1. Convolutional Neural Network(CNN)
CNNДѓЖрЪ§гІгУгкгАЯёЗНУц,Р§ШчИјЛњЦївЛеХЭМЦЌ,ШУЛњЦїЪЖБ№ЭМЦЌжаЪЧЪВУДЖЋЮїЁЃ
вЛАуЪзЯШвЊМйЩшЭМаЮЕФДѓаЁЖМЪЧвЛбљЕФ,дйНјаабЕСЗ,ФПБъгУЖРШШТыЕФвЛИіvectorРД
y
y
yБэЪОЁЃ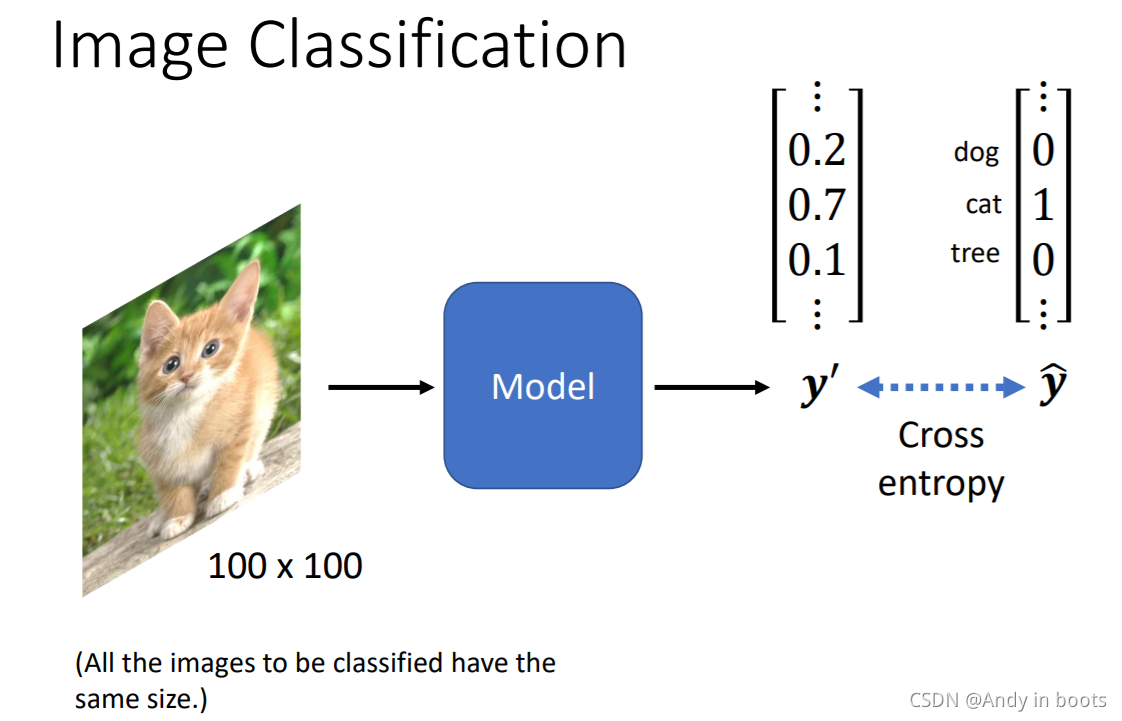
ЪзЯШ,ЮвУЧвЊЯШНЋгАЯёзЊЛЏЮЊЕчФдФмПДЖЎЕФаЮЪНЁЃ
ЖдгкЕчФдРДЫЕ,вЛеХЭМЦЌОЭЪЧвЛИіШ§ЮЌЕФTensorЁЃ
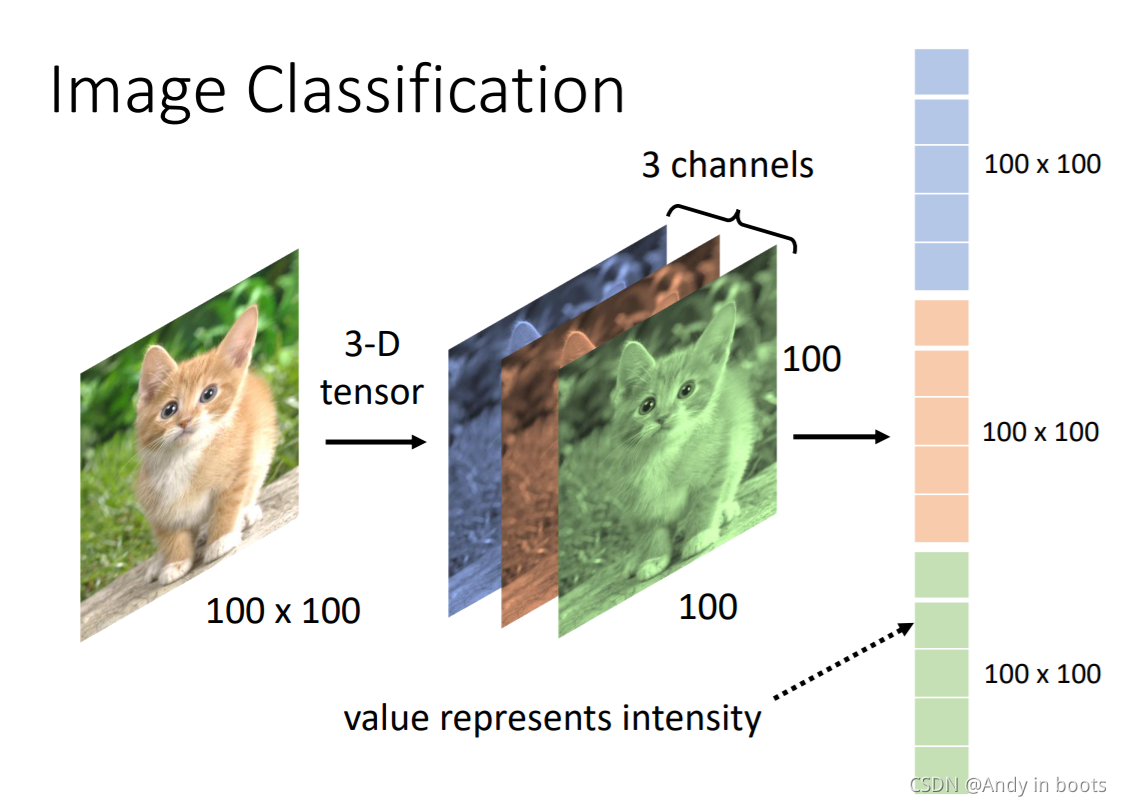
