第四篇,我们已经简单的过了一个segmentation网络,下面我们要进入一个相对要复杂一点的系列了,它也是用于目标检测的,与segmentation不同的是,这个网络会回归出目标的位置和大小。YOLO的全程是 You Only Look Once,它的作者是“小马哥”,这里我先表达一下对小马哥敬意和崇拜,真的是大隐隐于的大神,目前他已经官宣退出CV界,原因是居然后小时候看的动画片里的火箭队一样,维护世界和平,点赞,下面给你看看他的简历,你就知道他为什么叫小马哥了。
同时,YOLO在我看来也可以叫做 You Only Live Once,所以别留遗憾。

这画风哪像一个大佬啊,YOLO的 one stage模式也是牛X炸了,同时小马的硬核代码能力也是让人惊叹,膜拜,好了,不多说了,先放出经典的YOLO V3吧(YOLO V4 V5的作者不是小马哥了,但是小马哥也给与了YOLO V4一定的肯定)
他在TED上有一段演讲,放在2017年还是很轰动的,大家可以去看看。
1.YOLO V3模型结构和代码
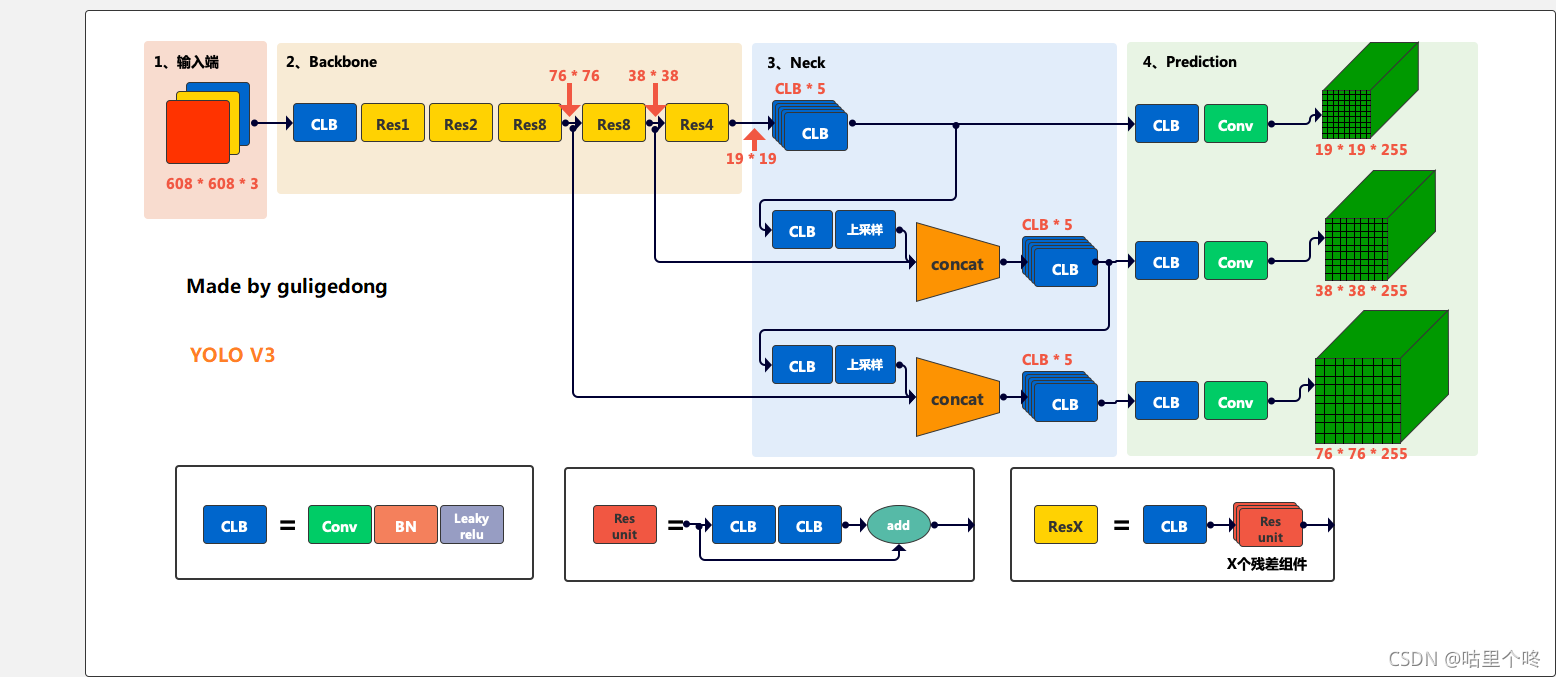
这个图是自己画的,所谓原创,就要完全原滋原味,这个是我女朋友小罗画,一会的YOLOv4是我画的,她是做设计的,明显就能看的出来差距。给她点赞,兄弟们。
backbone用的是darknet53,里面也是用到了经典残差模块,据说小马哥darknet53是他完全手撸的,没有用任何框架和依赖库,大佬果然就是大佬啊。然后Neck部分就是一些特征融合,最后也是分成了3个大中小的featuremap,体现出了他所谓的多尺度检测的概念。小的featuremap是下采样32倍的,中的featuremap是下采样16倍的,小的featuremap是下采样8倍的,大的featuremap用来检测小目标,小的featuremap用过来检测大的目标。非常的合理。还是那句话,这个世界永远不缺实现别人想法的人,有想法的人才是这个世界进步的源泉。敢想敢干的人更是值得我们尊敬的,敬小马哥。
好了,我也就是根据这个图手撸了代码,和小马哥不同的是,我要用依赖库,上代码
import torch
import torch.nn as nn
class yolo3(nn.Module):
def __init__(self, num_class=10):
super(yolo3, self).__init__()
self.darknet = dark_net()
finall_channel = (num_class + 5) * 3
self.yoloconvs32 = yoloconvs(1024, 512, finall_channel)
self.yoloconvs16 = yoloconvs(768, 256, finall_channel)
self.yoloconvs8 = yoloconvs(384, 128, finall_channel)
self.upsample = upsample()
def forward(self, x):
x_32, x_16, x_8 = self.darknet(x)
x_route32, yolo_output32 = self.yoloconvs32(x_32)
x_route32_16 = self.upsample(x_route32)
x_16 = torch.cat((x_16, x_route32_16), dim=1)
x_route16, yolo_output16 = self.yoloconvs16(x_16)
x_route16_8 = self.upsample(x_route16)
x_8 = torch.cat((x_8, x_route16_8), dim=1)
x_route8, yolo_output8 = self.yoloconvs8(x_8)
return yolo_output32, yolo_output16, yolo_output8
class dark_net(nn.Module):
def __init__(self):
super(dark_net, self).__init__()
self.conv0 = CBL(3, 32, stride=1)
self.conv1 = CBL(32, 64, stride=2) # first downsample
self.residual1 = residual_block(64, 32) # 1 time
self.conv2 = CBL(64, 128, stride=2) # second downsample
self.residual2 = nn.Sequential(
residual_block(128, 64),
residual_block(128, 64) # 2 time
)
self.conv3 = CBL(128, 256, stride=2) # third downsample
self.residual3 = nn.Sequential(
residual_block(256, 128),
residual_block(256, 128),
residual_block(256, 128),
residual_block(256, 128),
residual_block(256, 128),
residual_block(256, 128),
residual_block(256, 128),
residual_block(256, 128) # 8time
)
self.conv4 = CBL(256, 512, stride=2) # fourth down sample
self.residual4 = nn.Sequential(
residual_block(512, 256),
residual_block(512, 256),
residual_block(512, 256),
residual_block(512, 256),
residual_block(512, 256),
residual_block(512, 256),
residual_block(512, 256),
residual_block(512, 256) # 8time
)
self.conv5 = CBL(512, 1024, stride=2) # fifth down sample
self.residual5 = nn.Sequential(
residual_block(1024, 512),
residual_block(1024, 512),
residual_block(1024, 512),
residual_block(1024, 512) # 4 time
