基于 Weka 的数据库挖掘及数据预处理
关于作者
- 作者介绍
🍓 博客主页:作者主页
🍓 简介:JAVA领域优质创作者🥇、一名在校大三学生🎓、在校期间参加各种省赛、国赛,斩获一系列荣誉🏆。
🍓 关注我:关注我学习资料、文档下载统统都有,每日定时更新文章,励志做一名JAVA资深程序猿👨?💻。
文章目录
1、双击下面的 exe 程序进行安装
网盘链接:https://pan.baidu.com/s/1pTNWBHq5qdL1GaeZUh4uSQ 提取码:wpzr

2、出现欢迎窗口

3、单击 next 按钮进入下一步
同意 GNU GPL 协议,选择 I Agree 按钮

4、进入选择安装组件,默认选择 FULL,再单击 next

5、 选择安装路径

6、选择开始菜单文件夹名称
这里是 weka 3.8.4,没有特殊要求不需更改,单击 Install 安装完成即可。

7、安装完成后,可生成如下文件
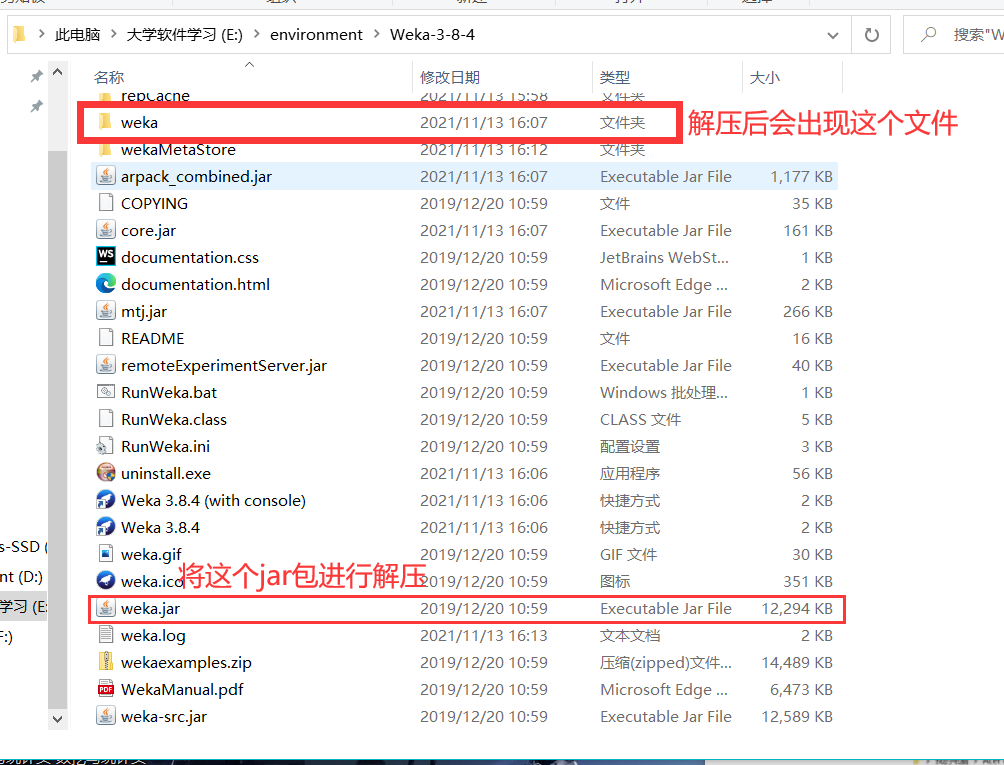
8、data 文件夹
这里需要看一下 data 文件夹,里面是 weka 自带 25个arff 文件作为测试数据集。
9、weka 的初步使用
在电脑的开始菜单里找到 Weka3.8.4 的子菜单,下面有三个菜单项,如下图,第一个菜单项:Documentation,提供weka 的参考资料,包括 Weka 手册、Java 包 API 文档及一些线资源。下面两个菜单项都可以启动Weka 界面,不同的是后者带有一个控制台的输出,而前者没有。
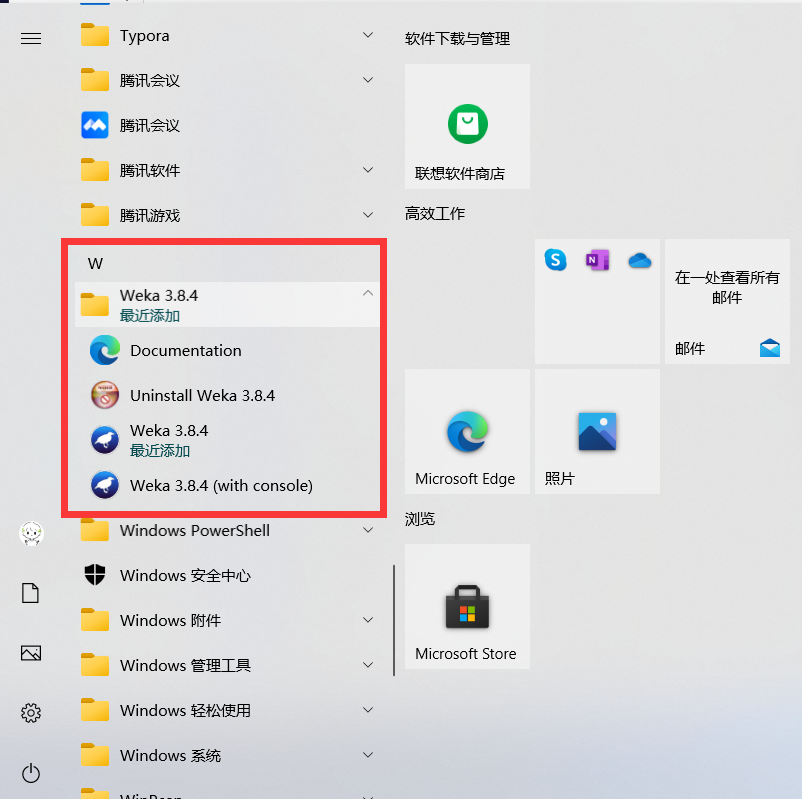
10、单击 weka3.8.4启动 weka 界面,并选择探索者界面 Explorer