етШ§ЮЌЗжБ№ЪЧПэКЭИпвдМАЭЈЕРЪ§(RGB),ПэКЭИпДњБэСЫЯёЫиЕФЪ§СПЁЃЮвУЧЕФЪфШыЖМЪЧЯђСП,ЫљвдЮвУЧвЊАбЫќРГЩвЛИіЯђСПЁЃ
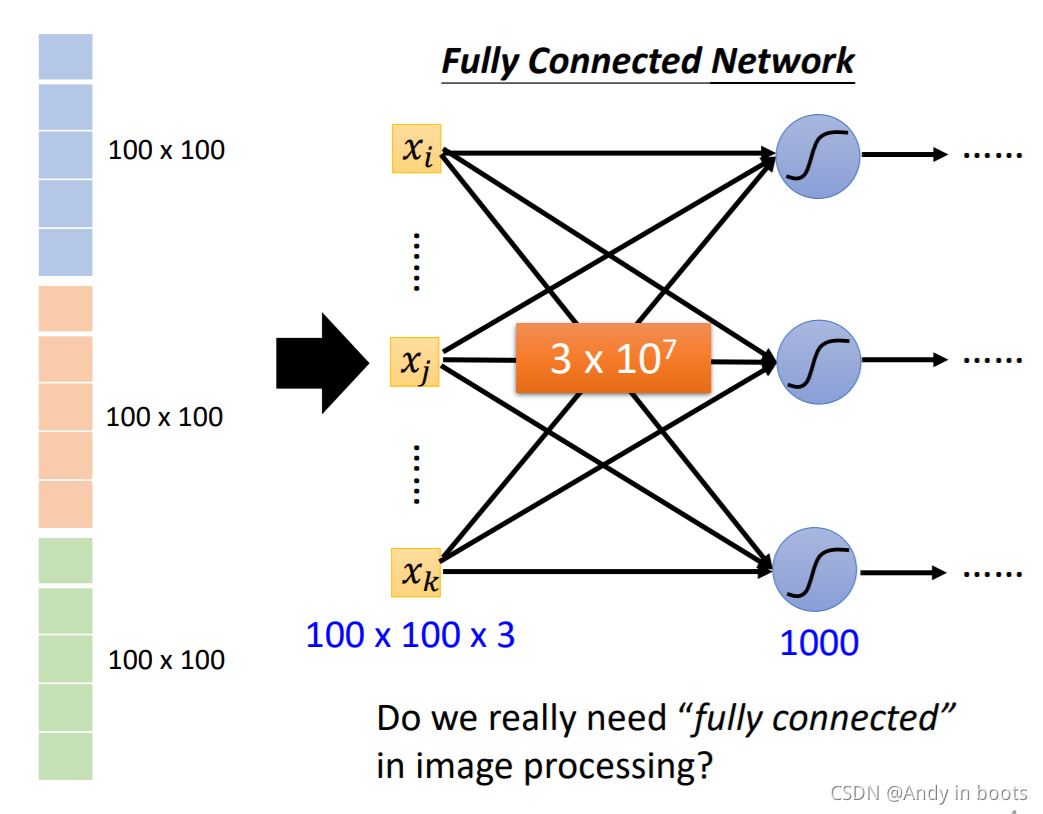
етбљЕФЛА,ЪфШыОЭЪЧ100x100x3ЕФЯђСП,етбљШчЙћвЛВуга1000ИіNeuron,ЕквЛВуЕФweightОЭЛсгаКмЖрЁЃетбљЖдгкШЋСЌНгВуРДЫЕ,КмШнвзВњЩњover fittingЁЃ

ЖдгкгАЯёРДЫЕ,ЦфЪЕдкЙ§ГЬжаашвЊМьВтЕНгаУЛгаГіЯжвЛаЉгагУЕФаЮЬЌЬиеї(pattern)ЁЃ
