ФПТМ
вЛЁЂОіВпЪї
1ЁЂЖЈвх
ОіВпЪї(decision tree):ЪЧвЛжжЛљБОЕФЗжРргыЛиЙщЗНЗЈ,ЪЧдквбжЊИїжжЧщПіЗЂЩњИХТЪЕФЛљДЁЩЯ,ЭЈЙ§ЙЙГЩОіВпЪїРДЧѓШЁОЛЯжжЕЕФЦкЭћжЕДѓгкЕШгкСуЕФИХТЪ,ЦРМлЯюФПЗчЯе,ХаЖЯЦфПЩааадЕФОіВпЗжЮіЗНЗЈ,ЪЧжБЙлдЫгУИХТЪЗжЮіЕФвЛжжЭМНтЗЈЁЃгЩгкетжжОіВпЗжжЇЛГЩЭМаЮКмЯёвЛПУЪїЕФжІИЩ,ЙЪГЦОіВпЪїЁЃ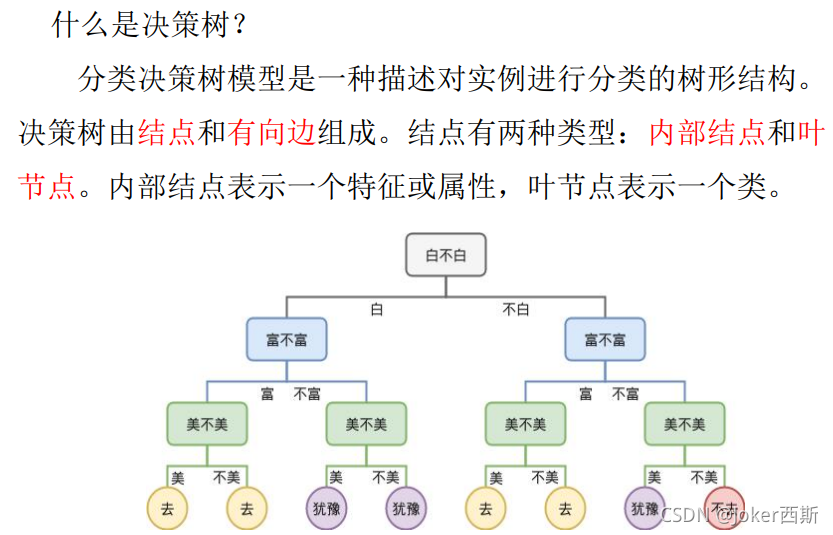
?2ЁЂЙЙдь
ОіВпЪїбЇЯАЕФЫуЗЈЭЈГЃЪЧвЛИіЕнЙщЕибЁдёзюгХЬиеї,ВЂИљОнИУЬиеїЖдбЕСЗЪ§ОнНјааЗжИю,ЪЙЕУИїИізгЪ§ОнМЏгавЛИізюКУЕФЗжРрЕФЙ§ГЬЁЃетвЛЙ§ГЬЖдгІзХЖдЬиеїПеМфЕФЛЎЗж,вВЖдгІзХОіВпЪїЕФЙЙНЈЁЃ
1) ПЊЪМ:ЙЙНЈИљНкЕу,НЋЫљгабЕСЗЪ§ОнЖМЗХдкИљНкЕу,бЁдёвЛИізюгХЬиеї,АДзХетвЛЬиеїНЋбЕСЗЪ§ОнМЏЗжИюГЩзгМЏ,ЪЙЕУИїИізгМЏгавЛИідкЕБЧАЬѕМўЯТзюКУЕФЗжРрЁЃ
2) ШчЙћетаЉзгМЏвбОФмЙЛБЛЛљБОе§ШЗЗжРр,ФЧУДЙЙНЈвЖНкЕу,ВЂНЋетаЉзгМЏЗжЕНЫљЖдгІЕФвЖНкЕуШЅЁЃ
3)ШчЙћЛЙгазгМЏВЛФмЙЛБЛе§ШЗЕФЗжРр,ФЧУДОЭЖдетаЉзгМЏбЁдёаТЕФзюгХЬиеї,МЬајЖдЦфНјааЗжИю,ЙЙНЈЯргІЕФНкЕу,ШчЙћЕнЙщНјаа,жБжСЫљгабЕСЗЪ§ОнзгМЏБЛЛљБОе§ШЗЕФЗжРр,ЛђепУЛгаКЯЪЪЕФЬиеїЮЊжЙЁЃ
4)УПИізгМЏЖМБЛЗжЕНвЖНкЕуЩЯ,МДЖМгаСЫУїШЗЕФРр,етбљОЭЩњГЩСЫвЛПХОіВпЪїЁЃ
?