进入探索者界面如下:

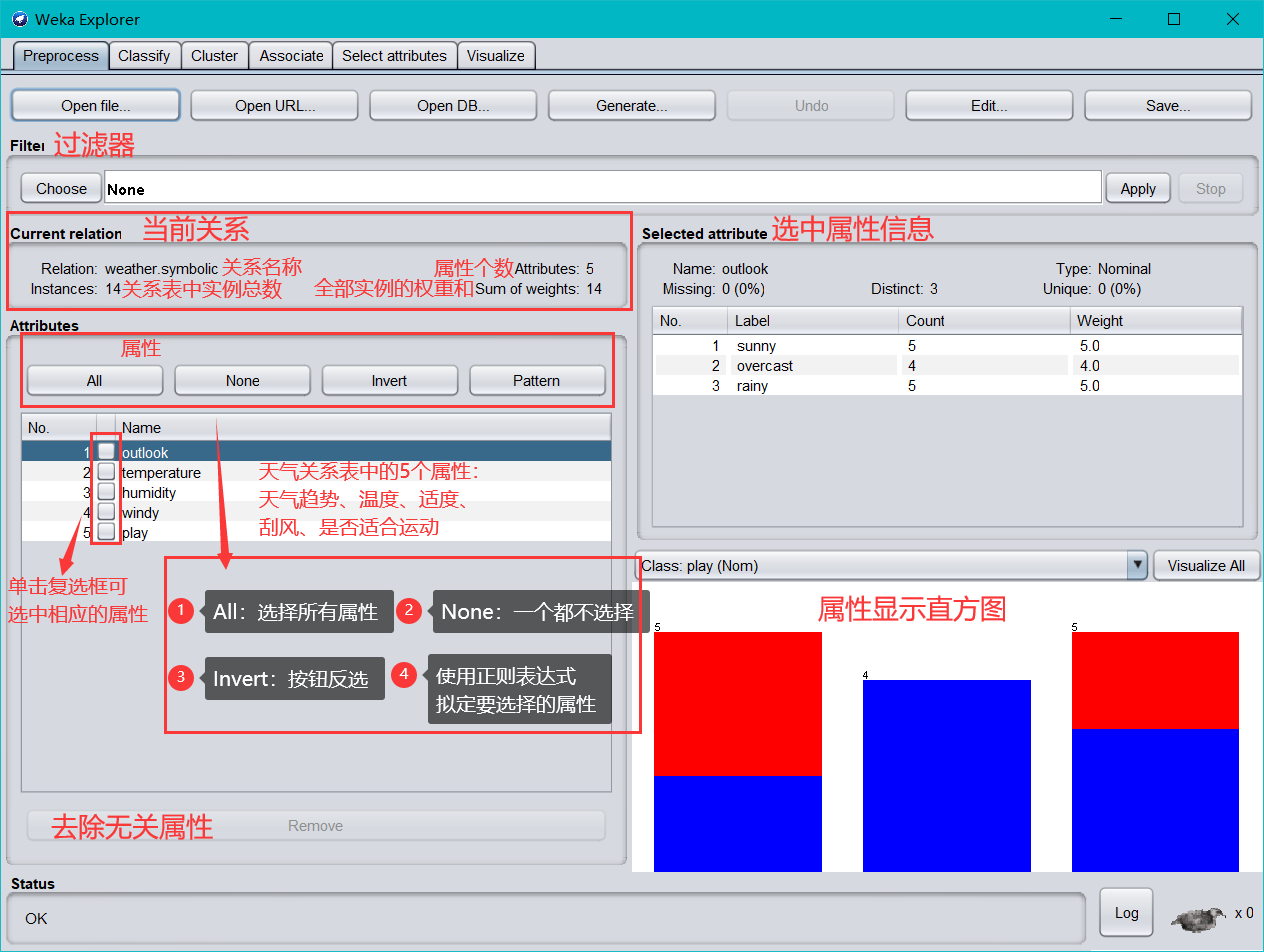
根据不同的功能把这个界面分成 8 个区域。
区域1 的几个选项卡是用来切换不同的挖掘任务面板。这一节用到的只有**“Preprocess”**,其他面板的功能将在以后介绍。
主界面最左上角(标题栏下方)的是标签栏,分为 6 个部分,功能
依次是:
Preprocess(数据预处理):选择和修改要处理的数据;
Classify(分类):训练和测试关于分类或回归的学习方案;
Cluster(聚类):从数据中学习聚类;
Associate(关联):从数据中学习关联规则;
Select attributes(属性选择):选择数据中最相关的属性;
Visualize(可视化):查看数据的交互式二维图像。
区域2是一些常用按钮。包括打开数据,保存及编辑功能、载入、编
辑数据
标签栏下方是载入数据栏,功能如下:
Open file:打开一个对话框,允许你浏览本地文件系统上的数据文
件(.dat);
Open URL:请求一个存有数据的 URL 地址;
Open DB:从数据库中读取数据;
Generate:从一些数据生成器中生成人造数据。
区域 3 中“Choose”某个“Filter”,可以实现筛选数据或者对数据进行某种变换。数据预处理主要就利用它来实现。
区域 4 展示了数据集的一些基本情况。
区域 5 中列出了数据集的所有属性。勾选一些属性并“Remove”就可以删除它们,删除后还可以利用区域 2 的“Undo”按钮找回。区域 5上方的一排按钮是用来实现快速勾选的。
在区域 5 中选中某个属性,则区域 6 中有关于这个属性的摘要。注意对于数值属性和分类属性,摘要的方式是不一样的。图中显示的是对数值属性“income”的摘要。
区域 7 是区域 5 中选中属性的直方图。若数据集的最后一个属性(我们说过这是分类或回归任务的默认目标变量)是分类变量(这里的“pep”正好是),直方图中的每个长方形就会按照该变量的比例分成不同颜色的段。要想换个分段的依据,在区域 7 上方的下拉框中选个不同的分类属性就可以了。下拉框里选上“No Class”或者一个数值属性会变成黑白的直方图。
区域 8 是状态栏,可以查看 Log 以判断是否有错。右边的 weka 鸟在动的话说明 WEKA 正在执行挖掘任务。右键点击状态栏还可以执行JAVA 内存的垃圾回收。
11、为了可以挖掘数据库中的数据,我们要将 Weka 和 MySQL 进行连接
(1)配置文件
-
如果 Weka 正在运行,先关闭 weka
-
在Weka下新建lib目录

