���ʹ�û���ѧϰ�Զ���bug: ����ָ��
ͨ������ѧϰ�����Զ���bug? ���ںܶ�ͬѧ��˵��������һ�����õĻ��⡣
������������,���ǿ����Լ�����������,ÿ���˶���ѧ�ᡣ
�������˵�ѷdz���,˵��Ҳ�ܼ����ǰ���bug�Ĵ���Ƭ�Ϻ���֮��Ĵ���Ƭ���������ݼ�,ʹ�����ƻ�������ļ�������ѵ����Ȼ��������ѵ���õ�ģ��ȥԤ���´����������
���˼������ݼ����������ġ�An Empirical Study on Learning Bug-Fixing Patches in the Wild via Neural Machine Translation��
�����Զ�������Ŀ�ܼ�,һ������bug�Ĵ���,��һ������֮��Ĵ��롣
����Ҫ�������ǿ�ͼ:
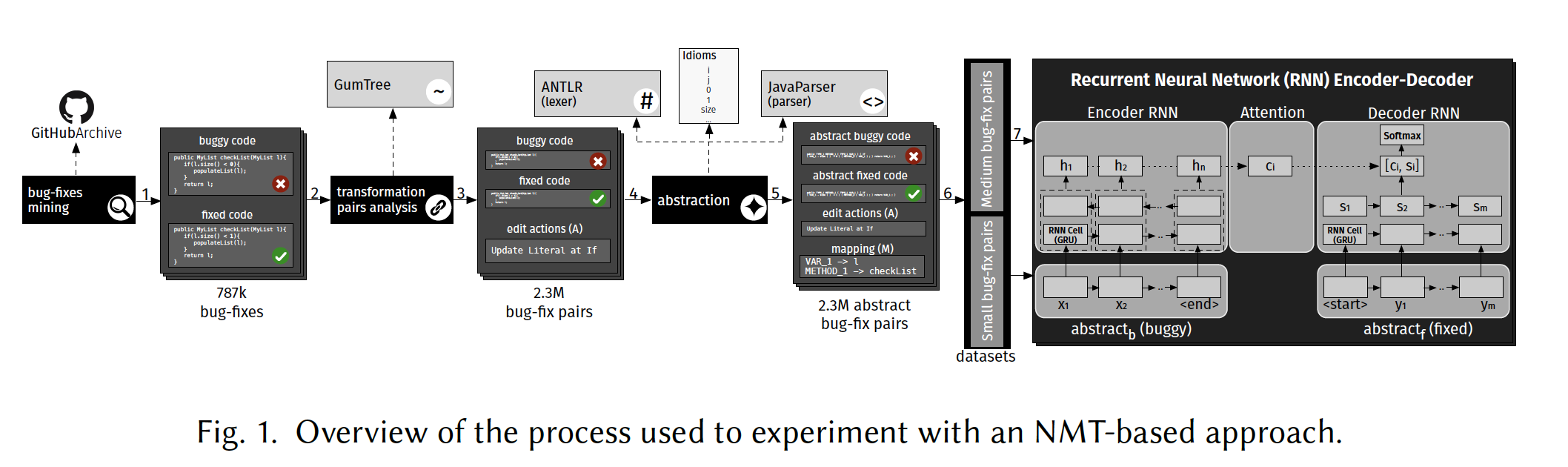
Ϊ�˸������Ӧ��������,���߶��ڴ�������˳���:

��������һ�����ݼ��е�����:
��bug�Ĵ�����������:
public java.lang.String METHOD_1 ( ) { return new TYPE_1 ( STRING_1 ) . format ( VAR_1 [ ( ( VAR_1 . length ) - 1 ) ] . getTime ( ) ) ; }
��֮���������ӵ�:
public java.lang.String METHOD_1 ( ) { return new TYPE_1 ( STRING_1 ) . format ( VAR_1 [ ( ( type ) - 1 ) ] . getTime ( ) ) ; }
�ְ��ֽ�����CodeBERT�Զ���bug
��Ϊ�������̷�����˹�����AI4SE����,��һֱ�DZ������ȵġ�����������ְ���ѧϰ�����ʹ������CodeBERTģ�����Զ���bug.
