前言
这篇依然没有涉及什么高深的原理,仅仅是上手练习的一些东西。
加载样本
import numpy as np
from scipy import sparse
from sklearn import datasets
#加载手写数字的数据集
digits_set = datasets.load_digits()
#创建特征矩阵
features_matrix = digits_set.data
#创建目标向量
target_vector = digits_set.target
#查看第一个样本
print(features_matrix[0])
print(features_matrix[0].size)
print(features_matrix)
print(features_matrix.shape[0])
print(features_matrix.shape[1])
[ 0. 0. 5. 13. 9. 1. 0. 0. 0. 0. 13. 15. 10. 15. 5. 0. 0. 3.
15. 2. 0. 11. 8. 0. 0. 4. 12. 0. 0. 8. 8. 0. 0. 5. 8. 0.
0. 9. 8. 0. 0. 4. 11. 0. 1. 12. 7. 0. 0. 2. 14. 5. 10. 12.
0. 0. 0. 0. 6. 13. 10. 0. 0. 0.]
64
[[ 0. 0. 5. ... 0. 0. 0.]
[ 0. 0. 0. ... 10. 0. 0.]
[ 0. 0. 0. ... 16. 9. 0.]
...
[ 0. 0. 1. ... 6. 0. 0.]
[ 0. 0. 2. ... 12. 0. 0.]
[ 0. 0. 10. ... 12. 1. 0.]]
1797
64
创建仿真数据
make_regression用作线性回归
from sklearn.datasets import make_regression
#特征就是变量x
#生成特征矩阵,目标向量,模型的系数
feature_matrix,target_vector,model_coefficent = make_regression(n_samples=30, #样本数
n_features=3, #特征数,也就是变量个数
n_informative=3, #参与建模的特征数
n_targets=1, #因变量个数
noise=0, #噪声
coef=True, #是否输出coef标志
random_state=1) #固定值表示每次调用参数一样的数据
#所有特征矩阵
print('Feature Matrix')
print(feature_matrix)
print('--------------------------------')
print(feature_matrix[:3])
#所有目标向量
print('Target Vector')
print(target_vector)
print('--------------------------------')
print(target_vector[:3])
#所有系数
print('Model Coefficient')
print(model_coefficent)
Feature Matrix
[[-1.10061918 0.58281521 0.04221375]
[ 2.10025514 0.19091548 -0.63699565]
[ 0.88514116 0.28558733 0.93110208]
[ 0.53035547 -0.26788808 -0.93576943]
[-0.50446586 -1.44411381 -1.39649634]
[-0.87785842 -0.17242821 -1.09989127]
[ 1.13376944 -0.38405435 -0.3224172 ]
[-0.07557171 0.48851815 -0.29809284]
[-0.34934272 -1.1425182 -0.35224985]
[-0.22232814 0.76201118 0.23009474]
[-0.12289023 -0.68372786 0.90085595]
[ 1.12948391 0.12182127 0.37756379]
[ 0.83898341 0.58662319 -0.20889423]
[ 0.50249434 0.90159072 1.14472371]
[ 1.65980218 0.2344157 -1.11731035]
[-0.67066229 0.11900865 0.19829972]
[ 2.18557541 1.51981682 1.13162939]
[ 0.30017032 0.61720311 0.12015895]
[ 0.82797464 -0.30620401 -2.02220122]
[-2.3015387 0.86540763 -1.07296862]
[ 0.41005165 0.18656139 -0.20075807]
[-0.0126646 -0.67124613 -0.84520564]
[-0.52817175 -0.61175641 1.62434536]
[ 0.31563495 0.87616892 0.16003707]
[ 0.05080775 1.6924546 -0.74715829]
[ 0.3190391 -0.7612069 1.74481176]
[ 0.51292982 1.25286816 -0.75439794]
[-2.06014071 1.46210794 -0.24937038]
[-0.88762896 -0.19183555 0.74204416]
[-0.6871727 -0.39675353 -0.69166075]]
--------------------------------
[[-1.10061918 0.58281521 0.04221375]
[ 2.10025514 0.19091548 -0.63699565]
[ 0.88514116 0.28558733 0.93110208]]
Target Vector
[ 37.74175696 6.94071851 86.5117958 -67.70279525 -205.06435022
-86.22405342 -36.08410374 23.71711098 -120.01461189 74.12311585
-9.29666977 45.15545942 48.26528776 145.43920532 -21.41853197
12.65550405 217.67124509 62.34037388 -127.29381592 -15.02503683
