HiNet: Deep Image Hiding by Invertible Network
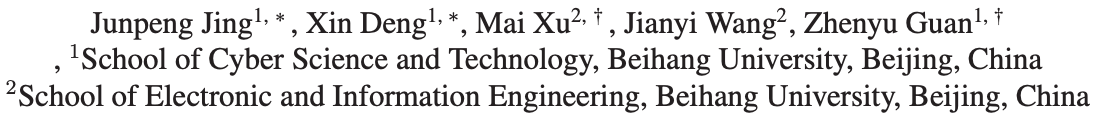
?

Figure 1. The illustration of difference between our image hiding method and the traditional methods [5, 23, 32].?
Ŀ¼
2.1. Steganography and Image Hiding
2.2. Invertible Neural Network
4.1. Experimental Settings Datasets and settings
Abstract
Image hiding aims to hide a secret image into a cover image in an imperceptible way, and then recover the secret image perfectly at the receiver end. Capacity, invisibility and security are three primary challenges in image hiding task.
This paper proposes a novel invertible neural network (INN) based framework, HiNet, to simultaneously overcome the three challenges in image hiding.
For large capacity, we propose an inverse learning mechanism by simultaneously learning the image concealing and revealing processes. Our method is able to achieve the concealing of a full-size secret image into a cover image with the same size.
For high invisibility, instead of pixel domain hiding, we propose to hide the secret information in wavelet domain.
Furthermore, we propose a new low-frequency wavelet loss to constrain that secret information is hidden in high-frequency wavelet subbands, which significantly improves the hiding security.
Experimental results show that our HiNet significantly outperforms other state-of-the-art image hiding methods, with more than 10 dB PSNR improvement in secret image recovery on ImageNet, COCO and DIV2K datasets.?
ͼ�����ص�Ŀ���ǽ�����ͼ��(secret image)��һ�ֲ��ɲ���ķ�ʽ���ص�����ͼ��(cover image)��,Ȼ���ڽ��ն������ػָ�����ͼ�����������ɼ��ԺͰ�ȫ����ͼ�����ص�������ս��
���������һ���µĻ��ڿ��������� (INN) �Ŀ�� HiNet,��ͬʱ�˷�ͼ�������е�������ս��
���ڴ�������ͼ��,�����һ��ͬʱѧϰͼ�����غͽ�ʾ���̵Ŀ���ѧϰ���ơ��÷����ܹ�ʵ�ֽ�ȫ�ߴ�����ͼ�����ص���ͬ�ߴ�ĸ���ͼ���С�
Ϊ����߲��ɼ���,�����С����������������Ϣ,���������������ء�
����,�����һ���µĵ�ƵС�������Լ��������Ϣ�������ڸ�ƵС���Ӵ���,�����������صİ�ȫ����
ʵ��������,�� ImageNet��COCO �� DIV2K ���ݼ���,HiNet ����ͼ��ָ������������������Ƚ���ͼ�����ط���,PSNR ����� 10 dB ���ϡ�
1.? Introduction
The task of image hiding is to conceal a secret image into a cover image to generate a stego image, which only allows the informed receivers to recover the secret image, but invisible to other people. For security concern, the stego image is usually required to be indistinguishable from the cover image. Different from bit-level message hiding or steganography [2, 20, 35, 36, 39�C41], image hiding is more challenging, which requires large capacity, high invisibility and security. Image hiding has a wide range of applications, of which secret communication and privacy protection are the most significant ones. Compared to the well-known image cryptography, image hiding has a remarkable security advantage, i.e., the stego image with secret information inside is indistinguishable from the cover image, which makes it more suitable for secret communication. In addition, unlike image cryptography, image hiding focuses more on the capacity and invisibility of hidden information rather than robustness.
