ResNet,��2015����������з�����CVPR�ϵ�һƪ����,�����˲в�����������������һ��,ֱ������������cv�硣������2016��ImageNet��ResNet��õ�һ������ResNet��������AI���������ڵ�ǰ�ؼ������С�
Ҫ�����Ժ��������������ResNet��ʮ��֮һ�Ҿ�������(Ц)
ResNet����
ResNet����������������˻����⡣��������,����Խ��ģ�;�����ϸ����ӵĽ����������ʵ��ѵ����,ģ��һ������Ч����һ����ú��п��ܻ�������Ч����,�ݶ���ʧ��ȱ�㡣����������չʾ����CIFAR-10��20��CNN��56��CNN���Ծ��ȡ���ͼ��֪,56��CNN�ľ��Ȼ���20��CNN�ľ��Ȳ
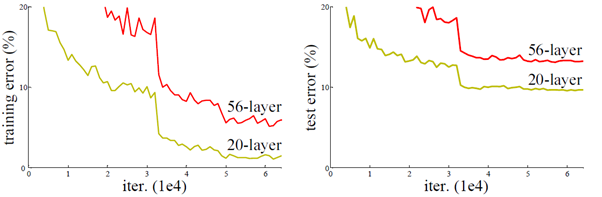
?��ѵ��������,����ش�ʱ�ǵõ�ÿһ��������ݶ�����ˡ���Խѵ�������ڻ��߽��������,�����ݶȶ��dz���С,������˺����õ������ݶ�Ҳ�ͺ��������ӽ���0��Ϊ�˽����һ����,�β�ʿ��������������в�ѧϰ��һ���
�в�ѧϰ
��������Ҫ��һ������Ļ������ټӼ�������ʱ,�����������ֱ���ں��������ԭ������������������������롣���������Dz�������,���ݲв�ѧϰ������������Ϊxʱ��ѧϰ����������Ϊ H(x)?,��������ϣ�����������ѧϰ���в�ֵ?F(x)=H(x)-x?,������ʵԭʼ��ѧϰ������?F(x)+x?��Ҳ����˵���������ʱ,���ǻ�����Ҫ��F(x)�Ļ����ϼ���x��
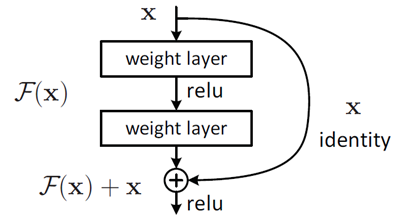
?��ԭ����Ļ���������������,����ʹ�����˻��ݶȱ�÷dz�С�������������Ϊ�в�ֵ������ֵ���ʱ,�����ݶ�ʱ�Ͳ����в���С�ݶȵ�ֵ����Ϊ����ʱʽ������һ��x,������֪���ǶԱ���������ʱ,x�ĵ�������1��Ҳ����dz�Ե�˵,���ڶԸò�������õ����ݶ���һ��С�ݶ��ټ���һ��1���������������ݶȵ�ֵ���ֲ����ݶȻ���ʧ��ȱ�㡣��Ȼ�в��ݶȲ�����ô��ȫΪ1,���Ҿ�����Ƚ�С,��1�Ĵ���Ҳ���ᵼ���ݶ���ʧ�����Բв�ѧϰ������ס�
����ṹ
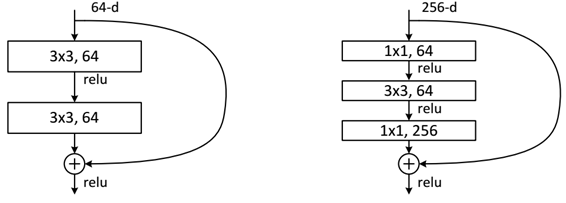
������������VGG������,����������Ͻ����˸Ľ�,��ͨ����·���Ƽ����˲вԪ�������ĵ�Ԫ�ṹ���Ǿ���,BN,����������·������ÿ����Ԫ�����λ�ü����˲в�����,��Ԫ����ټ��ϵ�Ԫ�������ͨ��һ���������Ϊ���������
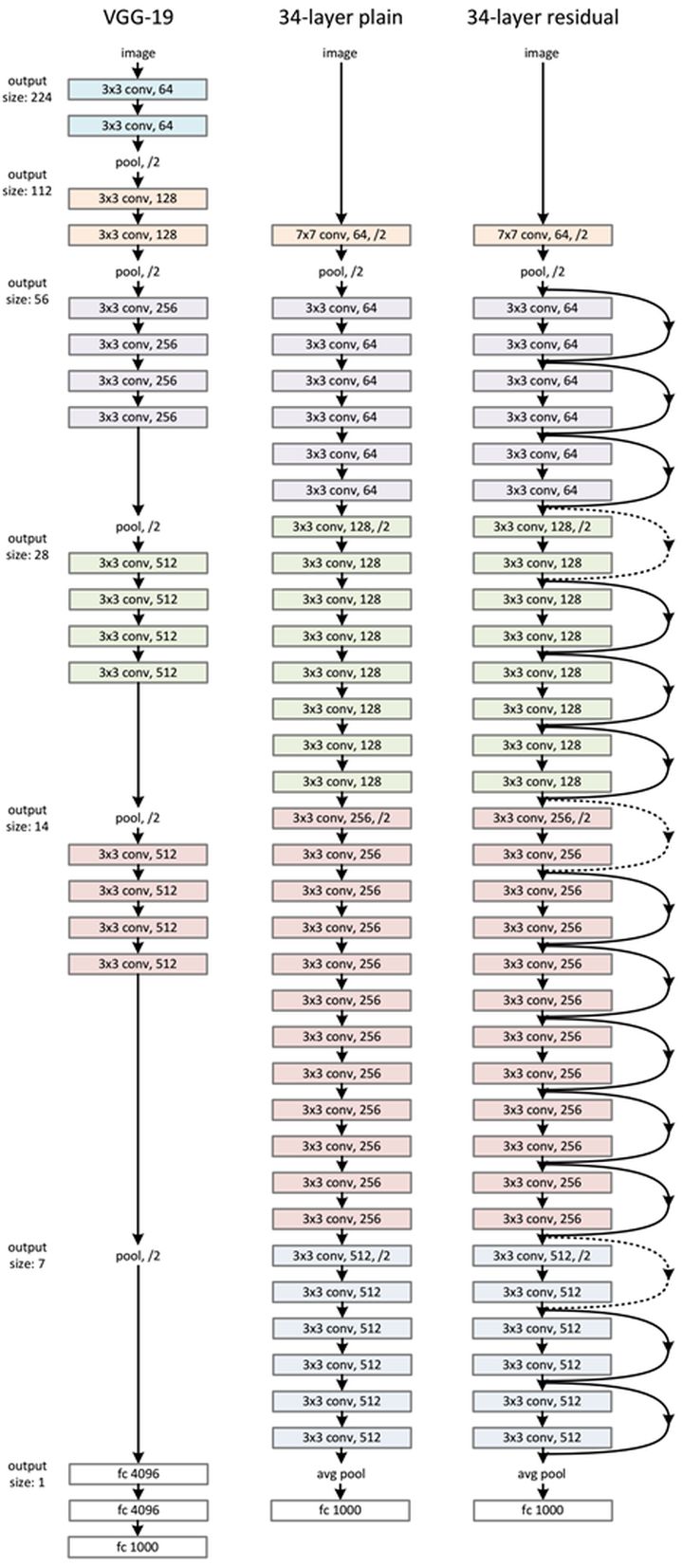
�����ڲ�ͬ���ResNet��˵,�вԪ�ĽṹҲ����ͬ
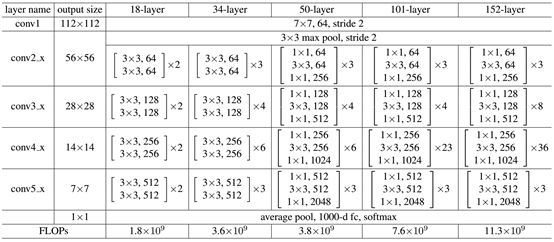