ЖўЁЂДњТыЪЕЯж
1.аХЯЂдівц

?вЛАуЖјбд,аХЯЂдівцдНДѓ,дђвтЮЖзХЪЙгУЪєадaРДНјааЛЎЗжЫљЛёЕУЕФЁАДПЖШЬсЩ§ЁБдНДѓ
ДњТыЪЕЯж?
#МЦЫуаХЯЂдівц
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt1(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet,i,value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet) #МЦЫуЯуХЉьи
infoGain = baseEntropy - newEntropy #МЦЫуаХЯЂдівц
if (infoGain >bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature 2.Ъ§ОнМЏ
?вд100ЬѕеїБјШыЮщЕФЪ§Он,гУ'ЩэИп', 'Ьхжи', 'ЪгСІ', 'гаЮоЮЦЩэ', 'зуаЭ','гаЮоДЋШОВЁ',ХаЖЯЪЧЗёТњзуШыЮщвЊЧѓЁЃ
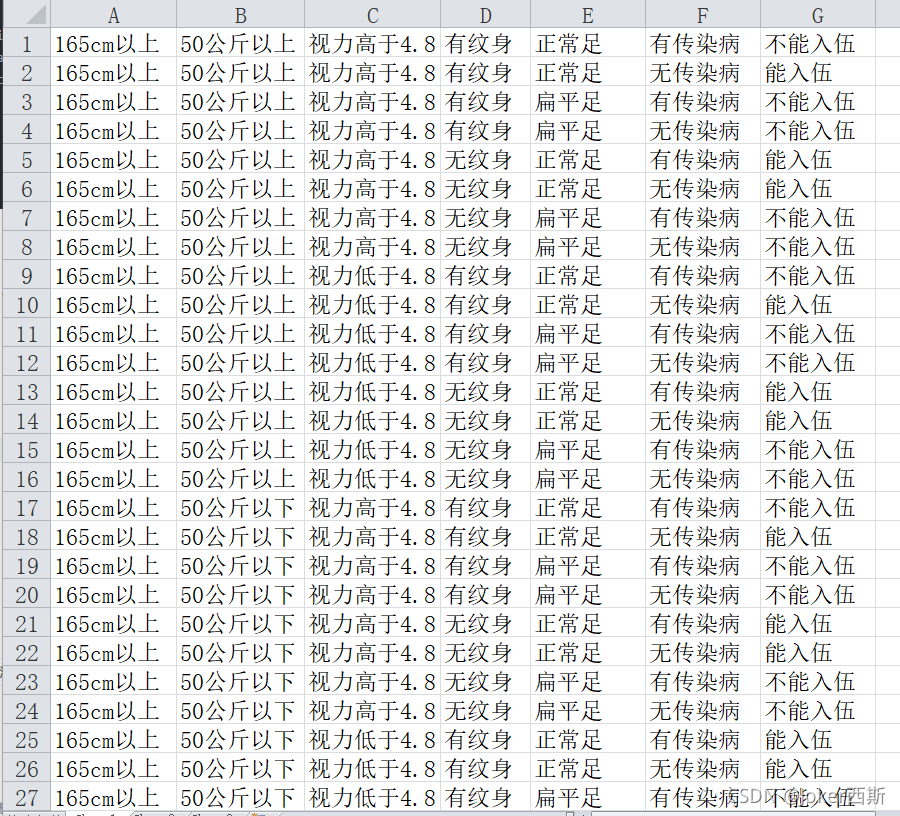
?ЖСШыЪ§ОнМЏ
#ЖСШыЪ§ОнМЏ
import pandas as pd
myData = pd.read_excel('C:\Users\Rouger\PycharmProjects\pythonProject\shujuji.xlsx',header = None)
print(myData.head())
myData = np.array(myData).tolist()
for d in myData:
for i in range(len(d)):
d[i] = d[i].strip()
Labels = ['ЩэИп', 'Ьхжи', 'ЪгСІ', 'гаЮоЮЦЩэ', 'зуаЭ','гаЮоДЋШОВЁ']3.ОіВпЪї
ДњТыШчЯТ
#ДДНЈОіВпЪї
def createTree(dataSet,labels):
#ШЁЗжРрБъЧЉ
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0] #РрБ№ЭъШЋЯрЭЌдђЭЃжЙМЬајЛЎЗж
if len(dataSet[0]) == 1:
return majorityCnt(classList) #БщРњЭъЫљгаЬиеїЪБЗЕЛиГіЯжДЮЪ§зюЖрЕФ
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues) #ЕУЕНСаБэАќКЌЕФЫљгаЪєаджЕ
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)
return myTree
#ЪЙгУpickleДцДЂОіВпЪї
def storeTree(inputTree, filename):
import pickle
fw = open(filename, 'w')
pickle.dump(inputTree, fw)
fw.close()
#ЖСШЁОіВпЪї