�о�����:�����,��ɶ�á�ͼ�����ص������ǽ�����ͼ��(secret image)���ص�����ͼ��(cover image)��,������дͼ��(stego image),ֻ����֪��Ľ��շ��ָ�����ͼ��,���������˲��ɼ������ڰ�ȫ����,��дͼ��ͨ��Ҫ�����ڱ�ͼ���������֡���λ����Ϣ���ػ���д����ͬ,ͼ�����ظ�����ս��,��Ҫ���������߲��ɼ��ԺͰ�ȫ����ͼ�����ؾ��й㷺��Ӧ��,��������ͨ�ź���˽����������Ҫ��Ӧ�á���������֪��ͼ������ѧ���,ͼ�����ؾ��������İ�ȫ������,������������Ϣ����дͼ���뱻��ͼ����������,���ʺϽ�������ͨ�š�����,��ͼ������ѧ��ͬ,ͼ�����ظ�ע��������Ϣ�������Ͳ��ɼ���,������³������
(��������ͼ��ķ���,��������ʱ��ô����,����ר���Ǹ���ָ����)
Traditional steganographic approaches can only hide a small amount of information [6,11,13,16,19,24], which cannot meet the requirement of large capacity in image hiding task. Baluja [4] proposed the first convolutional neural network (CNN) to solve image hiding problem. This work was then extended in [5] by permuting the pixels of secret image to enhance the hiding security. Weng et al. [32] further proposed a deep network for video steganography by temporal residual modeling. However, all these methods adopt two sub-networks for image hiding: a concealing network to hide a secret image
into a cover image to generate a stego image xstego, and a revealing network to recover the secret image xrec from xstego, as shown in Fig. 1 (a). The concealing and revealing networks have two sets of parameters, which are linked through simple concatenation. This loose connection may cause color distortion and texture-copying artifacts. Besides, they barely consider the security issue, making hidden secret information easy to be detected.?
�о���״:ָ���������ս����ͳ����д����ֻ��������������Ϣ,��������ͼ�����������������Ҫ��Baluja [4] ����˵�һ������������ (CNN) �����ͼ���������⡣�� [5] ��,ͨ��������ͼ�����ص�������������صİ�ȫ�ԡ�Weng et al. [32] ��һ�������һ�ֻ���ʱ��вģ����Ƶ��д������硣Ȼ��,������Щ����������������������������ͼ������:��������������ͼ�� ���سɸ���ͼ��������һ����дͼ��
����ʾ�����ָ���?
?�ָ�����ͼ��,��ͼ 1(a) ��ʾ,���غͽ�ʾ���������ֲ���,����ͨ��������ʵ�֡������ɳ�����(loose connection)���ܻᵼ����ɫʧ�����������ЧӦ������,��Щ�������������ǰ�ȫ����,ʹ�����ص�������Ϣ�����ױ�������?
Fig.1
In this paper, we propose an invertible image hiding network, HiNet, in which the concealing and revealing processes share the same set of network parameters, as shown in Fig. 1 (b). To the best of our knowledge, our work is the first attempt to explore invertible network in image hiding task. The main novelty is that image revealing is modelled as the reverse process of image concealing in an invertible network architecture, which means the network only needs to be trained once to get all network parameters for both concealing and revealing. This is a radical difference from the existing methods [5, 23, 32] which treat the concealing and revealing processes independently. Consequently, our HiNet achieves state-of-the-art performance on recovery accuracy, hiding security and invisibility.
�������һ�������ͼ����������,HiNet,���غͽ�ʾ�Ĺ����й�����ͬ���������,��ͼ 1(b) ��ʾ��������(Ӧ����)����һ�γ���̽������������ͼ�����������е�Ӧ��������Ҫ��ӱ֮������,��һ�����������ṹ��,��ͼ����ʽ��ģΪͼ�����صķ������,����ζ��ֻ����������һ��ѵ��,�Ϳ��Եõ����غͽ�ʾ����������������������еķ��� [5,23,32] ��Ȼ��ͬ,���з��������������غͽ�ʾ���̡����,HiNet �ڻָ����ȡ����ذ�ȫ����������ﵽ�����Ƚ������ܡ�
The main contributions of this paper are summarized as follows:
? We propose a novel image hiding network, namely HiNet, based on invertible neural network for the task of large-capacity image hiding.