-
查看自己数据库所兼容的jar包,这里我用的是5.1.49

-
配置环境变量
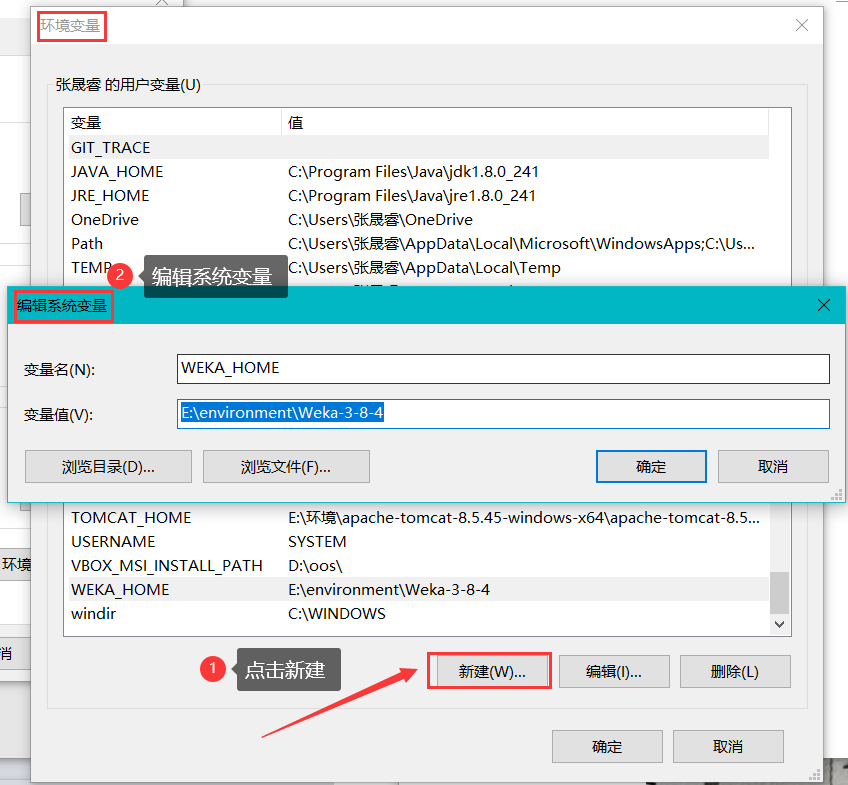
WEKA_HOME E:\environment\Weka-3-8-4 -
修改系统变量CLASSPATH
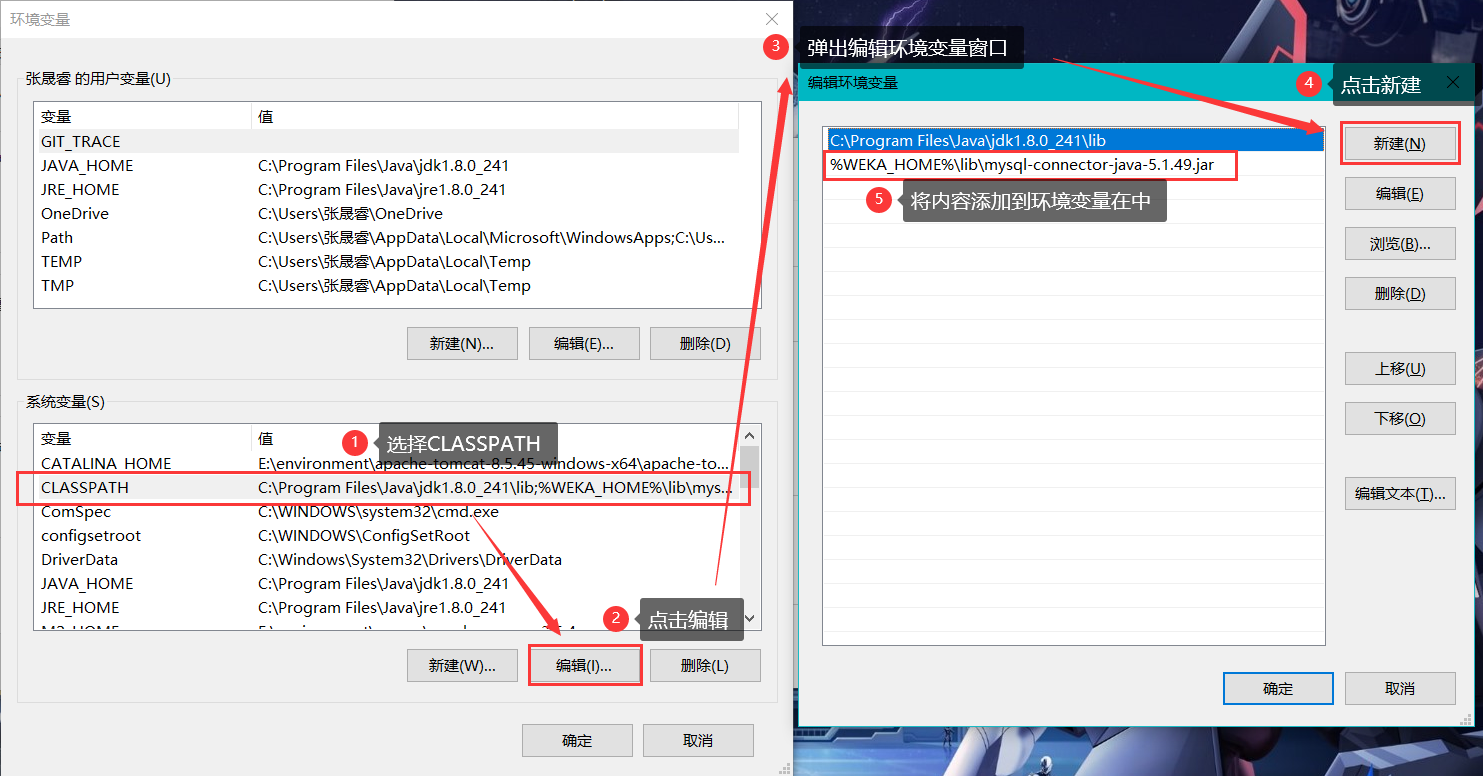
%WEKA_HOME%\lib\mysql-connector-java-5.1.49.jar
-
启动数据库运行,确保已建立名称为 weka 的数据库,并自行建表
-
修改以下目录中的 DatabaseUtils.props 文件(需要提前将 weka-3-8-4 文件夹下的 weka.jar 包解压才能找到)