def grabTree(filename):
import pickle
fr = open(filename)
return pickle.load(fr)
4.ЪЙгУMatplotlibЛцжЦОіВпЪї
ДњТыШчЯТ
#ЛцжЦОіВпЪї
import matplotlib.pyplot as plt
decisionNode = dict(boxstyle="sawtooth", fc="0.8")
leafNode = dict(boxstyle="round4", fc="0.8")
arrow_args = dict(arrowstyle="<-") #ЖЈвхЮФБОПђКЭМ§ЭЗ
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args) #ЛцжЦМ§ЭЗЕФзЂНт
#ЛёШЁвЖНсЕуЕФЪ§ФП
def getNumLeafs(myTree):
numLeafs = 0
#firstStr = myTree.keys()[0]
firstStr = next(iter(myTree))
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
numLeafs += getNumLeafs(secondDict[key]) #ВтЪдНкЕуЕФЪ§ОнЪЧЗёЮЊзжЕф
else: numLeafs +=1
return numLeafs
#ЛёШЁЪїЕФВуЪ§
def getTreeDepth(myTree):
maxDepth = 0
firstStr = next(iter(myTree))
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
thisDepth = 1 + getTreeDepth(secondDict[key])
else: thisDepth = 1
if thisDepth > maxDepth:
maxDepth = thisDepth
return maxDepth
#plotTreeКЏЪ§
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0]
yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1] #дкИИзгНкЕуМфЬюГфЮФБОаХЯЂ
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
def plotTree(myTree, parentPt, nodeTxt):
numLeafs = getNumLeafs(myTree)
depth = getTreeDepth(myTree) #МЦЫуПэгыИп
firstStr = next(iter(myTree))
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt) #БъМЧНкЕуЪєаджЕ
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD #МѕЩйyЦЋвЦ
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
