�㷨���
�����㷨��һ���ලѧϰ,�����������������������ͨ�����ϵ����������ĵķ�ʽ������������ࡣ�����ĵ�����ʽ��K-means�����FCM����ȡ�
K-means�㷨���
K-means��һ��Ӳ���ʽ,��ȷ���Ľ�ÿ����������һ��ȷ���ľ�����С�����ʵ�ַ�ʽ���ǵ������¾�������,�������,���ȳ�ʼ�� k k k����������,Ȼ��ÿ�������鵽���Լ���������ľ���������,�����¼����������,��˷�������ֱ���㷨�ﵽֹͣ������
FCM�㷨���
FCM��k-means���,��һ��ģ������ķ���,�����յľ�����Ϊһ�����Ⱦ���,��¼ÿ������������ÿ������ص������ȡ������ʵ�ַ�ʽ��k-meansҲ����,���ȿ��Գ�ʼ�������Ⱦ���,Ȼ������������ʽȷ����������,�ٵ������������Ⱦ���,��˵���ֱ���ﵽֹͣ������
��Ȼ,K-means�㷨��FCM�㷨��Ч���ܴ�̶���ȡ���� k k kֵ��ѡ�������б�ǩ���ݼ�����ʵ��ʱ,һ�����ѡ�����������Ϊ k k kֵʵ�顣
�㷨����
�����������š��� X = { x i j } n �� m X=\left\{x_{ij}\right\}_{n\times m} X={xij?}n��m?��ʾ��������,���� n n n��ʾ��������, m m m��ʾ����ά����������ǩΪ C = { C 1 , C 2 , �� , C k } C=\left\{C_1,C_2,\ldots, C_k\right\} C={C1?,C2?,��,Ck?}��ʾ k k k�����,�༴����ء�
K-means�㷨����
K-means��Ŀ������С��
J
=
��
i
=
1
k
J
i
=
��
i
=
1
k
��
x
��
C
i
�O
�O
x
?
m
i
�O
�O
J = \sum_{i=1}^{k} J_i = \sum_{i=1}^{k}\sum_{\boldsymbol{x} \in C_i} \Big|\Big|\boldsymbol{x}-\boldsymbol{m}_i\Big|\Big|
J=i=1��k?Ji?=i=1��k?x��Ci?��?�O�O�O?�O�O�O?x?mi?�O�O�O?�O�O�O?
����
x
\boldsymbol{x}
x��ʾ��������,
m
1
,
m
2
,
��
,
m
k
\boldsymbol{m}_1, \boldsymbol{m}_2, \ldots, \boldsymbol{m}_k
m1?,m2?,��,mk?��ʾ
C
1
,
C
2
,
��
,
C
k
C_1, C_2, \ldots, C_k
C1?,C2?,��,Ck?�ľ�����������,���㹫ʽΪ
m
i
=
1
�O
C
i
�O
��
x
��
C
i
x
\boldsymbol{m}_i = \frac{1}{\left|C_i\right|}\sum_{\boldsymbol{x} \in C_i} \boldsymbol{x}
mi?=�OCi?�O1?x��Ci?��?x
����
�O
C
i
�O
\left|C_i\right|
�OCi?�O��ʾ��
C
i
C_i
Ci?�Ĵ�С��
�ڴ˻�����,����k-means���㷨����:
- ��ʼ��ѡ�� k k k���������� m 1 ( 1 ) , m 2 ( 1 ) , �� , m k ( 1 ) \boldsymbol{m}_1^{(1)}, \boldsymbol{m}_2^{(1)}, \ldots, \boldsymbol{m}_k^{(1)} m1(1)?,m2(1)?,��,mk(1)?,������ȫ���ѡȡ��ѡȡ���������㡣���� t = 1 t=1 t=1��ʾ��ǰ����������
- ������С�������Ҫ�����ģʽ����
x
\boldsymbol{x}
x�����
k
k
k�����е�ijһ��
C
i
C_i
Ci?����
j = arg ? max ? i { �O �O x ? m i ( t ) �O �O , ?? i = 1 , 2 , �� , k } j = \mathop{\arg\max}_i \left\{\left|\left|\boldsymbol{x} - \boldsymbol{m}_i^{(t)} \right|\right|,\; i=1,2,\ldots,k \right\} j=argmaxi?{�O�O�O?�O�O�O?x?mi(t)?�O�O�O?�O�O�O?,i=1,2,��,k}