? We design two concealing and revealing modules with differentiable and invertible property, aiming to make the image hiding process fully reversible.
? We propose a low-frequency wavelet loss to control the distribution of secret information in different frequency bands, which significantly improves the hiding security.
������:
?? ��Դ�����ͼ����������,�����һ�ֻ���������������ͼ���������� HiNet��
?? ������������п��Ϳ������ʵ����غͽ�ʾģ��,Ŀ����ʹͼ�����ع�����ȫ���档
?? �����ƵС�����,��������������Ϣ�ڲ�ͬƵ�εķֲ�,����������صİ�ȫ����
2.? Related Work
2.1. Steganography and Image Hiding
(��)
2.2. Invertible Neural Network
Invertible neural network (INN) was first proposed by Dinh et al. [9]. Given a variable y and the forward computation x =
(y), one can recover y directly by y =
(x), where the inverse function
������������:���������� (INN) ������ Dinh et al. [9] ������������� y �����ݼ��� x = (y),����ͨ�� y =
(x) ֱ�ӻָ� y,�����溯��
?��?
������ͬ�IJ���?
��Ϊ��ʹ INN ���õش�����ͼ����ص�����,Dinh et al.[10] �����ģ���������˾�����,�������˶�߶Ȳ�,�Խ��ͼ���ɱ�,�������������Kingma et al. [15] �� INN �������˿���� 1 �� 1 ����,������� Glow,���㷨��ͼ�����ʵ�кϳɺʹ����dz���Ч��
Due to the excellent performance, INN has been utilized in many image-related tasks. Specifically, Ouderaa et al. [28] applied INN to image-to-image translation task. Ardizzone et al. [3] introduced conditional INN to guided image generation and colorization, in which the inverse process was guided by a conditional parameter. Xiao et al. [33] attempted to find a mapping between low and high resolution images using INN for image rescaling. Lugmayr et al. [18] proposed a normalizing flow-based method via INN on super-resolution, which attempted to directly account for the illposed nature of super-resolution, and learn to predict diverse photo-realistic high-resolution images. Most recently, Wang et al. [30] applied INN in digital image compression task. However, to the best of our knowledge, there is no work to?explore INN in image hiding task.
����������Ӧ��:���������������,INN ������������ͼ����ص������С�Ouderaa et al. [28] �� INN Ӧ����ͼ��ͼ���ת������Ardizzone et al. [3] ������ INN ���뵽����ͼ�����ɺ���ɫ��,�������������������������Xiao et al. [33] ��ͼͨ�� INN ����ͼ��������Ѱ�ҵͷֱ��ʺ߷ֱ���ͼ��֮���ӳ�䡣Lugmayr et al. [18] �����ֱ����������һ�ֻ��� INN �Ĺ�һ��������,��ͼֱ�ӽ��ͳ��ֱ��ʵIJ�̬����,��ѧϰԤ����ֱ���ĸ߷ֱ���ͼ�����,Wang et al. [30] �� INN Ӧ��������ͼ��ѹ������Ȼ��,��������֪,INN ��ͼ�����������в�û��̽��������
3.? Methods
�ڱ�����,�����һ���µ���������-��ʾ���� HiNet,��ʵ�����������߰�ȫ�Ժ߲��ɼ�����ͼ�����ء��� 1 �����˱���ʹ�õķ��š�

3.1. Network architecture
Fig. 2 shows the overall framework of the proposed HiNet.
In the forward concealing process, a pair of secret image
are accepted as inputs. They?are first decomposed into low and high-frequency wavelet sub-bands through discrete wavelet transform (DWT), which are then fed into a sequence of concealing blocks. The outputs of the last concealing block go through an inverse wavelet transform (IWT) block to generate a stego image
, together with the lost information r.
