全文翻译(全文合集):TVM: An Automated End-to-End Optimizing Compiler for Deep Learning
摘要
人们越来越需要将机器学习应用到各种各样的硬件设备中。现在的框架依赖于特定于供应商的算子库,针对窄带的服务器级GPU进行优化。将工作负荷部署到新平台,如移动电话,嵌入式设备和加速算子(如FPGA,ASIC)-需要大量手动操作。
提出了TVM,一个开源图形级别的编译器和算子级优化,提供高效跨多个应用程序移植到深度学习工作负荷硬件后端。TVM解决了深度学习特有的优化难题,如高级算子融合,映射到任意硬件原语,内存延迟隐藏。
通过以下方式自动优化底层程序,适配硬件特性:
采用一种自定义的,基于学习的成本模型方法,用于快速探索代码优化。实验结果表明,TVM可在不同的领域,提供高性能硬件后端,可与最先进的低功耗CPU,mobile GPU,server-class GPUs的手动调优库抗衡。展示了TVM面向加速算子后端的能力,如作为基于FPGA的通用深度学习加速算子。TVM系统是开源的,在几家大公司提供量产服务。
1.引言
深度学习(DL)模型,可以识别图像,处理自然语言,在挑战性战略游戏中击败人类。智能应用部署的需求日益增长,从云服务器,自动驾驶汽车和嵌入式设备,广泛应用于各种设备。由于硬件特性的多样性,包括嵌入式CPU,GPU,FPGA和ASIC(如TPU),将DL工作负荷,映射到这些设备非常重要。这些硬件目标包括内存组织,计算功能单元,如图1所示。

Figure 1: CPU, GPU and TPU-like accelerators require different on-chip memory architectures and compute primitives. This divergence must be addressed when generating optimized code.
当前的DL框架,如TensorFlow,MXNet,Caffe和Pytorch,依靠计算图实现优化,如自动微分和动态内存管理。图形级优化,通常太深奥,无法处理硬件后端特定的算子级转换。大部分框架专注于一个狭窄的服务器类GPU设备,特定于目标的优化高度工程化和特定于供应商的算子libraries。这些算子库,过于专业化和不透明,不易于跨硬件设备进行移植,需要大量的手动调谐数据。提供在各种DL框架中,支持各种硬件后端,目前需要大量的工程效率。即使对于受支持的后端,框架也必须在以下两者间,做出艰难的选择:
(1) 避免产生预定义运算子库中,没有的新运算符算子的图形优化
(2)使用这些新算子的未优化实现。
不同的硬件后端,实现图形级和算子级优化,采用了一种有趣的,完全不同的端到端方法。构建TVM,一种采用高级规范的编译器,从现有框架支持不同的代码生成,低级优化代码硬件后端。为了吸引用户,TVM需要提供与跨di-verse硬件后端的多种手动优化算子库相竞争的性能。这一目标需要解决下文介绍的主要挑战。
利用特定的硬件功能和限制。
DL加速算子引入了优化的张量计算原语,GPU和CPU不断改进处理元素。一个重大的挑战,客户生成优化的代码给定的算子描述。硬件指令的输入是多维的,可以是固定的,也可以是可变的长度;规定了不同的数据布局;有内存层次结构的特殊要求。系统必须利用加速算子,有效地处理这些复杂的原语。加速算子的设计也是如此,通常倾向于更精简的控制和load更多编译器堆栈复杂调度。对于专门化的加速算子,系统需要生成显式控制管道,针对CPU和GPU的硬件,优化隐藏内存访问延迟关系的代码。
优化的大搜索空间另一个挑战,在不手动调整算子的情况下,生成高效代码。内存访问,线程模式和新型硬件原语的组合选择,为生成的代码创建巨大的配置空间(例如,循环布局和排序,缓存,展开)。如果实施blackbox黑盒自动调谐,将产生巨大的搜索成本。可以采用预先确定的成本模型,指导搜索,由于模型的复杂性越来越高,构建准确成本模型,很难建立模型现代硬件。此外,要求为每种硬件类型,建立单独的成本模型。
TVM通过三个关键模块解决了这些挑战。
(1)引入一种张量表达式语言。
构建算子提供程序转换,通过各种优化生成不同版本的program原语。这一层开展Halid的计算/调度分离概念,将目标硬件本质与转换原语分离,支持新型加速算子及相应的新intrinsics。此外,引入了新的转换原语,应对与GPU相关的挑战,使部署能够特定于加速算子。可以应用不同的程序转换序列,为给定的算子声明,形成丰富的有效程序空间。
(2) 引入了一个自动程序优化框架,用于寻找优化的张量算子。
优化算子是在基于ML的成本模型的指导下,从硬件后端收集更多数据,该模型会不断调整和改进。
(3)在自动代码生成上,引入一个充分利用高级和算子级优化。
通过结合这三个模块,TVM可以将现有深度学习框架的模型描述,工作,执行高级和低级优化,为后端(如CPU,GPU和基于FPGA的专用处理器)生成特定于硬件的优化代码加速算子。
本文主要贡献:
?确定了在不同硬件后端为深度学习工作负荷,提供性能可移植性方面的主要优化挑战。
?引入了自定义的调度原语,充分利用了跨线程内存重用,创新的硬件本质和延迟隐藏。
?提出实施基于机器学习的自动探索和优化系统搜索的张量算子。
?构建了一个端到端的编译和优化堆栈,在高级框架(包括TensorFlow,MXNet,PyTorch,Keras,CNTK)中,多种硬件后端(包括CPU,服务器GPU,移动GPU和基于FPGA的加速算子)特定的工作负荷,部署深度学习。
开源TVM在几家大公司内部量产使用。在服务器级GPU,嵌入式GPU,嵌入式CPU和一个定制的基于FPGA的通用加速器上,使用真实的工作负荷,对TVM进行了评估。
实验结果表明,TVM具有便携性跨后端的性能实现加速,在现有框架的基础上,由手工优化的库支持,从1.2×到3.8×不等。
2.概述
通过使用示例,介绍TVM的组件。

Figure 2: System overview of TVM. The current stack supports descriptions from many deep learning frameworks and exchange formats, such as CoreML and ONNX, to target major CPU, GPU and specialized accelerators.