以记事本打开该文件,文件内容如下:
# General information on database access can be found here:
# https://waikato.github.io/weka-wiki/databases/
#
# Version: $Revision: 15255 $
# The comma-separated list of jdbc drivers to use
#jdbcDriver=RmiJdbc.RJDriver,jdbc.idbDriver
#jdbcDriver=jdbc.idbDriver
#jdbcDriver=RmiJdbc.RJDriver,jdbc.idbDriver,org.gjt.mm.mysql.Driver,com.mckoi.JDBCDriver,org.hsqldb.jdbcDriver
jdbcDriver=com.mysql.jdbc.Driver
# The url to the experiment database
#jdbcURL=jdbc:rmi://expserver/jdbc:idb=experiments.prp
jdbcURL=jdbc:mysql://localhost:3306/weka
#jdbcURL=jdbc:mysql://mysqlserver/username
# the method that is used to retrieve values from the db
# (java datatype + RecordSet.<method>)
# string, getString() = 0; --> nominal
# boolean, getBoolean() = 1; --> nominal
# double, getDouble() = 2; --> numeric
# byte, getByte() = 3; --> numeric
# short, getByte()= 4; --> numeric
# int, getInteger() = 5; --> numeric
# long, getLong() = 6; --> numeric
# float, getFloat() = 7; --> numeric
# date, getDate() = 8; --> date
# text, getString() = 9; --> string
# time, getTime() = 10; --> date
# timestamp, getTime() = 11; --> date
# the original conversion: <column type>=<conversion>
#char=0
#varchar=0
#longvarchar=0
#binary=0
#varbinary=0
#longvarbinary=0
#bit=1
#numeric=2
#decimal=2
#tinyint=3
#smallint=4
#integer=5
#bigint=6
#real=7
#float=2
#double=2
#date=8
#time=10
#timestamp=11
#mysql-conversion
CHAR=0
TEXT=0
VARCHAR=0
LONGVARCHAR=9
BINARY=0
VARBINARY=0
LONGVARBINARY=9
BIT=1
NUMERIC=2
DECIMAL=2
FLOAT=2
DOUBLE=2
TINYINT=3
SMALLINT=4
#SHORT=4
SHORT=5
INTEGER=5
BIGINT=6
LONG=6
REAL=7
DATE=8
TIME=10
TIMESTAMP=11
#mappings for table creation
CREATE_STRING=TEXT
CREATE_INT=INT
CREATE_DOUBLE=DOUBLE
CREATE_DATE=DATETIME
DateFormat=yyyy-MM-dd HH:mm:ss
#database flags
checkUpperCaseNames=false
checkLowerCaseNames=false
checkForTable=true
setAutoCommit=true
createIndex=false
# All the reserved keywords for this database
Keywords=\
AND,\
ASC,\
BY,\
DESC,\
FROM,\
GROUP,\
INSERT,\
ORDER,\
SELECT,\
UPDATE,\
WHERE
# The character to append to attribute names to avoid exceptions due to
# clashes between keywords and attribute names
KeywordsMaskChar=_
#flags for loading and saving instances using DatabaseLoader/Saver
nominalToStringLimit=50
idColumn=auto_generated_id
修改完之后,可将 DatabaseUtils.props 文件放在如下两个目录之一
A. 当前目录即可,即不改变它的位置
B. 若第一个目录不行,则把它放在用户目录中,若不知道自己的用户目录,在命 令 行 输 入 echo %USERPROFILE%, 即 可 找 到 用 户 目 录 路 径 , 将DatabaseUtils.props 文件放在用户目录的下的 wekafiles\props 子目录中,并把原来路径中的 DatabaseUtils.props 删掉。
(2)数据库设置
- 进入 weka 的探索者界面,单击 OPEN DB,进入 SQL 查看器,可以看到 URL 文本框的内容已变成前文修改的配置文件中的 jdbcURL 值。

- 单击如下按钮,连接数据库,如果前面设置无误,会在 SQL 查看器下,出现数据库连接成功的提示

(3)查询 Weka 数据库中 student 表中的数据

 注意:如果连接不上数据库,可按如下顺序依次查找:数据库驱动程序是否正确;CLASSPATH 的设置是否正确(用户变量);配置文件中的 jdbcDriver 和 jdbcURL 两项配置的拼写是否正确;配置文件是否放到了正确的路径;数据库用户名和密码是否正确;该数据库用户是否拥有足够的权限;数据库是否已经启动等其他问题。
注意:如果连接不上数据库,可按如下顺序依次查找:数据库驱动程序是否正确;CLASSPATH 的设置是否正确(用户变量);配置文件中的 jdbcDriver 和 jdbcURL 两项配置的拼写是否正确;配置文件是否放到了正确的路径;数据库用户名和密码是否正确;该数据库用户是否拥有足够的权限;数据库是否已经启动等其他问题。
12、使用 weka 进行数据预处理
Preprocess 标签可用于从文件、URL 或数据库中加载数据集,并且根据应用要求或领域知识过滤掉不需要进行处理或不符合要求的数
据。
(1)加载数据
- 单击 open file ,在 weka 的安装目录下选择 data 文件,打开 data 文件,选择 weather.nominal.arff 数据集。