)
def forward(self, x):
x = self.conv0(x)
x = self.conv1(x)
x = self.residual1(x)
x = self.conv2(x)
x = self.residual2(x)
x_8 = self.conv3(x)
x_8 = self.residual3(x_8)
x_16 = self.conv4(x_8)
x_16 = self.residual4(x_16)
x_32 = self.conv5(x_16)
x_32 = self.residual5(x_32)
return x_32, x_16, x_8
class CBL(nn.Module):
"""
CONV + BATCH_NORMAL + LEAKY_RELU
"""
def __init__(self, ch_input, ch_output, kernel_size=3, stride=1, padding=1, activition='leaky'):
super(CBL, self).__init__()
self.conv = nn.Conv2d(ch_input, ch_output, kernel_size, stride, padding)
self.bn = nn.BatchNorm2d(ch_output)
self.activition = nn.LeakyReLU(0.1) if activition == 'leaky' else nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.activition(x)
return x
class residual_block(nn.Module):
def __init__(self, ch_input, ch_output):
super(residual_block, self).__init__()
self.conv1 = CBL(ch_input, ch_output, kernel_size=1, stride=1, padding=0)
self.conv2 = CBL(ch_output, ch_output * 2, kernel_size=3, stride=1, padding=1)
def forward(self, x):
x1 = self.conv1(x)
x2 = self.conv2(x1)
x3 = x + x2
return x3
class upsample(nn.Module):
def __init__(self):
super(upsample, self).__init__()
def forward(self, x):
return nn.functional.interpolate(x, scale_factor=2, mode='nearest')
class yoloconvs(nn.Module):
def __init__(self, ch_input, ch_output, num_class):
super(yoloconvs, self).__init__()
self.conv1 = CBL(ch_input, ch_output, kernel_size=1, stride=1, padding=0)
self.conv2 = CBL(ch_output, 2 * ch_output, kernel_size=3, stride=1, padding=1)
self.conv3 = CBL(2 * ch_output, ch_output, kernel_size=1, stride=1, padding=0)
self.conv4 = CBL(ch_output, 2 * ch_output, kernel_size=3, stride=1, padding=1)
self.conv5 = CBL(2 * ch_output, ch_output, kernel_size=1, stride=1, padding=0)
self.conv6 = CBL(ch_output, 2 * ch_output, kernel_size=3, stride=1, padding=1)
self.yolo_output = CBL(2 * ch_output, num_class, kernel_size=1, stride=1, padding=0)
self.conv7 = CBL(ch_output, ch_output // 2, kernel_size=1, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x_route = self.conv5(x)
x_route_ = self.conv6(x_route)
yolo_output = self.yolo_output(x_route_)
x_route = self.conv7(x_route)
return x_route, yolo_output
if __name__ == '__main__':
net = yolo3(10).cuda()
x = torch.Tensor(2, 3, 412, 412).cuda()
y_32, y_16, y_8 = net(x)
# print(net)
print(y_32.shape)
print(y_16.shape)
print(y_8.shape)
?个人感觉代码还算比较整洁,但是肯定有更好的实现方式。各位别喷我就行。
2.YOLO V4结构图和代码
YOLO V4发布的,作者不是小马哥了,因为小马哥已经隐退了。很多人都说V4不够根正苗红,只是用集百家之所长,你怎么不去集一集,人家也是参与过v3维护和开发的人,吃不到葡萄说葡萄酸,这就是很多人的现状,夸奖别人就那么难么。有点愤青了。哈哈。上图
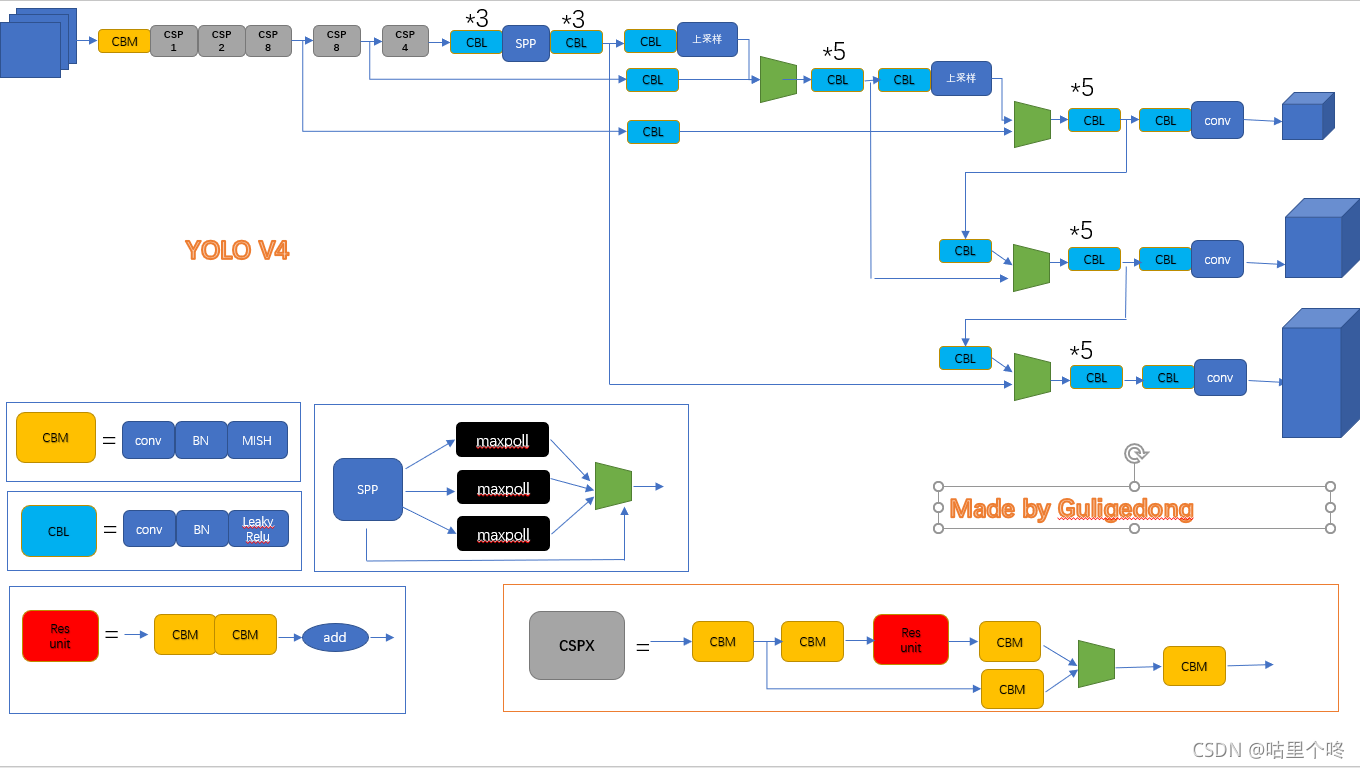
?这个就是我画的,很low有没有啊,哈哈哈。
可以看到和V3相比,在backbone中的激活函数换成了mish而不是leakyrule了,同时,backbone后面加入了spp,能够更好融合特征,有更好的尺度不变形。之后就和v3大差不差的了,V4在结构上和V3差距不大,但是他在样本增强上下了不上功夫,比如mixup之类的,使得网络的鲁棒性更强了。好了,上代码,依然是我手撸的。
import torch
import torch.nn as nn
import torch.nn.functional as F
class yolo4(nn.Module):
def __init__(self,num_class = 10):
