ЫЕУї:етЪЧвЛИіЛњЦїбЇЯАЪЕеНЯюФП(ИНДјЪ§Он+ДњТы+ЮФЕЕ+ДњТыНВНт),ШчашЪ§Он+ДњТы+ЮФЕЕ+ДњТыНВНтПЩвджБНгЕНЮФеТзюКѓЛёШЁЁЃ
АќКЌЫуЗЈ:RandomForestClassifierЁЂExtraTreesClassifierЁЂAdaBoostClassifierЁЂGradientBoostingClassifierЁЂSVCЁЃ
?
1.ЯюФПБГОА
? ? ? дкДѓЪ§ОнЪБДњ,ЮвУЧжегкгЕгаСЫЫуЗЈЫљашвЊЕФКЃСПЪ§ОнЁЃШчЙћАбЛњЦїбЇЯАБШзїЙЄвЕИяУќЪБЕФеєЦћЛњ,ФЧУДЪ§ОнОЭЪЧШМСЯЁЃгаСЫШМСЯ,ЛњЦїВХФмЙЛдЫзЊЁЃЦфДЮ,дкгВМўЗНУц,ЫцзХДцДЂФмСІЁЂМЦЫуФмСІЕФдіЧП,вдМАдЦЗўЮёЁЂGPU(зЈЮЊжДааИДдгЕФЪ§бЇКЭМИКЮМЦЫуЖјЩшМЦЕФДІРэЦї)ЕШЕФГіЯж,ЮвУЧМИКѕФмЙЛЫцвтЙЙНЈШЮКЮЩюЖШФЃаЭ(model)ЁЃStackingМЏГЩбЇЯАЗНЗЈПЩвдНЋЖржжЕЅвЛФЃаЭвдвЛЖЈЕФЗНЪНзщКЯЦ№РД,ЫќПЩвдНсКЯИїИіЕЅЯюдЄВтФЃаЭЕФгХЕу,ИќКУЕиНјаадЄВтЁЃ
? ? ? ?StackingМЏГЩбЇЯАЗНЗЈзюГѕгЩWolpertгк1992ФъЬсГіЁЃзїЮЊвЛжжаТаЫЕФЫуЗЈ,ЫќдкВЛЭЌСьгђОљгагІгУ,ВЂЧвШЁЕУСЫНЯЮЊВЛДэЕФНсЙћЁЃStackingЕФЬиБ№жЎДІдкгк,ЫќПЩвдШкКЯВЛЭЌжжРрЕФФЃаЭЁЃдкНтОіЗжРрЮЪЬтЪБ,вдвЛИіВуЪ§ЮЊ2ЕФStackingМЏГЩПђМмЮЊР§,вЛАуЕи,ПђМмЕФЕквЛВугЩЖрИіЛљЗжРрЦїзщГЩ,ИїЛљЗжРрЦїЕФЪфШыОљЮЊбЕСЗЪ§Он,ПђМмЕФЕкЖўВуЪЧдЊЗжРрЦї,дЊЗжРрЦїЕФбЕСЗЪ§ОнгЩЕквЛВуЛљЗжРрЦїЕФЪфГіКЭдЪМбЕСЗЪ§ОнЕФБъЧЉзщГЩ,дЊЗжРрЦїОЙ§бЕСЗКѓ,ОЭПЩвдЕУЕНЭъећЕФStackingМЏГЩФЃаЭЁЃ
2.Ъ§ОнЛёШЁ
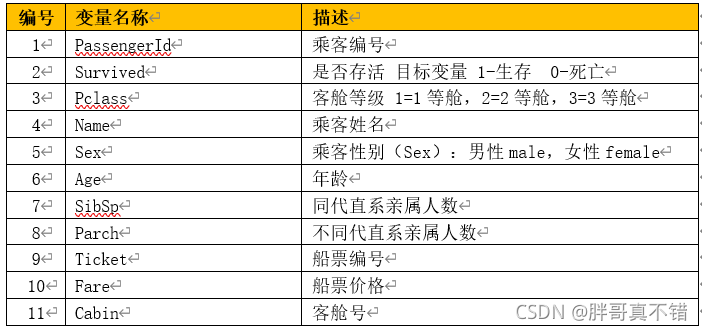