ОЭЫуЪЧШЫРр,дкЙлВьетеХЭМЦЌЕФЪБКђ,вВЪЧзЅШЁСЫЭМЦЌжаКмЯёФёзьЕФЬиеїНјааХаЖЯЁЃ
1.1 Neuron Version
ЮвУЧЛљгкЭМЦЌЕФетжжЬиад,ЖдЗНЗЈНјааСНЗНУцЕФМђЛЏ:
- ЪЙгУИаЪмвА
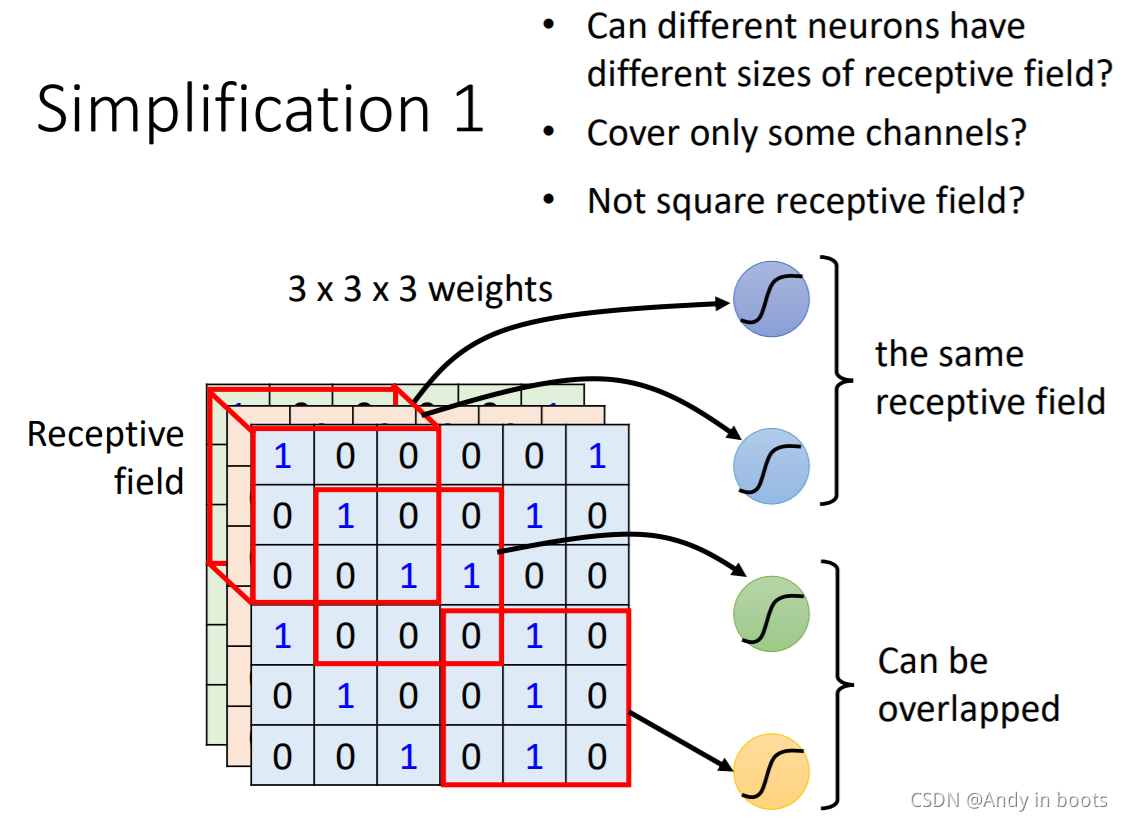
Ыљвд,ЮвУЧПЩвдЩшЖЈвЛаЉИаЪмвА,вЛИіЩёОдЊжЛашвЊЙизЂетвЛИіаЁЕФЧјгђОЭПЩвдСЫ,ЫќЕФЪфШыжЛашвЊЪЧетИіИаЪмвАРяЕФЪ§жЕЁЃ
ВЛЭЌЕФИаЪмвАжЎМфвВПЩвджиЕў,вЛИіИаЪмвАвВПЩвдгаЖрИіЩёОдЊНјааЙлВьЁЃОпЬхЕФИаЪмвАаЮзДЁЂГпДчДѓаЁЁЃЭЈЕРЕШВЮЪ§,ПЩвдздМКИљОнЖдЮЪЬтЕФРэНтздМКЩшЖЈЁЃ