图2总结了TVM中的执行步骤及相应部分。该系统首先将现有框架中的模型作为输入,转换为计算图形表示。然后执行高级数据流重写,生成优化的图。操作员级优化模块必须生成efficient代码-此图中每个融合运算符的。运算符是用声明性张量表达式语言指定的;未指定执行细节。TVM为给定的目标识别一组可能的代码优化
硬件目标的算子。可能的优化形成了一个很大的空间,使用基于ML的成本模型,寻找优化的算子。最后,系统将生成的代码,打包到可部署模块中。
最终用户示例。在以下几行代码中,用户可以从现有的深度学习框架中获取模型,调用TVM API获得可部署模块:
import tvm as t
Use keras framework as example, import model
graph, params = t.frontend.from_keras(keras_model)
target = t.target.cuda()
graph, lib, params = t.compiler.build(graph, target, params)
这个编译后的运行时模块,包含三个组件:
最终优化的计算图(graph)、生成的算子(lib)和模块参数(params)。可以使用这些组件,将模型部署到目标后端:
import tvm.runtime as t
module = runtime.create(graph, lib, t.cuda(0))
module.set_input(**params)
module.run(data=data_array)
output = tvm.nd.empty(out_shape, ctx=t.cuda(0))
module.get_output(0, output)
TVM支持局域网中的多个部署后端,如C++、java和Python。本文的其余部分描述了TVM的体系结构,及系统程序员如何扩展,支持新的后端。
3.优化计算图
计算图是在DL框架中表示程序的常用方法。图3显示了两层卷积神经网络的计算图表示示例。这种高级表示与低级编译器中间表示(IR,如LLVM)间的主要区别,中间数据项是大型多维张量。计算图提供了算子的全局视图,但避免指定每个算子必须如何实现。与LLVM IRs一样,计算图可以转换为功能等效图优化。利用常见DL工作负载中的形状特异性,优化一组固定的输入shape。
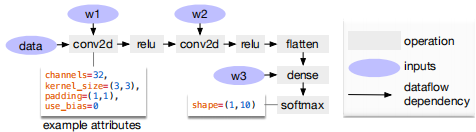
Figure 3: Example computational graph of a two-layer convolutional neural network. Each node in the graph represents an operation that consumes one or more tensors and produces one or more tensors. Tensor operations can be parameterized by attributes to confifigure their behavior (e.g., padding or strides).
TVM利用计算图表示应用高级优化:节点表示对张量或程序输入的算子,边表示算子间的数据依赖关系。实现多级图形优化,包括:算子fusion,将多个小算子融合在一起;常量折叠,预先计算可静态确定的图形部分,节省执行成本;静态内存调度过程,预先分配内存,保存每个中间张量;数据布局转换,将内部数据布局转换为后端友好的形式。
现在讨论算子融合和数据布局转换。
算子融合
算子融合将多个算子组合到单个内核中,无需将中间结果保存在内存中。这种优化可以大大减少执行时间,特别是在GPU和专用加速器中。具体来说,认识到四类图算子:
(1)内射(一对一映射,如add)
(2)归约(如sum)
(3)复杂输出可融合(将元素映射融合到输出,如conv2d)
(4)不透明(不能融合,如sort)。
提供了融合这些算子的通用规则,如下所示。
多个内射算子可以融合成另一个内射算子。归约算子可以与输入内射算子融合(例如,融合scale和sum)。如conv2d类的算子是复杂的可外fusion的,可以将元素算子fusion到输出中。可以应用这些规则,将计算图转换为融合版本。
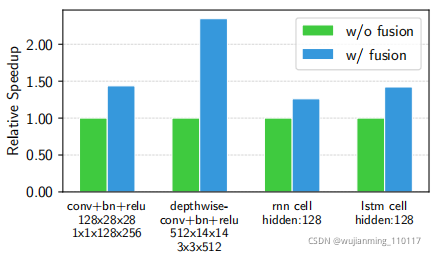
Figure 4: Performance comparison between fused and non-fused operations. TVM generates both operations. Tested on NVIDIA Titan X.
图4演示了对不同工作负载的影响的优化。通过减少内存访问,融合算子可以产生高达1.2倍到2倍的加速比。
数据布局转换。在计算图中存储给定张量有多种方法。最常见的数据布局选择是列主视图和行主视图。实际上,可能喜欢使用复杂的数据布局。例如,DL accelerator可能利用4×4矩阵运算,需要将数据平铺到4×4块中,优化局部访问。

Figure 5: Example schedule transformations that optimize a matrix multiplication on a specialized accelerator.