In the backward revealing process, the stego image
HiNet ������:��ͼ 2��
ǰ�����ع���:����Ϊ����ͼ�� ����ͼ��
?��
����,ͨ����ɢС���任 (DWT) �����ֽ�Ϊ�͡���ƵС���Ӵ�;
Ȼ��,�������뵽���ؿ�������;
���,���ؿ�����������С���任 (IWT) ��������һ����дͼ�� , ��һ��ʧȥ����Ϣ r��
�����ʾ����:����ͼ��? ��һ���������� z ͨ�� DWT ��һϵ�н�ʾģ��ָ�����ͼ��
��?
Figure 2. The framework of HiNet. In the forward concealing process, a secret image is hidden in a cover image through several concealing blocks to generate a stego image, together with the lost information. In the backward revealing process, the stego image and an auxiliary variable z from Gaussian distribution are fed to a series of revealing blocks to recover the secret image. Note that in our HiNet, revealing is the inverse process of concealing, and thus they share the same network parameters.

ͼ2:HiNet ��ܡ�ע��,�� HiNet ��,��ʾ�����ص������,������ǹ�����ͬ�����������
Wavelet domain hiding
Image hiding in pixel domain can easily lead to texture-copying artifacts and color distortion [11, 32]. Compared to pixel domain, the frequency domain, especially high-frequency domain, is more appropriate for image hiding.
In this paper, we adopt DWT to split image into low and high-frequency wavelet sub-bands before entering the invertible blocks, so that the network can better fuse the secret information into the cover image.
Moreover, the perfect reconstruction property of wavelets [21] can help decrease the information loss and improve the image hiding performance.
After DWT, the feature map of size (B, C, H,W) is turned into (B, 4C, H/2,W/2), in which B is batch size, H is height, W is width and C is channel number. As we can see, the computational cost can be reduced by DWT, which can help accelerate the training process.
Here, we adopt Haar wavelet kernel to perform DWT and IWT, for its simplicity and effectiveness. Note that wavelet transform is bidirectional symmetric, which means it will not affect the end-to-end training of our network.
����:ΪʲôҪ��С�������ͼ�����ء�
ͼ����������������������������αӰ����ɫʧ���������������,Ƶ����,��������Ƶ����ʺ�ͼ��������
���IJ���С���任�ڽ������ģ��֮ǰ,��ͼ��ֳɵ�ƵС���Ӵ�,ʹ�����ܹ����õؽ�������Ϣ�ںϵ�����ͼ������
����,С���������õ��ع�����,�����ڼ�����Ϣ��ʧ,���ͼ������������
DWT?��,size (B,C,H,W) �� feature map ��Ϊ? (B,4C,H/2,W/2)�����Կ���,DWT ���Խ��ͼ���ɱ�,�����ڼ���ѵ��������
�������� Haar С��������С���任��С���任,����Ч��
ע��С���任��˫��ԳƵ�,����ζ��������Ӱ������Ķ˵���ѵ����
(ÿһ�䶼����,���ŵ���չ����˵��Ϊʲô�������뵽��ô���ŵ�?)
Invertible concealing and revealing blocks
As shown in Fig. 2, the concealing and revealing blocks have the same sub-modules and share the same network parameters, but with reverse information flow directions. There are M concealing blocks with the same architecture, which is constructed as follows. For the i-th concealing block in the forward process, the inputs are
and
, and the outputs
and
are formulated as follows,
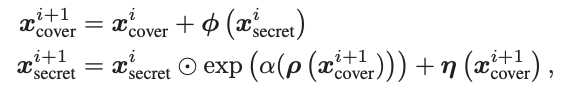
? (1)
where �� is a sigmoid function multiplied by a constant factor served as a clamp, and?
indicates the dot product operation. Here, ��(��), ��(��) and ��(��) are arbitrary functions and we adopt the widely used dense block in [29] to represent them for its good representation ability. The influence of different architectures for ��(��), ��(��), and ��(��) is discussed in ablation study in Section 4.4. After the last concealing block, we can obtain the outputs
and ?