 ДѓЖрЪ§ЪБКђ,ЖМбЁдёШ§ЭЈЕР,ЮвУЧАбИаЪмвАЕФГпДч(kernel size)ЩшжУЮЊ3x3,вЛАуЭЌвЛИіИаЪмвАЛсгавЛзщЩёОдЊШЅМьВтЫќ,ВНГЄвЛАуЩшжУЮЊ2ЁЃ
ДѓЖрЪ§ЪБКђ,ЖМбЁдёШ§ЭЈЕР,ЮвУЧАбИаЪмвАЕФГпДч(kernel size)ЩшжУЮЊ3x3,вЛАуЭЌвЛИіИаЪмвАЛсгавЛзщЩёОдЊШЅМьВтЫќ,ВНГЄвЛАуЩшжУЮЊ2ЁЃ
ЕБГЌГіСЫЭМЦЌЕФЗЖЮЇЪБвЛАуЛсзіpaddingРДВЙжЕЁЃ
-
ВЮЪ§ЙВЯэ
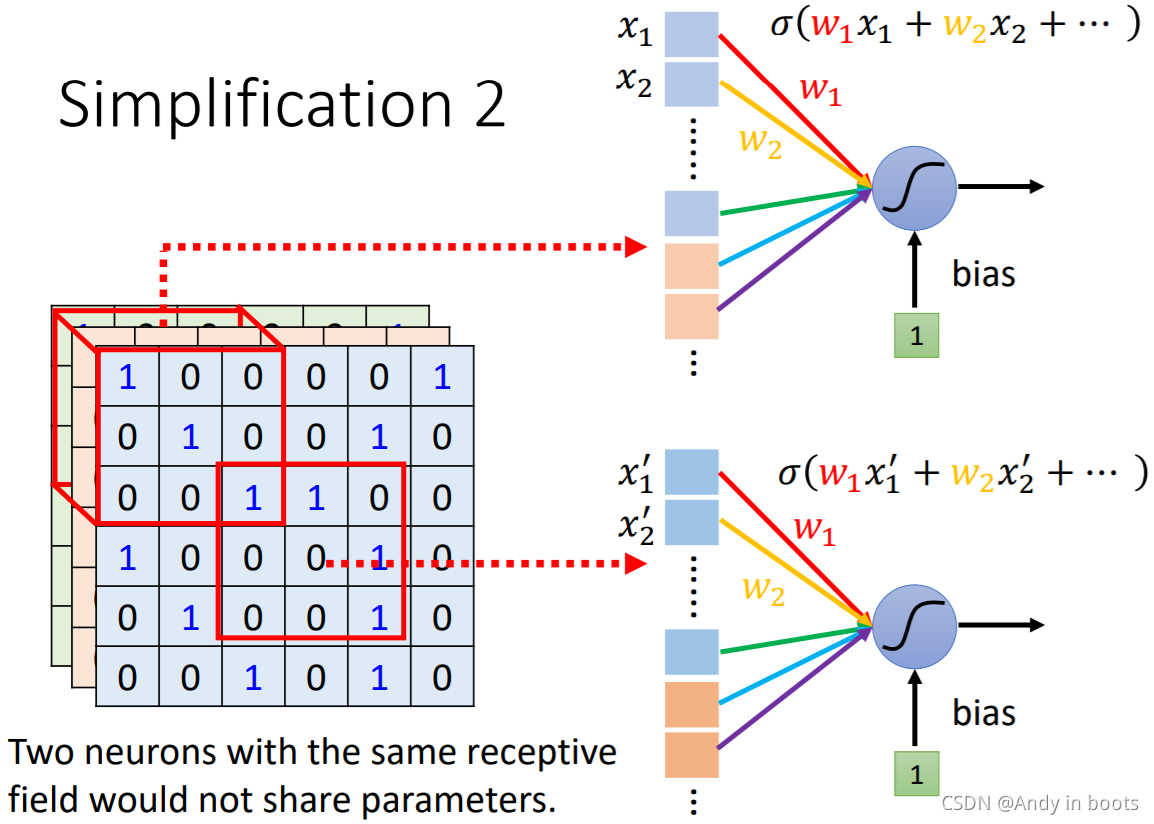