��һ��:��װtransformers���,��ΪCodeBERT �ǻ��������ܵ�:
pip install transformers --user
�ڶ���:��װPyTorch����Tensorflow��ΪTransformers�ĺ��,�����ܸ㶨�Ļ�,���ԾͰ�װ���µİ�:
pip install torch torchvision torchtext torchaudio --user
������,�����������ݼ�
git clone https://github.com/microsoft/CodeXGLUE
���ݼ��Ѿ������ص�CodeXGLUE/Code-Code/code-refinement/data/ ����,��Ϊsmall��medium�������ݼ���
��������small���ݼ�������:
cd code
export pretrained_model=microsoft/codebert-base
export output_dir=./output
python run.py \
--do_train \
--do_eval \
--model_type roberta \
--model_name_or_path $pretrained_model \
--config_name roberta-base \
--tokenizer_name roberta-base \
--train_filename ../data/small/train.buggy-fixed.buggy,../data/small/train.buggy-fixed.fixed \
--dev_filename ../data/small/valid.buggy-fixed.buggy,../data/small/valid.buggy-fixed.fixed \
--output_dir $output_dir \
--max_source_length 256 \
--max_target_length 256 \
--beam_size 5 \
--train_batch_size 16 \
--eval_batch_size 16 \
--learning_rate 5e-5 \
--train_steps 100000 \
--eval_steps 5000
ȡ������Ļ���������,����һ̨NVIDIA 3090GPU��Լѵ��һ����ʱ���ѵ�����ˡ�Ч����õ�ģ�ͱ��洢��output_dir/checkpoint-best-bleu/pytorch_model.bin�С�
Ȼ�����ǾͿ���ʹ�ò��Լ����������ǵ�ѵ���ɹ�:
python run.py \
--do_test \
--model_type roberta \
--model_name_or_path roberta-base \
--config_name roberta-base \
--tokenizer_name roberta-base \
--load_model_path $output_dir/checkpoint-best-bleu/pytorch_model.bin \
--dev_filename ../data/small/valid.buggy-fixed.buggy,../data/small/valid.buggy-fixed.fixed \
--test_filename ../data/small/test.buggy-fixed.buggy,../data/small/test.buggy-fixed.fixed \
--output_dir $output_dir \
--max_source_length 256 \
--max_target_length 256 \
--beam_size 5 \
--eval_batch_size 16
���ҵĻ�����,������Сʱ����������,�����������:
10/26/2021 11:51:57 - INFO - __main__ - Test file: ../data/small/test.buggy-fixed.buggy,../data/small/test.buggy-fixed.fixed
100%|��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������| 365/365 [30:40<00:00, 5.04s/it]
10/26/2021 12:22:39 - INFO - __main__ - bleu-4 = 79.26
10/26/2021 12:22:39 - INFO - __main__ - xMatch = 16.3325
10/26/2021 12:22:39 - INFO - __main__ - ********************
��������������ɵĴ��������ò�����?���ǿ���ͨ���Ƚ��������ɵ�output/test_1.output��output/test_1.gold���бȽ�,����ʹ�������evaluator.py�ű�:
python evaluator/evaluator.py -ref ./code/output/test_1.gold -pre ./code/output/test_1.output
����������:
BLEU: 79.26 ; Acc: 16.33
ǰ��������NLP����������BLEUָ��,������ȷ�ʡ�
���ָ��ˮƽ�����?���ǿ��Ը����߶Ա���:
| Method | BLEU | Acc (100%) | CodeBLEU |