super(yolo4,self).__init__()
self.csp_darknet = csp_datknet()
self.neck = neck(num_class)
def forward(self,x):
x_8,x_16,x_32 = self.csp_darknet(x)
yolo_output8,yolo_output16,yolo_output32 = self.neck(x_32,x_16,x_8)
return yolo_output32,yolo_output16,yolo_output8
class neck(nn.Module):
def __init__(self,num_class=10):
super(neck,self).__init__()
# neck1
self.conv0 = nn.Sequential(
CBL(1024, 512,kernel_size=1,stride=1,padding=0),
CBL(512, 1024,kernel_size=1,stride=1,padding=0),
CBL(1024, 512,kernel_size=1,stride=1,padding=0)
)
self.spp = spp()
self.conv1 = nn.Sequential(
CBL(2048, 512,kernel_size=1,stride=1,padding=0),
CBL(512, 1024,kernel_size=1,stride=1,padding=0),
CBL(1024, 512,kernel_size=1,stride=1,padding=0)
)
self.conv2 = CBL(512,256,kernel_size=1,stride=1,padding=0)
self.upsample1 = upsample()
self.conv3 = CBL(512,256,kernel_size=1,stride=1,padding=0)
self.conv4 = nn.Sequential(
CBL(512,256,kernel_size=1,stride=1,padding=0),
CBL(256,512,kernel_size=1,stride=1,padding=0),
CBL(512, 256, kernel_size=1, stride=1, padding=0),
CBL(256, 512, kernel_size=1, stride=1, padding=0),
CBL(512, 256, kernel_size=1, stride=1, padding=0)
)
self.conv5 = CBL(256,128,kernel_size=1, stride=1, padding=0)
self.upsample2 = upsample()
self.conv6 = CBL(256,128,kernel_size=1, stride=1, padding=0)
self.head1_conv_1 = nn.Sequential(
CBL(256,128,kernel_size=1, stride=1, padding=0),
CBL(128,256,kernel_size=3, stride=1, padding=1),
CBL(256, 128, kernel_size=1, stride=1, padding=0),
CBL(128, 256, kernel_size=3, stride=1, padding=1),
CBL(256, 128, kernel_size=1, stride=1, padding=0)
)
self.yolo8_conv = nn.Sequential(
CBL(128,256,kernel_size=3,stride=1,padding=1),
CBL(256,(5+num_class)*3,kernel_size=1,stride=1,padding=0)
)
self.conv7 = CBL(128,256,kernel_size=3,stride=2,padding=1)
self.head1_conv_2 = nn.Sequential(
CBL(512, 256, kernel_size=1, stride=1, padding=0),
CBL(256, 512, kernel_size=3, stride=1, padding=1),
CBL(512, 256, kernel_size=1, stride=1, padding=0),
CBL(256, 512, kernel_size=3, stride=1, padding=1),
CBL(512, 256, kernel_size=1, stride=1, padding=0)
)
self.yolo16_conv = nn.Sequential(
CBL(256,512,kernel_size=3,stride=1,padding=1),
CBL(512,(5+num_class)*3,kernel_size=1,stride=1,padding=0)
)
self.conv8 = CBL(256,512,kernel_size=3,stride=2,padding=1)
self.head1_conv_3 = nn.Sequential(
CBL(1024, 512, kernel_size=1, stride=1, padding=0),
CBL(512, 1024, kernel_size=3, stride=1, padding=1),
CBL(1024, 512, kernel_size=1, stride=1, padding=0),
CBL(512, 1024, kernel_size=3, stride=1, padding=1),
CBL(1024, 512, kernel_size=1, stride=1, padding=0)
)
self.yolo32_conv = nn.Sequential(
CBL(512,1024,kernel_size=3,stride=1,padding=1),
CBL(1024, (5 + num_class) * 3, kernel_size=1, stride=1, padding=0)
)
def forward(self, x_32,x_16,x_8):
x_32 = self.conv0(x_32)
x_32= self.spp(x_32)
neck1 = self.conv1(x_32)
upsample1 = self.conv2(neck1)
upsample1 = self.upsample1(upsample1)