ЮвУЧЭЈЙ§ШУИїИіЩёОдЊЙВЯэВЮЪ§ЪЕЯжЖдШЋЭМЕФМьВт,ВЛТлЬиеїГіЯждкЭМжаФФИіЕиЗНЖМЛсБЛМьВтЕНЁЃ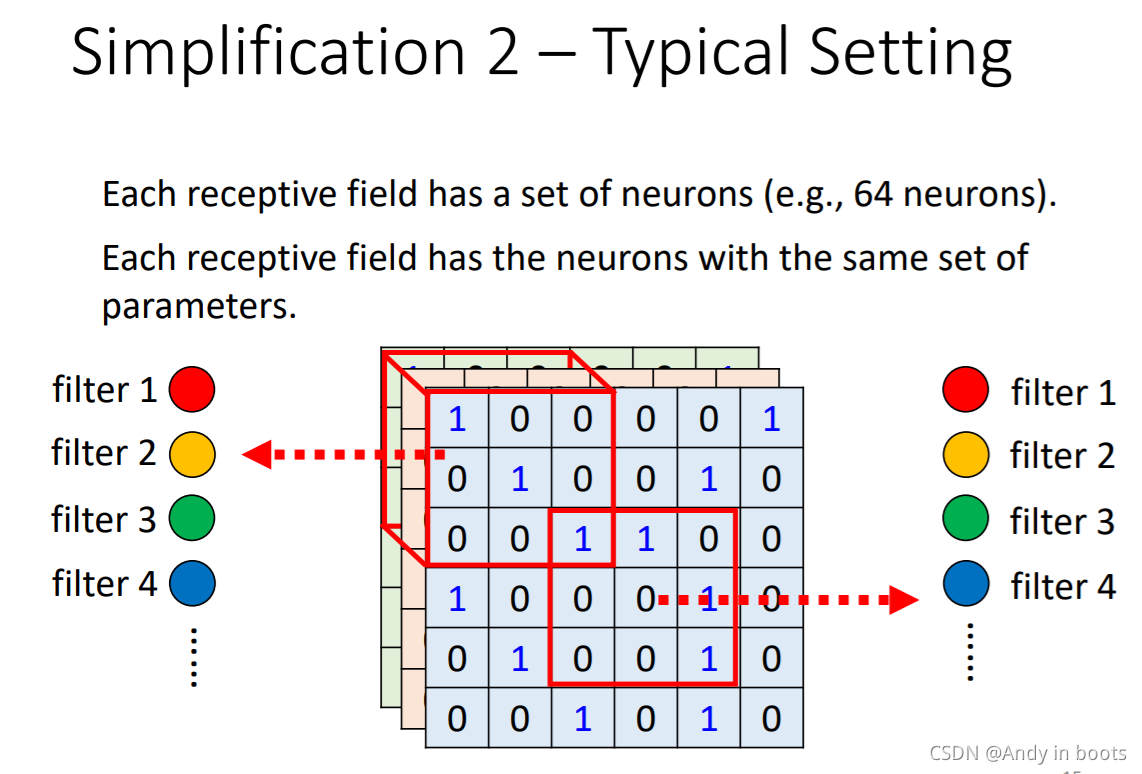
ЫљвдЦфЪЕзюКѓжЛгавЛзщЩёОдЊЕФВЮЪ§БЛУПвЛИіreceptive fieldЫљЙВгУ,етаЉЩёОдЊЙЋгУЕФВЮЪ§БЛГЦЮЊfilterЁЃ
ЖјReceptive Field + Parameter Sharing = Convolutional Layer
1.2 Filter Version Story
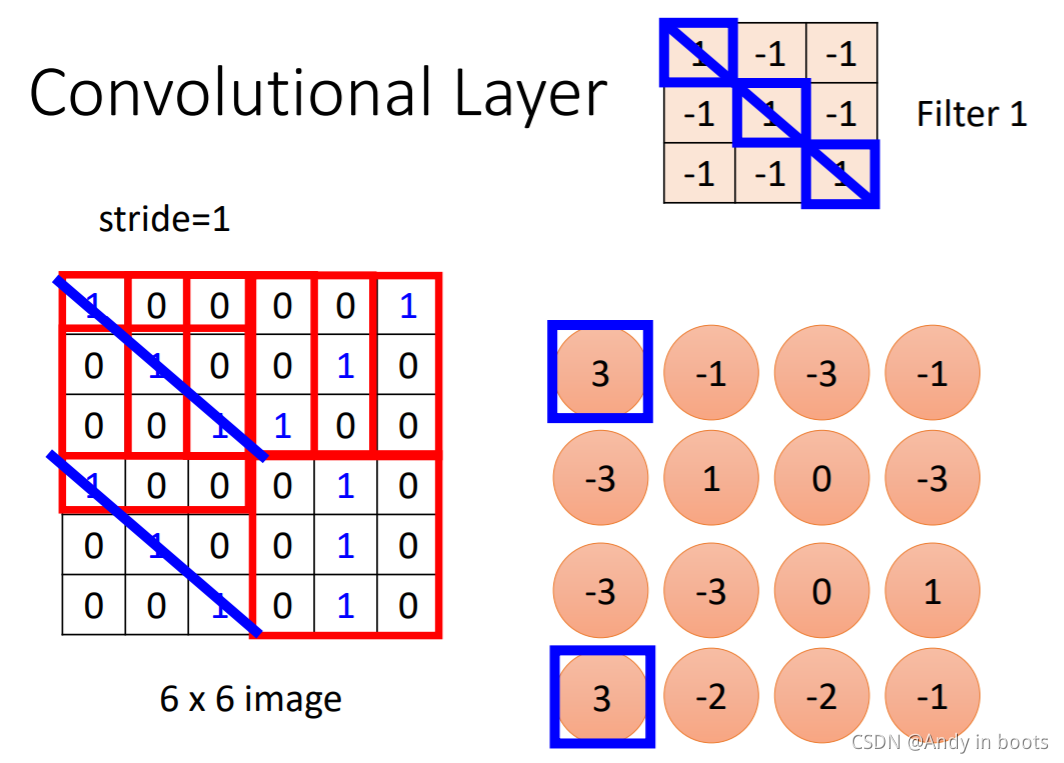
