ҵ�,������Ա�עΪ��x��(�������� ��������ֻ��һ������,��ĸxͨ�����ڴ���δ֪��������);���HMM��־λ��λ,���Ҹô�Ϊδ��¼��,��ͨ���������Ʒ�ģ�Ͷ�����д��Ա�ע;
2)���������,������������ʽ�ж�������,�ֱ��衰x��,��m��(���� ȡӢ��numeral�ĵ�3����ĸ,n,u��������),��eng��(Ӣ��)��
����Ͳ�����
�ο�
��ͷִ�Դ��
��ͷִʽ���,����:zhbzz2007
TF-IDF
TextRank
TextRank�㷨�Ļ���ԭ����textrank4zhʹ��ʵ��