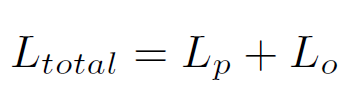前些日子作业多,就没看论文。组会上老师问我有没有用transformer做场景图的。我说没吧老师。然后师姐给我发了这篇。今天把这篇文章梳理完了,做个记录。
这篇文章是做动态场景图的,就是由视频生成场景图。我之前看的都是基于静态图片的,也就是静态场景图。论文作者设计了一个Transformer,捕捉到了单个帧内各谓语表示的空间信息和相邻帧的时序信息。为什么要利用好时序信息呢?对于视频而言,前一帧对后一帧是有启发作用的,作者认为如果前一帧是人-holding-杯子这样的关系,那么很容易就能猜到后一帧是人-drinking from-杯子这样的关系。
老规矩先上pipeline。

(1)目标检测网络,作者用的是FasterRCNN,backbone使用了ResNet101
(2)生成谓语表示
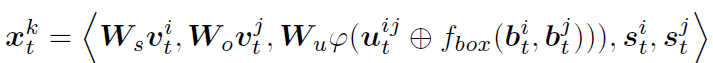
t:第t帧,k:第k个谓词
i ,j:谓词关联到的两个物体,第i个和第j个
v:目标检测网络提取的视觉特征
uij:i,j两个物体的union box经过ROIAlign的特征
fbox:把物体i的bbox和物体j的bbox转换成特征,并且和uij维度相同
φ:展平
s:物体类别的语义嵌入信息
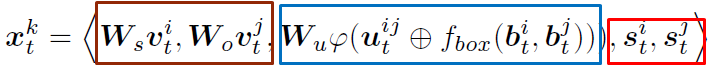
也就是说谓语表示融合了视觉特征、存在联系的主宾对的空间信息,和主宾对所属物体类别的语义信息。
(3)Spatial Encoder

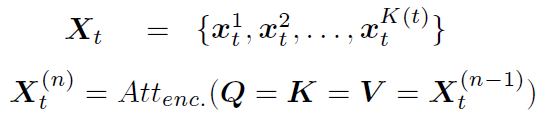
(4)Frame Encoding
帧编码。因为后面要利用相邻帧的信息,为了区分不同的帧,对每个帧进行编码,每个帧的编码结果不同。这一步注入了时序信息。
(5)Temporal Decoding
这一步是我觉得最重要的部分。时序解码这里利用的是相邻帧的信息,也就是真正地利用了时序信息。
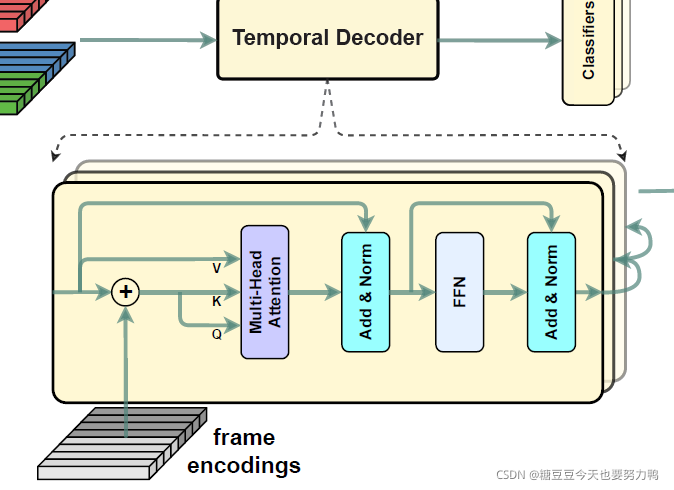
这里的Q和K是相同的。Ef就是帧编码,Zi是滑动窗口η在所有帧上滑动的结果,如果η=2,那么就是帧1帧2进行解码;帧2帧3解码;帧3帧4解码这样。

(7)loss function
谓语分类损失用的是多标签损失,对于预测正确的谓语,尽可能增大它的置信度,对于预测错误的谓语,尽可能减小它的置信度。
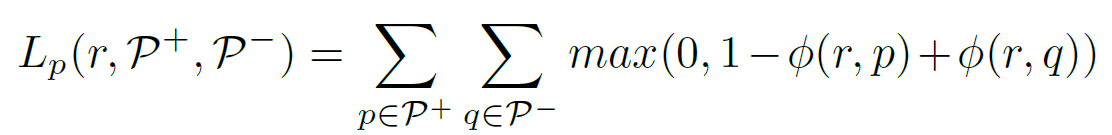
总损失 = 谓语分类损失+目标分类损失