数据布局优化,可以使用更好的内部数据布局,转换计算图形,在目标硬件上执行图形。先指定每个算子的首选数据布局,给定内存层次结构指定的约束。然后,如果生产者和消费者的首选数据布局不匹配,将在两者间执行适当的布局转换。
虽然高级图优化可以极大地提高DL工作负载的效率,但效率仅与operator library提供的一样高。目前,支持算子融合的少数DL框架,要求算子库提供融合模式的实现。随着更多的网络算子定期推出,可能的融合内核数量可能会大幅增加。当针对越来越多的硬件后端时,这种方法不再具有可持续性,因为所需的融合模式实现数量,随着必须支持的数据布局,数据类型和加速器内部结构的数量,组合增长。接下来提出一种代码生成方法,可以为给定模型的算子生成各种可能的实现。
4.生成张量运算
TVM通过在每个硬件后端,生成许多有效的实现,选择优化的实现,为每个算子生成高效的代码。
该过程基于Halide,将描述与计算规则(或调度优化)分离,将支持新的优化(嵌套并行,张量化和延迟隐藏)和大量硬件后端。重点介绍TVM的特定功能。
4.1 张量表达式和表空间

Figure 6: TVM schedule lowering and code generation process. The table lists existing Halide and novel TVM scheduling primitives being used to optimize schedules for CPUs, GPUs and accelerator back-ends. Tensorization is essential for accelerators, but it can also be used for CPUs and GPUs. Special memory-scope enables memory reuse in GPUs and explicit management of onchip memory in accelerators. Latency hiding is specifific to TPU-like accelerators.
引入了一种支持自动代码生成的张量表达式语言。与高级计算图表示不同,张量算子的实现是不透明的,每个算子都用索引公式表达式语言描述。以下代码显示了用于计算转置矩阵乘法的张量表达式示例:
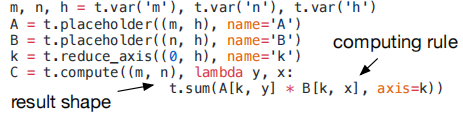
如何计算每个元素的表达式,每个计算算子都指定输出张量的形状和描述。张量表达式语言支持常见的算术和数学运算,涵盖常见的DL算子模式。该语言没有指定循环结构和许多其它执行细节,为各种后端添加硬件感知优化。采用Halide的解耦计算/调度原理,从张量表达式到低级代码的特定映射,使用调度表示。
许多可能的调度,都可以执行此功能。
通过增量应用基本转换(调度原语)构建调度,持程序的逻辑等价性。图5显示了在专用加速器上,调度矩阵乘法的示例。在内部,TVM使用一个数据结构,跟踪循环结构和其它信息,因为应用了调度转换。然后,这些信息可以为给定的最终调度生成低级代码。
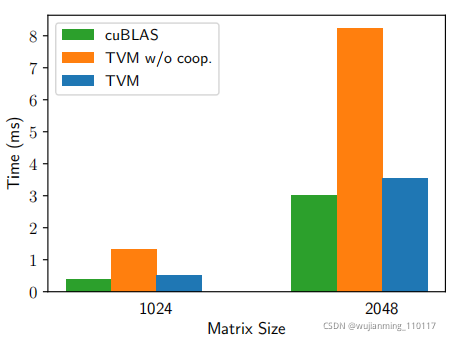
Figure 7: Performance comparison between TVM with and without cooperative shared memory fetching on matrix multiplication workloads. Tested on an NVIDIA Titan X.
张量表达式从Halide,Darkroom,TACO中获取线索。主要增强功能,包括支持下面讨论的新调度优化。为了在许多后端上实现高性能,必须支持足够多的调度原语,覆盖不同硬件后端上的各种优化。图6总结了TVM支持的算子代码生成过程和调度原语。重用有用的原语和来自Halide的低级循环程序AST,引入新的原语,优化GPU和加速器性能。新原语是实现最佳GPU性能所必需的,也是加速器所必需的。CPU、GPU、TPU类加速器是深度学习的三种重要硬件类型。
本节介绍了CPU、GPU和TPU类加速器的新优化原语,第5节说明了如何自动导出有效的调度。
4.2嵌套并行与协作
并行性是提高DL工作负载中,计算密集型内核效率的关键。现代GPU提供了巨大的并行性,要求将所有并行模式bake到调度转换中。大多数现有的解决方案,都采用了一种称为嵌套并行(一种fork-join形式)的模型。该模型需要一个并行schedule原语,并行化数据并行任务;每个任务可以进一步递归细分为子任务,利用目标体系结构的多级线程层次结构(例如,GPU中的线程组)。称此模型为无共享嵌套并行,因为一个工作线程,无法在同一并行计算阶段,查看同级的数据。
无共享方法的另一种替代方法是协同获取数据。具体来说,线程组可以协作获取所有需要的数据,放入共享内存空间。此优化可以利用GPU内存层次结构,通过共享内存区域跨线程重用数据。TVM支持这种众所周知的GPU优化,使用调度原语实现最佳性能。下面的GPU代码示例优化了矩阵乘法。

图7展示了这种优化的影响。将内存作用域的概念引入调度空间,以便将计算阶段(代码中的AS和BS)标记为共享。没有显式存储范围,自动范围推断,将计算阶段标记为线程本地。共享任务必须计算组中,所有工作线程的依赖关系。
必须正确插入内存同步屏障,确保共享加载的数据对用户可见。最后,除了对GPU有用之外,内存作用域标记特殊的内存缓冲区,在针对专用DL加速器时,创建特殊的降低规则。
4.3 张量化
DL工作负载具有很高的运算强度,通常可以分解为张量算子,如矩阵乘法或一维卷积。这些自然分解导致了最近的添加张量计算原语。这些新原语为基于调度的编译,带来了机遇和挑战;虽然这些使用可以提高性能,但编译框架必须无缝集成。称为张量化:类似于SIMD体系结构的矢量化,但有显著差异。指令输入是多维的,具有固定或可变的长度,每个都有不同的数据布局。无法支持一组固定的原语,因为新的加速器用自定义的张量指令变体出现。
需要一个可扩展的解决方案。
通过使用张量内在声明机制,将目标硬件结构从调度中分离出来,使张量化具有可扩展性。使用相同的张量表达式语言,声明每个新硬件内在的行为,以及与之相关的降低规则。下面的代码显示了如何定义8×8张量硬件的内在特性。

引入了一个tensorize调度原则,用相应的内部函数替换计算单元。编译器使用硬件声明匹配计算模式,降低到相应的硬件本身。