�� x �� C j ( t ) \boldsymbol{x}\in C_j^{(t)} x��Cj(t)?,�� x \boldsymbol{x} x���ھ��� C j ( t ) C_j^{(t)} Cj(t)?�� - ��������������ĵ��µ�����ֵ
m
i
(
t
+
1
)
\boldsymbol{m}_i^{(t+1)}
mi(t+1)?,��
m i ( t + 1 ) = 1 �O C i �O �� x �� C i x , ?? i = 1 , 2 , �� , k \boldsymbol{m}_i^{(t+1)} = \frac{1}{\left|C_i\right|}\sum_{\boldsymbol{x} \in C_i} \boldsymbol{x},\; i=1,2,\ldots, k mi(t+1)?=�OCi?�O1?x��Ci?��?x,i=1,2,��,k - �� m i ( t + 1 ) �� m i ( t ) , ?? i = 1 , 2 , �� , k \boldsymbol{m}_i^{(t+1)} \neq \boldsymbol{m}_i^{(t)},\; i=1,2,\ldots,k mi(t+1)?��?=mi(t)?,i=1,2,��,k,���㷨��δ����,���ز���2������,�㷨����,���� { C 1 , C 2 , �� , C k } \left\{C_1,C_2,\ldots, C_k\right\} {C1?,C2?,��,Ck?}�� { m 1 , m 2 , �� , m k } \left\{\boldsymbol{m}_1, \boldsymbol{m}_2, \ldots, \boldsymbol{m}_k\right\} {m1?,m2?,��,mk?},�㷨������
FCM�㷨����
FCM��Ŀ������С��
J
=
��
j
=
1
k
��
i
=
1
n
[
��
j
(
x
i
)
]
b
�O
�O
x
i
?
m
j
�O
�O
2
=
��
j
=
1
k
��
i
=
1
n
��
i
j
b
??
d
i
j
\begin{aligned} J &= \sum_{j=1}^{k}\sum_{i=1}^{n}\Big[\mu_j(\boldsymbol{x}_i)\Big]^b \Big|\Big|\boldsymbol{x}_i - \boldsymbol{m}_j \Big|\Big|^2\\ &= \sum_{j=1}^{k}\sum_{i=1}^{n}\mu_{ij}^b\;d_{ij} \end{aligned}
J?=j=1��k?i=1��n?[��j?(xi?)]b�O�O�O?�O�O�O?xi??mj?�O�O�O?�O�O�O?2=j=1��k?i=1��n?��ijb?dij??
����,��ǰ����,
x
i
\boldsymbol{x}_i
xi?��ʾ����,
m
j
\boldsymbol{m}_j
mj?��ʾ��������,��
��
j
(
x
i
)
=
��
i
j
\mu_j(\boldsymbol{x}_i)=\mu_{ij}
��j?(xi?)=��ij?��ʾ����
x
i
\boldsymbol{x}_i
xi?�����ھ���
C
j
C_j
Cj?��������,
b
b
bΪģ������,�Ǻ�
d
i
j
d_{ij}
dij?��ʾ����
x
i
\boldsymbol{x}_i
xi?����
C
j
C_j
Cj?����
m
j
\boldsymbol{m}_j
mj?֮��ľ��롣
��Ϊ������,��Ȼ
��
i
j
\mu_{ij}
��ij?Ҫ����
��
j
=
1
k
��
i
j
=
1
,
??
i
=
1
,
2
,
��
,
n
\sum_{j=1}^{k}\mu_{ij}=1,\; i=1,2,\ldots,n
j=1��k?��ij?=1,i=1,2,��,n
��ͬһ������������
k
k
k������ص�������֮��ӦΪ1��
�ɴ�Լ������,ʹ���������ճ��ӷ���⼫Сֵ���õ�
m
j
=
��
i
=
1
n
��
i
j
b
??
x
i
��
i
=
1
n
��
i
j
b
,
????
��
i
j
=
(
1
/
d
i
j
)
1
/
(
b
?
1
)
��
l
=
1
k
(
1
/
d
i
l
)
1
/
(
b
?
1
)
=
1
��
l
=
1
k
(
d
i
j
/
d
i
l
)
1
/
(
b
?
