����Ŀ¼
RoIAlign ���ô�
RoIAlign ���ڽ�����ߴ�����Ȥ���������ͼ,��ת��Ϊ�����̶��ߴ� H��W ��С����ͼ��
��RoI poolingһ��,�����ԭ���ǽ� h �� w h��w h��w ����������Ϊ H �� W H��W H��W ����,ÿ�������Ǵ�С����Ϊ h / H �� w / W h/H��w/W h/H��w/W ���Ӵ��� ,Ȼ��ÿ���Ӵ����е�ֵ���ػ�����Ӧ���������Ԫ�С��븴ϰRoI pooling����Ŀ��Կ���ƪ��
RoIAlign ��ʵ��������ȷ�汾�� RoIPooling,��˫���Բ�ֵȡ����RoIPooling�е�ֱ��ȡ���IJ�����
������һ������ͼ������ RoIAlign ����ԭ����
RoIAlign ����ԭ��
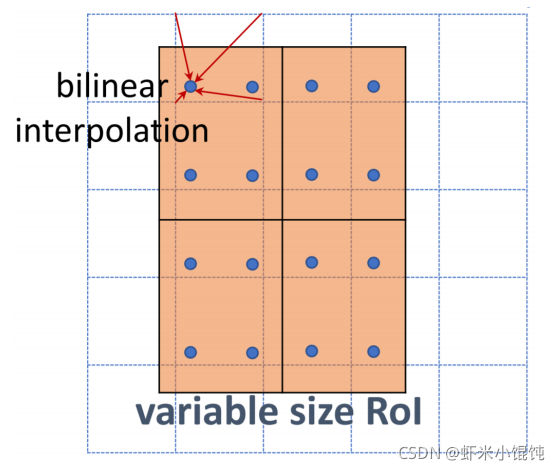
����һ��feature map,����ÿ����ͬ�ߴ��proposed region,��Ҫת���ɹ̶���С
H
��
W
H��W
H��W�� feature map,H��W����һ��ij�������
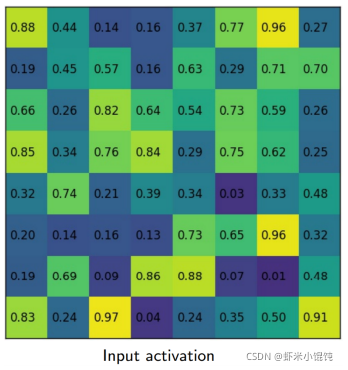
��ɫ�ֿ���һ��
7
��
5
7��5
7��5 ��С�� proposed region,�����зֳ�
H
��
W
H��W
H��W ��sections(������2x2��):
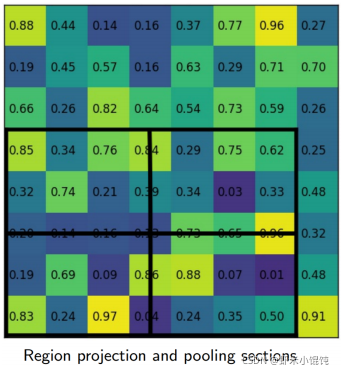
��ÿ��section�����ĸ�����,�ú�ɫ����ʾ������λ��:
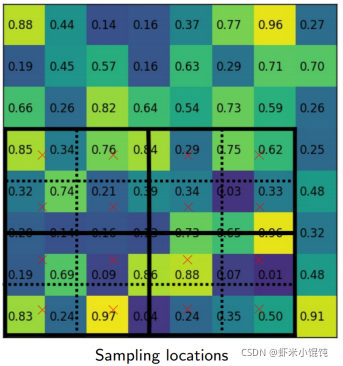
ÿ��section���ĸ���ɫ����ֵ,��˫���Բ�ֵ����:
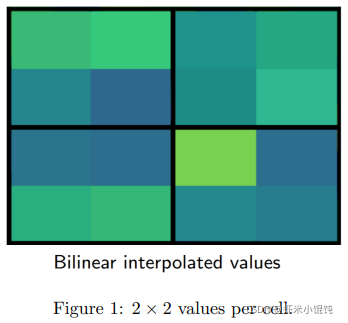
��ÿ�� section ���ĸ�ֵ���� max pooling,������:
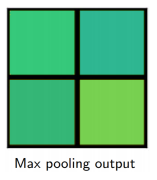
������������Ҫ�Ĺ̶���С����ˡ�
����̶���С�������ͨ��ȫ���ӵIJ�,���ڱ߽��ع�ͷ���,�����ڼ��ͷָ�ģ���С�
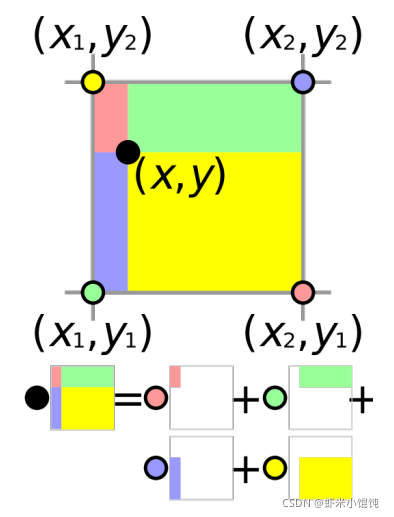
˫���Բ�ֵ(Bilinear Interpolation)
������ͼ���Ӿ���������˫���Բ�ֵ,�ڵ��ϵ�˫���ڲ�ֵ�Ǹ����ĸ���ļ�Ȩ��,Ȩֵ���ĸ����Ӧ����ɫ������������е�ռ�ȡ��������ϽǻƵ�
(
x
1
,
y
2
)
(x_1,y_2)
(x1?,y2?) ��Ӧ�������½ϴ�Ļ�ɫ���������
pytorch�е�ʵ��
RoIAlign��pytorch�е�ʵ����torchvision.ops.RoIAlign,torchvision.ops��ʵ�ֵ��Ǽ�����Ӿ����ض���operators��
class: torchvision.ops.RoIAlign(output_size, spatial_scale, sampling_ratio)
- output_size (int or Tuple[int, int]) �C �����С,�� (height, width) ��ʾ��
- spatial_scale (float) �C ����������ӳ�䵽������ı������ӡ�Ĭ��ֵ1.0��
- sampling_ratio (int) �C ��ֵ���������ڼ���ÿ���ϲ����bin�����ֵ�IJ�������Ŀ�����> 0,��ǡ��ʹ��sampling_ratio x sampling_ratio����㡣���<= 0,��ʹ������Ӧ�����������(����Ϊcell (roi_width / pooled_w),ͬ������߶�)��Ĭ��ֵ1��
torchvision.ops.roi_align(input, boxes, output_size, spatial_scale=1.0, sampling_ratio=-1)
- input (Tensor[N, C, H, W]) �C ��������
- boxes (Tensor[K, 5] or List[Tensor[L, 4]]) �C �����Χ���� ( x 1 , y 1 , x 2 , y 2 ) (x1, y1, x2, y2) (x1,y1,x2,y2) ��ʽ��ʾ�����������ǵ���tensor,��һ�б�ʾbatch index;���������һ��tensor List,ÿ��tensor��Ӧbatch�еĵ� i i i��Ԫ�صķ���
��ʾ��
import torch
import torchvision
# ����RoIAlign��
pooler = torchvision.ops.RoIAlign(output_size=2,sampling_ratio=2,spatial_scale=5)
# ����һ�� 8x8 ��feature:
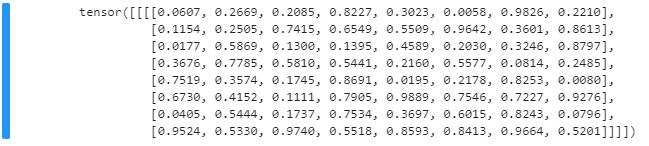
inputTensor = torch.rand(1,1,8,8)
inputTensor��������:
�ٴ���һ��box:
box = torch.tensor([[0.0,0.375,0.875,0.625]])
output = pooler(inputTensor,[box])#shape:[1, 1, 2, 2]
������:

��FasterRCNN�е�ʹ��ʾ��
import torchvision
import torchvision
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.rpn import AnchorGenerator
# load a pre-trained model for classification and return
# only the features
backbone = torchvision.models.mobilenet_v2(pretrained=True).features
# FasterRCNN needs to know the number of
# output channels in a backbone. For mobilenet_v2, it's 1280
# so we need to add it here
backbone.out_channels = 1280
# let's make the RPN generate 5 x 3 anchors per spatial
# location, with 5 different sizes and 3 different aspect
# ratios. We have a Tuple[Tuple[int]] because each feature
# map could potentially have different sizes and
# aspect ratios
anchor_generator = AnchorGenerator(sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),))
# let's define what are the feature maps that we will
# use to perform the region of interest cropping, as well as
# the size of the crop after rescaling.
# if your backbone returns a Tensor, featmap_names is expected to
# be [0]. More generally, the backbone should return an
# OrderedDict[Tensor], and in featmap_names you can choose which
# feature maps to use.
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=['0'],
output_size=7,
sampling_ratio=2)
# put the pieces together inside a FasterRCNN model
model = FasterRCNN(backbone,
num_classes=2,
rpn_anchor_generator=anchor_generator,
box_roi_pool=roi_pooler)
�����
https://zhuanlan.zhihu.com/p/59692298
https://zhuanlan.zhihu.com/p/73138740
https://pytorch.org/docs/1.2.0/torchvision/ops.html
https://pytorch.org/docs/1.2.0/_modules/torchvision/ops/roi_align.html