Tensorization将调度与特定的硬件原语分离,易于扩展TVM支持新的硬件体系结构。Tensorization调度生成的代码,符合高性能计算的实践:将复杂算子分解为一系列微内核调用。可以使用tensorize原语,进行手工制作的微内核的优点,这在某些平台形式中可能是有益的。例如,为移动CPU实现超低精度算子,这些CPU通过利用位串行数据算子1或2位宽的数据类型矩阵向量乘法微内核。该微内核将结果累加为越来越大的数据类型,以最小化内存占用。将微内核作为TVM固有的张量表示,可产生高达1.5倍于非张量化的加速比。
4.4显式内存延迟隐藏
延迟隐藏将内存算子与计算重叠的过程,最大限度地利用内存和计算资源。根据目标硬件后端的不同,需要不同的策略。
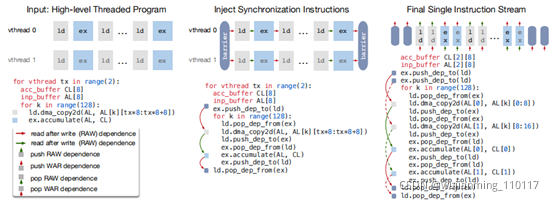
Figure 8: TVM virtual thread lowering transforms a virtual thread-parallel program to a single instruction stream; the stream contains explicit low-level synchronizations that the hardware can interpret to recover the pipeline parallelism required to hide memory access latency.
在CPU上,内存延迟隐藏通过同步多线程或硬件预取隐式实现的。GPU依赖于许多线程的快速上下文切换。相反,像TPU这样的专用DL加速器,通常支持使用解耦访问执行(DAE)的精简控制架构和卸载细粒度的问题与软件同步。
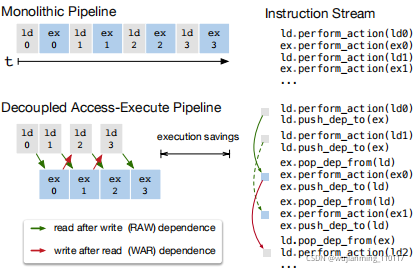
Figure 9: Decoupled Access-Execute in hardware hides most memory access latency by allowing memory and computation to overlap. Execution correctness is enforced by low-level synchronization in the form of dependence token enqueueing/dequeuing actions, which the compiler stack must insert in the instruction stream.
图9显示了一个减少运行时延迟的DAE硬件管道。与单片硬件设计相比,该管道可以将大部分内存访问隐藏在头上,几乎充分利用计算资源。要为了获得更高的利用率,必须使用细粒度同步算子,扩充指令流。如果没有这些算子,依赖关系将无法强制执行,导致错误的执行。因此,DAE硬件管道,需要细粒度依赖排队,在管道阶段间均衡操作,保证正确执行,如图9的指令流所示。
编程需要显式低级同步的DAE加速器很困难。为了减轻编程负担,引入了虚拟线程调度原语,让程序员指定一个高级数据并行程序,就像指定一个支持多线程的硬件后端一样。TVM会自动降低program,转换为具有低级显式同步的单个指令流,如图8所示。该算法从高级多线程程序调度开始,插入必要的低级同步算子,确保在每个线程内正确执行。接下来,将所有虚拟线程的算子交错到single的指令流。
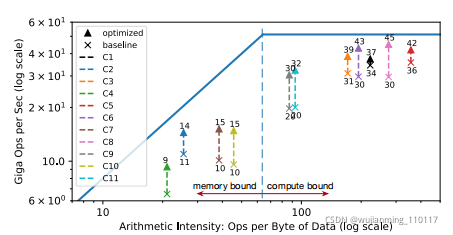
Figure 10: Rooflfline of an FPGA-based DL accelerator running ResNet inference. With latency hiding enabled by TVM, performance of the benchmarks is brought closer to the rooflfline, demonstrating higher compute and memory bandwidth effificiency.
5. 自动化优化
考虑到一组丰富的调度原语,剩下的问题是为DL模型的每一层,找到最佳的算子实现。在这里,TVM为与每个层关联的特定输入shape和布局,创建一个专门的算子。这种专门化提供了显著的性能优势(与针对较小shape和布局多样性的手工代码相比),但也带来了自动化挑战。系统需要选择调度优化,如修改循环排序或优化内存层次结构,以及调度特定参数,如平铺大小和循环展开系数。
这样的组合选择为每个硬件后端的算子实现,构建了一个巨大的搜索空间。为了应对这一挑战,构建了一个自动化的进度优化器,有两个主要组件:一个是提出有前途的新配置的调度管理器,另一个是预测给定配置性能的机器学习成本模型。本节描述了这些组件和TVM的自动优化流程(图11)。
5.1调度空间规格
构建了一个调度模板规范API,让开发人员在调度空间中声明knobs。模板规范允许在指定可能的调度时,根据需要结合开发人员的领域特定知识。还为每个硬件后端,创建了一个通用主模板,该模板根据使用张量表达式语言表示的计算描述,自动提取可能的knobs。在高层次上,希望考虑尽可能多的配置,让优化器管理选择负载。因此,优化器必须搜索数十亿种可能的配置,查找实验中使用的真实世界DL工作负载。
5.2 基于ML的成本模型
从大型配置空间中,通过黑盒优化,即自动调整,找到最佳调度的一种方法。此方法用于调整高性能计算库。然而,自动调整需要许多实验,确定良好的配置。
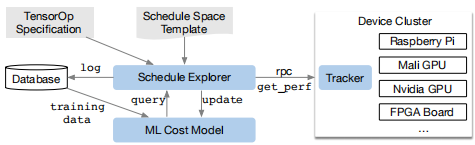
Figure 11: Overview of automated optimization framework. A schedule explorer examines the schedule space using an ML-based cost model and chooses experiments to run on a distributed device cluster via RPC. To improve its predictive power, the ML model is updated periodically using collected data recorded in a database.