9.7024454 -103.40308389 31.72711817 86.54267457 101.8362499
36.32267081 70.15981245 83.7468125 13.84670287 -80.17725038]
--------------------------------
[37.74175696 6.94071851 86.5117958 ]
Model Coefficient
[12.41733151 84.20308924 55.28219787]
make_classification用作分类
from sklearn.datasets import make_classification
#生成特征矩阵和目标向量
feature_matrix,target_vector = make_classification(n_samples=30, #样本数
n_features=3, #特征数
n_informative=3, #参与建模的特征数
n_redundant=0, #冗余信息
n_classes=2, #类别
weights=[.25,.75], #权重
random_state=1) #固定值表示每次调用参数一样的数据
print('Feature Matrix')
print(feature_matrix)
print('Target Vector')
print(target_vector)
Feature Matrix
[[ 6.92519795e-01 1.13852523e+00 3.08812106e-01]
[ 3.88951614e-01 1.35195506e+00 8.45267453e-01]
[-1.61239191e+00 3.84863206e+00 -1.48104647e+00]
[-1.55155113e+00 -9.15242208e-01 1.87070202e+00]
[-1.37094493e+00 1.69611288e+00 -2.48345110e-01]
[ 3.35688592e-01 -1.48298550e+00 -1.33301281e+00]
[-1.68433513e+00 3.32953976e-01 -2.33101004e+00]
[ 1.69960192e+00 8.14466543e-01 -3.34700643e-01]
[-1.61123255e+00 1.25663465e+00 -1.88306830e+00]
[-2.41080203e+00 5.44220286e-01 -1.13809428e+00]
[-1.31576718e+00 -2.31329364e-01 -1.13715401e+00]
[ 2.44352863e-01 1.10054314e+00 -1.52949645e+00]
[-5.43585663e-01 -1.65153944e-01 -1.92898725e+00]
[ 6.03050835e-01 1.73597889e+00 3.01950504e-01]
[-1.49173629e-02 1.49493030e+00 -2.09226227e+00]
[ 5.02745823e-01 -1.10378957e+00 -1.92250524e+00]
[ 2.71333714e+00 1.29796309e+00 -5.74452615e-01]
[ 1.21648685e+00 1.13814022e+00 -1.15907489e+00]
[ 1.65879465e+00 3.09560595e+00 5.38155725e-01]
[ 2.05191840e+00 2.03163207e+00 -4.45435701e-01]
[-5.27732874e-01 2.35754111e+00 -7.01354054e-01]
[ 6.50085392e-03 -2.79111057e+00 1.11765731e+00]
[ 7.54879885e-01 1.44517982e+00 -1.06112098e+00]
[-1.37185725e+00 -1.25387234e+00 2.01388876e+00]
[ 1.60935053e+00 2.32646578e+00 -1.16622915e+00]
[ 5.75450411e-01 2.01897401e-03 -7.14120297e-01]
[-4.82268742e-01 2.99152002e+00 -1.56940995e+00]
[-1.76396658e+00 5.39206733e-02 -5.59453249e-01]
[-9.66653664e-01 2.45921914e+00 -8.49076661e-01]
[-1.10692641e+00 1.18622109e+00 -1.34893436e+00]]
Target Vector
[0 0 1 0 1 1 1 1 1 1 1 1 1 0 1 1 1 1 0 1 1 0 1 0 1 1 1 1 1 1]
make_blobs用作聚类
from sklearn.datasets import make_blobs
#生成特征矩阵和目标向量
feature_matrix,target_vector = make_blobs(n_samples=30, #样本数
n_features=3, #特征数
centers=3, #类别
cluster_std=0.5, #每个类的方差
shuffle=True, #洗乱数据
random_state=1) #固定值表示每次调用参数一样的数据
print('Feature Matrix')
print(feature_matrix)
print('Target Vector')
print(target_vector)
import matplotlib.pyplot as plt
#第一列第二列
plt.scatter(feature_matrix[:,0],feature_matrix[:,1],c = target_vector)
plt.show()
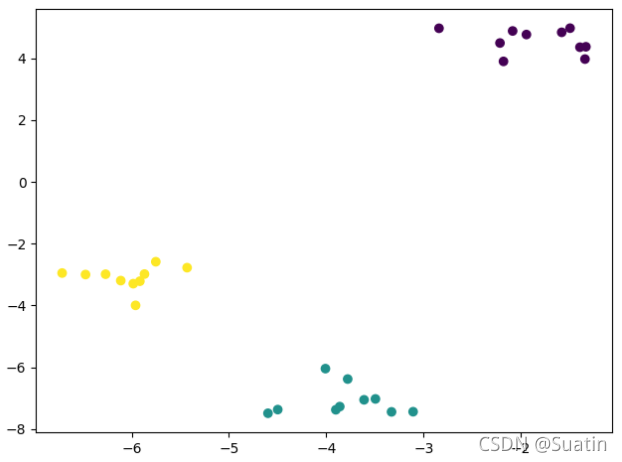
Feature Matrix
[[ -1.58030246 4.84319899 -10.05340419]
[ -2.08458609 4.88689987 -10.10642159]
[ -1.49416134 4.97746113 -10.56251008]
[ -1.33141787 4.37524407 -10.86703965]
[ -6.11226706 -3.19474192 -2.83801255]