upsample1_down = self.conv3(x_16)
upsample1 = torch.cat((upsample1,upsample1_down),dim=1)
neck2 = self.conv4(upsample1)
upsample2 = self.conv5(neck2)
upsample2 = self.upsample2(upsample2)
upsample2_down = self.conv6(x_8)
upsample2 = torch.cat((upsample2,upsample2_down),dim=1)
neck3 = self.head1_conv_1(upsample2)
yolo_output8 = self.yolo8_conv(neck3)
yolo_output16 = self.conv7(neck3)
yolo_output16 = torch.cat((yolo_output16,neck2),dim=1)
neck4 = self.head1_conv_2(yolo_output16)
yolo_output16 = self.yolo16_conv(neck4)
yolo_output32 = self.conv8(neck4)
yolo_output32 = torch.cat((yolo_output32,neck1),dim=1)
yolo_output32 = self.head1_conv_3(yolo_output32)
yolo_output32 = self.yolo32_conv(yolo_output32)
return yolo_output8,yolo_output16,yolo_output32
class spp(nn.Module):
def __init__(self):
super(spp,self).__init__()
self.maxpool1 = nn.MaxPool2d(kernel_size=5,stride=1,padding= 5//2)
self.maxpool2 = nn.MaxPool2d(kernel_size=9,stride=1,padding= 9//2)
self.maxpool3 = nn.MaxPool2d(kernel_size=13,stride=1,padding= 13//2)
def forward(self,x):
x1 = self.maxpool1(x)
x2 = self.maxpool2(x)
x3 = self.maxpool3(x)
x = torch.cat((x,x1,x2,x3),dim=1)
return x
class csp_datknet(nn.Module):
def __init__(self):
super(csp_datknet, self).__init__()
self.conv0 = CBM(3,32,kernel_size=3,stride=1,padding=1)
# csp1
self.csp1_conv1 = CBM(32,64,kernel_size=3,stride=2,padding=1)
self.residual_block_csp1 = residual_block_csp1(64,32)
self.csp1_conv2_1 = CBM(64, 64, kernel_size=1, stride=1, padding=0)
self.csp1_conv2_2 = CBM(64, 64, kernel_size=1, stride=1, padding=0)
self.csp1_conv2_3 = CBM(64, 64, kernel_size=1, stride=1, padding=0)
self.csp1_conv2_4 = CBM(128, 64, kernel_size=1, stride=1, padding=0)
#csp2
self.csp2_conv1 = CBM(64,128,kernel_size=3,stride=2,padding=1)
self.residual_block_csp2 = nn.Sequential(
residual_block_csp(64,64),
residual_block_csp(64,64)
)
self.csp2_conv2_1 = CBM(128, 64, kernel_size=1, stride=1, padding=0)
self.csp2_conv2_2 = CBM(64, 64, kernel_size=1, stride=1, padding=0)
self.csp2_conv2_3 = CBM(128, 64, kernel_size=1, stride=1, padding=0)
self.csp2_conv2_4 = CBM(128, 128, kernel_size=1, stride=1, padding=0)
#csp8_1
self.csp3_conv1 = CBM(128,256,kernel_size=3,stride=2,padding=1)
self.residual_block_csp3 = nn.Sequential(
residual_block_csp(128,128),
residual_block_csp(128,128),
residual_block_csp(128, 128),
residual_block_csp(128, 128),
residual_block_csp(128, 128),
residual_block_csp(128, 128),
residual_block_csp(128, 128),
residual_block_csp(128, 128)
)
self.csp3_conv2_1 = CBM(256, 128,kernel_size=1,stride=1,padding=0)
self.csp3_conv2_2 = CBM(128, 128, kernel_size=1, stride=1, padding=0)
self.csp3_conv2_3 = CBM(256, 128, kernel_size=1, stride=1, padding=0)
self.csp3_conv2_4 = CBM(256, 256, kernel_size=1, stride=1, padding=0)
#csp8_2
self.csp4_conv1 = CBM(256,512,kernel_size=3,stride=2,padding=1)
self.residual_block_csp4 = nn.Sequential(