另一种方法是建立一个预定义的成本模型,指导对特定硬件后端的搜索,不是运行所有的可能性,测量性能。理想情况下,一个完美的成本模型,会考虑影响性能的所有因素:内存访问模式,数据重用,管道依赖性和线程连接模式等。不幸的是,由于现代硬件越来越复杂,这种方法很麻烦。此外,每个新的硬件目标,都需要一个新的(预定义的)成本模型。
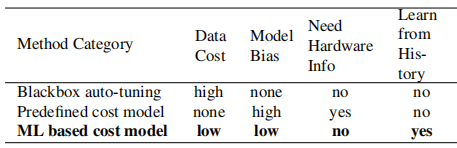
Table 1: Comparison of automation methods. Model bias refers to inaccuracy due to modeling.
相反,采用统计方法,解决成本建模问题。在这种方法中,调度资源管理器提出的配置,可能会提高算子的性能。对于每个调度配置,使用一个ML模型,该模型将降低的循环程序作为输入,预测在给定硬件后端上的运行时间。该模型使用搜索期间收集的运行时,测量数据进行训练,不需要用户输入详细的硬件信息。在优化过程中,随着探索更多配置,会定期更新模型,提高准确性。
对于其它相关的工作负载也是如此。通过这种方式,ML模型的质量随着更多的实验提高。表1总结了自动化方法之间的主要差异。基于ML的成本模型,在自动调整和预定义的成本建模间,取得了平衡,可以从相关工作负载的历史性能数据中获益。
机器学习模型设计选择。必须考虑两个关键因素,选择调度管理器,将使用的ML模型:质量和速度。
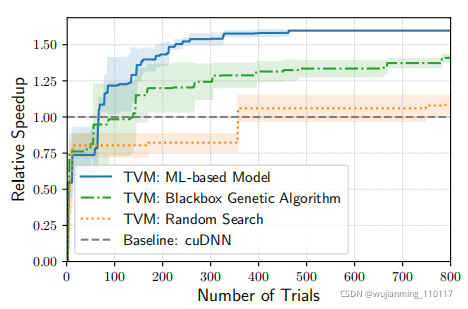
Figure 12: Comparison of different automation methods for a conv2d operator in ResNet-18 on TITAN X. The ML-based model starts with no training data and uses
the collected data to improve itself. The Y-axis is the speedup relative to cuDNN. We observe a similar trend for other workloads.
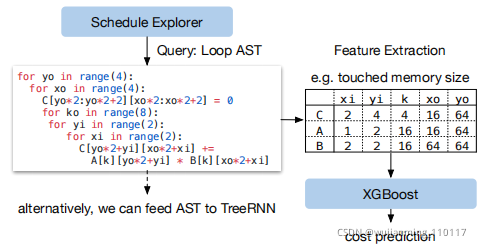
Figure 13: Example workflflow of ML cost models. XGBoost predicts costs based on loop program features. TreeRNN directly summarizes the AST.
schedule explorer经常查询成本模型,由于模型预测时间和模型重新安装时间产生开销。为了发挥作用,这些开销必须小于在实际硬件上,测量性能所需的时间,根据具体的工作负载/硬件目标,实际硬件上的性能可以达到秒级。这种速度要求将问题与传统的超参数调优问题区分,在超参数调优问题中,执行测量的成本,相对于模型开销非常高,可以使用更昂贵的模型。除了选择模型外,需要选择一个目标函数训练模型,如配置的预测运行时间中的误差。
由于资源管理器,仅根据预测的相对顺序(A的运行速度比B快),选择排名靠前的候选对象,因此不需要直接预测绝对执行时间。相反,使用排名目标,预测运行时成本的相对顺序。
在ML Optimizer中实现了几种类型的模型。采用了一个梯度树推进模型(基于XGBoost),该模型根据从循环程序中提取的特征进行预测;这些特性包括每个循环级别上,每个内存缓冲区的内存访问计数和重用率,以及循环注释的一次热编码,如“矢量化”,“展开”和“并行”。评估了一个神经网络模型,该模型使用TreeRNN,在无需特性工程的情况下,评测循环程序的AST。图13总结了成本模型的工作流程。发现treeboosting和TreeRNN具有相似的预测质量。然而,前者的预测速度是后者的两倍,训练时间也少得多。因此,在实验中选择了梯度树推进作为默认的成本模型。尽管如此,相信这两种方法都是有价值的,期望今后对这个问题进行更多的研究。
平均而言,树推进模型的预测时间为0.67毫秒,比实际测量快数千倍。图12比较了基于ML的优化器和blackbox自动调优方法;前者发现更好的配置比后者快得多。
5.3进度计划
一旦选择了一个成本模型,就可以选择有希望的配置,在这些配置上迭代地运行真正的度量。在每次迭代中,浏览器使用ML模型的预测,选择一批候选对象,在这些候选对象上运行度量。然后将收集的数据,用作更新模型的训练数据。如果不存在初始训练数据,资源管理器会随机挑选候选对象进行测量。
最简单的探索算法,通过成本模型枚举,运行每个配置,选择前k名预测执行者。然而,这种策略在较大的搜索空间中,变得难以处理。
