1,特征工程-数据降维(特征的数量)


这里主要介绍过滤式,即对方差进行选择,去掉比较相似的数据.


def var():
'''
特征选择-删除低方差内容
:return:
'''
var=VarianceThreshold(threshold=1.0)#这里参数设置为阈值,方差低于等于该值的将被删除,这个值通常在10内取
data=var.fit_transform([[0, 2, 0, 3],
[0, 1, 4, 3],
[0, 1, 1, 3]])
print(data)
if __name__=='__main__':
var()
[[0]
[4]
[1]]
其他特征选择方式在算法中介绍
(2)主成分分析

PCA:主成分分析,应用在特征数量在上百个的情况下,作用是用低维度信息尽可能的表达出高维度信息的全部内容.

pca的任务:


该参数为小数时,表示保留多少信息,一般在90-95之间
为整数时,表示减少到多少特征,一般不用这种形式.
def pca():
'''
数据降维-主成分分析
:return:
'''
pca=PCA(n_components=0.9)#表示保留90%的信息
data=pca.fit_transform([[2,8,4,5],
[6,3,0,8],
[5,4,9,1]])
print(data)
if __name__=='__main__':
pca()
[[-3.13587302e-16 3.82970843e+00]
[-5.74456265e+00 -1.91485422e+00]
[ 5.74456265e+00 -1.91485422e+00]]
2,

代码在instacart.ipynb中
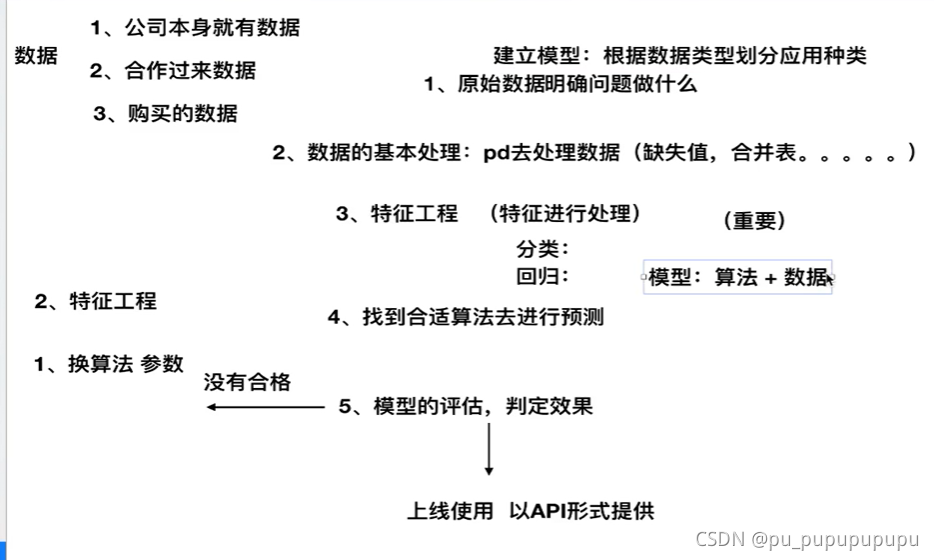
3,机器学习算法



开发流程:
4,sklearn数据集
模型=算法+数据




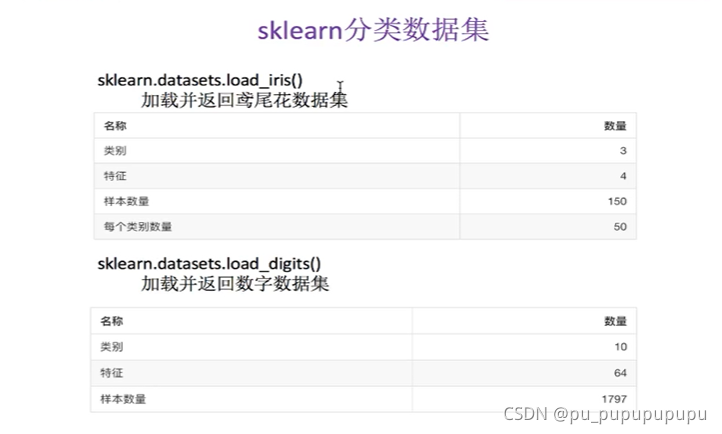
from sklearn.datasets import load_iris
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
li=load_iris()
#
# print(li.data)
# print(li.target)
# print(li.DESCR)
# di=load_digits()
#
# print(di.data)
# print(di.target)
# print(di.feature_names)
# 注意返回值, 训练集 train x_train, y_train 测试集 test x_test, y_test
x_train,x_text,y_train,y_test=train_test_split(li.data,li.target,test_size=0.25)
print('训练集数据:',x_train,y_train)
print('测试集数据:',x_text,y_test)