residual_block_csp(256, 256),
residual_block_csp(256, 256),
residual_block_csp(256, 256),
residual_block_csp(256, 256),
residual_block_csp(256, 256),
residual_block_csp(256, 256),
residual_block_csp(256, 256),
residual_block_csp(256, 256)
)
self.csp4_conv2_1 = CBM(512, 256, kernel_size=1, stride=1, padding=0)
self.csp4_conv2_2 = CBM(256, 256, kernel_size=1, stride=1, padding=0)
self.csp4_conv2_3 = CBM(512, 256, kernel_size=1, stride=1, padding=0)
self.csp4_conv2_4 = CBM(512, 512, kernel_size=1, stride=1, padding=0)
#csp4
self.csp5_conv1 = CBM(512,1024,kernel_size=3,stride=2,padding=1)
self.residual_block_csp5 = nn.Sequential(
residual_block_csp(512, 512),
residual_block_csp(512, 512),
residual_block_csp(512, 512),
residual_block_csp(512, 512)
)
self.csp5_conv2_1 = CBM(1024,512,kernel_size=1, stride=1, padding=0)
self.csp5_conv2_2 = CBM(512, 512, kernel_size=1, stride=1, padding=0)
self.csp5_conv2_3 = CBM(1024, 512, kernel_size=1, stride=1, padding=0)
self.csp5_conv2_4 = CBM(1024,1024,kernel_size=1, stride=1, padding=0)
def forward(self,x):
x = self.conv0(x)
#CSP1
csp1_conv1 = self.csp1_conv1(x)
csp1_conv_left = self.csp1_conv2_1(csp1_conv1)
csp1_conv_left = self.residual_block_csp1(csp1_conv1)
csp1_conv_left = self.csp1_conv2_2(csp1_conv_left)
csp1_conv_right = self.csp1_conv2_3(csp1_conv1)
csp1_conv = torch.cat((csp1_conv_left,csp1_conv_right),dim=1)
csp1_conv = self.csp1_conv2_4(csp1_conv)
#CSP2
csp2_conv1 = self.csp2_conv1(csp1_conv)
csp2_conv_left = self.csp2_conv2_1(csp2_conv1)
csp2_conv_left = self.residual_block_csp2(csp2_conv_left)
csp2_conv_left = self.csp2_conv2_2(csp2_conv_left)
csp2_conv_right = self.csp2_conv2_3(csp2_conv1)
csp2_conv = torch.cat((csp2_conv_left,csp2_conv_right),dim=1)
csp2_conv = self.csp2_conv2_4(csp2_conv)
#CSP8_1
csp3_conv1 = self.csp3_conv1(csp2_conv)
csp3_conv_left = self.csp3_conv2_1(csp3_conv1)
csp3_conv_left = self.residual_block_csp3(csp3_conv_left)
csp3_conv_left = self.csp3_conv2_2(csp3_conv_left)
csp3_conv_right = self.csp3_conv2_3(csp3_conv1)
csp3_conv = torch.cat((csp3_conv_left,csp3_conv_right),dim=1)
csp3_conv = self.csp3_conv2_4(csp3_conv)
#CSP8_2
csp4_conv1 = self.csp4_conv1(csp3_conv)
csp4_conv_left = self.csp4_conv2_1(csp4_conv1)
csp4_conv_left = self.residual_block_csp4(csp4_conv_left)
csp4_conv_left = self.csp4_conv2_2(csp4_conv_left)
csp4_conv_right = self.csp4_conv2_3(csp4_conv1)
csp4_conv = torch.cat((csp4_conv_left,csp4_conv_right),dim=1)
csp4_conv = self.csp4_conv2_4(csp4_conv)
#CSP4
csp5_conv1 = self.csp5_conv1(csp4_conv)
csp5_conv_left = self.csp5_conv2_1(csp5_conv1)
csp5_conv_left = self.residual_block_csp5(csp5_conv_left)
csp5_conv_left = self.csp5_conv2_2(csp5_conv_left)
csp5_conv_right = self.csp5_conv2_3(csp5_conv1)
csp5_conv = torch.cat((csp5_conv_left,csp5_conv_right),dim=1)
csp5_conv = self.csp5_conv2_4(csp5_conv)
return csp3_conv,csp4_conv,csp5_conv
class CBM(nn.Module):
"""
CONV + BATCH_NORMAL + MISH
"""
def __init__(self, ch_input, ch_output, kernel_size=3, stride=1, padding=1, activition='mish'):
super(CBM, self).__init__()
self.conv = nn.Conv2d(ch_input, ch_output, kernel_size, stride, padding)
self.bn = nn.BatchNorm2d(ch_output)
self.activition = Mish() if activition == 'mish' else None
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.activition(x)
return x
class CBL(nn.Module):
"""
CONV + BATCH_NORMAL + LEAKY_RELU
"""
def __init__(self, ch_input, ch_output, kernel_size=3, stride=1, padding=1, activition='leaky'):
super(CBL, self).__init__()
self.conv = nn.Conv2d(ch_input, ch_output, kernel_size, stride, padding)
self.bn = nn.BatchNorm2d(ch_output)
self.activition = nn.LeakyReLU(0.1) if activition == 'leaky' else None
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.activition(x)
return x
class Mish(nn.Module):
def __init__(self):
super().__init__()
def forward(self,x):
x = x * (torch.tanh(F.softplus(x)))
return x
class residual_block_csp1(nn.Module):
def __init__(self,ch_input,ch_output):
super(residual_block_csp1,self).__init__()
self.conv1 = CBM(ch_input,ch_output,kernel_size=1,stride=1,padding=0)
self.conv2 = CBM(ch_output,ch_output*2,kernel_size=3,stride=1,padding=1)
def forward(self,x):
x1 = self.conv1(x)
x2 = self.conv2(x1)
x3 = x + x2
return x3
class residual_block_csp(nn.Module):
def __init__(self,ch_input,ch_output):
super(residual_block_csp,self).__init__()
self.conv1 = CBM(ch_input,ch_output,kernel_size=1,stride=1,padding=0)
self.conv2 = CBM(ch_output,ch_output,kernel_size=3,stride=1,padding=1)
def forward(self,x):
x1 = self.conv1(x)
x2 = self.conv2(x1)
x3 = x + x2
return x3
class upsample(nn.Module):
def __init__(self):
super(upsample, self).__init__()
def forward(self, x):
return nn.functional.interpolate(x, scale_factor=2, mode='nearest')
if __name__ == '__main__':
net = yolo4().cuda()
x = torch.Tensor(2,3,640,640).cuda()
y3,y4,y5 = net(x)
print(y3.shape)
print(y4.shape)
print(y5.shape)
有点冗长,不太美观。
3.YOLO V5S的模型结构和代码
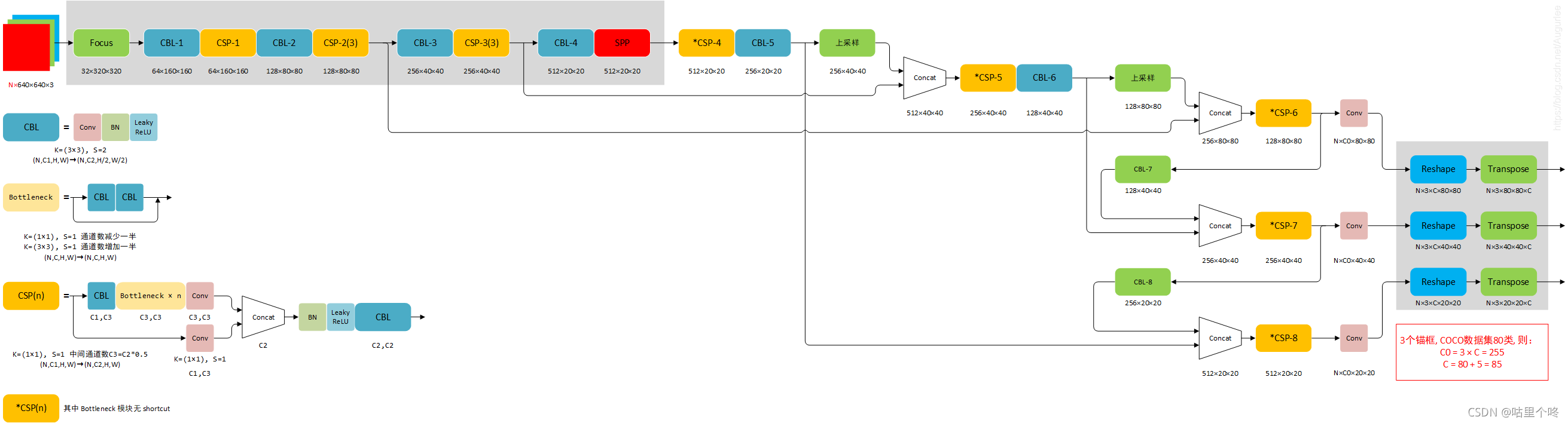
图片貌似有点太大了,看不清就放大看吧。
?大家可以看到,激活函数又变回了leakyrule。可能为了减小计算量吧,毕竟mish的计算量大的多,轻量化网络就要损失一些精度吧。为了减小参数量,V5S还用到了Focus方法,在减小参数量的同时,它给我的感觉是还变相增大了batch_size,作者也是在速度和精度上来回徘徊啊。后面的东西看上去又差不多了,上代码吧
import torch
import torch.nn as nn
from torch.nn import Upsample as UpSample
def autopad(k, p=None):
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class CBLx1(nn.Module):
def __init__(self, ch_in, ch_out, k=3, s=2, p=None, groups=1):
super(CBLx1, self).__init__()
self.conv = nn.Conv2d(ch_in, ch_out, k, s, autopad(k, p), groups=groups, bias=False)
self.bn = nn.BatchNorm2d(ch_out)
self.act = nn.SiLU()
def __call__(self, x):
x = self.conv(x)
x = self.bn(x)
return self.act(x)
class CBL(nn.Module):
def __init__(self, ch_in, ch_out, k=3, s=2, p=None, groups=1):
super(CBL, self).__init__()
self.conv = nn.Conv2d(ch_in, ch_out, k, s, autopad(k, p), groups=groups, bias=False)