plotTree(secondDict[key],cntrPt,str(key))
else:
plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD
#ДДНЈЛцжЦУцАх
def createPlot(inTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops)
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0;
plotTree(inTree, (0.5,1.0), '')
plt.show()
#ЪЙгУОіВпЪїЕФЗжРрКЏЪ§
def classify(inputTree,featLabels,testVec):
firstStr = list(inputTree.keys())[0]
secondDict = inputTree[firstStr]
featIndex = featLabels.index(firstStr) #НЋБъЧЉзжЗћДЎзЊЛЛЮЊЫїв§
for key in secondDict.keys():
if testVec[featIndex] == key:
if type(secondDict[key]).__name__=='dict':
classLabel = classify(secondDict[key],featLabels,testVec)
else:
classLabel = secondDict[key]
return classLabel5.ЪЕбщНсЙћ
ЪЙгУаХЯЂдівцЗНЗЈЩњГЩОіВпЪї
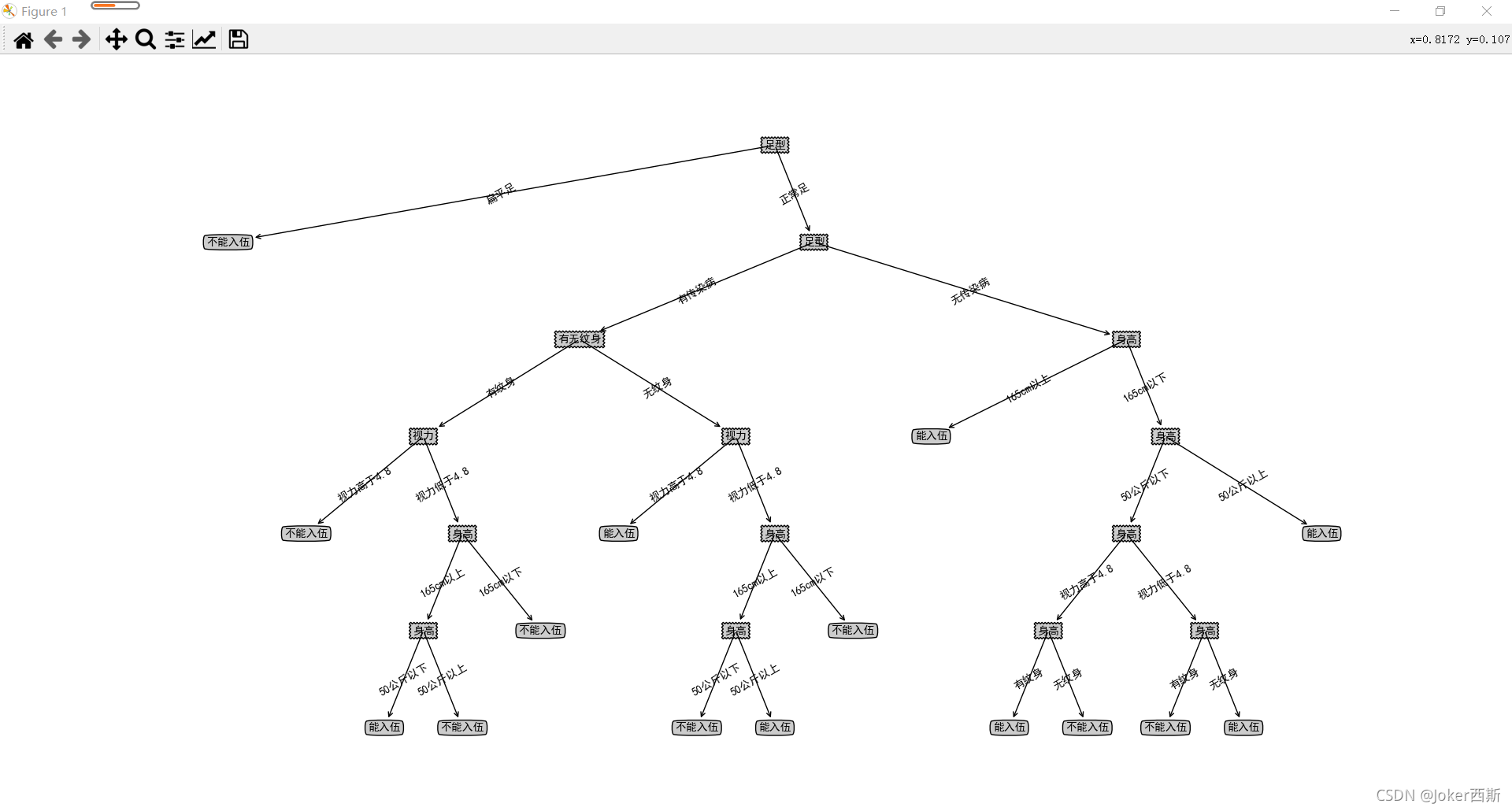
?ЪЙгУвдЯТЪ§ОнНјаабщжЄ

НсЙћ
 ?
?
?е§ШЗТЪЮЊ90%
Ш§ЁЂзмНс
1ЁЂгХЕу
1)взгкРэНтКЭНтЪЭ,ОіВпЪїПЩвдПЩЪгЛЏЁЃ
2)МИКѕВЛашвЊЪ§ОндЄДІРэЁЃЦфЫћЗНЗЈОГЃашвЊЪ§ОнБъзМЛЏ,ДДНЈащФтБфСПКЭЩОГ§ШБЪЇжЕЁЃОіВпЪїЛЙВЛжЇГжШБЪЇжЕЁЃ
3)ЪЙгУЪїЕФЛЈЗб(Р§ШчдЄВтЪ§Он)ЪЧбЕСЗЪ§ОнЕу(data points)Ъ§СПЕФЖдЪ§ЁЃ
4)ПЩвдЭЌЪБДІРэЪ§жЕБфСПКЭЗжРрБфСПЁЃЦфЫћЗНЗЈДѓЖМЪЪгУгкЗжЮівЛжжБфСПЕФМЏКЯЁЃ
5)ПЩвдДІРэЖржЕЪфГіБфСПЮЪЬтЁЃ
2ЁЂШБЕу
1)ОіВпЪїбЇЯАПЩФмДДНЈвЛИіЙ§гкИДдгЕФЪї,ВЂВЛФмКмКУЕФдЄВтЪ§ОнЁЃвВОЭЪЧЙ§ФтКЯЁЃаоМєЛњжЦ(ЯждкВЛжЇГж),ЩшжУвЛИівЖзгНкЕуашвЊЕФзюаЁбљБОЪ§СП,ЛђепЪ§ЕФзюДѓЩюЖШ,ПЩвдБмУтЙ§ФтКЯЁЃ
2)ОіВпЪїПЩФмЪЧВЛЮШЖЈЕФ,вђЮЊМДЪЙЗЧГЃаЁЕФБфвь,ПЩФмЛсВњЩњвЛПХЭъШЋВЛЭЌЕФЪїЁЃетИіЮЪЬтЭЈЙ§decision trees with an ensembleРДЛКНтЁЃ
3)ИХФюФбвдбЇЯА,вђЮЊОіВпЪїУЛгаКмКУЕФНтЪЭЫћУЧЁЃ
?