МйЩшFilterЕФЪ§жЕвбжЊ,ШчЭМЫљЪО,ЦфЪЕетИіfilterОЭЪЧдкЖдНЧЯпГіЯжШ§Иі1ЕФЪБКђЪ§жЕзюДѓ,етвВЪЧеввЛжжЬиеїЁЃ
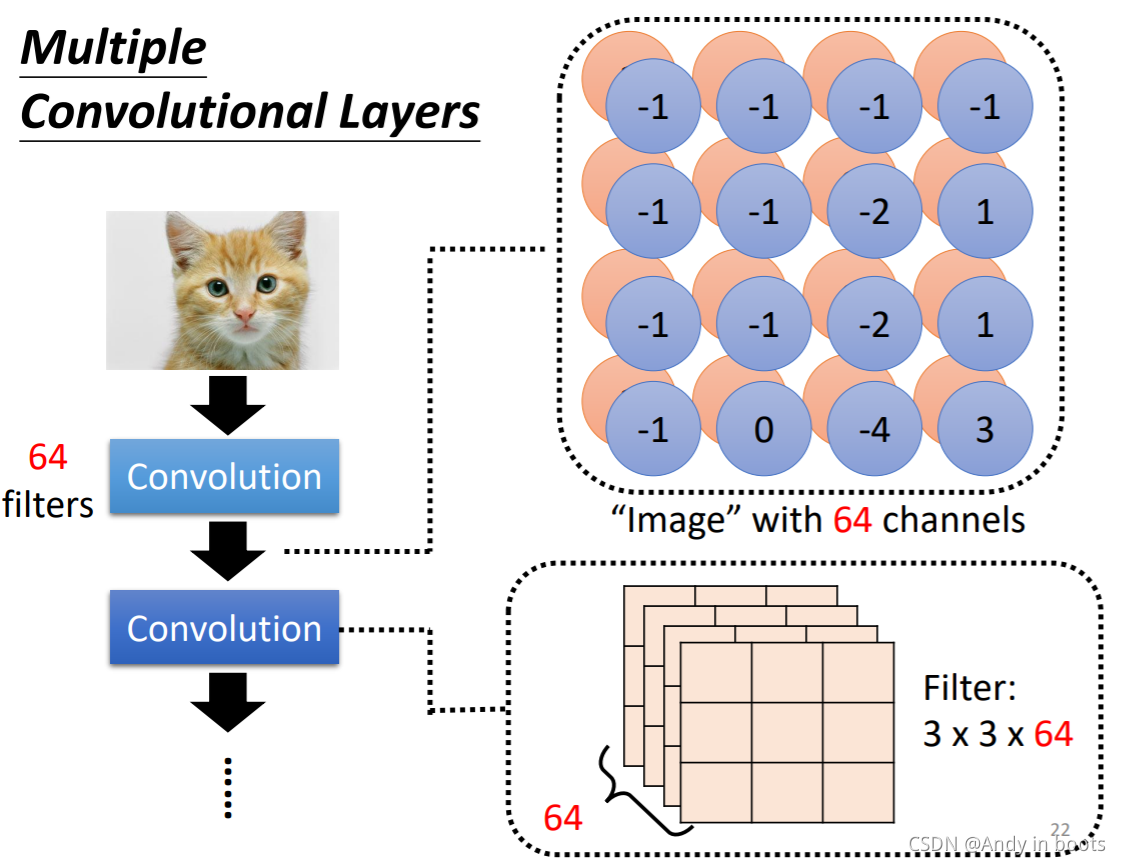
ОЙ§64ИіfilterФкЛ§КѓЕУЕНЕФНсЙћ,ЦДНгЦ№РДЦфЪЕвВПЩвдПДзївЛеХЬиЪтЕФЁАЭМЦЌЁБ,га64ИіЭЈЕРЁЃ
етЪБКђЕкЖўДЮЕФConvolutionВуЕФfilterОЭашвЊЪЧ3x3x64ЕФГпДчЁЃ
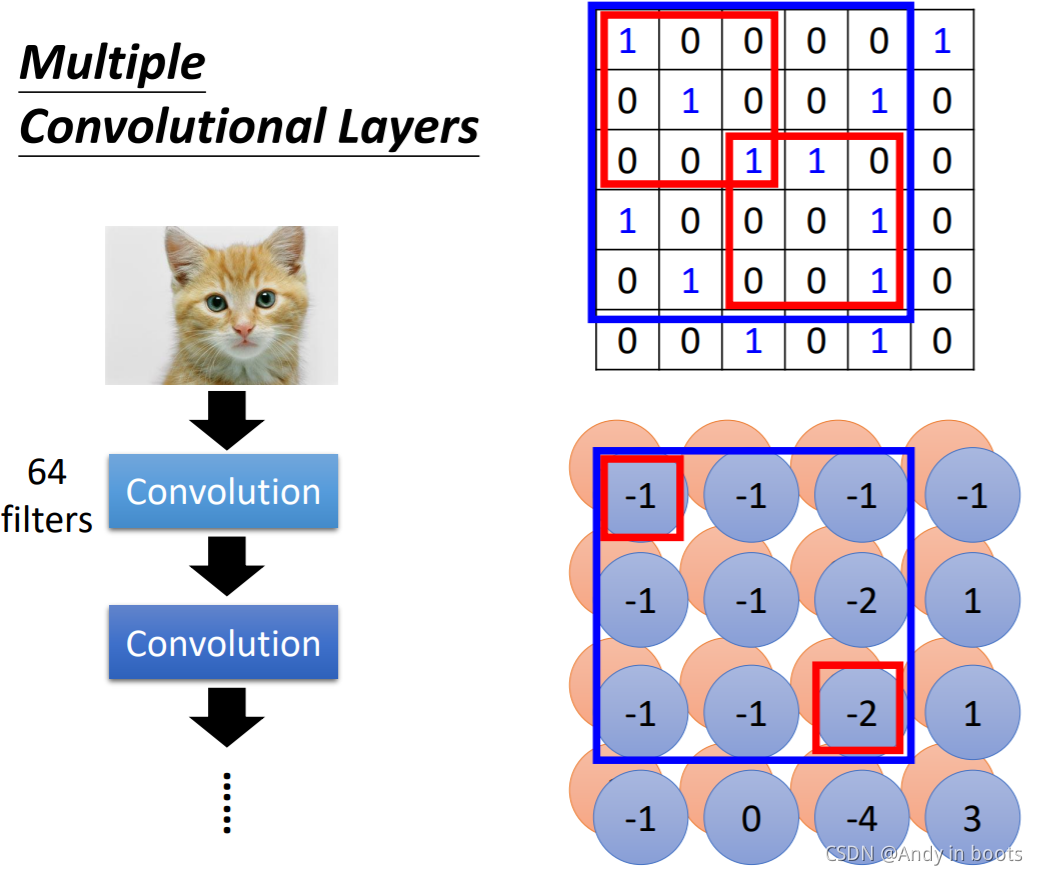
дкЕкЖўВуЕФОэЛ§Ву,ШчЙћгУЕФЛЙЪЧ3x3ЕФfilter,ЦфЪЕвбОПЩвдЛёЕУдЭМЦЌжа5x5ЕФЧјгђЬиеїСЫ,ЫљвдВЛгУЕЃаФ3x3ЕФЮоЗСЛёЕУНЯДѓЗЖЮЇЕФЬиеїЁЃжЛвЊВуЪ§дНЩю,МьВтЕНЕФЗЖЮЇОЭЛсдНДѓ!

ОэЛ§ВугыЩёОЭјТчЕФЙиЯЕ:
УПИіFilterОЭЪЧИїИіИаЪмвАЩЯЖдгІЩёОдЊЙВЯэЕФвЛзщВЮЪ§,FilterЕФИіЪ§ОЭЫЕУїСЫИаЪмвАЩЯгаЖрЩйИіЩёОдЊдкНјааЙлВтЁЃ
1.3 Pooling

АбДѓЭМЦЌБфаЁ,ВЂУЛгаВЮЪ§,жЛЪЧвЛИіВйзїЁЃMax PoolingОЭЪЧбЁдёвЛИіЗЖЮЇФкзюДѓЕФжЕЁЃ
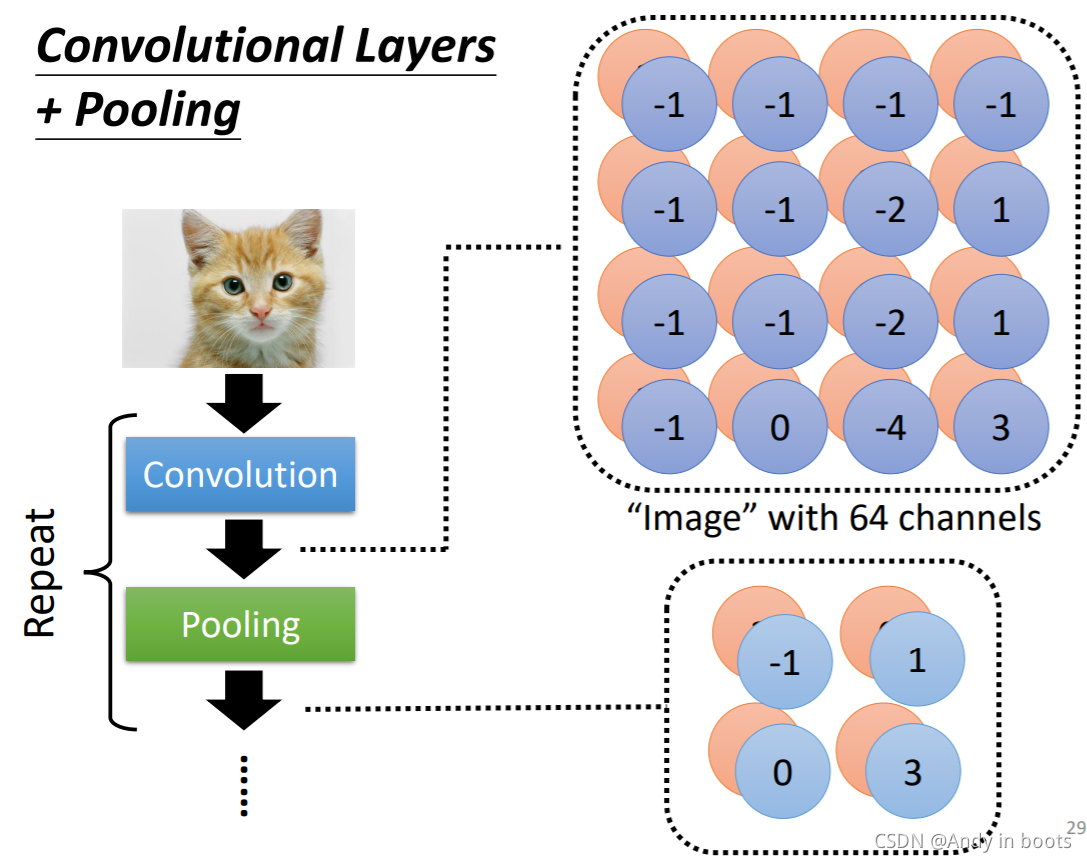
ЪЕМЪЩЯЮвУЧАбPoolingНсКЯЕНОэЛ§ВйзїКѓ,ЕЋгаЪБКђЛсдьГЩвЛаЉЁАЫ№ЩЫЁБЁЃ