self.bn = nn.BatchNorm2d(ch_out)
self.act = nn.LeakyReLU()
def __call__(self, x):
x = self.conv(x)
x = self.bn(x)
return self.act(x)
class Focus(nn.Module):
def __init__(self, ch_in, ch_out, k=1, s=1, p=None, groups=1):
super(Focus, self).__init__()
self.cbl = CBLx1(ch_in*4, ch_out, k, s, autopad(k,p), groups)
def __call__(self, x):
out = torch.cat([
x[..., ::2, ::2], # 从第0行第0列开始,每隔一个元素取值
x[..., 1::2, ::2], # 从第1行第0列开始,每隔一个元素取值
x[..., ::2, 1::2], # 从第0行第1列开始,每隔一个元素取值
x[..., 1::2, 1::2] # 从第1行第1列开始,每隔一个元素取值
], 1)
return self.cbl(out)
class Bottleneck(nn.Module):
def __init__(self, ch_in, ch_out, blocks, shortcut=True):
super(Bottleneck, self).__init__()
self.add = (shortcut and ch_in == ch_out)
hidden_chanel = ch_out // 2
unit_layer = nn.Sequential(
CBL(ch_in, ch_out, k=1, s=1),
CBL(2 * hidden_chanel, ch_out, 3, 1)
)
self.unit_layer_n = nn.Sequential(*[unit_layer for _ in range(blocks)])
def __call__(self, x):
if self.add:
return x + self.unit_layer_n(x)
else:
return self.unit_layer_n(x)
class CSP1_n(nn.Module):
def __init__(self, ch_in, ch_out, k=1, s=1, p=None, groups=1, n=1):
super(CSP1_n, self).__init__()
c_ = int(ch_out // 2)
self.up = nn.Sequential(
CBL(ch_in, c_, k, s, autopad(k, p), groups),
Bottleneck(c_, c_, n),
nn.Conv2d(c_, c_, 1)
)
self.bottom = nn.Conv2d(ch_in, c_, 1, 1, 0)
self.tie = nn.Sequential(
nn.BatchNorm2d(c_ * 2),
nn.LeakyReLU(),
nn.Conv2d(c_ * 2, ch_out, 1, 1, 0, bias=False)
)
def __call__(self, x):
total = torch.cat([self.up(x), self.bottom(x)], dim=1)
out = self.tie(total)
return out
class CSP2_n(nn.Module):
def __init__(self, ch_in, ch_out, k=1, s=1, p=None, groups=1, n=1):
super(CSP2_n, self).__init__()
c_ = ch_out // 2
self.up = nn.Sequential(
CBL(ch_in, c_, k, s, autopad(k, p), groups),
Bottleneck(c_, c_, n),
nn.Conv2d(c_, ch_out, 1),
)
self.tie = nn.Sequential(
nn.BatchNorm2d(ch_out),
nn.LeakyReLU(),
nn.Conv2d(ch_out, ch_out, 1, 1, 0, bias=False)
)
def __call__(self, x):
total = self.up(x)
out = self.tie(total)
return out
class SPP(nn.Module):
def __init__(self, ch_in, ch_out, k=(5, 9, 13)):
super(SPP, self).__init__()
hiddel_channel = ch_in // 2
length = len(k) + 1
self.conv1 = CBL(ch_in, hiddel_channel, 1, 1)
self.max_pool = nn.ModuleList(nn.MaxPool2d(kernel_size=x, stride=1, padding=x//2) for x in k)
self.conv2 = CBL(hiddel_channel * length, ch_out, 1, 1)
def forward(self, x):
x = self.conv1(x)
out = torch.cat([x] + [m(x) for m in self.max_pool], 1)
out = self.conv2(out)
return out
class CSPDarkNet(nn.Module):
def __init__(self, gd=0.33, gw=0.5):
super(CSPDarkNet, self).__init__()
self.truck_big = nn.Sequential(
Focus(3, 32),
CBL(32, 64, k=3, s=2, p=1),
CSP1_n(64, 64, n=3),
CBL(64, 128, k=3, s=2, p=1),
CSP1_n(128, 128, n=3),
)
self.truck_middle = nn.Sequential(
CBL(128, 256, k=3, s=2, p=1),
CSP1_n(256, 256, n=3),
)
self.truck_small = nn.Sequential(
CBL(256, 512, k=3, s=2, p=1),
SPP(512, 512)