?��С��50��ʱһ��вԪ��ֻ���������,����һ��������3*3�����˴�СȻ�������1���ı�feature map�Ĵ�С,����һ��������С��Сһ���������Ϊ�˲�ʹ��Ϣ��ʧ��̫�ཫfeature map��ͨ��������һ��,����Ҳ��������ĸ����ԡ�����50��ʱ,������һ��1*1�ľ����㽫feature map��ͨ����ӳ�������Ҫ��ͨ����,��ͨ��������һ����3*3�ı��С�ľ����㡣�����ͨ��һ����ͨ�������ı��ľ����㡣��ͼ�п��Կ���,ResNet�����ͨ����ÿ����������˶�·����,����γ��˲в�ѧϰ,�������߱�ʾfeature map���������˸ı䡣
?Pytorchʵ��ResNet
import torch
import time
from torch import nn
# ��ʼ�ľ�����,�������ͼƬ���д�����feature map
class Conv1(nn.Module):
def __init__(self,inp_channels,out_channels,stride = 2):
super(Conv1,self).__init__()
self.net = nn.Sequential(
nn.Conv2d(inp_channels,out_channels,kernel_size=7,stride=stride,padding=3,bias=False),# �����Ľ��(i - k + 2*p)/s + 1,��ʱͼ���С��Сһ��
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)# ���ݾ����Ĺ�ʽ,��feature map�ߴ��Ϊԭ����һ��
)
def forward(self,x):
y = self.net(x)
return y
class Simple_Res_Block(nn.Module):
def __init__(self,inp_channels,out_channels,stride=1,downsample = False,expansion_=False):
super(Simple_Res_Block,self).__init__()
self.downsample = downsample
if expansion_:
self.expansion = 4# ��ά����չ��expansion��
else:
self.expansion = 1
self.block = nn.Sequential(
nn.Conv2d(inp_channels,out_channels,kernel_size=3,stride=stride,padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels,out_channels*self.expansion,kernel_size=3,padding=1),
nn.BatchNorm2d(out_channels*self.expansion)
)
if self.downsample:
self.down = nn.Sequential(
nn.Conv2d(inp_channels,out_channels*self.expansion,kernel_size=1,stride=stride,bias=False),
nn.BatchNorm2d(out_channels*self.expansion)
)
self.relu = nn.ReLU(inplace=True)
def forward(self,input):
residual = input
x = self.block(input)
if self.downsample:
residual = self.down(residual)# ʹx��h��ά����ͬ
out = residual + x
out = self.relu(out)
return out
class Residual_Block(nn.Module):
def __init__(self,inp_channels,out_channels,stride=1,downsample = False,expansion_=False):