[ -6.26823132 -2.98766593 -1.83717439]
[ -5.86852818 -2.98333444 -1.85376094]
[ -4.5991299 -7.48900414 -8.23652789]
[ -3.10743548 -7.43885905 -8.44362672]
[ -5.75219546 -2.58359772 -2.02923219]
[ -1.39265445 4.36050322 -9.04080231]
[ -3.86138326 -7.27293797 -7.52820308]
[ -3.77991888 -6.38136583 -7.81637007]
[ -5.91600086 -3.21413791 -2.09041548]
[ -4.00872553 -6.04386781 -7.92946776]
[ -2.17857929 3.90174996 -10.52684078]
[ -3.90176705 -7.37571561 -8.01536908]
[ -6.47442986 -2.99825175 -1.66090654]
[ -3.32919865 -7.44371925 -7.85908102]
[ -3.49475054 -7.02475689 -8.03910872]
[ -6.71503417 -2.94972104 -2.0997289 ]
[ -5.43054725 -2.77587972 -2.87033242]
[ -1.340879 3.97653657 -9.11140869]
[ -5.96000181 -3.99549724 -1.29092623]
[ -1.94281502 4.77147767 -9.81121561]
[ -4.49868599 -7.36987481 -8.00002191]
[ -2.84129421 4.97416254 -10.50621957]
[ -5.98383318 -3.29388922 -0.91621746]
[ -3.61165643 -7.0534392 -7.72461097]
[ -2.21474143 4.497097 -9.71554007]]
Target Vector
[0 0 0 0 2 2 2 1 1 2 0 1 1 2 1 0 1 2 1 1 2 2 0 2 0 1 0 2 1 0]
Process finished with exit code 0
从普通文件中加载数据
csv
import pandas as pd
dataset = pd.read_csv('test.csv')
#前8行数据
print(dataset.head(8))
5 2021-01-01 00:00:00 0
0 4 2021-01-01 00:00:01 1
1 3 2021-01-01 00:00:02 1
2 2 2021-01-01 00:00:03 0
3 1 2021-01-01 00:00:04 0
test.csv文件内容
5,2021-01-01 00:00:00,0
4,2021-01-01 00:00:01,1
3,2021-01-01 00:00:02,1
2,2021-01-01 00:00:03,0
1,2021-01-01 00:00:04,0
excel
import pandas as pd
dataframe = pd.read_excel('test.xls')
#前10行
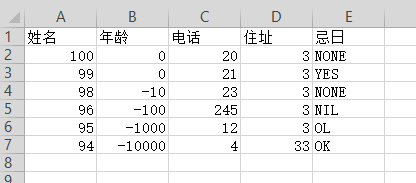
print(dataframe.head(10))
没对齐
姓名 年龄 电话 住址 忌日
0 100 0 20 3 NONE
1 99 0 21 3 YES
2 98 -10 23 3 NONE
3 96 -100 245 3 NIL
4 95 -1000 12 3 OL
5 94 -10000 4 33 OK
json
import pandas as pd
dataset = pd.read_json('_test.json')
print(dataset.head(10))
version configurations
0 0.2.0 {'type': 'chrome', 'request': 'launch', 'name'...
json格式化网站
http://www.kjson.com/
json文件
{
"version": "0.2.0",
"configurations": [
{
"type": "chrome",
"request": "launch",
"name": "Launch Chrome against localhost",
"url": "file:///C:/Users/LX/Desktop/Code/JSLearning/module.html",
"webRoot": "${workspaceRoot}"
}
]
}
sqlite
import pandas as pd
import sqlite3
#连接或创建数据库
connection = sqlite3.connect('my_database.db')
#获取光标
cursor = connection.cursor()
#创建表
cursor.execute('CREATE TABLE demllie('
'id varchar(20) primary key,'
'name varchar(20)'
') ')
#插入数据
for i in range(10):
cursor.execute('INSERT INTO demllie(id,name) values('
'%d,\'%d SUATIN DEMLLIE ZHANGQI %d \''
')'%(i,i,i))
#插入了多少行
print('row=',cursor.rowcount)
#查询表demllie
dataframe = pd.read_sql_query('SELECT * FROM demllie',connection)
#查看数据
print(dataframe.head(7))
#-------------
#关闭光标
cursor.close()
#关闭连接
connection.close()
row= 1
id name
0 0 0 SUATIN DEMLLIE ZHANGQI 0
1 1 1 SUATIN DEMLLIE ZHANGQI 1
2 2 2 SUATIN DEMLLIE ZHANGQI 2
3 3 3 SUATIN DEMLLIE ZHANGQI 3
4 4 4 SUATIN DEMLLIE ZHANGQI 4
5 5 5 SUATIN DEMLLIE ZHANGQI 5
6 6 6 SUATIN DEMLLIE ZHANGQI 6