БОДЮНЈФЃЪ§ОнРДдДгкЭјТч(БОЯюФПзЋаДШЫећРэЖјГЩ),Ъ§ОнЯюЭГМЦШчЯТ:
?Ъ§ОнЯъЧщШчЯТ(ВПЗжеЙЪО):
3.Ъ§ОндЄДІРэ
? ? ? ецЪЕЪ§ОнжаПЩФмАќКЌСЫДѓСПЕФШБЪЇжЕКЭдывєЪ§ОнЛђШЫЙЄТМШыДэЮѓЕМжТгавьГЃЕуДцдк,ЗЧГЃВЛРћгкЫуЗЈФЃаЭЕФбЕСЗЁЃЪ§ОнЧхЯДЕФНсЙћЪЧЖдИїжждрЪ§ОнНјааЖдгІЗНЪНЕФДІРэ,ЕУЕНБъзМЕФЁЂИЩОЛЕФЁЂСЌајЕФЪ§Он,ЬсЙЉИјЪ§ОнЭГМЦЁЂЪ§ОнЭкОђЕШЪЙгУЁЃЪ§ОндЄДІРэЭЈГЃАќКЌЪ§ОнЧхЯДЁЂЙщдМЁЂОлКЯЁЂзЊЛЛЁЂГщбљЕШЗНЪН,Ъ§ОндЄДІРэжЪСПОіЖЈСЫКѓајЪ§ОнЗжЮіЭкОђМАНЈФЃЙЄзїЕФОЋЖШКЭЗКЛЏМлжЕЁЃвдЯТМђвЊНщЩмЪ§ОндЄДІРэЙЄзїжажївЊЕФдЄДІРэЗНЗЈ:
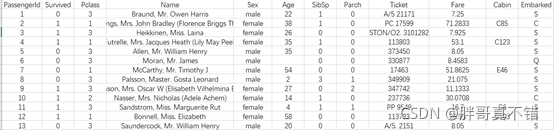
3.1 гУPandasЙЄОпВщПДЪ§Он
ЪЙгУPandasЙЄОпЕФhead()ЗНЗЈВщПДЧА6ааЪ§Он:
ЙиМќДњТы:
?
3.2ЖдЬиеїCabinНјааДІРэ
?ЪЙгУPandasЙЄОпЕФtype()ЗНЗЈРДВщРраЭЪЧЗёЮЊfloatРраЭ,РДХаЖЯГЫПЭЪЧЗёгаПЭВеКХ,ЙиМќДњТы:
3.3ЙЙНЈIsAloneЬиеї
ЭЈЙ§SibSp КЭ Parch ЬиеїЕФНсКЯ,РДЙЙНЈаТЕФЬиеїFamilySize;ЭЈЙ§FamilySizeЬиеїРДЙЙНЈIsAloneЬиеї;ЙиМќДњТыШчЯТ:
?
3.4ЬиеїEmbarkedКЭFareШБЪЇЪ§ОнДІРэ
EmbarkedЬиеїгУЁЏSЁЏРДЬюГфПежЕ, FareЬиеїгУжаЮЛЪ§РДЬюГфПежЕ,ЙиМќДњТыШчЯТ:
?
?
3.5ЙЙНЈCategoricalAgeЬиеї
ЭЈЙ§ФъСфЕФЦНОљжЕЁЂБъзМВюРДЙЙНЈФъСфЗжЖЮЬиеї,ЙиМќДњТыШчЯТ:
?
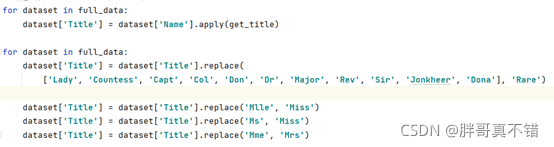
3.6ЙЙНЈTitleЬиеї
ЖдГЫПЭУћзжНјааЙцЗЖЛЏДІРэ,ЙиМќДњТыШчЯТ:
?