НќФъРДКмЖрЪБКђЖМгУFull-Cov,ВЛгУPoolingЁЃвђЮЊpoolingЪЧгУРДМѕЩйМЦЫуСП,ЖјЫцзХЫуСІзЪдДЕФЗЂеЙОЭТ§Т§ВЛашвЊСЫЁЃ
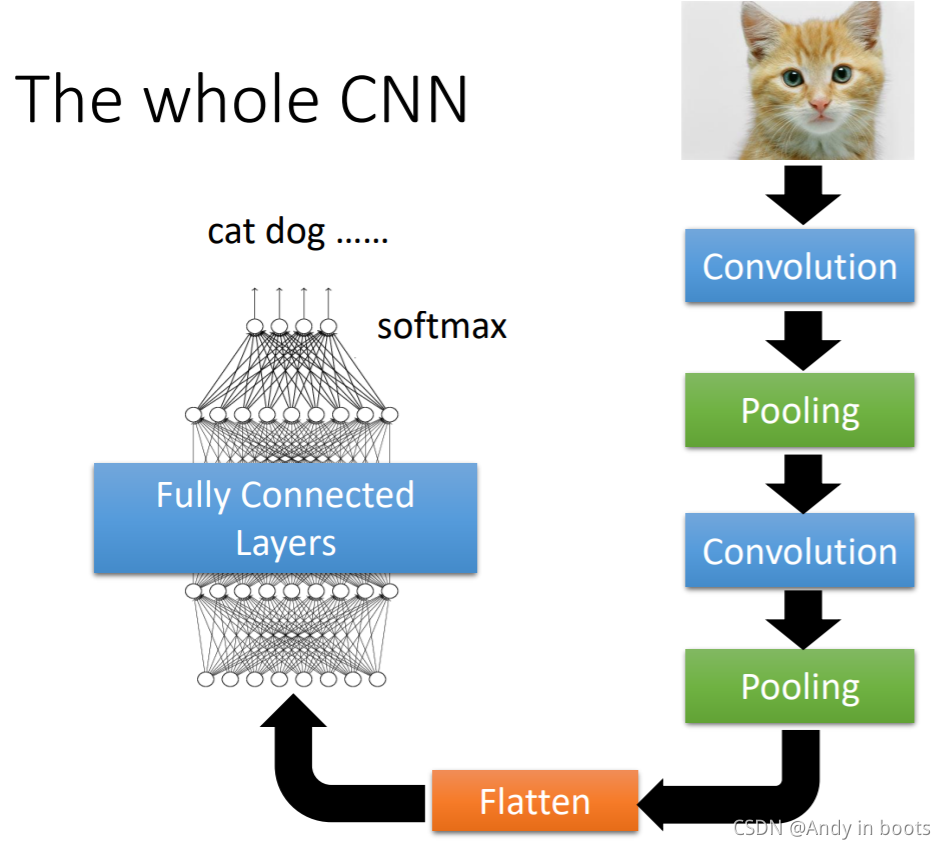
дкЗжРрЮЪЬтжазюКѓАбОэЛ§КѓЕФНсЙћРжБГЩвЛИіЯђСП(FlattenВйзї),ОЙ§вЛИіШЋСЌНгВуЁЂsoftmaxетаЉЗжРрЕФЛљБОВНжшОЭЭъ ГЩСЫЁЃ

ЮвУЧПЩвдЗЂЯждкAlpha GoжаВЂУЛгагУЕНpooling,ЫљвдЭјТчвЛЖЈвЊИљОнЧщПіНјааЩшМЦ,СЖЕЄвВвЊНВОПЗНЗЈЁЃ