, which are then fed into two IWT blocks to generate the stego image
ģ�ͽ���:�������غͽ�ʾģ������ṹ��
��ͼ 2 ��ʾ,���ؿ�ͽ�ʾģ�������ͬ����ģ��,������ͬ���������,����Ϣ�������෴����ģ���� M ����ͬ�ṹ������ģ�顣
����ģ��:
����ǰ������еĵ� i ������ģ��,����Ϊ and
,���
and
��ʾΪ (1)��
����,�� ��һ�� s �ͺ�������һ����Ϊ?clamp �ij�������,��ʾ������㡣
���� ��(��)����(��) �� ��(��) �����⺯��,���IJ��� [29] �й㷺ʹ�õ� dense blocks ����ʾ����,��Ϊ���������õı�ʾ��������ͬ��ϵ�ṹ�� ��(��)����(��) �� ��(��) ��Ӱ���� 4.4 �ڵ������о��н��������ۡ�
�����һ������ģ��֮��,���Եõ���� and ?
,Ȼ������������� IWT ��,�ֱ�������дͼ��?
�Ͷ�ʧ��Ϣ r��??
In the revealing process, the information flow direction is from the (i+1)-th revealing block to the i-th revealing block, which is in reverse order to the concealing process, as shown in Fig. 2. Specifically, for the M-th revealing block, the inputs are
?and
which are generated by the stego image
and
. For the i-th revealing block, the inputs are
and
, and the outputs are
?and
. Their relationship is modelled as follows,
(2)
After the last revealing block, i.e., the revealing block 1, the output
is fed into an IWT block to generate the recovery image
.?
��ʾģ��:
�ڽ�ʾ������,��Ϣ���ķ����Ǵ� �� (i+1) ����ʾģ�鵽�� i ����ʾģ��,�����ع��̵�˳���෴,��ͼ 2 ��ʾ��������˵,���ڵ� M ����ʾģ��,����������дͼ�� �������� z ͨ�� DWT ���ɵ�
?and
������,z �ǴӸ�˹�ֲ���������������� M?����ʾ��������
and
�����ڵ� i?����ʾģ��,������
and
,�����
?and
�����ǵĹ�ϵ�� (2) ��ʾ�������һ����ʾģ��,����ʾģ�� 1 ֮��,���
?������ IWT ģ��,���ɻָ�ͼ��
��
The lost information r and auxiliary variable z
The lost information r is one of the outputs in the forward concealing process, and z is one input to the backward revealing process. In the concealing process, the network tries to hide the secret image into the cover image. However, it is difficult to hide such a large capacity in the cover image, which inevitably leads to the loss of secret information. In addition, the intrusion of secret image may destroy the?original information in the cover image. The lost secret information and destroyed cover information make up the lost information r.
Here, r is assumed to be case-agnostic for the reasons below. Suppose that the distribution of all images in dataset is
. The inputs in the forward process are
. Due to the strict equivalence of Eqs. (1) and (2), and the reversible constraint of INN, the mixed distribution of the outputs
. For stego image
. Thus, it is reasonable to assume the remained r to be case-agnostic.????????
��ʧ����Ϣ r ��ǰ�����ع��̵�һ�����,z �Ǻ����ʾ���̵�һ�����롣
�����ع�����,������ͼ������ͼ�����ص�����ͼ���С�Ȼ��,��˴���������������ڷ���ͼ����,���ɱ���ص���������Ϣ�Ķ�ʧ������,����ͼ������ֿ��ܻ��ƻ�����ͼ���е�ԭʼ��Ϣ����ʧ��������Ϣ�ͱ��ƻ����ڻ���Ϣ�����˶�ʧ����Ϣ r��
����,r ���ٶ�Ϊ�����ص�?case- notistic,ԭ������:
�������ݼ�������ͼ��ķֲ�Ϊ ��ǰ����̵�������
��
,���Ǵ���ͬ�����ݼ�����,�����ѭ��ͬ�ķֲ�:
�����ڷ��� (1) �� (2) ���ϸ�ȼ���,�Լ� INN �Ŀ���Լ��,���?
�� r �Ļ�Ϸֲ�Ӧ������������ͬ�ķֲ�,��
��������дͼ��
,�� 3.2 ���е�������ʧ�ƶ���ֲ��븲��ͼ��ƥ��,��
�����,���Ժ����ؼ���ʣ�µ� r �Ǹ����ص���?