super(Residual_Block,self).__init__()
self.downsample = downsample# �ж��Ƿ��x�����²���ʹx��ģ�����ֵά��ͨ������ͬ
if expansion_:
self.expansion = 4# ��ά����չ��expansion��
else:
self.expansion = 1
# ģ��
self.conv1 = nn.Conv2d(inp_channels,out_channels,kernel_size=1,stride=1,bias=False)# ��������ͼ�ߴ緢���ı�,��ӳ������
self.drop = nn.Dropout(0.5)
self.BN1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels,out_channels,kernel_size=3,stride=stride,padding=1,bias=False)# ��ʱ�����˴�С������С����Ӱ������ͼ�ߴ��С,�ɲ�������
self.BN2 = nn.BatchNorm2d(out_channels)
self.conv3 = nn.Conv2d(out_channels,out_channels*self.expansion,kernel_size=1,stride=1,bias=False)# �ı�ͨ����
self.BN3 = nn.BatchNorm2d(out_channels*self.expansion)
self.relu = nn.ReLU(inplace=True)
if self.downsample:
self.down = nn.Sequential(
nn.Conv2d(inp_channels,out_channels*self.expansion,kernel_size=1,stride=stride,bias=False),
nn.BatchNorm2d(out_channels*self.expansion)
)
def forward(self,input):
residual = input
x = self.relu(self.BN1(self.conv1(input)))
x = self.relu(self.BN2(self.conv2(x)))
h = self.BN3(self.conv3(x))
if self.downsample:
residual = self.down(residual)# ʹx��h��ά����ͬ
out = h + residual# ��
out = self.relu(out)
return out
class Resnet(nn.Module):
def __init__(self,net_block,block,num_class = 1000,expansion_=False):
super(Resnet,self).__init__()
self.expansion_ = expansion_
if expansion_:
self.expansion = 4# ��ά����չ��expansion��
else:
self.expansion = 1
# ����ij�ʼͼ���ľ���
# (3*64*64) --> (64*56*56)
self.conv = Conv1(3,64)
# ����ģ��
# (64*56*56) --> (256*56*56)
self.block1 = self.make_layer(net_block,block[0],64,64,expansion_=self.expansion_,stride=1)# strideΪ1,���ı�ߴ��С