相反,运行了一个并行模拟退火算法。资源管理器从随机配置开始,在每一步中,都会随机转到附近的配置。如果成本模型预测的成本降低,转换是成功的。如果目标配置成本较高,可能会失败(拒绝)。随机游动倾向于收敛于具有较低速度的配置成本模型预测的成本。搜索状态在成本模型更新期间持续存在;从这些更新之后的最后一个配置继续。
5.4分布式设备池和RPC
分布式设备池可扩展硬件测试的运行,在多个优化作业之间,实现细粒度资源共享。TVM实现了一个定制的,基于RPC的分布式设备池,使客户端能够在特定类型的设备上运行程序。可以使用此接口,在主机编译器上编译程序,请求远程设备,远程运行函数,在主机上访问相同脚本中的结果。TVM的RPC支持动态上载,使用运行时约定运行交叉编译的模块和函数。因此,相同的基础结构,可以执行单个工作负载优化和端到端图Inference。这种方法自动化了跨多个设备的编译,运行和配置步骤。
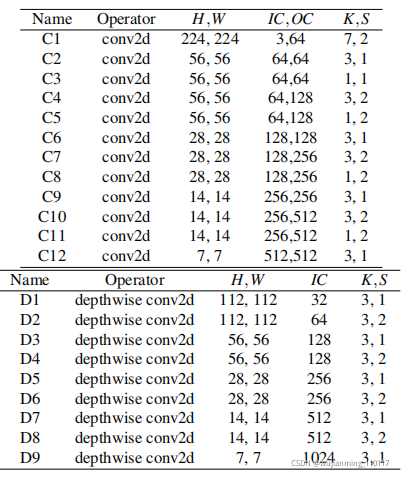
Table 2: Confifigurations of all conv2d operators in ResNet-18 and all depthwise conv2d operators in MobileNet used in the single kernel experiments. H/W denotes height and width, IC input channels, OC output channels, K kernel size, and S stride size. All ops use “SAME” padding. All depthwise conv2d operations have channel multipliers of 1.
这种基础架构对于嵌入式设备尤其重要,因为传统上,嵌入式设备需要进行繁琐的手动交叉编译,代码部署和测量。
6.评价
TVM核心是用C++实现的(~50k LoC)。提供Python和Java的语言绑定。本文前面的部分评估了TVM的几个独立优化和组件的影响,即,图4中的算子融合,图10中的延迟隐藏,以及图12中基于ML的成本模型。
现在重点关注端到端评估,旨在回答以下问题:
?TVM能否在多个平台上优化DL工作负载?
?TVM与每个后端上现有的DL frame works(依赖高度优化的库)相比如何?
?TVM能否支持新出现的DL工作负载(例如,深度卷积,低精度算子)?
?TVM能否支持优化新的专用加速器?
为了回答这些问题,在四种平台上评估了TVM:
(1) 服务器级GPU
(2) 嵌入式GPU
(3) 嵌入式CPU
(4) 在低功耗FPGA SoC上实现的DL加速计。
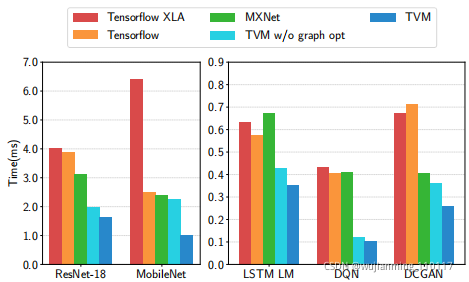
Figure 14: GPU end-to-end evaluation for TVM, MXNet, Tensorflflow, and Tensorflflow XLA. Tested on the NVIDIA Titan X.
基准测试基于现实世界的DL推理工作负载,包括ResNet,MobileNet,LSTM语言模型,深度Q网络(DQN)和深度卷积生成对抗网络(DCGAN)。将方法与现有的DL框架进行比较,包括MxNet和TensorFlow,依赖于高度工程化的,特定于供应商的库。TVM执行端到端的自动优化和代码生成,无需外部算子库。
6.1 服务器级GPU评估
首先比较端到端的深度神经网络TVM,MXNet(V1.1),Tensorflow(V1.7)和Tensorflow XLA的NVIDIA TITIX。MXNet和Tensorflow都使用cuDNN v7作为卷积算子;实现了版本的深度卷积,因为相对较新,还没有得到最新库的支持。还使用cuBLAS v8进行矩阵乘法。另一方面,Tensorflow XLA使用JIT编译。
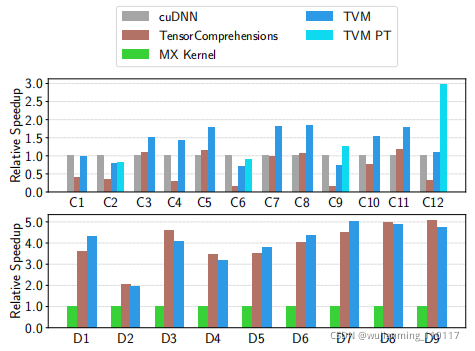
Figure 15: Relative speedup of all conv2d operators in ResNet-18 and all depthwise conv2d operators in MobileNet. Tested on a TITAN X. See Table 2 for operator confifigurations. We also include a weight pretransformed Winograd for 3x3 conv2d (TVM PT).