In backward revealing, the recovery image
.?
������ʾ��,�ָ�ͼ��? Ҫ��ֻ����дͼ��?
����ȡ,�������� r����ʵ������һ�����ʶ�������,��Ϊ���Դ�ͬһ��?
�лָ��������
��Ϊ�˻�þ�ȷ��
,�ڷ�ʾ�����в�����һ���������� z������ z �Ǵ�һ�� case- notistic �ֲ��������ȡ��,�÷ֲ��� r �ķֲ���ͬ���÷ֲ�����ѵ��ʱͨ�� 3.2 �ڵĽ�ʾ��ʧ��ѧϰ��,ȷ���ֲ��е�ÿ���������ܺܺõػָ�������Ϣ���ڲ�ʧһ���Ե�ǰ����,����ֲ�Ϊ��˹�ֲ�,��
��??
Why INN works for image hiding?
The image hiding task is composed of two reverse procedures: the concealing procedure aims to hide a secret image xsecret in a cover image xcover, to generate a new container called stego image xstego; while the revealing procedure attempts to recover the secret image from the stego image as high-fidelity as possible. In previous works [5, 23, 32], the concealing and revealing procedures are sequentially achieved by two forward networks, i.e., one network for concealing and the other for revealing. However, for perfect concealing and revealing performance, these two processes should be fully reversible. Based on this, we innovatively treat the image concealing and revealing as the forward and backward processes of the same INN, i.e, they are invertible. As a result, they can coordinate with each other to improve the hiding and revealing performance simultaneously. As demonstrated in the experiments, our network with INN architecture significantly advances the state-of-the-art image hiding performance.
һ�仰:���ع��� �� ��ʾ���� Ӧ���ǿ���Ĺ�ϵ��
ͼ��������������������������:���ع���ּ�ڽ�����ͼ��? ���ص�����ͼ��?
��,����һ���µ�������Ϊ stego ͼ��
;����ʾ��������ͼ����дͼ���лָ��������ܸ߱��������ͼ��
��ǰ�˵Ĺ�����,���غͽ�ʾ������������ǰ������������ɵ�,һ������������,��һ���ǽ�ʾ���硣
Ȼ��,Ϊ�����������غͽ�ʾ����,����������Ӧ������ȫ����ġ�
�ڴ˻�����,���Ĵ����Եؽ�ͼ������غͽ�ʾ��Ϊͬһ INN ������ͷ������,��������̡�
���,���ǿ����Э��,ͬʱ������غ���ʾ���ܡ�
������ʵ����֤����,���ĵ������� INN ��ϵ�ṹ������������Ƚ���ͼ���������ܡ�
3.2. Loss function
The total loss function is composed of three different losses: the concealing loss to guarantee the concealing performance, the revealing losses to ensure the recovering performance, and a new low-frequency wavelet loss to enhance the hiding security.?
����ĺ��������ֲ�ͬ��������:��֤�������ܵ�������ġ���֤�ָ����ܵĽ�ʾ��ĺ���ǿ���ذ�ȫ�Եĵ�ƵС����ġ�
Concealing loss
The forward concealing process aims?to hide
is defined as follows,

? ? (3)
where
?is equal to
, with �� indicating the network parameters. In addition, N is the number of training samples, and C measures the difference between cover and stego images, which can be 1 or 2 norm.
������ʧ:
ǰ�����ع��̵�Ŀ���ǽ�? ���ص�?
��,����?
ͼ����дͼ��Ҫ���븲��ͼ���������֡�Ϊ��,������ʧ?
�Ķ�������:?
���� ?����
, �� ��ʾ���������N Ϊѵ����������,C Ϊ����ͼ�����дͼ��IJ�ֵ,������1����2��������?????
Revealing loss
In the backward revealing process, given the stego image
as follows,
(4) ?
where the recovery image
is equal to
, with
?indicating the backward revealing process. Similar to C, R measures the difference between recovered secret images
�ø�˹�ֲ� p(z) �е����� z �����ָ�����ͼ��Ϊ��,����ʾ��ʧ ������?(4)�����лָ�ͼ��?