- 加载数据后,出现如下数据信息:
(2)使用数据集编辑器修改数据
加载天气数据集后,单击 Preprocess 标签页中的 Edit 按钮,弹出如下对话框,列出全部天气数据。

在这个界面可以手动删除一些属性或者实例,或者修改数据
(3)使用过滤器删除属性
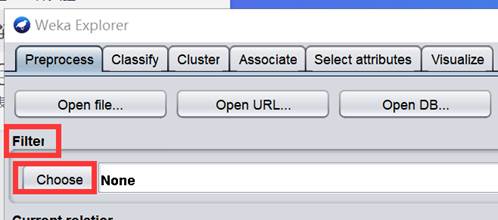
-
加载天气数据后,在 Filter 下单击 Choose 按钮
-
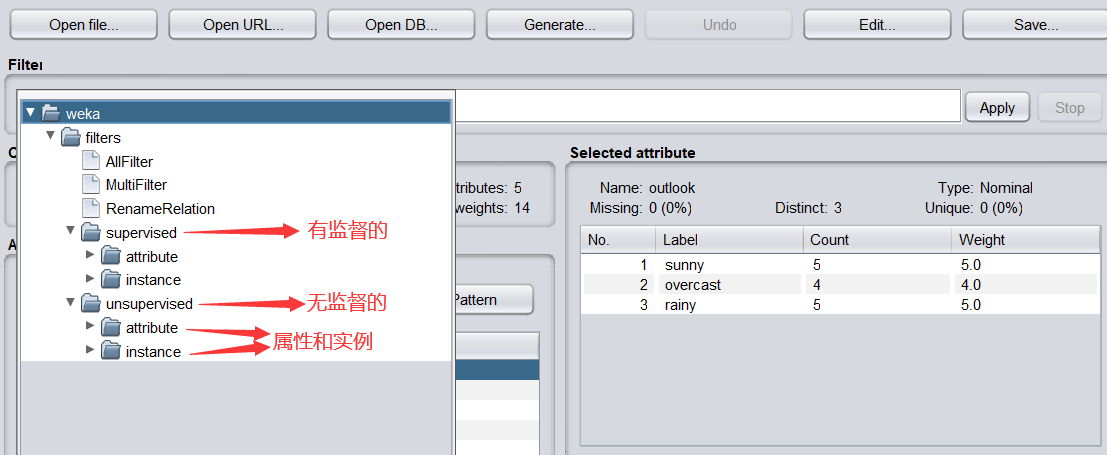
打开过滤器分层列表,如下图,有两种过滤算法,一种有监督,一种无监督,前者使用类别属性,后者不使用,继续往下是属性和实例,前者主要处理有关属性的过滤,后者处理有关实例的过滤。
-
适合删除属性的的过滤器是 Remove,我们在unsupervised(无监督)―>attribute―> Remove 条目,单击选择该过滤器,Choose 右侧文本框就会显示。Remove,如下图

- 再单击该文本框,打开通用对象编辑器对话框以设置参数,如下图

- 设置完参数,点击 Ok,回到以下界面,文本框显示:remove -R 2,含义是删除数据集中的第二个属性。单击右边的 Apply 过滤器生效。

- 可单击 edit 按钮,查看删除属性后的结果,但这种方法只能改变内存中的数据,不会影响数据集文件中的内容,要想保存该文件,可通过 save 按钮保存删除属性后的文件。
(4)使用过滤器添加属性
- 仍然是单击 Choose 按钮,依次 weka―>filter―>unsupervised(无监督)―>attribute―>AddUserFiledss过滤器
- 单击 Choose 旁边的文本框,打开通用对象编辑器对话框以设置参数,单击 New 按钮,设置属性名称为 mode,属性类型为 Nominal,其他不设置,单击 Ok

- 单击 Ok,出现如下,再单击 Apply,会发现属性选项组的属性表格中多了一个 mode 属性。

- 单击 Edit,打开 Vierwer 对话框,可以看到新增的属性并没有值

- 继续单击 Choose 按钮,选择unsupervised(无监督)―>attribute―>AddValues过滤器,单击该文本框,出现如下对话框,在 labels 标签设置 mode 的取值。