)
def forward(self, x):
h_big = self.truck_big(x) # (80,80)
h_middle = self.truck_middle(h_big) # (40,40)
h_small = self.truck_small(h_middle) # (20,20)
return h_big, h_middle, h_small
class YOLO(nn.Module):
def __init__(self, nc=80):
super(YOLO, self).__init__()
self.nc = nc
self.backone = CSPDarkNet()
self.neck_small = nn.Sequential(
CSP2_n(512, 512, n=3),
CBL(512, 256, 1, 1, 0)
)
self.up_middle = nn.Sequential(
UpSample(scale_factor=2)
)
self.out_set_middle = nn.Sequential(
CSP2_n(512, 256, n=3),
CBL(256, 128, 1, 1, 0),
)
self.up_big = nn.Sequential(
UpSample(scale_factor=2)
)
self.out_set_tie_big = nn.Sequential(
CSP2_n(256, 128, n=3)
)
self.pan_middle = nn.Sequential(
CBL(128, 128, 3, 2, 1)
)
self.out_set_tie_middle = nn.Sequential(
CSP2_n(256, 256, n=3)
)
self.pan_small = nn.Sequential(
CBL(256, 256, 3, 2, 1)
)
self.out_set_tie_small = nn.Sequential(
CSP2_n(512, 512, n=3)
)
# ------------------------------Prediction--------------------------------
# prediction
big_ = round(128)
middle = round(256)
small_ = round(512)
self.out_big = nn.Sequential(
nn.Conv2d(big_, 3 * (5 + nc), 1, 1, 0)
)
self.out_middle = nn.Sequential(
nn.Conv2d(middle, 3 * (5 + nc), 1, 1, 0)
)
self.out_small = nn.Sequential(
nn.Conv2d(small_, 3 * (5 + nc), 1, 1, 0)
)
def __call__(self, x):
big, middle, small = self.backone(x)
# 第一部分:
# 1.CSP2_n + CBL
neck_small = self.neck_small(small)
# 2.从上采样到CBL
up_middle = self.up_middle(neck_small)
middle_cat = torch.cat([up_middle, middle], dim=1)
out_set_middle = self.out_set_middle(middle_cat)
# 3.上采样到CSP2_n
up_big = self.up_big(out_set_middle) # torch.Size([2, 128, 76, 76])
big_cat = torch.cat([up_big, big], dim=1)
out_set_tie_big = self.out_set_tie_big(big_cat)
# 4.后面
out_big = self.out_big(out_set_tie_big)
# out_big = out_big.view(-1, 3, (5+self.nc), out_big.shape[-2], out_big.shape[-1])
# out_big = out_big.permute(0, 1, 3, 4, 2)
# 第二部分:
# 1.CBL-7到CSP-7
neck_tie_middle = torch.cat([self.pan_middle(out_set_tie_big), out_set_middle], dim=1)
up_middle = self.out_set_tie_middle(neck_tie_middle)
# 2.后面
out_middle = self.out_middle(up_middle)
# out_middle = out_middle.view(-1, 3, (5+self.nc), out_middle.shape[-2], out_middle.shape[-1])
# out_middle = out_middle.permute(0, 1, 3, 4, 2)
# 第三部分:
# 1.CBL-8到CSP-8
neck_tie_small = torch.cat([self.pan_small(up_middle), neck_small], dim=1)
out_set_small = self.out_set_tie_small(neck_tie_small)
# 2.后面部分
out_small = self.out_small(out_set_small)
# out_small = out_small.view(-1, 3, (5 + self.nc), out_small.shape[-2], out_small.shape[-1])
# out_small = out_small.permute(0, 1, 3, 4, 2)
return out_small, out_middle, out_big
if __name__ == '__main__':
net = YOLO(nc=10)
a = torch.randn(2, 3, 640, 640)
y = net(a)
print(y[0].shape, y[1].shape, y[2].shape)
?PS:YOLO V5S是我一个小兄弟帮我写的,手动点赞。
今天画图真是画废了~~~~
好了,3个模型的网络结构和代码就先到这了,之后要说到的anchor,iou,nms,数据处理,我觉得才是YOLO里面最抽象的东西。我们放到下一章来讲。
至此,敬礼,salute!!!!
老规矩,上咩咩