1
)
\boldsymbol{m}_j = {\displaystyle{\frac{\displaystyle{\sum_{i=1}^{n}\mu_{ij}^b\; \boldsymbol{x}_i}}{\displaystyle{\sum_{i=1}^{n}\mu_{ij}^b}}}},\;\; \mu_{ij}= {\displaystyle{\frac{\displaystyle{\left(1\big/ d_{ij}\right)^{1/(b-1)}}}{\displaystyle{\sum_{l=1}^{k}\left(1\big/ d_{il}\right)^{1/(b-1)}}}}} = {\displaystyle{\frac{\displaystyle{1}}{\displaystyle{\sum_{l=1}^{k}(d_{ij} / d_{il})^{1/(b-1)}}}}}
mj?=i=1��n?��ijb?i=1��n?��ijb?xi??,��ij?=l=1��k?(1/dil?)1/(b?1)(1/dij?)1/(b?1)?=l=1��k?(dij?/dil?)1/(b?1)1?
�������FCM�㷨������:
- ��ʼ�������Ⱦ��� U ( 0 ) = { �� i j ( 0 ) } U^{(0)}=\left\{\mu_{ij}^{(0)}\right\} U(0)={��ij(0)?},���ǵ������� t = 0 t=0 t=0��
- ������ʽ���¾�������
m
(
t
+
1
)
\boldsymbol{m}^{(t+1)}
m(t+1)
m j ( t + 1 ) = �� i = 1 n [ �� i j ( t ) ] b x i �� i = 1 n [ �� i j ( t ) ] b \boldsymbol{m}_j^{(t+1)} = {\displaystyle{\frac{\displaystyle{\sum_{i=1}^{n}\left[\mu_{ij}^{(t)}\right]^b\boldsymbol{x}_i}}{\displaystyle{\sum_{i=1}^{n}\left[\mu_{ij}^{(t)}\right]^b}}}} mj(t+1)?=i=1��n?[��ij(t)?]bi=1��n?[��ij(t)?]bxi?? - ������ʽ���������Ⱦ���
U
(
t
+
1
)
U^{(t+1)}
U(t+1)
�� i j ( t + 1 ) = 1 �� l = 1 k [ d i j ( t + 1 ) / d i l ( t + 1 ) ] 1 / ( b ? 1 ) \mu_{ij}^{(t+1)} = {\displaystyle{\frac{\displaystyle{1}}{\displaystyle{\sum_{l=1}^{k}\left[d_{ij}^{(t+1)} / d_{il}^{(t+1)}\right]^{1/(b-1)}}}}} ��ij(t+1)?=l=1��k?[dij(t+1)?/dil(t+1)?]1/(b?1)1?
������������, d i j ( t ) = �O �O x i ? m j ( t ) �O �O 2 d_{ij}^{(t)}=\left|\left|\boldsymbol{x}_i - \boldsymbol{m}_j^{(t)} \right|\right|^2 dij(t)?=�O�O�O?�O�O�O?xi??mj(t)?�O�O�O?�O�O�O?2�� - ������ʽ���¾�������
m
(
t
+
1
)
\boldsymbol{m}^{(t+1)}
m(t+1)
�� �O �O m ( t ) ? m ( t + 1 ) �O �O < �� \Big|\Big| \boldsymbol{m}^{(t)} -\boldsymbol{m}^{(t+1)} \Big|\Big| < \varepsilon �O�O�O?�O�O�O?m(t)?m(t+1)�O�O�O?�O�O�O?<��,���ʾ�㷨����,ֹͣ����,��� m \boldsymbol{m} m�Լ� U U U������,���ز���3��
���ݼ�����
UCI-sonar���ݼ�
UCI-sonar���ݼ���һ��ͨ���������ݶ���ʯ��ˮ���б�����ݼ�����ֻ�����ࡰM���͡�R����ʾˮ����ʯ,�����ռ�60ά,Ϊ60�����ɵ���ռ�����,���ݼ�����207������,����111����M����,96����R���ࡣ
UCI-iris���ݼ�
UCI-iris���ݼ���һ�������β�������ݼ�,�����ĸ����,�����ռ�Ϊ��ά,��ʾ�����ĸ�����,���ݼ�����150��������
Cifar-10���ݼ�
Cifar-10���ݼ���һ��ͼ��������ݼ�,ͼ��ߴ� 3 �� 32 �� 32 3\times 32 \times 32 3��32��32,��10�ࡣ����ʵ��ʹ�õ���ͼƬ���������ص���Ϊ���ݼ�,��������ͼ��ָ�ľ�������

ʵ������
����ǰ�������ݼ�,��ʹ����ԭ�����������Ϊ k k kֵ������Cifar-10���ݼ�,���Զ����ͬ��kֵʵ�顣��FCM�ľ������ b b b,ͳһȡ1.1��
ʵ�黷��:Intel? Core? i7-9750H CPU @ 2.60GHz.