- 再次单击 Edit 按钮,打开 Viewer 对话框,如下图,可以看到新增的属性下拉列表框有取值了。

? 我们可以看到上表中 mode 属性在最后一列,这个天气数据集的最后一列应该是类别属性 play,根据其他条件属性的取值,比如晴天,温度/湿度适宜,没风等条件来判断是否适合外出运动,所以这里我们需要将 mode 属性和 play 属性调换一下位置。继续选择unsupervised(无监督)―>attribute―>Reorder过滤器,再单击 choose 旁边的文本框,弹出如下图,设置参数为 1,2,3,4,6,5 相当于将第五列和四列调换位置。

- 最后再单击 Edit 按钮,打开 Viewer 对话框,如下图,可以看到 mode 和 play 交换了位置。

(5)使用过滤器删除实例
A.选择
- choose―>weka―>filter―>unsupervised―>instance―>RemoveFolds过滤器

-
过滤器将数据集分割为给定的交叉验证折数,并指定输出第几折。点击Choose 旁边的文本框,弹出如下对话框

-
单击 ok-Apply,然后查看数据会发现,14 条数据只剩两条了

B.选择
-
choose―>weka―>filter―>unsupervised―>instance―>RemovePercentage过滤器

-
过滤器删除数据集中给定百分比的实例,点击 Choose 旁边的文本框,弹出如下对话框

-
单击 ok-Apply,然后查看数据会发现,14 条数据只剩 7 条了。
C.选择
-
choose―>weka―>filter―>unsupervised―>instance―>RemoveRange过滤器

-
过滤器删除数据集中给定范围的实例,点击 Choose 旁边的文本框, 弹出如下:

-
单击 ok-Apply,然后查看数据会发现,14 条数据只剩 11 条了,第 3-5条数据被删掉了。
应用:使用 weka 将数据离散化
? Weka 中数据类型有标称型(nominal),只能取预定义值列表中的一个;数值型(numeric),只能是实数或整数;字符串类型(String),由双引号引用的任意长度的字符列表;还有日期型(Date)和 关系型(Relational)。
? 如果数据集包含数值型属性,所用的学习方案只能处理标称型属性的分类,则将数值型属性离散化是必要的。有两种类型的离散化技术-无监督离散和有监督离散化,前者不需要也不关注类别属性值,后者在创建间隔时考虑实例的类别属性值。离散化数值型属性的直观方法是将值域分隔为多个预先设定的间隔区间。
1、无监督离散化有等宽和等频离散化。
等宽离散化(等宽分箱):将数值型属性从最小值到最大值平均分为十份,即将数值从最小值到最大值分成 10 个区间,这样每个区间所包含的实例数量就各不相等,从而造成实例分布不均匀,有的间隔区域内包含很多个实例,但有的却很少甚至没有。
等频离散化:按数值型属性的大小顺序将全部实例平均分成十份,如 200 条实例,先按取值大小排好顺序,再每 20 条一份,分成十份。
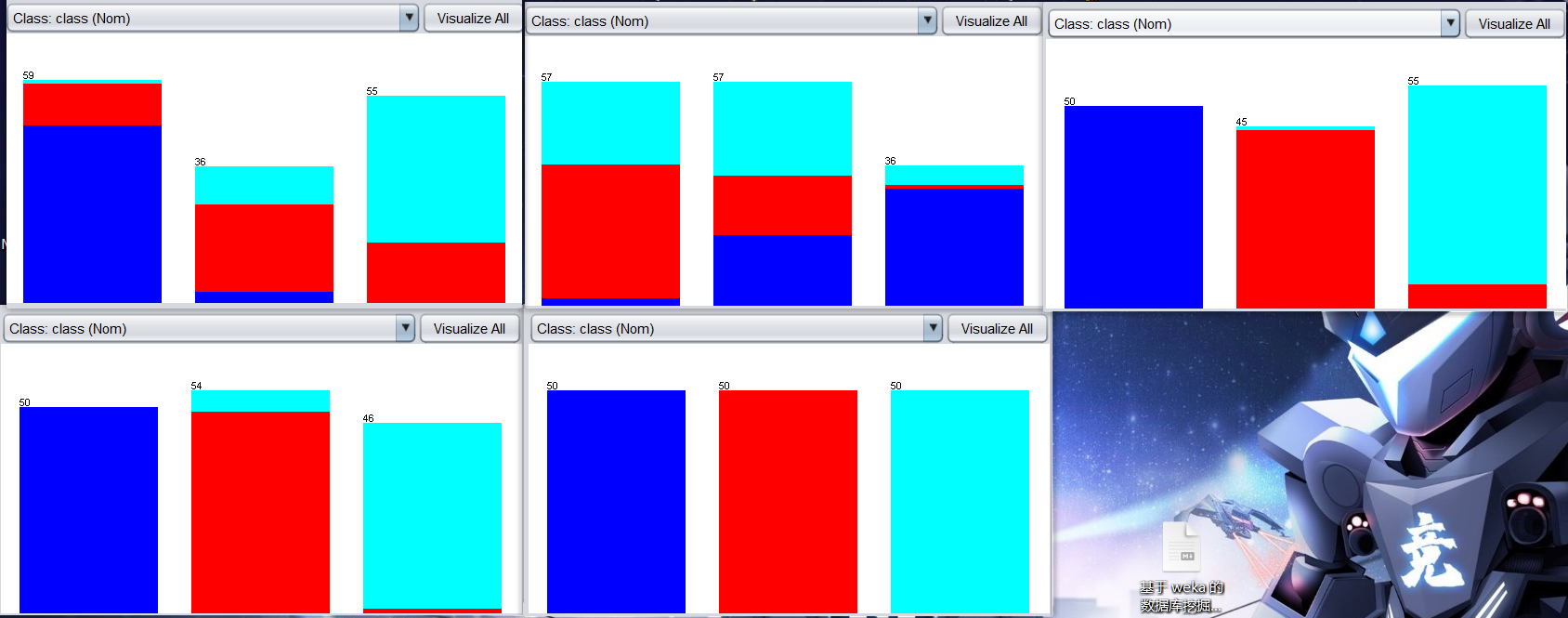
下面以实例说明这两种方法的差异,首先,在 data 目录中找到玻璃数据集glass.arff 文件,如下图是玻璃数据集中各属性的含义。