����
,����?
��ʾ���Թ��̡��� C ����,R �����ָ�������ͼ��?
�� GT ������ͼ��?
֮��IJ��졣?????
Low-frequency wavelet loss
In addition to the above two losses, we propose a low-frequency wavelet loss
to enhance the network��s anti-steganalysis ability. The motivation of this loss is from [4], which verifies that the information hidden in high-frequency components is less likely to be detected than that in low-frequency components. Here, in order to ensure most information is hidden in the highfrequency sub-bands, the low frequency sub-bands of stego image are required to be similar to those of cover image after wavelet decomposition. Suppose that
indicates the operation of extracting low-frequency sub-bands after wavelet decomposition, the low-frequency wavelet loss
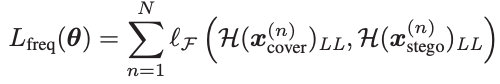
?
(5)
Here, F measures the difference between the low-frequency sub-bands of cover and stego images.
��ƵС����ʧ:
��������������ʧ��,��������˵�ƵС����ʧ? ����ǿ���������д����������������ʧ�Ķ������� [4],��֤ʵ����������Ƶ�����е���Ϣ���ڵ�Ƶ�����е���Ϣ�������ױ���������,Ϊ����֤����Ϣ�����ڸ�Ƶ�Ӵ���,Ҫ����дͼ��ĵ�Ƶ�Ӵ�����С���ֽ���븲��ͼ��ĵ�Ƶ�Ӵ���������?
��ʾС���ֽ����ȡ��Ƶ�Ӵ��IJ���,���ƵС�����?
����Ϊ (5)������,F �������Ǻ���дͼ��ĵ�Ƶ�Ӵ�֮��IJ��졣
Total loss function
The total loss function
is a weighted sum of concealing loss
Here, ��c, ��r and ��f are weights for balancing different loss terms. In the training process, we firstly pre-train the network by minimizing
����ʧ����:
����ĺ���Ltotal��������� ����ʾ���?
�͵�ƵС�����?
�ļ�Ȩ��,��?(6)��
����,��c, ��r, ��f ��ƽ�ⲻͬ��ʧ���Ȩ�ء���ѵ��������,����ͨ����С��? ��?
���������Ԥѵ��,������ ��f Ϊ 0��Ȼ��,����?
�Զ˵��˷�ʽѵ�����硣???
4.? Experiments
4.1. Experimental Settings Datasets and settings
The DIV2K [1] training dataset is used for training our HiNet. The testing datasets include DIV2K [1] testing dataset with 100 images at resolution 1024 �� 1024, ImageNet [25] with 50,000 images at resolution 256 �� 256, and COCO [17] dataset with 5,000 images at resolution 256 �� 256. Note that the testing images are cropped using center-cropping strategy, to make sure the cover and secret images are with the same resolution. The number of concealing and revealing blocks M is set to 16. The training patch size is 256 �� 256, and the number of total iteration is 80K. The parameters ��c, ��r and ��f are set to 10.0, 1.0, 10.0, respectively. The mini-batch size is set to 16, in which half is randomly selected as cover patches and the remained are secret patches. The Adam [14] optimizer is adopted with standard parameters and an initial learning rate of 1 �� 10?4.5 , which is halved every 10K iterations.?