# (256*56*56) --> (512*28*28)
self.block2 = self.make_layer(net_block,block[1],64*self.expansion,128,expansion_=self.expansion_,stride=2)
# (512*28*28) --> (1024*14*14)
self.block3 = self.make_layer(net_block,block[2],128*self.expansion,256,expansion_=self.expansion_,stride=2)
# (1024*14*14) --> (2048*7*7)
self.block4 = self.make_layer(net_block,block[3],256*self.expansion,512,expansion_=self.expansion_,stride=2)
self.avgPool = nn.AvgPool2d(7,stride=1)# (2048*7*7) --> (2048*1*1)����ƽ���ػ��㽫���������ںϲ�ȡƽ��
if expansion_:
length = 2048
else:
length = 512
self.linear = nn.Linear(length,num_class)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def make_layer(self,net_block,layers,inp_channels,out_channels,expansion_=False,stride = 1):
block = []
block.append(net_block(inp_channels,out_channels,stride=stride,downsample=True,expansion_=expansion_))# �Ƚ���һ��ģ���ͨ������СΪ��ģ����Ҫ��ͨ����
if expansion_:
self.expansion = 4
else:
self.expansion = 1
for i in range(1,layers):
block.append(net_block(out_channels*self.expansion,out_channels,expansion_=expansion_))
return nn.Sequential(*block)
def forward(self,x):
x = self.conv(x)
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
# x = self.avgPool(x)
x = x.view(x.shape[0],-1)
x = self.linear(x)
return x
def Resnet18():
return Resnet(Simple_Res_Block,[2,2,2,2],num_class=10,expansion_=False)# ��ʱÿ��ģ������ֻ���������
def Resnet34():
return Resnet(Simple_Res_Block,[3,4,6,3],num_class=10,expansion_=False)
def Resnet50():
return Resnet(Residual_Block,[3,4,6,3],expansion_=True)# Ҳ��50��resnet,���������16��ģ��,ÿ��ģ�����������,���ʣ�³�ʼ�ľ���������ȫ���Ӳ�,�ܹ�50��
def Resnet101():
return Resnet(Residual_Block,[3,4,23,3],expansion_=True)
def Resnet152():
return Resnet(Residual_Block,[3,8,36,3],expansion_=True)
�������ResNet18,34,50,101,152��
��CIFAR-10�����?
# ����cifar10��cifar100��ѵ��
import torch
import os
import time
import torchvision
import tqdm
import numpy as np
from torch.utils.data import Dataset,DataLoader
from ResNet import Resnet18,Resnet34,Resnet50,Resnet101,Resnet152
from visualizer import Vis
class opt():
model_name = 'Resnet18'
save_path = 'checkpoints'
save_name = 'lastest_param.pth'
device = 'cuda'
batch_size = 128
learning_rate = 0.001
epoch = 60
state_file = 'checkpoints/result/lastest_param.pth'
load_f = True
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
train_transform = torchvision.transforms.Compose([
torchvision.transforms.RandomCrop(32,padding=4),
torchvision.transforms.RandomHorizontalFlip(p=0.5),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
test_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
def load_save(model,load_f = False):
if load_f:
state = torch.load(opt.state_file)
model.load_state_dict(state)
return model
else:
return model
# model
if opt.model_name == "Resnet18":
model = Resnet18()
model.to(opt.device)
elif opt.model_name == "Resnet34":
model = Resnet34()
model.to(opt.device)
elif opt.model_name == "Resnet50":
model = Resnet50()
model.to(opt.device)
load_save(model,opt.load_f)
# dataset
train_dataset = torchvision.datasets.CIFAR10(
root = 'data',
train = True,
transform = opt.train_transform,
download=True
)
test_dataset = torchvision.datasets.CIFAR10(
root = 'data',
train = False,
transform = opt.test_transform,
download=True
)
# dataloader
train_loader = DataLoader(
train_dataset,
batch_size=opt.batch_size,
shuffle=True,
num_workers=6
)
test_loader = DataLoader(
test_dataset,
batch_size=100,
shuffle=False,
num_workers=6
)
# loss
loss_fn = torch.nn.CrossEntropyLoss()# ������
# �Ż���
optim = torch.optim.SGD(model.parameters(),lr=opt.learning_rate,momentum=0.9,weight_decay=5e-4)# ��Ȩ����˥��,Ҳ���Ǹ���ʧ������һ��l2������,��ģ��û�нϺ�����,�Ͳ���
flag = 0
def reverse_norm(img,mean=None,std=None):
imgs = []
for i in range(img.size(0)):
image = img[i].data.cpu().numpy().transpose(1, 2, 0)
if (mean is not None) and (std is not None):
image = (image * std + mean) * 255
else: # ���ֻ�Ǿ�����ToTensor()
image = image * 255
imgs.append(image.transpose(2,0,1))
return np.stack(imgs)
for epoch in range(opt.epoch):
now = time.time()
print('---epoch{}---'.format(epoch))
model.train()
loss_epoch = 0
true_pre_epoch = 0
correct = 0
for i,(img,label) in enumerate(tqdm.tqdm(train_loader)):
img,label = img.to(opt.device),label.to(opt.device)
output = model(img)
loss = loss_fn(output,label)
loss.backward()
optim.step()
optim.zero_grad()
flag += 1
loss_epoch += loss.data
pre = torch.argmax(output, dim=1)
num_true = (pre == label).sum()
true_pre_epoch += num_true
correct += label.shape[0]
if (i+1)%100 == 0:
print('epoch {} iter {} loss : {}'.format(epoch,i+1,loss_epoch/(i+1)))
if (i+1)%200 == 0:
acc = true_pre_epoch/correct
print('epoch {} iter {} train_acc : {}'.format(epoch,i+1,acc))
imgs = reverse_norm(img,mean=(0.4914, 0.4822, 0.4465),std=(0.2023, 0.1994, 0.2010))
# ���ӻ�
vis = Vis()
vis.linee(Y=loss_epoch/(i+1),X=flag,win='loss')
vis.linee(Y=acc,X=flag,win='acc')
vis.Image(imgs,pre,opt.classes)
# save
model_path = os.path.join(opt.save_path,opt.save_name)
torch.save(model.state_dict(),model_path)
# test
model.eval()
num = 0
labels = 0
for img ,label in test_loader:
img, label = img.to(opt.device), label.to(opt.device)
output = model(img)
num += (torch.argmax(output,dim=1).data == label.data).sum()
labels += label.shape[0]
fin = time.time()
print('epoch {} test_acc : {} ����һ��epoch����ʱ��:{}s'.format(epoch,num/labels,fin-now))���
��ΪCIFAR-10�����ݼ���СҲֻ��һ����10����,ͼƬ��32*32�Ĵ�С��������ѡ�����ResNet18ȥ����ѵ�������ֶ�����ѧϰ��֮��,ģ�͵IJ��Ծ����ܴﵽ87%���Ҳ���������ѧϰ��ȥѵ��,����0.1ѵ����150��epoch,�����ֱַ�����0.01��0.001ѵ����60��epoch��ѵ��ʱ��loss��С��ѵ����������ͼ,ͼ����ÿ��ֵ��ͻ��������ֶ�������ѧϰ�ʡ�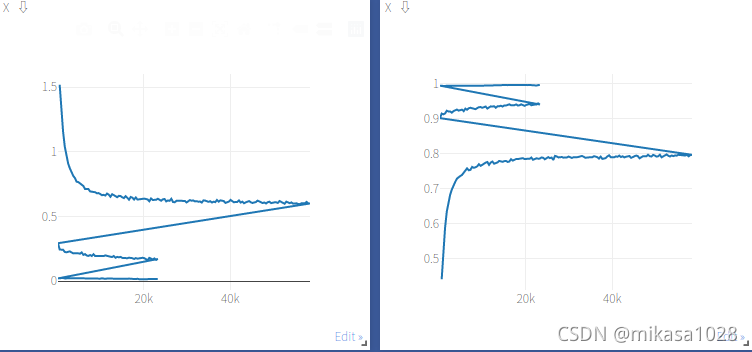
?���Ծ���
---epoch57---
25%|������ | 97/391 [00:03<00:08, 35.42it/s]epoch 57 iter 100 loss : 0.01788470149040222
50%|���������� | 197/391 [00:05<00:05, 35.00it/s]Setting up a new session...