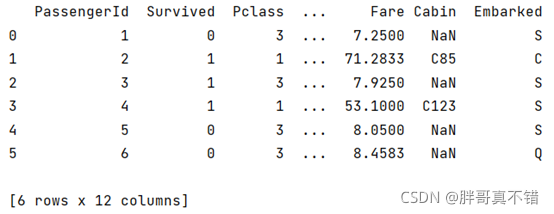
зюКѓеыЖдДІРэКѓЕФЬиеїНјааВщПД,НсЙћШчЯТ:
?
4.ЬНЫїадЪ§ОнЗжЮі
4.1 ЯрЙиадЗжЮі
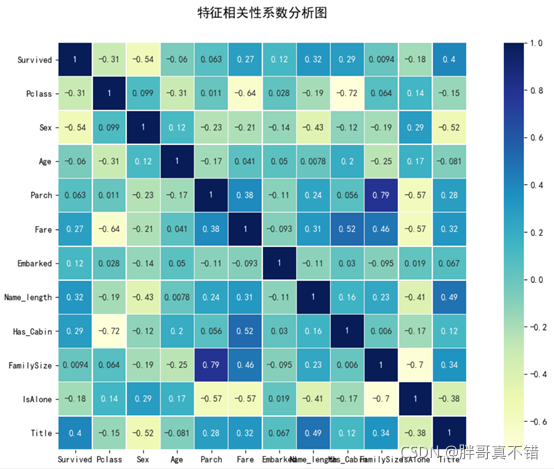
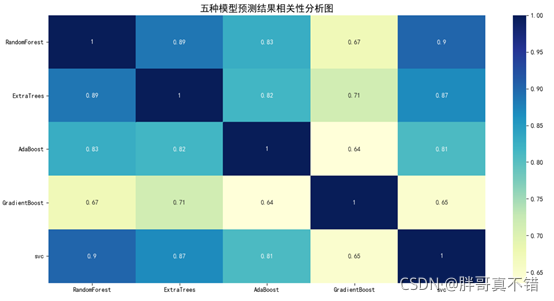
гУPandasЙЄОпЕФcorr()ЗНЗЈ matplotlib seabornНјааЯрЙиадЗжЮі,НсЙћШчЯТ:
?
ЭЈЙ§ЩЯЭМПЩвдПДЕН,Ъ§ОнЯюжЎМфе§жЕЪЧе§ЯрЙи/ИКжЕЪЧИКЯрЙи,Ъ§жЕдНДѓ ЯрЙиаддНЧПЁЃ
4.2 УПИіЬиеїЩњГЩХфЖдЭМ
етжжХфЖдЭМ,ПЩвдПДЕНУПСНИіЬиеїжЎМф еыЖдГЫПЭЪЧЗёЩњДцаЮГЩЖдБШ,ЗНБуЙлВьЬиеїЁЃР§Шч:ГЫПЭдк2ЕШВеЧвФъСфдНаЁ дНШнвзЩњДцЁЃ
5.ЬиеїЙЄГЬ
5.1 НЈСЂЬиеїЪ§ОнКЭБъЧЉЪ§Он
SurvivedЮЊБъЧЉЪ§Он,Г§ SurvivedжЎЭтЕФЮЊЬиеїЪ§ОнЁЃЙиМќДњТыШчЯТ:
?
