论文阅读汇总:
论文来源:https://arxiv.org/pdf/1905.09642.pdf
发表日期:2019arXiv.cs.CL
题目:基于迁移学习的日语情感分析研究
代码:https://github.com/dennybritz/sentiment-analysis
摘要:
文本分类方法通常需要特定任务的模型体系结构和巨大的标记数据集。在本文中,展示了迁移学习技术在日语文本分类中的潜在应用。具体而言,我们在乐天产品评论和雅虎电影评论数据集上执行二进制和多类情感分类。不难发现,基于迁移学习的方法比在3倍数据量上训练的比任务特定模型表现更好。此外,这些方法比在Wikipedia(维基百科)上的预训练语言模型效果更好。
背景:
日语的稀疏性,深度学习对大型数据集的依赖性,在分析日语方面投入的精力并不多。日语脚本不包含空格,句子可能模棱两可,因此有多种方式将字符拆分为单词,每种方式都有完全不同的含义。
预训练:

首先,我们在大型语料库上训练语言模型。然后,我们在目标语料库上对其进行微调。最后,使用标记的样本来训练分类器。
Word Embeddings:
单词嵌入是将单词表示为稠密向量。已有许多神经网络实现,包括word2vec(Mikolov等人,2013年)、fasttext(Joulin等人,2016年)和Glove(Pennington等人,2014年),它们使用单层嵌入并在各种NLP任务中实现最先进的性能。然而,这些嵌入并不是上下文特定的:在短语“我洗了我的盘子”和“我吃了我的盘子”中,“盘子”一词指的是不同的东西,但仍然由相同的嵌入来表示。
怎么使单词上下文有关?
(1)ELMo(Embeddings from LanguageModel)
通过以无监督的方式利用大量单语数据克服了这一问题。ELMO的核心基础是双向语言模型,它通过结合上下文来预测给定句子的目标词的概率。ELMo还需要特定任务的模型。
(2)ULMFiT(Embeddings from LanguageModel)
单模型结构的ULMFiT,可用于预培训和特定任务的微调。他们使用新的技术,如区分性微调和倾斜三角形学习率,以实现稳定的微调。OpenAI通过引入GPT(一种多层 transformer decoder)扩展了这一想法。ELMo使用正向和反向语言模型的浅层连接,而ULMFiT和OpenAI GPT是单向的。加粗样式
(3)Bert
基于多层的transformer encoder
训练过程
(1)预训练
文本提取,标记,使用了已经预训练的Bert base模型
结果
(1)没有经过预训练
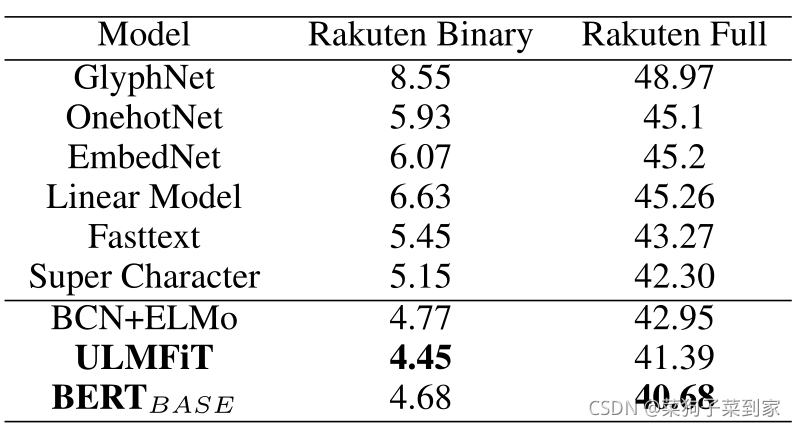
(2)经过了预训练
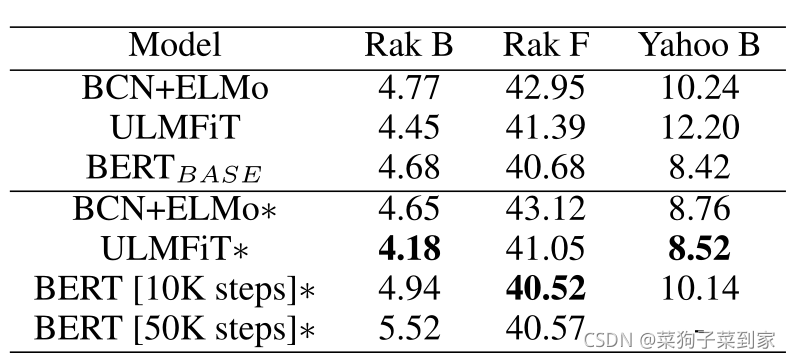
总结
基于乐天产品评论和雅虎电影评论数据集中所做的实验,得出以下结论:
(1)当任务是二进制分类时,为BERT调整域可能不会产生好的结果。对于所有其他情况,域自适应能更好。
(2)ELMo和ULMFiT即使在语言模型的一小部分上进行训练,也能表现良好。
(3)在目标任务上微调ELMo和BCN层可以提高性能。
(4)只有13%的数据集,迁移学习方法比以前的先进模型表现得更好。ELMo和ULMFiT在小语料库上的表现较好,但BERT表现更差,因为它被设计用于**MSM和NSP任务的训练。最后,域自适应总是提高ULMFiT**的性能。