论文地址:https://arxiv.org/abs/1804.01452
代码:https://github.com/LiqunChen0606/Jointly-Discovering-Visual-Objects-and-Spoken-Words
论文笔记,有问题请在评论区指出
摘要
本文设计了一个将音频字幕和对应的图像关联的神经网络,通过image-audio retrieval代理任务的学习,也可以实现图像中的声源定位。本文方法不需要监督。在Places 205和ADE20K数据集上进行了实验,实现了把图像中的物体和语音中的文字在语义上联结配对。作者是在raw sensory上实现的:即image pixels 和 speech waveform。
一、背景

作者想要探究在未经处理的数据上(unaligned、unannotated)能否将语音与视觉联系起来。
作者强调的是本文方法不使用任何传统的语音识别或转录,或目标检测识别模型,在不使用任何监督的情况下,实现对图像中物体和语音单词的检测分割。
二、模型
作者方法和之前方法不同的是,不再将整张图像和语音发音映射起来,而是学习在时间上和空间上分布的表示,实现在每个模态上的直接共同定位。优化目标是ranking-based。
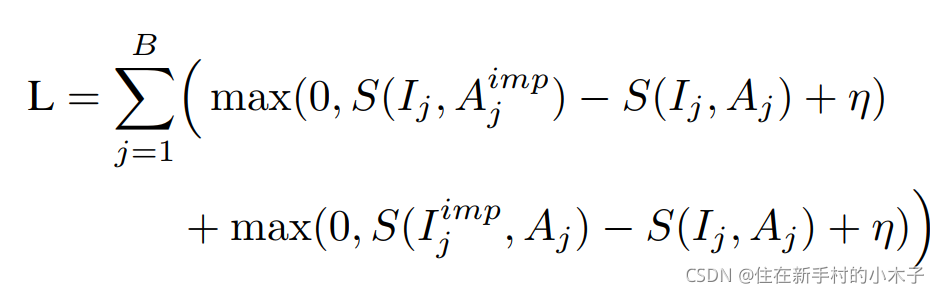
作者使用两个分支来分别处理图像和音频
对于图像分支,前人工作一般需要预训练VGG,本文不需要,另外只保留到了conv5,去掉了后面的池化等操作。

对于音频和图像相似性的计算,先点积
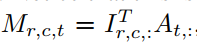
可选用的相似性计算:
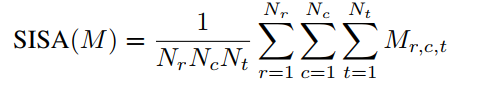
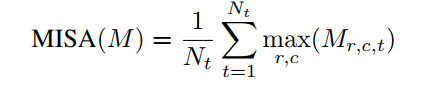
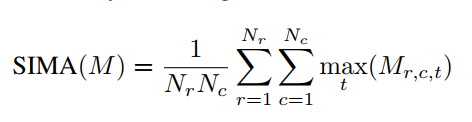
三、实验
首先进行了查询实验

然后进行了定位实验


还进行了聚类实验


并提出了一个基于WordNet的衡量指标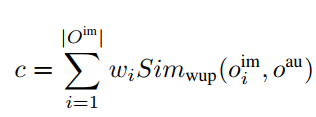
不同损失和网络结构对比
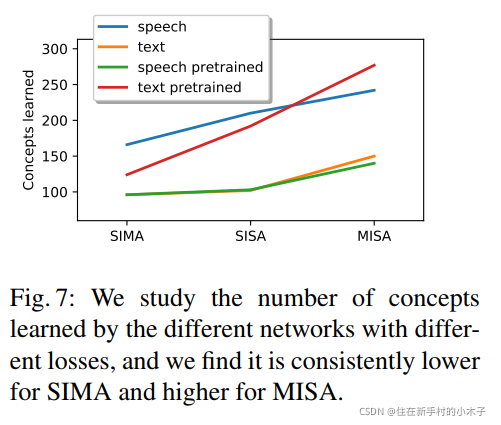
可视化