epoch 57 iter 200 loss : 0.019015971571207047
epoch 57 iter 200 train_acc : 0.9937499761581421
77%|���������������� | 301/391 [00:09<00:02, 32.77it/s]epoch 57 iter 300 loss : 0.01771947182714939
100%|��������������������| 391/391 [00:11<00:00, 32.87it/s]
epoch 57 test_acc : 0.8694999814033508 ����һ��epoch����ʱ��:12.92395305633545s
---epoch58---
25%|������ | 97/391 [00:03<00:08, 33.84it/s]epoch 58 iter 100 loss : 0.01748574711382389
50%|���������� | 197/391 [00:06<00:06, 32.05it/s]Setting up a new session...
epoch 58 iter 200 loss : 0.016185222193598747
epoch 58 iter 200 train_acc : 0.9952343702316284
77%|���������������� | 301/391 [00:09<00:02, 35.15it/s]epoch 58 iter 300 loss : 0.015332281589508057
100%|��������������������| 391/391 [00:11<00:00, 33.29it/s]
epoch 58 test_acc : 0.8686999678611755 ����һ��epoch����ʱ��:12.811056137084961s
---epoch59---
26%|������ | 101/391 [00:03<00:08, 35.97it/s]epoch 59 iter 100 loss : 0.01672389917075634
50%|���������� | 197/391 [00:05<00:05, 32.87it/s]Setting up a new session...
epoch 59 iter 200 loss : 0.0159761980175972
epoch 59 iter 200 train_acc : 0.9956249594688416
76%|���������������� | 297/391 [00:08<00:02, 35.49it/s]epoch 59 iter 300 loss : 0.016513127833604813
100%|��������������������| 391/391 [00:11<00:00, 33.80it/s]
epoch 59 test_acc : 0.8678999543190002 ����һ��epoch����ʱ��:12.58652377128601s
�����ѽ���,�˳�����Ϊ 0
�����ܽ�
1.��SGD��һ��Ȩ��˥��,Ҫ��Ȼ�����ϵ���ѵ�����Ⱥܸ�,���Ծ��Ⱥܵ͡� 2.�ټ�һ��momentum,����ֵ��Ϊ0.9 3.��Ȩ��˥���IJ�����Ϊ5e-4 4.��batch_size��Ϊ128,һ��ʼ���õ�64������ʹģ�������ĺܺ� 5.ѵ��ʱ�������ĺܺ�ʱ,���Զ��һЩ������ǿ 6.Ϊ�����ѵ������,�����ֶ���ѧϰ�ʵķ�����100��epoch֮��,��ѧϰ�ʸ�Ϊ1e-3��ѵ��60��epoch
��һ���ֵĵ��ξ���ο���Pytorchʵս2:ResNet-18ʵ��Cifar-10ͼ�����(���Լ�����ȷ��95.170%)_sunqiande88�IJ���-CSDN����
��������Ըþ���ģ�ͻ��и��õ�trick���ߵ�������߲��Ծ���,������и��õľ��Ȼ��벻��ϧ��ķ��������������Ը�����,лл!