RL-GAN-Net: A Reinforcement Learning Agent Controlled GAN Network for Real-Time Point Cloud Shape Completion
1.题目
RL-GAN-Net: A Reinforcement Learning Agent Controlled GAN Network for Real-Time Point Cloud Shape Completion
RL-GAN-Net:一种用于实时点云形状完成的强化学习Agent控制GAN网络
2.作者

代码
3. 引言
我们提出了RL-GAN网络,其中强化学习(RL)代理提供生成式对抗网络(GAN)的快速和鲁棒控制。我们的框架应用于点云形状完成,通过控制GAN将有噪声的部分点云数据转换为高保真的完成形状。虽然氮化镓很不稳定,也很难训练,我们绕过这个问题通过(1)训练GAN潜在空间表示的尺寸相比减少了原始点云输入和(2)使用一个gan RL代理来找到正确的输入生成的潜在空间表示的形状,最适合当前输入不完整的点云。建议的管道健壮地完成了大量缺失区域的点云。据我们所知,这是第一次尝试训练RL agent来控制GAN,它有效地学习了GAN输入噪声到点云潜在空间的高度非线性映射。RL代理取代了复杂优化的需要,从而使我们的技术实时。此外,我们还演示了我们的管道可以用来提高缺失数据点云的分类精度。
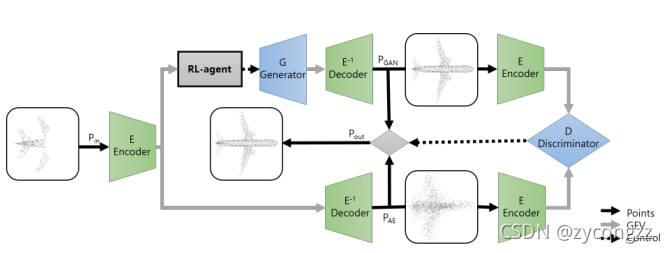
图2:形状完井网络的前向传递。通过观察编码的部分点云,我们的rl -GAN网为潜在的GAN选择一个合适的输入,并生成一个清洁的形状编码。对合成的潜在表示进行解码,实时得到完整的点云。在我们的混合版本中,鉴别器最终选择最佳形状。
4.方法
我们的形状完成管道由三个基本的构建模块组成,即自动编码器(AE)、潜空间生成对抗网络(l-GAN)和强化学习(RL) agent。每个组成部分都是一个深度神经网络,必须单独训练。我们首先训练AE,并使用编码数据训练- gan。RL剂与预先训练的AE和GAN一起训练。我们方法的前向传递如图2所示。训练后的声发射编码器将噪声和不完整的点云编码为噪声全局特征向量(GFV)。在这种嘈杂的GFV下,我们训练过的RL代理会为- gan的发生器选择正确的种子。生成器生成干净的GFV,最后通过AE的解码器得到干净的GFV的完整点云表示。鉴别器观察生成的形状和经过声发射处理的形状的GFV,选择更合理的形状。在下面的小节中,我们将解释我们方法的三个基本构建块,然后描述组合的体系结构。
4.1 Autoencoder (AE)
AE通过训练一个复制输入的网络来创建输入数据的低维编码。AE由编码器和解码器组成。编码器将复杂的输入转换为编码表示,解码器将编码版本还原为原始维度。我们将有效的中间表示称为GFV,它是通过训练AE获得的。AE的训练是通过反向传播来减少输入和输出点云之间的距离,使用EMD (Earth Movers distance, EMD)[36]或Chamfer距离[10,1]。由于倒角距离的效率,我们在EMD上使用倒角距离,其定义如下:
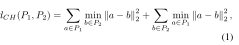
式(1)中p1p2分别为输入点云和输出点云。我们首先在ShapeNet点云数据集上训练一个类似于Achlioptas等人[1]所报道的网络[40,6]。Achlioptas等人的[1]也证明了经过训练的声发射可以用于形状补全。训练过的解码器将GFV映射到一个完整的点云,即使输入的GFV是由一个不完整的点云生成的。但随着输入中缺失数据的百分比增加,性能急剧下降(图14)。
l-GAN
GAN通过联合训练一对生成器和鉴别器[13]来生成新的但真实的数据。虽然GAN在图像生成任务中证明了它的成功[42,14,2],但在实践中,训练GAN往往是不稳定的,会出现模式坍塌[26]。Achlioptas等人的[1]研究表明,与在原始点云上训练GAN相比,在GFV或潜在表征上训练GAN会获得更稳定的训练结果。同样,我们也在GFV上训练GAN, GFV是使用训练过的AE 3.1节的编码器从完整的点云数据转换而来的。该生成器从噪声种子合成一个新的GFV,然后使用AE解码器将其转换成完整的3D点云。我们将网络称为l- gan或潜型gan。Gurumurthy等人的[15]也同样使用了l- gan来完成点云形状。他们制定了一个优化框架,以找到生成器的最佳输入,以创建最佳解释输入处不完整点云的GFV。然而,由于原始点与GFV之间的映射是高度非线性的,优化不能写成简单的反向传播。相反,能量项是三个损失项的组合。我们将损失列在下面,其中epinis不完全点云输入,E和E?1分别为AE的编码器和解码器,and and d分别为gan的生成器和鉴别器。
倒角损耗:输入部分点云P in和生成解码点云 E^?1(G(z))