|---|---|---|---|
| Naive copy | 78.06 | 0.0 | - |
| LSTM | 76.76 | 10.0 | - |
| Transformer | 77.21 | 14.7 | 73.31 |
| CodeBERT | 77.42 | 16.4 | 75.58 |
ȷ����Ȼ����������,����CodeBERT�Ѿ���ԭ����ʹ�õ�RNN����������60%�ˡ�
����ͨ��diff��ֱ�۸��������ɵĺ�ԭʼ��֮��IJ��:

�������ݵ�����,����û�з�һ����ϸ��,�Ϳ����Զ���������bug,���ֱ���ǡ�˯�����롱����
�Զ�����bug
��������Զ����bug���������ʵ�û�Զ,���ǿ�����ֻ����bug��
�ɱ�С���Զ�����bug��������������,�������������Ժ�ȷ�ʶ��нϴ�������
�Ƿ���bug�����ݼ��ر��,ֻҪ��һ���ֶ�����־�Dz�����bug�Ϳ����ˡ�
���ݼ���ʽ����,��jsonl�ĸ�ʽ�洢:
{"project": "qemu", "commit_id": "aa1530dec499f7525d2ccaa0e3a876dc8089ed1e", "target": 1, "func": "static void filter_mirror_setup(NetFilterState *nf, Error **errp)\n{\n MirrorState *s = FILTER_MIRROR(nf);\n Chardev *chr;\n chr = qemu_chr_find(s->outdev);\n if (chr == NULL) {\n error_set(errp, ERROR_CLASS_DEVICE_NOT_FOUND,\n \"Device '%s' not found\", s->outdev);\n qemu_chr_fe_init(&s->chr_out, chr, errp);", "idx": 8}
{"project": "qemu", "commit_id": "21ce148c7ec71ee32834061355a5ecfd1a11f90f", "target": 1, "func": "static inline int64_t sub64(const int64_t a, const int64_t b)\n\n{\n\n\treturn a - b;\n\n}\n", "idx": 10}
����Ҫдʲô����,����ֱ��ѵ��:
python run.py \
--output_dir=./saved_models \
--model_type=roberta \
--tokenizer_name=microsoft/codebert-base \
--model_name_or_path=microsoft/codebert-base \
--do_train \
--train_data_file=../dataset/train.jsonl \
--eval_data_file=../dataset/valid.jsonl \
--test_data_file=../dataset/test.jsonl \
--epoch 5 \
--block_size 200 \
--train_batch_size 32 \
--eval_batch_size 64 \
--learning_rate 2e-5 \
--max_grad_norm 1.0 \
--evaluate_during_training \
--seed 123456
���ʱ����Զ�����Ҫ�̵Ķ�,20����ȫ�㶨��
Ȼ�������²��Լ�:
python run.py \
--output_dir=./saved_models \
--model_type=roberta \
--tokenizer_name=microsoft/codebert-base \
--model_name_or_path=microsoft/codebert-base \
--do_eval \
--do_test \
--train_data_file=../dataset/train.jsonl \
--eval_data_file=../dataset/valid.jsonl \
--test_data_file=../dataset/test.jsonl \
--epoch 5 \
--block_size 200 \
--train_batch_size 32 \
--eval_batch_size 64 \
--learning_rate 2e-5 \
--max_grad_norm 1.0 \
--evaluate_during_training \
--seed 123456
����һ��ȷ��:
python ../evaluator/evaluator.py -a ../dataset/test.jsonl -p saved_models/predictions.txt
��������:
{'Acc': 0.6288433382137628}
���Ǹ�ҵ�����������Ա���:
| Methods | ACC |
|---|---|
| BiLSTM | 59.37 |
| TextCNN | 60.69 |
| RoBERTa | 61.05 |
| CodeBERT | 62.08 |
ȷ�ʶ������˹���
�����������ĺô�,��Ȼ������ǰ�潲�ġ�˯�����롱��ֻҪ���۸������Ч����,����ʶ���������������,�����л����ϲ���Ҫ��ά����������