news=fetch_20newsgroups(subset='all')#该参数用来指定下载什么数据,data_home参数指定下载路径,默认在家目录下
print(news.data)
print(news.target)
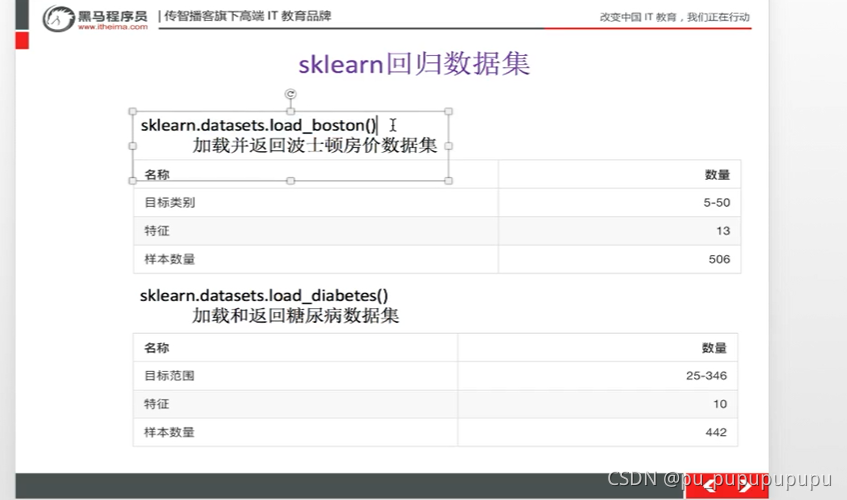
lb=load_boston()
print(lb.data)
print(lb.target)
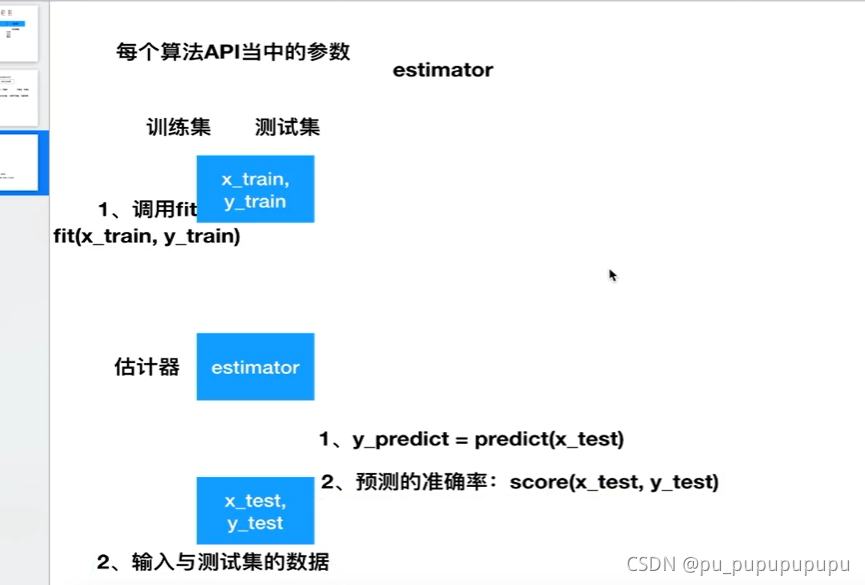
5,转换器与估计器
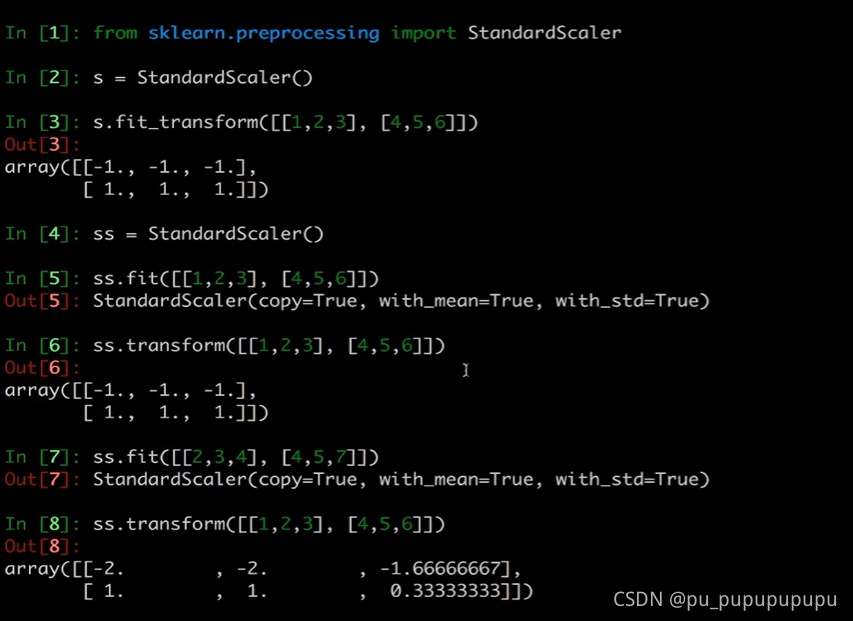
由这个例子可以看出,fit+transform=fit_transform
并且fit用于输入数据并且确定标准,计算数据的一些平均值等.transform用于以fit的标准来转化数据.(两次数据不一样也可以)

估计器流程,先用fit将训练集数据输入,再进行预测