Python�汾:python3.6, numpy=1.19.4, sklearn=0.21.2.
ʵ����������
����ʵ��
����ʹ�������㷨��UCI���������ݼ��Ͻ���ʵ�顣������ͼ��ȡ���ݼ���ǰ��ά��չʾ��
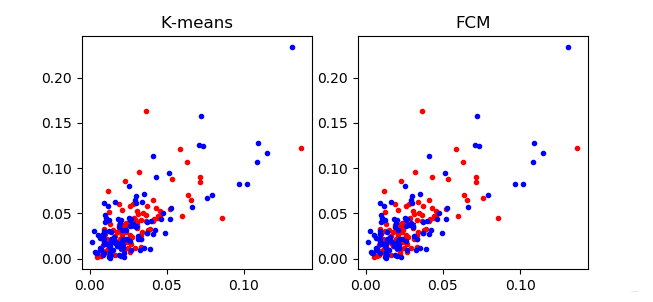

���Կ���,����ǰ����ά��iris���ݼ����Ѿ������ɷ�,����Ч���Ϻá���sonars���ݼ��ɷ��Խϲ��Ȼ,����ǰ����ά�������㷨������Ч���¶���,������sonars���ݼ���60��ά�ȡ����,�����������õľ����㷨����ָ�ꡣ�ڴ˲���ָ��ľ�����㼰ʵ�ַ�ʽ,������˵��,
ARIָ��
ARIָ����һ����Ҫ���ݼ���ǩ�ķ���ָ��,ָ�귶Χ�� [ ? 1 , ?? 1 ] [-1,\; 1] [?1,1],Խ���ʾ��������ԭ��ǩԽ�ӽ�,������Ч��Խ�á�
FMIָ��
FMIָ��Ҳ��Ҫ�б�ǩ����,��ARָ��Ƚ�����,��ָ�귶Χ�� [ 0 , ?? 1 ] [0,\; 1] [0,1]֮��,Խ�����Ч��Խ�á�
SCָ��
SCָ����һ�ֺ�������ؼ���ڲ������ָ��,����䲻��Ҫ�б�ǩ���ݡ�ָ�귶Χ�� [ 0 , ?? 1 ] [0, \; 1] [0,1]֮��,Ҳ��ָ��Խ���ʾ����Ч��Խ�á�
ʵ���������ݼ��������㷨�µı���,�õ��±�������
| UCI-sonar | UCI-iris | |||
|---|---|---|---|---|
| K-means | FCM | K-means | FCM | |
| Time/ms | 6.2 | 7.1 | 1.3 | 2.0 |
| ARI | 0.002 | 0.008 | 0.716 | 0.730 |
| FMI | 0.505 | 0.503 | 0.811 | 0.821 |
| SC | 0.199 | 0.198 | 0.551 | 0.552 |
���ϱ���,FCM���������ݼ��ϵñ��ֶ�������K-means�㷨,����Ӧ��Ҫ�и����ʱ�俪����ͬʱ,sonars���ݼ��ľ���Ч�����Բ���iris���ݼ�,�����ӽ�������ࡣ
ͼ��ָ�ʵ��
ʹ�������㷨�Ե���ͼ���е����ص���о���,�����ݼ�Ϊһ��ͼƬ,������ 32 �� 32 32\times 32 32��32��,ά��Ϊ3ά(RGB)������ʵ��������ͼ,��һ��Ϊԭͼ,MaskͼƬ������ÿ���������� k = 3 , 4 , 5 , 6 k=3,4,5,6 k=3,4,5,6,���������Ϊk-means,�Ҳ�ΪFCM��

��Ȼ�����ľ�����ȫ�������ص����ɫ,Ч���ܲ�,������ȫû�дﵽͼ��ָ��Ŀ�ġ�
���ǵ�,ͼ��ָ�Ľ���������ص�Ŀռ�λ���йص�,��˳��Լ�����������ά�ȱ�ʾ���ص�� x x x�� y y y��������,�Դ˱����������ص�Ŀռ�λ�ù�ϵ����Ȼ,������ͼ���Ͼ�����������ص�,���µ�����ά����Ҳ��ͬ���������
�����µ�5ά���ݼ�,��������,��ʱЧ���Ѿ����Ը��ơ�����չʾ9��ͼƬ��

��������,�����ķָ�Ч���Ƚ�����,���Dz���������ض�Ŀ��ķָ�,�����Ƕ�����ɫ��ķָ�����㷨�Ա�����,FCM�㷨��k-means����̫����졣
��¼
��¼����Ϊ���롣�������ұ�д��k-means�Լ�FCM��,Ȼ�������������ݼ��ϵ�ʵ�顣
��
import numpy as np
from sklearn.base import BaseEstimator, ClassifierMixin
from scipy.spatial.distance import cdist
from sklearn import datasets, metrics
import time
class KMeans(BaseEstimator, ClassifierMixin):
def __init__(self, k):
# method=2 => use L2 distance
self.k = k
self.x = None
self.y = None
self.labels = None
self.centers = None
self.iterations = 500
def quick_L2(self, x, a):
"""
Calculate distance between every vectors in x and a.
