数据集
下载链接在这
https://download.pytorch.org/tutorial/faces.zip
数据集的位置可以与你编写的脚本放在一个文件夹下。红色矩形框是你下载的数据集,红色矩形框+红色椭圆框是编写的python脚本。
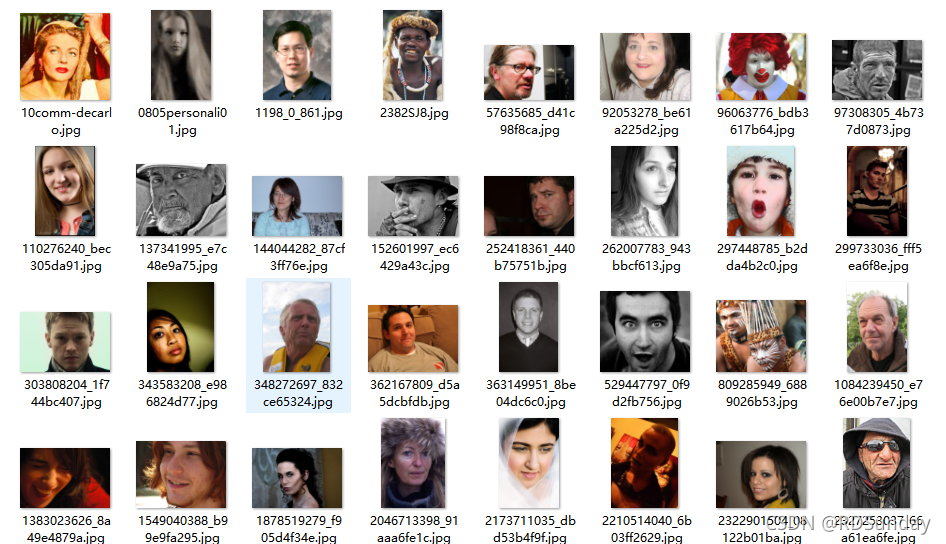
数据集就长下面这样。
对数据集进行操作
下面代码我都进行了注释可以直接复制到自己建的python文件进行运行。很容易看明白
from __future__ import print_function, division
import os
import torch
import pandas as pd #用于更容易地进行csv解析
from skimage import io, transform #用于图像的IO和变换
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
# 忽略警告
import warnings
warnings.filterwarnings("ignore")
plt.ion() # interactive mode
landmarks_fram = pd.read_csv('faces/face_landmarks.csv')
n =65 #表示第65张图条,
print(landmarks_fram) #打印的是数据集中的图片的信息,例如图片的名称,图片照片那个标注的坐标信息
img_name = landmarks_fram.iloc[n,0] #表示的是打印第65行的第0列的信息,也就是第65张图片的名称
print("@@@@@@@@@@@@@@")
print(img_name) #打印的是图片的名称
landmarks = landmarks_fram.iloc[n, 1:].to_numpy() #表示person-7.jpg图片的第1列到最后一列的数值
print("下面是landmarks!")
print(landmarks)
landmarks = landmarks.astype('float').reshape(-1, 2)
print("下面是把landmarks数据类型变成float,并且转成2列的矩阵111111111")
print(landmarks)
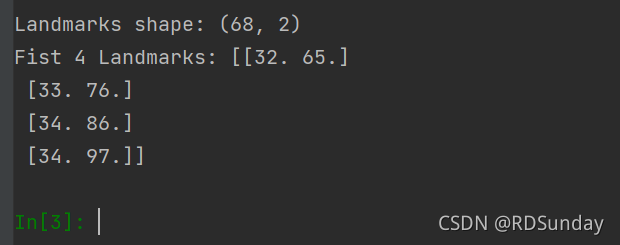
print('Landmarks shape: {}'.format(landmarks.shape))
print('Fist 4 Landmarks: {}'.format(landmarks[:4]))
def show_landmarks(image,landmarks):
"""显示带有地标的图片 """
plt.imshow(image)
# 绘制散点图,landmarks[:,0]表示的是X的坐标,landmarks[:,1]表示的是y的坐标
plt.scatter(landmarks[:, 0], landmarks[:, 1], s=10, marker='.', c='r')
plt.pause(0.001) # pause a bit so that plots are updated
plt.figure()
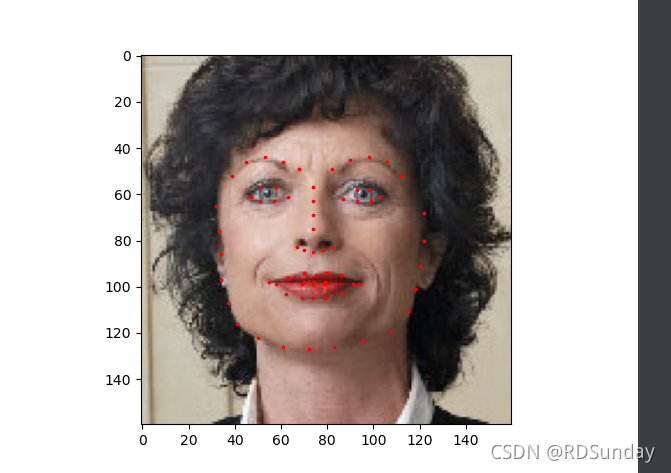
show_landmarks(io.imread(os.path.join('faces/',img_name)),landmarks)
# print(io.imread(os.path.join('faces/'),1))
plt.show()
运行结果如下
建立数据集类,图形展示结果
class FaceLandmarksDataset(Dataset):
"""面部标记数据集."""
def __init__(self, csv_file, root_dir, transform=None):
"""
csv_file(string):带注释的csv文件的路径。
root_dir(string):包含所有图像的目录。
transform(callable, optional):一个样本上的可用的可选变换
"""
self.landmarks_frame = pd.read_csv(csv_file)
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.landmarks_frame)
def __getitem__(self, idx):
img_name = os.path.join(self.root_dir,
self.landmarks_frame.iloc[idx, 0])
image = io.imread(img_name)
landmarks = self.landmarks_frame.iloc[idx, 1:]
landmarks = np.array([landmarks])
landmarks = landmarks.astype('float').reshape(-1, 2)
sample = {'image': image, 'landmarks': landmarks}
if self.transform:
sample = self.transform(sample)
return sample
face_dataset = FaceLandmarksDataset(csv_file='faces/face_landmarks.csv',root_dir='faces/')
fig = plt.figure()
for i in range(len(face_dataset)):
sample = face_dataset[i] # 因为有__getitem__ 方法,所以可以查看索引,返回字典,即第i个样本的image和landmarke
print(i,sample['image'].shape,sample['lanmarks'].shape)
ax = plt.subplot(1,4,i+1) # 1是横坐标,4是纵坐标,i+1是它的摆放顺序
plt.tight_layout()
ax.set_title('Sample #{}'.format(i))
ax.axis('off')
show_landmarks(**sample) # 因为sample为字典,所以可以利用这种形式返回字典中所有键对应的值
if i ==3:
plt.show()
break
结果


完整的代码
完整的代码包含了, 将样本中的数据缩放到指定大小,随机裁剪样本中的图像,在样本上应用上述的每个变换,辅助功能:显示批次。
from __future__ import print_function, division
import os
import torch
import pandas as pd #用于更容易地进行csv解析
from skimage import io, transform #用于图像的IO和变换
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
# 忽略警告
import warnings
warnings.filterwarnings("ignore")
plt.ion() # interactive mode
landmarks_fram = pd.read_csv('faces/face_landmarks.csv')
n =65 #表示第65张图条,
print(landmarks_fram) #打印的是数据集中的图片的信息,例如图片的名称,图片照片那个标注的坐标信息
img_name = landmarks_fram.iloc[n,0] #表示的是打印第65行的第0列的信息,也就是第65张图片的名称
print("@@@@@@@@@@@@@@")
print(img_name) #打印的是图片的名称
landmarks = landmarks_fram.iloc[n, 1:].to_numpy() #表示person-7.jpg图片的第1列到最后一列的数值
print("下面是landmarks!")
print(landmarks)
landmarks = landmarks.astype('float').reshape(-1, 2)
print("下面是把landmarks数据类型变成float,并且转成2列的矩阵111111111")
print(landmarks)
print('Landmarks shape: {}'.format(landmarks.shape))
print('Fist 4 Landmarks: {}'.format(landmarks[:4]))
def show_landmarks(image,landmarks):
"""显示带有地标的图片 """
plt.imshow(image)
# 绘制散点图,landmarks[:,0]表示的是X的坐标,landmarks[:,1]表示的是y的坐标
plt.scatter(landmarks[:, 0], landmarks[:, 1], s=10, marker='.', c='r')
plt.pause(0.001) # pause a bit so that plots are updated
plt.figure()
show_landmarks(io.imread(os.path.join('faces/',img_name)),landmarks)
# print(io.imread(os.path.join('faces/'),1))
plt.show()
# 所有的图片都在同一个文件夹中,这种情况一般会有labels的文本数据,
# 在这种情况下我们一般会用到torch.utils.data.Dataset,
# 继承Dataset类,并重载__init__, __len__, __getitem__三个函数,
class FaceLandmarksDataset(Dataset):
"""面部标记数据集."""
def __init__(self, csv_file, root_dir, transform=None):
"""
csv_file(string):带注释的csv文件的路径。
root_dir(string):包含所有图像的目录。
transform(callable, optional):一个样本上的可用的可选变换
"""
self.landmarks_frame = pd.read_csv(csv_file)
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.landmarks_frame)
def __getitem__(self, idx):
img_name = os.path.join(self.root_dir,
self.landmarks_frame.iloc[idx, 0])
image = io.imread(img_name)
landmarks = self.landmarks_frame.iloc[idx, 1:]
landmarks = np.array([landmarks])
landmarks = landmarks.astype('float').reshape(-1, 2)
sample = {'image': image, 'landmarks': landmarks}
if self.transform:
sample = self.transform(sample)
return sample
face_dataset = FaceLandmarksDataset(csv_file='faces/face_landmarks.csv',
root_dir='faces/')
fig = plt.figure()
for i in range(len(face_dataset)):
sample = face_dataset[i]
print(i, sample['image'].shape, sample['landmarks'].shape)
ax = plt.subplot(1, 4, i + 1)
plt.tight_layout()
ax.set_title('Sample #{}'.format(i))
ax.axis('off')
show_landmarks(**sample)
if i == 3:
plt.show()
break
#图片大小不一,通过如下变换对图片进行预处理:
class Rescale(object):
''''
将样本中的数据缩放到指定大小
args:
output_size(tuple或者int):所需的大小。如果是元祖,测输出
'''
def __init__(self,output_size):
assert isinstance(output_size,(int,tuple))
self.output_size = output_size
def __call__(self, sample):
image,landmarks = sample['image'],sample['landmarks']
h,w = image.shape[:2]
if isinstance(self.output_size,int):
if h > w:
new_h, new_w = self.output_size * h/w,self.output_size
else:
new_h,new_w = self.output_size,self.output_size * w/h
else:
new_h,new_w = self.output_size
new_h,new_w = int(new_h),int(new_w)
img = transform.resize(image,(new_h,new_w))
landmarks = landmarks * [new_w/w, new_h / h]
return {'image':img,'landmarks': landmarks}
class RandomCrop(object):
'''
随机裁剪样本中的图像
'''
def __init__(self,output_size):
assert isinstance(output_size,(int,tuple))
if isinstance(output_size,int):
self.output_size = (output_size,output_size)
else:
assert len(output_size) == 2
self.output_size = output_size
def __call__(self, sample):
image,landmarks = sample['image'],sample['landmarks']
h , w = image.shape[:2]
new_h, new_w = self.output_size
top = np.random.randint(0, h - new_h)
left = np.random.randint(0, w - new_w)
image = image[top: top + new_h,
left: left + new_w]
landmarks = landmarks - [left, top]
return {'image': image, 'landmarks': landmarks}
class ToTensor(object):
"""将样本中的ndarrays转换为Tensors."""
def __call__(self, sample):
image, landmarks = sample['image'], sample['landmarks']
# 交换颜色轴因为
# numpy包的图片是: H * W * C
# torch包的图片是: C * H * W
image = image.transpose((2, 0, 1))
return {'image': torch.from_numpy(image),
'landmarks': torch.from_numpy(landmarks)}
scale = Rescale(256)
crop = RandomCrop(128)
composed = transforms.Compose([Rescale(256),
RandomCrop(224)])
# 在样本上应用上述的每个变换。
fig = plt.figure()
sample = face_dataset[65]
for i, tsfrm in enumerate([scale, crop, composed]):
transformed_sample = tsfrm(sample)
ax = plt.subplot(1, 3, i + 1)
plt.tight_layout()
ax.set_title(type(tsfrm).__name__)
show_landmarks(**transformed_sample)
plt.show()
transformed_dataset = FaceLandmarksDataset(csv_file='faces/face_landmarks.csv',
root_dir='faces/',
transform=transforms.Compose([
Rescale(256),
RandomCrop(224),
ToTensor()
]))
for i in range(len(transformed_dataset)):
sample = transformed_dataset[i]
print(i, sample['image'].size(), sample['landmarks'].size())
if i == 3:
break
dataloader = DataLoader(transformed_dataset, batch_size=4,
shuffle=True, num_workers=0)
# 辅助功能:显示批次
def show_landmarks_batch(sample_batched):
"""Show image with landmarks for a batch of samples."""
images_batch, landmarks_batch = \
sample_batched['image'], sample_batched['landmarks']
batch_size = len(images_batch)
im_size = images_batch.size(2)
grid_border_size = 2
grid = utils.make_grid(images_batch)
plt.imshow(grid.numpy().transpose((1, 2, 0)))
for i in range(batch_size):
plt.scatter(landmarks_batch[i, :, 0].numpy() + i * im_size + (i + 1) * grid_border_size,
landmarks_batch[i, :, 1].numpy() + grid_border_size,
s=10, marker='.', c='r')
plt.title('Batch from dataloader')
for i_batch, sample_batched in enumerate(dataloader):
print(i_batch, sample_batched['image'].size(),
sample_batched['landmarks'].size())
# 观察第4批次并停止。
if i_batch == 3:
plt.figure()
show_landmarks_batch(sample_batched)
plt.axis('off')
plt.ioff()
plt.show()
break
效果如下