DIV2K ѵ�����ݼ�����ѵ��?HiNet���������ݼ����� DIV2K �������ݼ�,�ֱ���Ϊ1024 �� 1024,����100��ͼ��;ImageNet �������ݼ�,�ֱ���Ϊ 256 �� 256,���� 50,000 ��ͼ��;COCO �������ݼ�,�ֱ���Ϊ 256 �� 256,���� 5,000 ��ͼ��
����ͼ����ʹ�����IJü����Բü���,��ȷ�����������ͼ�������ͬ�ķֱ��ʡ����غ���ʾ��M����������Ϊ16��ѵ�� patch ��СΪ 256 �� 256,�ܵ�������Ϊ 80K����c����r����f �ֱ���Ϊ 10.0��1.0��10.0��mini batch ��С����Ϊ 16,�������ѡȡһ����Ϊ cover patches,����Ϊ secret patches������ Adam �Ż���,���ñ�����,��ʼѧϰ��Ϊ 1 �� 10?4.5,ÿ 10K �ε������롣
Benchmarks
To verify the effectiveness of our method, we compare it with several state-of-the-art (SOTA) image hiding methods, including one traditional image steganography method named 4bit-LSB, and three deep learning based methods: HiDDeN [41], Weng et al. [32], and Baluja [5]. For fair comparison, we re-trained the models of Weng et al. [32], Baluja [5], and HiDDeN [41] using the same training dataset as ours. Note that the original HiDDeN [41] model can only hide messages, which is not consistent with the image hiding configuration in this paper. To make it able to hide images, we slightly modified its output dimension and then re-trained the network.
Ϊ����֤��������Ч��,�����뼸�����Ƚ��� (SOTA) ͼ�����ط��������˱Ƚ�,����һ�ִ�ͳ��ͼ�����ط��� 4bit-LSB,�Լ����ֻ������ѧϰ�ķ���:HiDDeN[41]��Weng et al. [32] ��Baluja[5]��Ϊ�˱ȽϹ�ƽ,ʹ����������ͬ��ѵ�����ݼ��� Weng et al. [32]��Baluja [5] �� HiDDeN ��ģ�ͽ���������ѵ����ע��,ԭ���� HiDDeN ģ��ֻ��������Ϣ,���뱾�ĵ�ͼ���������ò�һ�¡�Ϊ��ʹ���ܹ�����ͼ��,�������������ά��,Ȼ������ѵ�������硣
Evaluation metrics
There are four metrics adopted to measure the quality of cover/stego and secret/recovery pairs, including Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM) [31], Root Mean Square Error (RMSE), and Mean Absolute Error (MAE). The larger value of PSNR, SSIM and smaller value of RMSE, MAE indicate higher image quality. In addition, we use the statistical steganalysis tool named StegExpose [7] and SRNet [8] to evaluate the security performance of our method.
���IJ��÷�ֵ����� (PSNR)���ṹ������ָ�� (SSIM)����������� (RMSE) ��ƽ��������� (MAE) 4��ָ���������ڱ�/��д������/�ָ��Ե�������PSNR��SSIM ֵԽ��,RMSE��MAE ֵԽС,ͼ������Խ�á�����,����ʹ��ͳ����д�������� StegExpose [7] �� SRNet [8] ���������ǵķ����İ�ȫ���ܡ�


5.? Conclusion
In this paper, we propose a novel invertible neural network named HiNet for image hiding, which drastically increases both the hiding security and recovering accuracy. Our HiNet models the image concealing and revealing as the forward and backward processes of an invertible network, which means that they share the same network parameters. As a consequence, the network only needs to be trained once to get all network parameters for both image concealing and revealing processes. In network training, a new lowfrequency wavelet loss is proposed to improve the security of image hiding. Extensive experimental results show that our method can achieve image hiding with large capacity and high security, which significantly outperforms other SOTA methods both quantitatively and qualitatively.
���������һ���µ�����ͼ�����صĿ��������� HiNet,�������������صİ�ȫ�Ժͻָ���ȷ�ԡ�HiNet ��ͼ������غͽ�ʾ��ģΪ���������ǰ��ͺ������,����ζ�����ǹ�����ͬ��������������,��ͼ�����غͽ�ʾ������,ֻ����������һ��ѵ��,���ɻ�����е����������������ѵ����,Ϊ�����ͼ�����صİ�ȫ��,�����һ���µĵ�ƵС����ʧ�㷨��������ʵ��������,�÷����ܹ�ʵ�ִ��������߰�ȫ�Ե�ͼ������,�ڶ����Ͷ����϶������������� SOTA ������