Gurumurthy等人[15]对定义为损失加权和的能量函数进行了优化,权值随着每次迭代逐渐演化。然而,我们提出了一个使用RL框架的更鲁棒的GAN控制,其中RL代理通过观察损失的组合迅速找到GAN的z输入。
4.3 强化学习(RL)
在典型的基于rl的框架中,代理在环境中起作用。在每个时间步骤t给定一个观察值,代理执行一个动作并收到一个奖励。agent网络学习到一个策略π,它以一定的概率将状态映射到动作上。环境可以建模为马尔可夫决策过程,即当前状态和行动只依赖于以前的状态和行动。任何给定状态下的报酬为贴现后的未来报酬Rt=PT i=tγ(i?t)r(si, ai)。最终目标是找到一种能够提供最大回报的政策。
我们在RL框架中制定形状完成任务,如图3所示。对于我们的问题,环境是声发射和l- gan的结合,所产生的损失作为各种网络的中间结果计算,以及输入和预测形状之间的差异。观测统计量是从不完全输入点云编码的初始噪声GFV。我们假设环境是马尔可夫的,并且完全被观察到;也就是说,最近的最近的观察足以定义状态。代理执行一个动作,为生成器的z-space输入选择正确的种子。然后将合成的GFV通过解码器获得完整的点云形状。
训练RL代理的主要任务之一是正确地制定奖励函数。根据行动的质量,环境会给予行动者奖励。在RL-GAN-Net中,正确的决策等同于对生成器进行正确的种子选择。我们使用负损失函数的组合作为形状完成任务15的奖励,该任务表示在所有笛卡尔坐标(rCH=?LCH)、潜在空间(rGF V=?LGF V)和从判别器(rD=?LD)的角度上的损失。最终奖励条件如下:
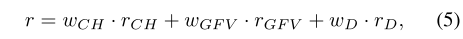
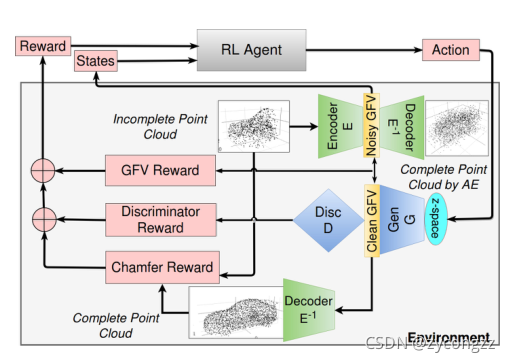
图3:训练RL-GAN-Net完成形状。我们的RL框架使用AE(绿色表示)和l- gan(蓝色表示)。RL代理和环境是灰色的,嵌入式奖励、状态和行动空间是红色的。输出被解码并完成,如下所示。注意右上角的解码器和解码点云是为了比较而添加的,不影响训练。通过使用RL代理,我们的管道能够实时完成形状。
其中ch、wGF V、wdare为每个损失函数分配了相应的权重。我们在补充材料中解释了权重的选择。由于行为空间是连续的,我们采用Lillicrap et al.[24]的深度确定性策略梯度(deep deterministic policy gradient, DDPG)。在DDPG算法中,参数化的参与者网络μ(s| θμ)学习特定的策略,并以确定的方式将状态映射到特定的动作。评论家网络Q(s, a)使用Bellman方程,并提供行动质量和状态的衡量。行动者网络的训练方法是找出行动者网络参数对成本的梯度的期望回报,也称为策略梯度。可以定义为:
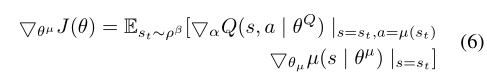
在培训代理商之前,我们要确保AE和GAN都经过了充分的预培训,因为它们构成了环境。代理依靠它们来选择正确的操作。具体的训练过程的算法在算法1中进行了总结。

4.4 Hybrid RL-GAN-Net
使用上面描述的普通实现,生成的完整点云的细节有时会有有限的语义变化。当缺失数据的部分相对较小时,声发射通常可以完成与输入点云更吻合的形状。另一方面,声发射性能显著下降。
随着更多的数据丢失,我们的RL-agent仍然可以找到正确的语义形状。基于这一观察,我们提出了一种混合方法,使用一个鉴别器作为开关,从香草rlgan网和AE中选择最佳结果。我们最终使用的结果管道如图2所示。我们的混合方法可以在保留局部细节的同时,鲁棒地实时完成语义形状。
5.0 实验

图4:点云形状完成的定性结果缺失了20%的原始点。由于丢失的数据相对较少,AE有时在完成形状时表现得更好。因此,我们的混合RL-GAN-Net在AE和香草RL-GAN-Net中可靠地选择了最佳输出形状。
5.1 完成情况
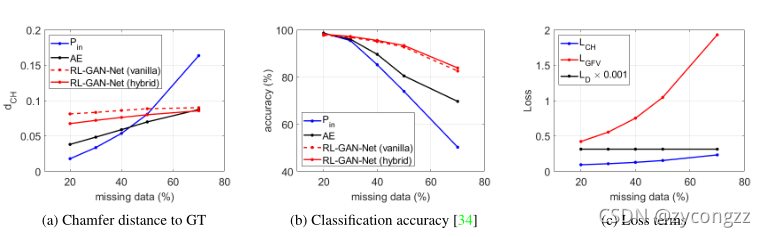
Figure 5:Performance analysis.We compare the two versions of our algorithms against the original input and the AE in terms of (a) the
Chamfer distance (the lower the better) and (b) the performance gain for shape classification (the higher the better). ? We also analyze
the losses of RL-GAN-Net with different amount of missing data.