图14显示,TVM优于基线,由于联合图优化和生成高性能融合算子的自动优化器,其加速比从1.6×到3.8×不等。DQN的3.8倍加速是由于其使用了未经cuDNN优化的非常规算子(4×4 conv2d,步长=2);ResNet工作负载更为传统。TVM会在这两种情况下自动找到优化的。
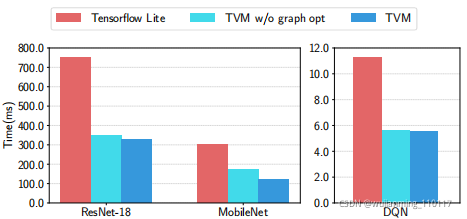
Figure 16: ARM A53 end-to-end evaluation of TVM and TFLite.
为了评估算子级优化的有效性,还对ResNet和MobileNet中的每个张量算子,进行了细分比较,如图15所示。将TensorComprehension(TC,commit:ef644ba)作为一个额外的基线,是最近引入的自动调优框架。2 TC结果包括在10代×100群体×每个算子2个随机种子中发现的最佳seeds(即每个算子2000次试验)。二维卷积是最重要的DL算子之一,cuDNN进行了大量优化。然而,TVM仍然可以为大多数层,生成更好的GPU内核。深度卷积是一种结构简单的新算子。
在这种情况下,TVM和TC都可以找到比MXNet手工制作的内核更快的内核。TVM的改进主要归功于,对大调度空间的探索和有效的基于ML的搜索算法。
6.2嵌入式CPU评估
在ARM Cortex A53(四核1.2GHz)上,评估了TVM的性能。使用Tensorflow Lite(TFLite,commit:7558b085)作为基线系统。
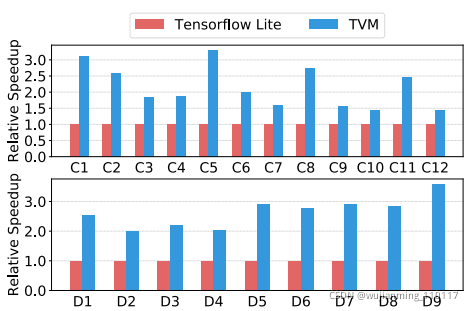
Figure 17: Relative speedup of all conv2d operators in ResNet-18 and all depthwise conv2d operators in mobilenet. Tested on ARM A53. See Table 2 for the configurations of these operators.
图17将TVM算子与ResNet和MobileNet的手工优化算子进行了比较。TVM生成的算子,在两种神经网络工作负载方面,都优于手动优化的TFLite版本。该结果还证明了TVM能够快速优化新兴的张量算子,如深度卷积算子。最后,图16显示了三种工作负载的端到端比较,TVM优于TFLite基线。
3个超低精度算子,通过为小于8位的定点数据类型,生成高度优化的算子,展示了TVM支持超低精度推理的能力。低精度网络用矢量化位串行乘法,代替昂贵的乘法,矢量化位串行乘法,由按位和pop计数减少组成。实现高效的低精度推理,需要将量化数据类型打包为更广泛的标准数据类型,如int8或int32。
TVM系统生成的代码性能优于Caffe2的手动优化库。实现了一个特定于ARM的tensorization内核,利用ARM指令构建一个高效,低精度的矩阵向量微内核。然后,使用TVM的自动优化器,搜索调度空间。

Figure 18: Relative speedup of single- and multithreaded low-precision conv2d operators in ResNet. Baseline was a single-threaded, hand-optimized implementation from Caffe2 (commit: 39e07f7). C5, C3 are 1x1 convolutions that have less compute intensity, resulting in less speedup by multi-threading.
图18将TVM与ResNet上的Caffe2超低精度库进行了比较,用于2位激活,1位权重推理。由于基线是单线程的,还将与单线程TVM版本进行比较。
单线程TVM优于基线,尤其是C5,C8和C11层;这些是内核大小为1×1,步长为2的卷积层,超低精度基线库未对此进行优化。此外,还利用额外的TVM功能,生成一个并行库实现,该实现显示出比基线更好的性能。除了2位+1位配置,TVM可以生成优化基线库不支持的其它精度配置,提高灵活性。
6.3 嵌入式GPU评估
对于移动GPU实验,在配备ARM Mali-T860MP4 GPU的Firefly-RK3399板上,运行端到端管道。基线是供应商提供的库,即ARM计算库(v18.03)。
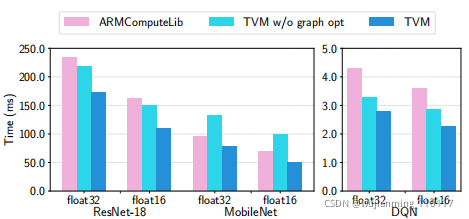
Figure 19: End-to-end experiment results on Mali-T860MP4. Two data types, flfloat32 and flfloat16, were evaluated.
如图19所示,对于float16和float32,在三种可用模型上的表现,都优于基线(基线尚不支持DCGAN和LSTM)。加速比范围为1.2×到1.6×6.4 FPGA加速器,评估Vanilla深度学习加速器,介绍TVM如何在在FPGA上原型化的通用推理加速器设计上,处理特定于加速器的代码生成。
在本次评估中使用了Vanilla DeepLearning Accelerator(VDLA)――将以前加速器提案中的特征,提取到一个最低限度的硬件架构中――展示TVM生成高效调度的能力,该调度可以针对专门的加速器。图20显示了VDLA体系结构的高级硬件组织。VDLA编程为张量处理器,高效执行高计算强度的算子(例如,矩阵乘法,高维卷积)。可以执行加载/存储操作,将阻塞的三维张量,从DRAM带到SRAM的相邻区域。为网络参数,层输入(窄数据类型)和层输出(宽数据类型),提供专门的片上存储器。最后,VDLA提供了对连续加载,计算和存储的显式同步控制,最大化内存和计算算子间的重叠。
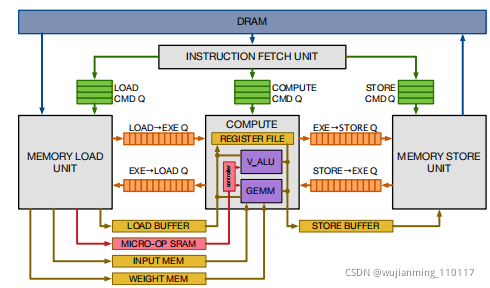
Figure 20: VDLA Hardware design overview.