:param x: (n, n_features)
:param a: (m, n_features)
:return: (n, m) distance between every vectors in x and a
"""
dis = -2 * np.dot(x, a.T)
dis += np.einsum('ij,ij->i', x, x)[:, np.newaxis]
dis += np.einsum('ij,ij->i', a, a)[np.newaxis, :]
return dis
def fit(self, x, y=None, init_method='random_point', seed=None, eps=1e-5):
self.x = x
self.y = y
self.centers = 0
if seed is not None:
np.random.seed(seed)
if init_method == 'random_point':
self.centers = x[np.random.choice(x.shape[0], self.k), :]
else:
self.centers = np.random.randint(np.min(x), np.max(x), (x.shape[0], self.k))
pre_centers = self.centers.copy()
for i in range(self.iterations):
dis = self.quick_L2(self.x, self.centers)
idx = np.argmin(dis, axis=1)
for j in range(self.centers.shape[0]):
self.centers[j, :] = np.mean(self.x[idx == j, :], axis=0)
if np.mean(np.abs(pre_centers - self.centers)) < eps:
break
pre_centers = self.centers.copy()
def predict(self, a=None):
if a is None:
a = self.x
dis = self.quick_L2(a, self.centers)
idx = np.argmin(dis, axis=1)
return idx
class FCM(BaseEstimator, ClassifierMixin):
def __init__(self, k, alpha=2):
# method=2 => use L2 distance
self.k = k
self.alpha = alpha
self.x = None
self.y = None
self.labels = None
self.centers = None
self.u = None
self.iterations = 500
def quick_L2(self, x, a):
"""
Calculate distance between every vectors in x and a.
:param x: (n, n_features)
:param a: (m, n_features)
:return: (n, m) distance between every vectors in x and a
"""
dis = -2 * np.dot(x, a.T)
dis += np.einsum('ij,ij->i', x, x)[:, np.newaxis]
dis += np.einsum('ij,ij->i', a, a)[np.newaxis, :]
return dis
def fit(self, x, y=None, init_method='u', seed=None, eps=1e-5):
self.x = x
self.y = y
if seed is not None:
np.random.seed(seed)
if init_method == 'u':
self.u = np.random.rand(self.x.shape[0], self.k)
self.u /= np.sum(self.u, axis=1)[:, np.newaxis]
else:
# TODO
pass
pre_J = 0
for i in range(self.iterations):
u_a = self.u ** self.alpha # u_{ij}^{\alpha}
self.centers = np.dot(self.u.T, self.x) / np.sum(self.u, axis=0)[:, np.newaxis]
dis = self.quick_L2(self.x, self.centers)
J = np.sum(u_a * dis)
if abs(J - pre_J) < eps:
