��Ƶ����ģ�ͻ���
ǰ��
��������������ǿ�㷨����������,��ѧ�ڼ�����е�ǰ�ζ�������ͳ�źŴ����㷨��19���Ժ�������ѧϰ����������ģ��ƾ��������Ĵ���Ч��,һʱ��ͷ����,�ƺ�ÿ���˶���ʼ������ģ�ͽ����·�ӡ�
�ر��Ǵ�2020������ʼ�ٰ��Deep Noise Suppression Challenge �C INTERSPEECH 2020(DNS)��ʼ,������У������Ժ���������ҵ���������ʩչ���ա������־ٰ���Deep Noise Suppression Challenge �C ICASSP 2021��Deep Noise Suppression Challenge �C INTERSPEECH 2021
�����ж���ֻ��עʵʱ/��ʵʱ��,����Լ���ıȽ���,��ģ�͵IJ������ͼ�����Ҫ��ȽϿ���,���Ի����ϲ�����ģ�Ͷ����Լ���װ�úܡ�ǿ׳��,����֪�����õļ����ںϵ��Լ���ģ����,����һЩģ�ͻ�����ģ���������ϡ����Ա��˷dz�ϣ�����췽�ܹ�����һ��Сģ������,����Ѹ��Ӧ������ʵ,����ͨ��Ʒ�ʡ�
ʵ�ʹ�����,��Ҫģ�����,���ǵĿɲ�ֹ��Щ,Ŀǰ�˲���㷨����Ҫ��ȽϿ���,PC����һЩ,���ֻ���ƽ����Щ�豸���㷨�����Ҫ�����ϸ��ģ��ѡ�ͺͼ�֦��������
ģ��ѡ��,��Ҫ��ģ�͵�Ч��������������������ռ���ڴ��С��ʱ�ӵȷ������ֿ�ʼ���Dz������,��Ȼ��,���Сģ�;Ϳ������㽵���Ч������,�ǹ�ϲ��,������������IJ���,ȥѵ��ģ�͡����ϾͿ��Թ��̻�����ˡ����Сģ�Ͳ���work,�Ǿ���Ҫ��������豸�Ĵ洢�ռ�Ϳ�������,Ѱ�����ɸ�Ч��Զ������Ч������Ĵ�ģ��,Ȼ��ͨ��ѹ���ֶ�(��֦��������)��ģ�͵IJ������ͼ�����������,�����п��ܳ���Ч���½�������,�����һ�������Գ��ԵĴ�ĥ�����ˡ�
���Ľ���Щ��ľ����������������������Ĺؼ���������顢��Դ���붼����������,Ŀǰֻ�Ǽ�����,���������ÿһ��ģ����ϸ��������ת�������������������¡�ϣ�������������㷨��ѧϰ��Ӧ�ù�����������,�����ȷ�ĵط�,��������ָ����
�ɻ�����:��ӭ�ղص���
һ��ģ��ȫ��

����ģ�ͼ��
Conv-TasNet
Yi Luo, Nima Mesgarani
Conv-TasNet ��Yi Luo�ڼ�2017�����TasNet֮��,��һ�˵��˵���������ģ�͡�
ģ����Ҫ��һά�ն�������ʱ�����������ɡ�
1�� ģ�Ϳ�ͼ

2�� Ч�� 3������
3������
https://github.com/kaituoxu/Conv-TasNet
DC-U-Net
Hyeong-Seok Choi
Department of Transdisciplinary Studies, Seoul National University, Seoul, Korea
DC-Unet�������ȸ��������Unet���ŵ�����������ֵ��ͼ,���ø�����Ϣ�ڼ�����ϵ�¹��������ķ�ֵ����λ��ͬʱ�����weighted-SDR loss���÷�����ͨ�������������ȡ��������Ϣ,�Ӷ����½ϴ��ģ�ͺ��Ӷȡ�
1�� ģ�Ϳ��
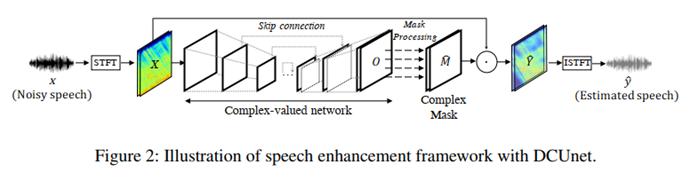
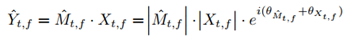
2��weighted-SDR loss

3����

4������
https://github.com/chanil1218/DCUnet.pytorch
DPRNN
Yi Luo??, Zhuo Chen?, Takuya Yoshioka?
?Department of Electrical Engineering, Columbia University, NY, USA
?Microsoft, One Microsoft Way, Redmond, WA, USA
DPRNN������������ָ�Ϊ��С�Ŀ�,��������Ӧ�ÿ��ںͿ��RNN��
1��ģ�Ϳ��

2����

3������
https://github.com/ShiZiqiang/dual-path-RNNs-DPRNNs-based-speech-separation
PHASEN
Dacheng Yin1, Chong Luo2, Zhiwei Xiong1, and Wenjun Zeng2
1University of Science and Technology of China
2Microsoft Research Asia
PHASEN����ȷ�����źŵķ�ֵ����λ��Ϣ�����������һ��˫������ṹ(TSB, two-stream block,����������λ��),����˫��֮������Ϣ����,����������TSBģ������IJ���;�����FTB(frequency transformation blocks)ģ��,���ڻ��Ƶ���ϵij�ʱ���ȵĹ�ϵ,FTB�ֲ���TSBģ��Ŀ�ʼ�ͽ���λ��,FTB��Ч����ȫ��Ƶ�������,������г�������,ͨ������ FTB �����Ŀ��ӻ�,���ǿ��Է��� FTB �Է���ѧ����г������ԡ���
1��ģ�Ϳ��

˫���ṹ��ǿ�����Լ���λ�����ɡ�����,ǿ������Ҫ�ɾ�������,Ƶ��任ģ��(FTB)�Լ�˫�� LSTM ���,����λ��Ϊ���������硣ǿ������Ԥ����Ϊ��ֵ��Ĥ M,��ȡֵΪ����ʵ��,��λ����Ԥ��������λ�צ�,��ȡֵΪ����,��ʵ�����鲿��ɡ��������ʱƵ����Ϊ S_in,����� S_out=abs(S_in )?M?�� ������,? ����������˲�����Ϊ�˳������˫������Ϣ,���� gating �ķ�ʽ��ǿ��������λ��֮����������Ϣ��������,�Ӷ���ǿ�Ȼ�����λ��������������������һ·����Ϣ��Ϊ�ο�����������Ϣ������,����������廮��Ϊ3�� Two Stream Block(TSB)��ÿһ�� TSB �Ľṹ��ͬ,�� TSB �����,����һ����Ϣ����������ʵ�����,˫�����Ϣ��������λԤ��������Ҫ��
�����ǿ�����Ĺ�����,����ͼ�����г��õ�С�ߴ��ά�������������������ź��е�г������ԡ���ͬ����Ȼͼ��,�����ź���ת��Ϊʱ-Ƶ����ʱ������Բ���������ɷ�,������г���ɷ�,����Щг���������һ�ֲַ���Ƶ���ϵ�ȫ�������,����:Ƶ�� f_0 �����ں� 2f_0,1/2 f_0,3f_0,3/2 f_0,1/3 f_0,2/3 f_0�� ��Щг����ص�Ƶ��ͬʱ����,��ЩƵ�ʷֲ�������Ƶ�����ϡ�֮ǰ�Ĺ�����ʹ�õ� U-net,�ն������Ⱦ����ṹ�������ڴ������������,��������Ч�ظ��ܵ�����ȫ��Ƶ������ԡ�Ϊ��,�����Ƶ��任ģ��(Frequency Transformation Block, FTB)����������г�����ڵ�ȫ��Ƶ������ԡ�
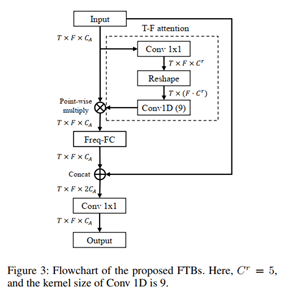
FTB �Ľṹ����ͼ��ʾ,����˵,������ע����(attention)�������ھ������(non-local)����ԡ�������ܹ���,ÿһ��TSB��ǿ���������������˸���һ�� FTB,ȷ��ÿһ�� TSB �д�������Ϣ�Լ�˫����������Ϣ���ܹ�ע��г������ԡ�
2����

3������
https://github.com/huyanxin/phasen
Demucs
Alexandre D��fossez Nicolas Usunier L��on Bottou
Facebook AI Research
Demucs��һ��waveform-to-waveform ģ��,��U-Net �ṹ��˫�� LSTM���ɡ�
1�� ģ�Ϳ��

2����

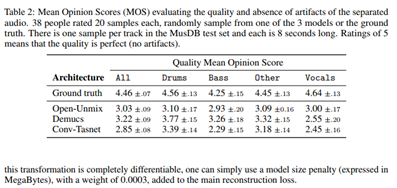
3������
https://github.com/facebookresearch/demucs
SuDoRM-RF
Efthymios Tzinis, Zhepei Wang, Paris Smaragdis
University of Illinois at Urbana-Champaign
Adobe Research
ȫ��:SUccessive DOwnsampling and Resampling of Multi-Resolution Features��ֱ��������������²������ز�����
��ģ��,a)���Բ�������Դ�����豸��,b)ѵ���ٶȿ�,��ʵ�����õķ�������,c)�����Ӳ�������ʱ�������õ���չ�ԡ�
�ʺ������ƶ��豸,�ܹ������ĸ�������������ڴ�Ҫ��Ͳ��������»�ø���������ƵԴ����ͽ�С��ʱ�ӡ�
1�� ģ�Ϳ��

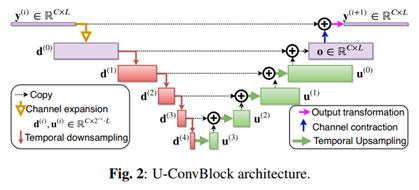
2����

3������
https://github.com/etzinis/sudo_rm_rf
DC-CRN
Yanxin Hu1;?, Yun Liu2;?, Shubo Lv1, Mengtao Xing1, Shimin Zhang1, Yihui Fu1, Jian Wu1, Bihong Zhang2, Lei Xie1
1Audio, Speech and Language Processing Group (ASLP@NPU), School of Computer Science, Northwestern Polytechnical University, Xi��an, China
2AI Interaction Division, Sogou Inc., Beijing, China
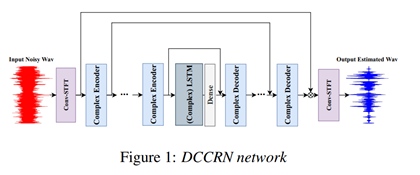
DCCRN�����DCUNET ��CRN������,����ͬ��ģ�Ͳ�����С�����,������1/6��DCUNET������,�ʹﵽ��DCUNET��Ч����
�ɾ�:Interspeech 2020 Deep Noise Suppression (DNS),ʵʱ������һ��,��ʵʱ�����ڶ�����
��ʵʱ�����ĵ�һ����Amazon��PoCoNetģ��,�����Ƿ�ʵʱ,�Ͳ�չ�������ˡ�

1�� ģ�Ϳ��

2����
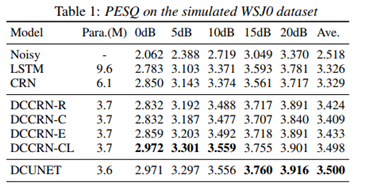
���Կ���DCCRN-CL ��DCUNET ������С��PESQָ�궼�ܽӽ�,����DCCRN-CL�ļ�������DCUNET��1/6��
3������
https://github.com/huyanxin/DeepComplexCRN
https://github.com/maggie0830/DCCRN
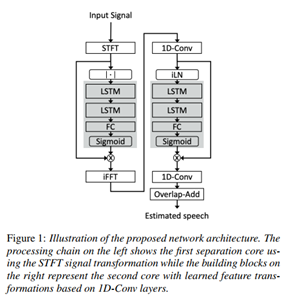
DTLN
Nils L. Westhausen and Bernd T. Meyer
Communication Acoustics & Cluster of Excellence Hearing4all Carl von Ossietzky University, Oldenburg, Germany
1�� ģ�Ϳ��
2����
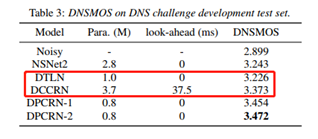
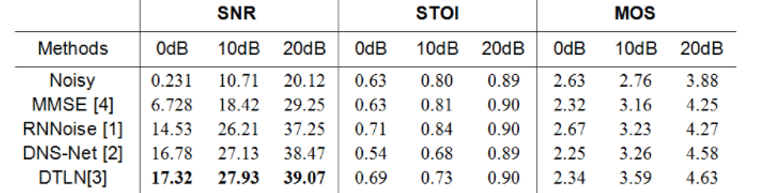
3������
https://github.com/breizhn/DTLN
Sepformer
Cem Subakan1, Mirco Ravanelli1, Samuele Cornell2, Mirko Bronzi1, Jianyuan Zhong3
1Mila-Quebec AI Institute, Canada, 2Universit`a Politecnica delle Marche, Italy 3University of Rochester, USA
��DPRNN��һ�������㷨,��Ҫ��multi-head attention �� feed-forward layers��ɡ�������DPRNN�����˫·�����,����RNN�滻Ϊa multiscale pipeline composed of transformers,����ѧϰ���ںͳ���������ϵ��
1�� ģ�Ϳ��

2����

3������
https://github.com/speechbrain/speechbrain/
SDD-Net
Andong Li1;2, Wenzhe Liu1;2, Xiaoxue Luo1;2, Guochen Yu1;3, Chengshi Zheng1;2, Xiaodong Li1;2
1Key Laboratory of Noise and Vibration Research, Institute of Acoustics, Chinese Academy of
Sciences, Beijing, China
2University of Chinese Academy of Sciences, Beijing, China
3Communication University of China, Beijing, China
Deep Noise Suppression Challenge �C INTERSPEECH 2021 ��һ��
1�� ģ�Ϳ��

2����

3��δ�ҵ���Դ����
DPCRN
Xiaohuai Le1;2;3, Hongsheng Chen1;2;3, Kai Chen1;2;3, Jing Lu1;2;3
1Key Laboratory of Modern Acoustics, Nanjing University, Nanjing 210093, China
2NJU-Horizon Intelligent Audio Lab, Horizon Robotics, Beijing 100094, China
3Nanjing Institute of Advanced Artificial Intelligence, Nanjing 210014, China
Deep Noise Suppression Challenge �C INTERSPEECH 2021 ������
1�� ģ�Ϳ��

2����
