上一篇文章谈到如何简便的使用bert, simpletransformers好用是好用,但延展性、灵活性不足,主要是很难加入各种自定义特性(比如pipeline、和数值型特征混合使用等)。
基于此,本篇文章就来谈谈,如何通过继承Scikit Learn中的两个基类 ---?TransformerMixin和BaseEstimator来实现一个高度定制化且易用的BERT特征提取器。
本教程的目的是用BERT和Sci-kit Learn建立一个最简单的句子级分类的例子。笔者不打算详细讨论BERT是什么,也不打算讨论它的内部机理,笔者只是想以最小的工作量向你展示如何利用Sci-kit Learn来“二次开发”bert特征抽取器,兼顾易用性和灵活性。
做好这个bert特征抽取器以后,笔者将用一个文本情绪分类数据集来检验一下经封装的Sci-kit Learn transformer的实际效果。
如无问题,我们可以在任何现有的Sci-kit Learn的pipeline上只需插入一行代码就可以玩转bert。
????????
????????对于NLP领域来说,文本表示就是不将文本视为字符串,而视为在数学上处理起来更为方便的向量。如何将字符串变为包含语义关联性的向量,就是文本表示的核心问题。BERT是一个在海量文本上训练的深度转化模型。海量的预训练结合模型架构和一些巧妙的训练技巧,使BERT能够学习到NLP任务中"比较好"的特征。
在这里,我们将使用基于PyTorch的transformers(https://github.com/huggingface/transformers )来创建一个可复用的特征提取器。
同时,我们可以将封装好的bert特征提取器嵌入到任何Sci-kit Learn流程中。
更多关于BERT工作原理的信息,可以阅读Jay Alamar关于BERT原理(http://jalammar.github.io/illustrated-bert ) 和如何使用BERT(http://jalammar.github.io/a-visual-guide-to-using-bert-for-the-first-time/?)的2篇优秀博客文章。
一,创建一个基于Sci-kit Learn的BERT特征提取器
代码环节:
首先,载入必要的库:
import torch
import pandas as pd
import numpy as np
from transformers import BertTokenizer,BertModel
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression,SGDClassifier
from sklearn import preprocessing
from sklearn import metrics
from sklearn import svm1,Totenization
(1)定义一个自己想要的tokenizer,(2)运行encode_plus方法。它可以让我们设置各类参数,比如 maximum size(语句最大长度)和special characters(是否包含特殊字符)等。
#tokenizer = BertTokenizer.from_pretrained(r"E:\bert-base-uncased")#不能上网就用本地的。
tokenizer=BertTokenizer.from_pretrained('bert-base-uncased') #定义了我们想要的 tokenizer
# encode_plus 方法,它可以让我们设置各类参数,
# 比如 maximum size(语句最大长度)和special characters(是否包含特殊字符)等。
tokenized_dict=tokenizer.encode_plus( "hi my name is nicolas",add_special_tokens=True,max_length=5)
print(tokenized_dict['input_ids'])
?从结果中可以看到,101,102对于BERT模型来说,添加了一个[CLS]“类”token和一个[SEP]“类”token,这两个token也算到最大序列长度里,所以这里只显示了3个单词的token。这两个token对maximum size值为5会有影响,所以我们最终会丢掉两个词汇,这是需要着重注意的地方。
在返回的结果字典中,我们只需要?input_ids?字段,这个字段持有我们将传递给 BERT 模型的令牌化单词的整型编码。CLS token表征整个语句嵌入,separator toekn用来告诉BERT下一个新的句子将出现。
对于我们的基本句子分类任务,我们将使用CLS嵌入作为特征集合(the set of features)。
2, Model
下一步是使用BERT模型生成语句嵌入。同样, transformers 库为我们完成了大部分工作。我们可以创建一个简单的BERT模型,然后在我们的tokenized 输出上运行预测。
bert_model=BertModel.from_pretrained('bert-base-uncased')
tokenized_text=torch.tensor(tokenized_dict['input_ids'])
#对于tensor张量的计算操作,需要构建计算图。(计算过程的构建,以便梯度反向传播等操作)
# no_grad()表示不进行计算图构建。
with torch.no_grad():
embeddings=bert_model(torch.tensor(tokenized_text.unsqueeze(0))) #在0维度增加一个维度。(5)->(1,5)
print(embeddings[0][:,0,:].shape)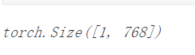 ?
?
BERT模型需要接受一个张量,其形式为 [batch_size , sentence_length],这意味着我们需要unsqueeze 把一维矩阵扩充维度。
另外注意这里我们如何使用torch.no_grad()。第一次处理大批量的样本时,如果忘了这个操作,会导致电脑的内存被占用完,电脑由此也会变得奇卡无比~所以在运行预测之前记得关闭梯度,否则你会保存太多的梯度信息,运行速度会变得极度糟糕!
embeddings返回的tuple默认有两个字段,第一个是矩阵,形如:
批量大小×句子长度×嵌入维度
对于基本的BERT模型和我们的例子,最终是[1, 5, 768]。第一个张量持有我们感兴趣的分类所需的嵌入。
第二个张量是集合输出。池输出是在训练下一个句子时,经过线性层和Tanh激活函数后的[CLS]嵌入。在本文中,可以对第二个忽略不计。

?
3, 抽取embeddings
为了完成我们的 BERT 特征提取器,我们最后需要的是将最终的嵌入物组合成一个单一的向量,用于分类。
对于大多数分类任务,你只需要抓取[CLS] token 对应的嵌入就可以做得很好。我们可以用下面这个函数来操作:
get_cls = lambda x: x[0][:, 0, :]?取出所有批次的句子中的第一个(也就是[CLS])token对应的嵌入(embeddings)。
注意,如果是上面这样,运行程序会维度错误,这里需要将维度(batch_size,output_size)变成一维的,用:
get_cls = lambda x:torch.flatten(x[0][:, 0, :])但是,也许你想更“花哨”地使用其他功能。比方说你想用所有的内嵌神经元来做预测:
flatten_embed = lambda x: torch.flatten(x[0])
4,?建立一个基于Sci-kit Learn的Bert文本特征抽取器 ---?BertTransformer
我们只需要上述三个基本组件就可以得到一个语句嵌入。创建一个新类,叫做BertTransformer,它继承自BaseEstimator和TransformerMixin,然后把我们上面工作过的代码作为tokenization步骤和prediction步骤放进去。
这样我们只需将一个文本列表传递给它,调用transform函数,我们的分类器就可以开始学习了。
from typing import Callable,List,Optional,Tuple
import pandas as pd
from sklearn.base import TransformerMixin,BaseEstimator
import torch
class BertTransformer(BaseEstimator,TransformerMixin):
def __init__(self,bert_tokenizer,bert_model,max_length:int=60,device='cuda',
embedding_func:Optional[Callable[[torch.tensor],torch.tensor]]=None,):
self.tokenizer=bert_tokenizer
self.device=device
self.model=bert_model.to(self.device)
self.model.eval()
self.max_length=max_length
self.embedding_func=embedding_func
if self.embedding_func is None:
self.embedding_func=lambda x: torch.flatten(x[0][:, 0, :])
def _tokenize(self,text:str) -> Tuple[torch.tensor,torch.tensor]:
tokenized_text=self.tokenizer.encode_plus(text,add_special_tokens=True,
max_length=self.max_length)['input_ids']
attention_mask=[1]*len(tokenized_text)
return(torch.tensor(tokenized_text).unsqueeze(0).to(self.device),
torch.tensor(attention_mask).unsqueeze(0).to(self.device),
)
def _tokenize_and_predict(self,text:str) -> torch.tensor:
tokenized,attention_mask=self._tokenize(text)
embeddings = self.model(tokenized, attention_mask)
return self.embedding_func(embeddings)
def transform(self, text: List[str]):
if isinstance(text, pd.Series):#判断是否为数组,是数组,就要转为list列表。
text = text.tolist()
with torch.no_grad(): # 把每一句的第一个[CLS]token的embedding拼接到一起。stack是增加新的维度进行堆叠.
return torch.stack([self._tokenize_and_predict(string) for string in text])
def fit(self, X, y=None):
"""不需要拟合数据,返回自身即可"""
return self二,在情绪分类数据集上测试效果
1,载入数据和数据预处理
(1)载入数据集。
数据集:
figure8_df=pd.read_csv('情感分类数据集.csv',header=None,names=["sentiment","content",])#读表时,可以自己加一下每一列的名字
print(figure8_df['sentiment'])
#检视所有的类别
print(np.unique(figure8_df['sentiment'].tolist()))

?(2)
将标签映射为整形数值,便于分类器读入。
对整个数据集的标签进行离散化处理。
#将标签映射为整形数值,便于分类器读入。
le=preprocessing.LabelEncoder()
le.fit(np.unique(figure8_df['sentiment'].tolist()))
#对整个数据集的标签进行离散化处理。
figure8_df["sentiment"] =figure8_df["sentiment"].apply(lambda x:le.transform([x])[0])
print(figure8_df.head(15))?
?
?(3)将数据随机分成70%的训练集、15%的验证集和15%的测试集。
split = np.random.choice(
["train", "val", "test"],
size=figure8_df.shape[0],
p=[0.70, 0.15, 0.15]
)
print('标签值标准化:%s' % le.transform(["anger", "disgust", "fear","guilt",'joy']))
print('标准化标签值反转:%s' % le.inverse_transform([0, 2 ,0 ,1 ,2]))
figure8_df["split"] = split
x_train = figure8_df[figure8_df["split"] == "train"]
y_train = x_train["sentiment"]
x_test = figure8_df[figure8_df["split"] == "test"]
y_test = x_test["sentiment"]
x_val = figure8_df[figure8_df["split"] == "val"]
y_val = x_val["sentiment"]
print(x_train.shape,y_train.shape,x_test.shape,y_test.shape,x_val.shape,y_val.shape) ?
?

?
2,训练模型
训练模型很简单。我们只需要定义一个pipeline,用一个transformer和一个estimator就可以了。
bert_transformer=BertTransformer(tokenizer,bert_model)
classifier=SGDClassifier()
model=Pipeline([('vectorizer',bert_transformer),#里面是实例化的对象。
('classifier',classifier),])
model.fit(x_train["content"].tolist(), y_train.tolist())3,检测模型预测效果
predictions = model.predict(x_test["content"].tolist())
print("Confusion Matrix:")
print(metrics.confusion_matrix(y_test,predictions))这个模型只使用了BERT变换器的CLS嵌入和一个SVM。

类似下图这样的矩阵,对角线值最大,意味着每个类别区别正确。neutral被归为neutral.....

三,扩展
?如果我们也想要一些经典的TF-IDF特征呢?只需要做一个特征联合(feature union),然后传递给分类器。
from sklearn.pipeline import FeatureUnion
from sklearn.feature_extraction.text import (
CountVectorizer, TfidfTransformer
)
tf_idf = Pipeline([
("vect", CountVectorizer()),
("tfidf", TfidfTransformer())
])
model = Pipeline([
("union", FeatureUnion(transformer_list=[
("bert", bert_transformer),
("tf_idf", tf_idf)
])),
("classifier", classifier),
])
model.fit(x_train.tolist(), y_train.tolist())
总结:
?可以轻松的将基本BERT的功能插入到任何Sci-kit Learn模型中。
?只需要定义BERT模型,并将其作为一个“特征化(faturization)”步骤添加到pipline中即可。Sci-kit Learn会处理剩下的事情。
?