return
# Ensure \alpha - 1 != 0.
# Note that dis_ij is for d_ij^2
e = 1 / (self.alpha - 1 + eps * 100)
self.u = 1 / ((dis ** e) * np.sum(dis ** (-e), axis=1)[:, np.newaxis])
pre_J = J
def predict(self):
return np.argmax(self.u, axis=1)
if __name__ == '__main__':
iris = datasets.load_iris()
data = iris['data']
labels = iris['target']
tim = time.clock()
print('KNN:')
kmeans = KMeans(k=3)
kmeans.fit(data)
res = kmeans.predict()
print(res)
print('Time: ' + str(time.clock() - tim))
print('ARIָ��: ' + str(metrics.adjusted_rand_score(labels, res)))
print('FMIָ��: ' + str(metrics.fowlkes_mallows_score(labels, res)))
print('SCָ��: ' + str(metrics.silhouette_score(data, res, metric='euclidean')))
print('----------------------------------------')
tim = time.clock()
print('FCM:')
fcm = FCM(k=3)
fcm.fit(data)
res = fcm.predict()
print(res)
print('Time: ' + str(time.clock() - tim))
print('ARIָ��: ' + str(metrics.adjusted_rand_score(labels, res)))
print('FMIָ��: ' + str(metrics.fowlkes_mallows_score(labels, res)))
print('SCָ��: ' + str(metrics.silhouette_score(data, res, metric='euclidean')))
.
sonarsʵ��
from module import FCM, KMeans
from sklearn import metrics
import time
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
path = 'sonar.all-data'
data = pd.read_csv(path).values
labels = np.zeros_like(data[:, -1])
labels[data[:, -1] == 'R'] = 1
data = np.asarray(data[:, :-1], dtype=np.float32)
tim = time.clock()
print('KNN:')
kmeans = KMeans(k=2)
kmeans.fit(data)
res = kmeans.predict()
print(res)
print('Time: ' + str(time.clock() - tim))
print('ARIָ��: ' + str(metrics.adjusted_rand_score(labels, res)))
print('FMIָ��: ' + str(metrics.fowlkes_mallows_score(labels, res)))
print('SCָ��: ' + str(metrics.silhouette_score(data, res, metric='euclidean')))
plt.subplot(121)
plt.title('K-means')
plt.plot(data[res == 0, 0], data[res == 0, 1], 'r.')
plt.plot(data[res == 1, 0], data[res == 1, 1], 'b.')
plt.plot(kmeans.centers[0, 0], kmeans.centers[0, 1], 'r*')
plt.plot(kmeans.centers[1, 0], kmeans.centers[1, 1], 'b*')
print('----------------------------------------')
tim = time.clock()
print('FCM:')
fcm = FCM(k=2)
fcm.fit(data)
res = fcm.predict()
print(res)
print('Time: ' + str(time.clock() - tim))
print('ARIָ��: ' + str(metrics.adjusted_rand_score(labels, res)))
print('FMIָ��: ' + str(metrics.fowlkes_mallows_score(labels, res)))
print('SCָ��: ' + str(metrics.silhouette_score(data, res, metric='euclidean')))
plt.subplot(122)
plt.title('FCM')
plt.plot(data[res == 0, 0], data[res == 0, 1], 'r.')
plt.plot(data[res == 1, 0], data[res == 1, 1], 'b.')
plt.plot(fcm.centers[0, 0], fcm.centers[0, 1], 'r*')
plt.plot(fcm.centers[1, 0], fcm.centers[1, 1], 'b*')
plt.show()
.
irisʵ��
from module import FCM, KMeans
from sklearn import datasets, metrics
import time
import matplotlib.pyplot as plt
iris = datasets.load_iris()
data = iris['data']
labels = iris['target']
tim = time.clock()
print('KNN:')
kmeans = KMeans(k=3)
kmeans.fit(data)
res = kmeans.predict()
print(res)
print('Time: ' + str(time.clock() - tim))
print('ARIָ��: ' + str(metrics.adjusted_rand_score(labels, res)))
print('FMIָ��: ' + str(metrics.fowlkes_mallows_score(labels, res)))
print('SCָ��: ' + str(metrics.silhouette_score(data, res, metric='euclidean')))
plt.subplot(121)
plt.title('K-means')
plt.plot(data[res == 0, 0], data[res == 0, 1], 'r.')
plt.plot(data[res == 1, 0], data[res == 1, 1], 'b.')
plt.plot(data[res == 2, 0], data[res == 2, 1], 'y.')
