目录
1. LFM算法概述
对于基于邻域的机器学习算法来说,如果要给一个用户推荐商品,那么有两种方式。
一种是基于物品的,另一种是基于用户的。
基于物品的是,从该用户之前的购买商品中,推荐给他相似的商品。
基于用户的是,找出于该用户相似的用户,然后推荐给他相似用户购买的商品。
但是,推荐系统除了这两种之外,还有其他的方式。例如如果知道该用户的兴趣分类,可以给他推荐该类别的商品。
为了实现这一功能,我们需要根据用户的行为数据得到用户对于不同分类的兴趣,以及不同商品的类别归属。
1.1 类别归属
根据用户行为来划分每件商品的归属类别。该方式还有一个好处是,一个商品可以分别属于不同类别,只是在各个类别中的权重不一样。
1.2 用户对于各个类别的喜爱程度
用户对于不同的类别的喜好程度也不同,该算法可以根据用户的行为数据推测出用户对不同的类别的喜好。
1.3 LFM算法原理介绍
首先是数据的处理,由于使用的是隐性数据集,只有正样本,例如用户点击了某件商品,没有负样本。
数据处理主要是选出数据集的负样本。
负样本的选取策略主要有以下要点:
(1)正负样本要均衡,基本保证正负样本的比例1:1
(2)负样本需要选择用户没有行为的热门商品。
1.3.1 具体的例子介绍算法的思想
对于音乐,每一个用户都有自己的喜好,比如A喜欢带有小清新的、吉他伴奏的、王菲等元素(latent factor),如果一首歌(item)带有这些元素,那么就将这首歌推荐给该用户,也就是用元素去连接用户和音乐。每个人对不同的元素偏好不同,而每首歌包含的元素也不一样。
所以,我们希望能找到这样两个矩阵:潜在因子-用户矩阵Q、潜在因子-音乐矩阵P
(1)潜在因子-用户矩阵:表示不同的用户对于不用元素的偏好程度,1代表很喜欢,0代表不喜欢。

(2)潜在因子-音乐矩阵:表示每种音乐含有各种元素的成分,比如下表中,音乐A是一个偏小清新的音乐,含有小清新这个Latent Factor的成分是0.9,重口味的成分是0.1,优雅的成分是0.2......

利用这两个矩阵,我们能得出张三对音乐A的喜欢程度是
0.6*0.9 + 0.8*0.1 + 0.1*0.2 + 0.1*0.4 + 0.7*0 = 0.68
每个用户对每首歌都这样计算可以得到不同用户对不同歌曲的评分矩阵。

因此我们队张三推荐四首歌中得分最高的B,对李四推荐得分最高的C,王五推荐B。
基于上面的思想,基于兴趣分类的方法大概需要解决3个问题:
- ?如何对物品分类,以及如何确定这些物品在这个类中的权重?
- 如何确定用户对哪类物品感兴趣,以及感兴趣的程度
- 确定了用户的兴趣,选择这个类的哪些物品推荐给用户?
这个潜在因子(latent factor)――“类” 是怎么得到的呢?
由于面对海量的让用户自己给音乐分类并告诉我们自己的偏好系数显然是不现实的,事实上我们能获得的数据只有用户行为数据。我们沿用 @邰原朗的量化标准:单曲循环=5, 分享=4, 收藏=3, 主动播放=2 , 听完=1, 跳过=-2 , 拉黑=-5,在分析时能获得的实际评分矩阵R,也就是输入矩阵大概是这个样子:

事实上这是个非常非常稀疏的矩阵,因为大部分用户只听过全部音乐中很少一部分。如何利用这个矩阵去找潜在因子呢?这里主要应用到的是矩阵的UV分解。也就是将上面的评分矩阵分解为两个低维度的矩阵,用Q和P两个矩阵的乘积去估计实际的评分矩阵,而且我们希望估计的评分矩阵

1.3.2?LFM算法的求解
隐语义模型计算用户u对物品i兴趣的公式:
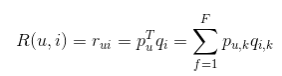
Pu,k表示用户u的兴趣和第k个隐类的关系,而Qi,k表示物品i与第k个隐类的关系。F为隐类的数量,r便是用户对物品的兴趣度。
接下的问题便是如何计算这两个参数p和q了,对于这种线性模型的计算方法,这里使用的是梯度下降法。大概的思路便是使用一个数据集,包括用户喜欢的物品和不喜欢的物品,根据这个数据集来计算p和q。
下面给出公式,对于正样本,我们规定r=1,负样本r=0:

有时会写成这种形式:

上式中后两项的是用来防止过拟合的正则化项,λ需要根据具体应用场景反复实验得到。损失函数的优化使用随机梯度下降算法:

迭代计算不断优化参数(迭代次数事先人为设置),直到参数收敛。

其中P矩阵表示:特定用户对特定类的喜好程度,Q表示特定电影属于特定类的权重。这样就实现了由用户行为对电影自动聚类。如果推荐一部电影给某个特定用户,通过查询这部电影在PQ矩阵内的具体值就能预测这个用户对这部电影的评分。
该模型的参数:

?2. LFM算法应用场景
根据上述内容,可以得到相应的模型输出,即两个潜在因子矩阵。其中,潜在因子的维度是之前设定的,可以理解为你认为有哪些特征可能会影响user对item的喜好程度。
那么得到模型输出后,如何应用?
(1)计算用户toplike:对于与用户没有被展示的item,可以计算出一个用户对item的倾向性得分,取top即toplike,后直接完成用户对item的喜爱度列表,写入离线即可完成对在线的推荐。
(2)计算item的topsim:得到item的向量可以用很多表示距离的公式包括cos等等,计算出每一个item的相似度矩阵,该矩阵可以用于线上推荐。当用户点击item之后,给其推荐与该item的topsim item。
(3)计算item的topic:根据得到的item向量,可以用聚类的方法,如K-means等等,取出一些隐含的类别。也就是一些隐含的topic能将item分成不同的簇,推荐时按簇推荐。