在低功耗PYNQ板上,实现了VDLA设计,该板集成了时钟频率为667MHz的ARM Cortex A9双核CPU和基于Artix-7的FPGA结构。在这些有限的FPGA资源上,实现了一个时钟频率为200MHz的16×16矩阵向量单元,执行8位值的乘积,在每个周期累加到32位寄存器中。此VDLA设计的理论峰值吞吐量约为102.4GOPS/s。为激活存储分配了32kB的资源,为参数存储分配了32kB的资源,为microcode缓冲区分配了32kB的资源,为寄存器文件分配了128kB的资源。这些片上缓冲区决不足以为单层ResNet,提供足够的片上存储,无法对有效的内存重用和延迟隐藏,进行案例研究。
使用C Runtime API为VDLA构建了一个驱动程序库,该API构造指令,推送到目标加速器执行。代码生成算法将加速器程序转换为一系列调用,转换为Runtime API。添加专门的加速器后端,需要~Python中的2k LoC。
端到端ResNet评估。使用TVM在PYNQ平台上,生成ResNet推理内核,将尽可能多的层卸载到VDLA。
生成仅CPU和CPU+FPGA实现的调度。由于卷积深度较低,第一个ResNet卷积层,无法在FPGA上有效卸载,而是在CPU上计算。然而,ResNet中的所有其它卷积层,都适合于高效的floading。由于VDLA不支持支持这些操作,因此CPU上执行了诸如剩余层和激活类的操作。

Figure 21: We offlfloaded convolutions in the ResNet workload to an FPGA-based accelerator. The grayed-out bars correspond to layers that could not be accelerated by the FPGA and therefore had to run on the CPU. The FPGA provided a 40x acceleration on offlfloaded convolution layers over the Cortex A9.
图21将ResNet推理时间分解为仅CPU执行和CPU+FPGA执行。大部分计算都花费在卷积层上,这些卷积层可以卸载到VDLA。对于这些卷积层,实现的加速比为40×。不幸的是,由于阿姆达尔定律,FPGA加速系统的整体性能,受到必须在CPU上执行的部分工作负载的制约。扩展VDLA设计,支持这些其它算子,将有助于进一步降低成本。
这个基于FPGA的实验,展示了TVM适应新体系结构和所暴露的硬件本质的能力。
7.相关工作
深度学习框架为用户提供了方便的界面,表达DL工作负载,轻松部署到不同的硬件后端。虽然现有框架目前依赖于供应商特定的tensor算子库,执行工作负载,但可以利用TVM的堆栈为大量硬件设备,生成优化的代码。
高级计算图DSL是表示和执行高级优化的典型方式。Tensorflow的XLA和最近推出的DLVM属于这一类。这些工作中计算图的表示是相似的,本文使用了高级计算图DSL。虽然图级表示非常适合高级优化,但级别太高,无法在一组不同的硬件后端下优化张量算子。以前的工作依赖于特定的降低规则,直接生成低级LLVM,或者求助于供应商定制的库。这些方法需要对每个硬件后端和变型算子组合,进行大量工程设计。
Halide引入了分离计算和调度的思想。采用Halide的思想,在编译器中重用现有的有用调度原语。
张量算子调度与GPU DSL和基于多面体的循环变换的其它工作有关。TACO介绍了一种在CPU上生成稀疏张量算子的通用方法。Weld是用于数据处理任务的DSL。特别关注解决GPU和专用加速器的DL工作负载的新调度挑战。新原语可能被这些工作中的优化管道所采用。
ATLAS和FFTW等高性能库,使用自动调优获得最佳性能。张量理解应用黑盒自动调谐和多面体优化CUDA内核。OpenTuner和现有的超参数优化算法,采用域无关搜索。预定义的成本模型,用于自动调度Halid中的图像处理管道。TVM的ML模型,使用有效的领域感知成本模型,该模型考虑了项目结构。
基于分布式的调度优化器,可以扩展到更大的搜索空间,可以在大量受支持的后端上,找到最先进的内核。提供了一个端到端堆栈,可以直接从DL框架中获取描述,与图形级堆栈一起进行联合优化。
尽管用于深度学习的加速器越来越流行,但如何有效地针对这些设备,构建编译堆栈仍不清楚。评估中使用的VDLA设计,提供了一种总结类TPU加速器特性的通用方法,提供了一个关于如何为加速器编译代码的具体案例研究。
可能有利于将深度学习编译为FPGA的现有系统。本文提供了一个通用的解决方案,通过张量化和编译器驱动的延迟隐藏,有效定位加速器。
8.结论
提出了一个端到端编译堆栈,解决跨不同硬件后端的深度学习的基本优化挑战。系统包括自动端到端优化,这是从历史上看,这是一项劳动密集型和高度专业化的任务。
希望这项工作将鼓励对端到端编译方法的进一步研究,为DL系统软硬件协同设计技术打开新的机会。
参考文献:
TVM: An Automated End-to-End Optimizing Compiler for Deep Learning