plt.plot(kmeans.centers[0, 0], kmeans.centers[0, 1], 'r*')
plt.plot(kmeans.centers[1, 0], kmeans.centers[1, 1], 'b*')
plt.plot(kmeans.centers[2, 0], kmeans.centers[2, 1], 'y*')
print('----------------------------------------')
tim = time.clock()
print('FCM:')
fcm = FCM(k=3)
fcm.fit(data)
res = fcm.predict()
print(res)
print('Time: ' + str(time.clock() - tim))
print('ARIָ��: ' + str(metrics.adjusted_rand_score(labels, res)))
print('FMIָ��: ' + str(metrics.fowlkes_mallows_score(labels, res)))
print('SCָ��: ' + str(metrics.silhouette_score(data, res, metric='euclidean')))
plt.subplot(122)
plt.title('FCM')
plt.plot(data[res == 0, 0], data[res == 0, 1], 'r.')
plt.plot(data[res == 1, 0], data[res == 1, 1], 'b.')
plt.plot(data[res == 2, 0], data[res == 2, 1], 'y.')
plt.plot(fcm.centers[0, 0], fcm.centers[0, 1], 'r*')
plt.plot(fcm.centers[1, 0], fcm.centers[1, 1], 'b*')
plt.plot(fcm.centers[2, 0], fcm.centers[2, 1], 'y*')
plt.show()
.
CIFARʵ��
from module import FCM, KMeans
import numpy as np
import cv2
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # ����������ʾ���ı�ǩ
plt.rcParams['axes.unicode_minus'] = False # ����������ʾ����
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dic = pickle.load(fo, encoding='bytes')
return dic
def put_mask(img, mask):
mask_draw = np.zeros((32, 32, 3), dtype=np.uint8)
mask_draw[mask == 0] = np.array((0, 0, 255))
mask_draw[mask == 1] = np.array((0, 255, 0))
mask_draw[mask == 2] = np.array((255, 0, 0))
mask_draw[mask == 3] = np.array((255, 255, 0))
mask_draw[mask == 4] = np.array((255, 0, 255))
mask_draw[mask == 5] = np.array((0, 255, 255))
mask_draw[mask == 6] = np.array((0, 0, 0))
# alpha Ϊ��һ��ͼƬ������
alpha = 0.8
# beta Ϊ�ڶ���ͼƬ������
beta = 0.2
gamma = 0
# cv2.addWeighted ��ԭʼͼƬ�� mask �ں�
masked_img = cv2.addWeighted(img, alpha, mask_draw, beta, gamma)
return mask_draw, masked_img
if __name__ == '__main__':
pic_list = range(1,10)
k_list = [3, 4, 5, 6]
ttt = 0 # num for showing pictures
plt.figure(1)
for i in range(len(pic_list)):
img = cv2.imread(str(pic_list[i]) + '.jpg')
print(img.shape)
ttt += 1
plt.subplot(len(pic_list), len(k_list) * 2 + 1, ttt)
plt.axis('off')
plt.imshow(img)
if i == 0:
plt.title('ԭͼ', fontdict={'fontsize': 10})
for kk in range(len(k_list)):
tmp = [img[:, :, i].reshape((1024, 1)) for i in range(3)]
tmp.append(np.array([i % 32 for i in range(1024)]).reshape(1024, 1))
tmp.append(np.array([i // 32 for i in range(1024)]).reshape(1024, 1))
data = np.concatenate(tmp, axis=1)
kmeans = KMeans(k=k_list[kk])
kmeans.fit(data)
label = kmeans.predict()
# print('SCָ��: ' + str(metrics.silhouette_score(data, label, metric='euclidean')))
label = label.reshape((32, 32))
# print(label)
mask, masked_img = put_mask(img, label)
ttt += 1
plt.subplot(len(pic_list), len(k_list) * 2 + 1, ttt)
plt.axis('off')
plt.imshow(mask)
if i == 0:
plt.title('K-means', fontdict={'fontsize': 10})
fcm = FCM(k=k_list[kk])
fcm.fit(data)
label = fcm.predict()
label = label.reshape((32, 32))
mask, masked_img = put_mask(img, label)
ttt += 1
plt.subplot(len(pic_list), len(k_list) * 2 + 1, ttt)
plt.axis('off')
plt.imshow(mask)
if i == 0:
plt.title('FCM', fontdict={'fontsize': 10})
# ttt += 1
# plt.subplot(len(pic_list), len(k_list) * 2 + 1, ttt)
# plt.axis('off')
# plt.imshow(masked_img)
plt.show()
.