本章小结:
首先加载sklearn中的内部的乳腺癌文件,再提取数据特征,分析已有的特征,如果特征值比较少,那么可以根据目前已有的特征构造新的特征。然后将数据集分为训练集和测试集,由于数据比较少,所以用20%的比例分离数据集,再用logistic回归算法进行预测,分别用degree = 1 或者 2 或者等等用来模拟数据,选出最适合的模型,再绘制学习曲线,对模型进行进一步的测试,最终选取合适的模型。
注意:如果特征值有差异过大,可以进行正则化表示。


导入需要的库
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
将数据集拆分
行569,列30,没有患乳腺癌的人数357,患乳腺癌的人数212
可以用print(cancer)找到文件下载的路径
# 载入数据
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
X = cancer.data
y = cancer.target
print('data shape: {0}; no. positive: {1}; no. negative: {2}'.format(
X.shape, y[y==1].shape[0], y[y==0].shape[0]))
print(cancer.data[0])
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)

特征名字
cancer.feature_names

模型训练
# 模型训练
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(solver='liblinear')
model.fit(X_train, y_train)
train_score = model.score(X_train, y_train)
test_score = model.score(X_test, y_test)
print('train score: {train_score:.6f}; test score: {test_score:.6f}'.format(
train_score=train_score, test_score=test_score))
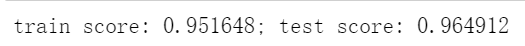
看有多少预测成功
# 样本预测
y_pred = model.predict(X_test)
print('matchs: {0}/{1}'.format(np.equal(y_pred, y_test).sum(), y_test.shape[0]))
找出低于 90% 概率的样本个数
# 预测概率:找出低于 90% 概率的样本个数
y_pred_proba = model.predict_proba(X_test)
print('sample of predict probability: {0}'.format(y_pred_proba[0]))
y_pred_proba_0 = y_pred_proba[:, 0] > 0.1
result = y_pred_proba[y_pred_proba_0]
y_pred_proba_1 = result[:, 1] > 0.1
print(result[y_pred_proba_1])

增加多项式处理
import time
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
# 增加多项式预处理
def polynomial_model(degree=1, **kwarg):
polynomial_features = PolynomialFeatures(degree=degree,
include_bias=False)
logistic_regression = LogisticRegression(**kwarg)
pipeline = Pipeline([("polynomial_features", polynomial_features),
("logistic_regression", logistic_regression)])
return pipeline
model = polynomial_model(degree=2, penalty='l1', solver='liblinear')
start = time.perf_counter()
model.fit(X_train, y_train)
train_score = model.score(X_train, y_train)
cv_score = model.score(X_test, y_test)
print('elaspe: {0:.6f}; train_score: {1:0.6f}; cv_score: {2:.6f}'.format(
time.perf_counter()-start, train_score, cv_score))
logistic_regression = model.named_steps['logistic_regression']
print('model parameters shape: {0}; count of non-zero element: {1}'.format(
logistic_regression.coef_.shape,
np.count_nonzero(logistic_regression.coef_)))

学习曲线绘制
from common.utils import plot_learning_curve
from sklearn.model_selection import ShuffleSplit
cv = ShuffleSplit(n_splits=10, test_size=0.2, random_state=0)
title = 'Learning Curves (degree={0}, penalty={1})'
degrees = [1, 2]
penalty = 'l1'
start = time.perf_counter()
plt.figure(figsize=(12, 4), dpi=144)
for i in range(len(degrees)):
plt.subplot(1, len(degrees), i + 1)
plot_learning_curve(plt, polynomial_model(degree=degrees[i], penalty=penalty, solver='liblinear', max_iter=300),
title.format(degrees[i], penalty), X, y, ylim=(0.8, 1.01), cv=cv)
print('elaspe: {0:.6f}'.format(time.perf_counter()-start))

python的warnings模块

import warnings
warnings.filterwarnings("ignore")
penalty = 'l2'
start = time.perf_counter()
plt.figure(figsize=(12, 4), dpi=144)
for i in range(len(degrees)):
plt.subplot(1, len(degrees), i + 1)
plot_learning_curve(plt, polynomial_model(degree=degrees[i], penalty=penalty, solver='lbfgs'),
title.format(degrees[i], penalty), X, y, ylim=(0.8, 1.01), cv=cv)
print('elaspe: {0:.6f}'.format(time.perf_counter()-start))