6.ЙЙНЈStackingЗжРрФЃаЭ
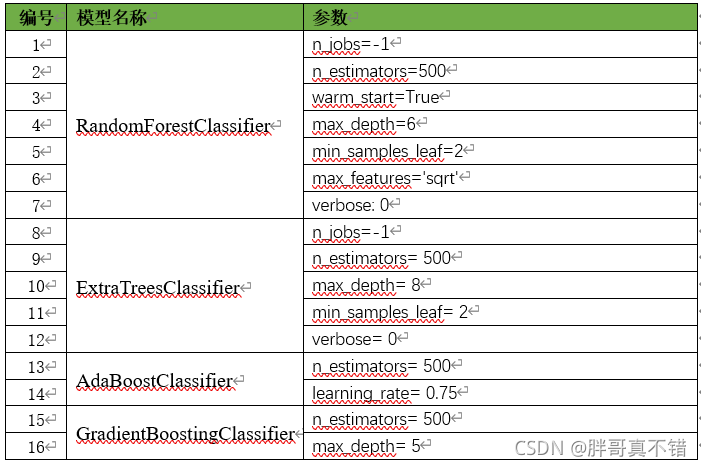
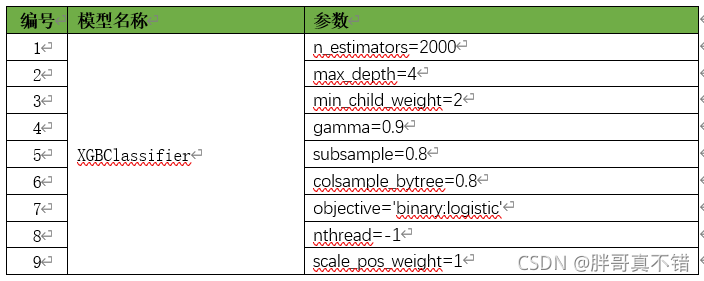
жївЊЪЙгУRandomForestClassifierЁЂExtraTreesClassifierЁЂAdaBoostClassifierЁЂGradientBoostingClassifierЁЂSVCЫуЗЈ,гУгкФПБъЗжРрЁЃЕквЛВуФЃаЭ:ЪЙгУЩЯУц5жжЫуЗЈНјааНЈФЃЁЂФтКЯЁЂдЄВт;ЕкЖўВуФЃаЭ:БОДЮЗжРрФЃаЭЪЧЪЙгУЧА5ИіФЃаЭЕФдЄВтНсЙћзїЮЊЬиеї,ВтЪдМЏЕФБъЧЉзїЮЊБъЧЉ,вдXGBClassifierЫуЗЈзїЮЊЛљЗжРрЦї,НјааНЈФЃЁЂФтКЯЁЂдЄВтЁЃ
6.1ЕквЛВуФЃаЭВЮЪ§
?ЙиМќДњТыШчЯТ:
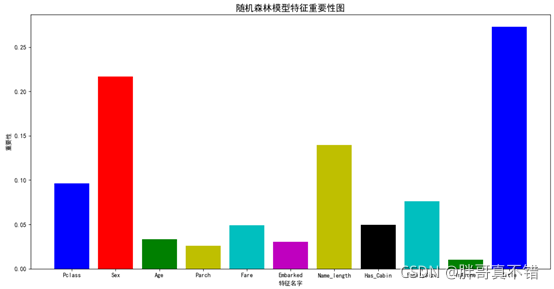
6.2ЕквЛВуФЃаЭЬиеїживЊад
?
ЭЈЙ§ЩЯЭМПЩвдПДГі,ЫцЛњЩСжФЃаЭЬиеїживЊадХХУћЮЊTitleЁЂSexЕШЁЃ
?
ЭЈЙ§ЩЯЭМПЩвдПДГі,МЋЖЫЫцЛњЪїФЃаЭЬиеїживЊадХХУћЮЊSexЁЂTitleЕШЁЃ
?
ЭЈЙ§ЩЯЭМПЩвдПДГі,AdaBoostФЃаЭЬиеїживЊадХХУћЮЊName_lengthЁЂTitleЕШЁЃ
?
ЭЈЙ§ЩЯЭМПЩвдПДГі,Gradient BoostФЃаЭЬиеїживЊадХХУћЮЊTitleЁЂName_lengthЕШЁЃ
?
ЭЈЙ§ЩЯЭМПЩвдПДГі,ЫљгаФЃаЭЬиеїживЊадХХУћЮЊName_lengthЁЂTitleЁЂSexЕШЁЃ
6.3 ЮхжжФЃаЭЯрЙиадЗжЮі
?
еыЖдЮхжжФЃаЭЕФдЄВтНсЙћНјааЯрЙиадЗжЮі,ЭЈЙ§ЩЯЭМПЩвдПДГіДѓгк0ЕФЮЊе§ЯрЙи Ъ§жЕдНДѓЯрЙиаддНЧП;аЁгк0ЕФЮЊИКЯрЙиЁЃ
6.4ЕкЖўВуФЃаЭВЮЪ§
ЙиМќДњТыШчЯТ:
?
7.ФЃаЭЦРЙР
7.1ЦРЙРжИБъМАНсЙћ
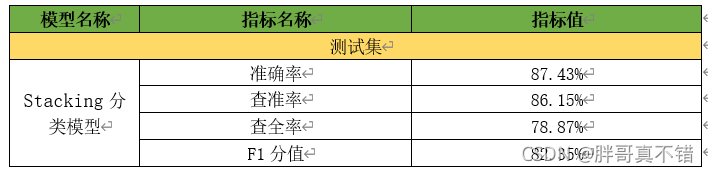
ЦРЙРжИБъжївЊАќРЈзМШЗТЪЁЂВщзМТЪЁЂВщШЋТЪЁЂF1ЗжжЕЕШЕШЁЃ
?ДгЩЯБэПЩвдПДГі,зМШЗТЪЮЊ87% ?F1ЗжжЕЮЊ82%,StackingЗжРрФЃаЭвВЯрЕБВЛДэЁЃ
ЙиМќДњТыШчЯТ:
7.2 ЗжРрБЈИц
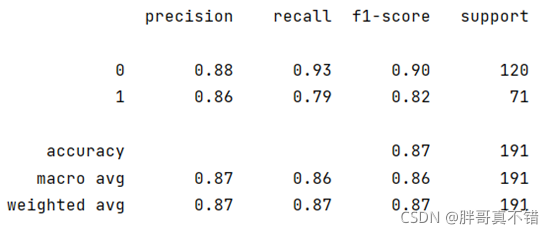
StackingЗжРрФЃаЭЗжРрБЈИц:
ДгЩЯЭМПЩвдПДЕН,ЗжРрРраЭЮЊ0ЕФF1ЗжжЕЮЊ0.90;ЗжРрРраЭЮЊ1ЕФF1ЗжжЕЮЊ0.82;ећИіФЃаЭЕФзМШЗТЪЮЊ0.87.
7.3 ROCЧњЯп
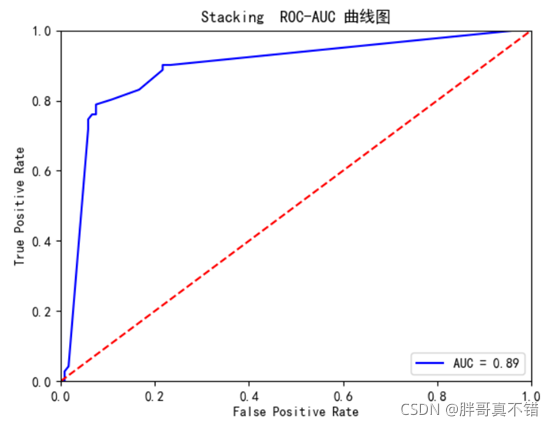
ДгЩЯЭМПЩвдПДГіAUCжЕЮЊ0.89,ФЃаЭвВЯрЕБВЛДэЁЃ
8.НсТлгыеЙЭћ
злЩЯЫљЪі,БОЮФВЩгУСЫStackingЗжРрФЃаЭ,зюжежЄУїСЫЮвУЧЬсГіЕФФЃаЭаЇЙћСМКУЁЃзМШЗТЪДяЕНСЫ93%,ПЩгУгкШеГЃЩњЛюжаНјааНЈФЃдЄВт,вдЬсИпМлжЕЁЃ








БОДЮЛњЦїбЇЯАЯюФПЪЕеНЫљашЕФзЪСЯ,ЯюФПзЪдДШчЯТ:
ЯюФПЫЕУї:
СДНг:https://pan.baidu.com/s/13r3-mTcCRBfwWRtbpnFUpw?
ЬсШЁТы:s2wnЭјХЬШчЙћЪЇаЇ,ПЩвдЬэМгВЉжїЮЂаХ:zy10178083