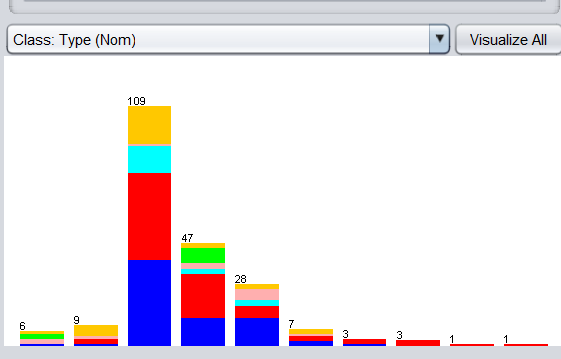
将其加载至探索者界面,在 Preprocess标签页中查看 RI 属性直方图如下:

思考:RI 属性的直方图中各种颜色和各种数值代表什么?
等宽离散化
依次打开choose―>weka―>filters―>unsupervised―>attribute―>Discretize过滤器。保持默认参数不变,点击 Apply,出现如下图:
等频离散化
设置 Discretize 中的 值为 true。得到等频离散化后的 RI 属性,如下图:
值为 true。得到等频离散化后的 RI 属性,如下图:
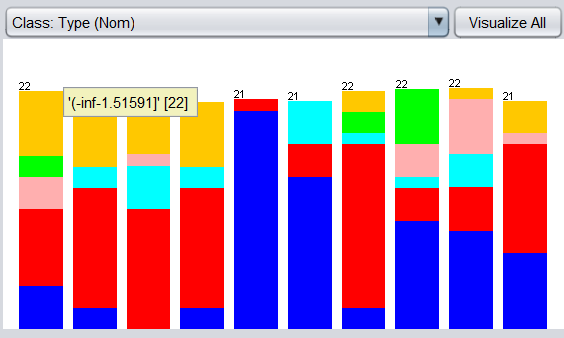
我们可能会产生错觉,等频离散化后形成的直方图似乎会等高,但是有兴趣的可以自行看看 Ba,Fe 属性的等频离散化,是否会等高,思考为什么会这样。

2、有监督离散化
首先打开 data 数据集中的鸢尾花数据集,即 iris.arff 文件,数据集中各属性如下:
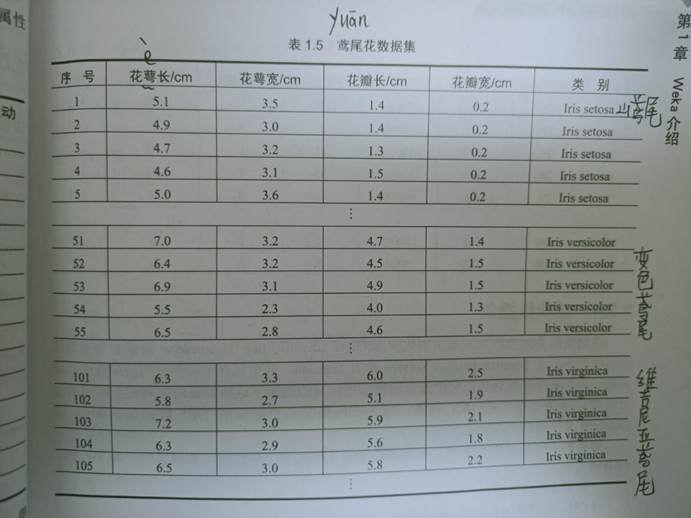
Weka 中打开 iris 数据集,显示如下图
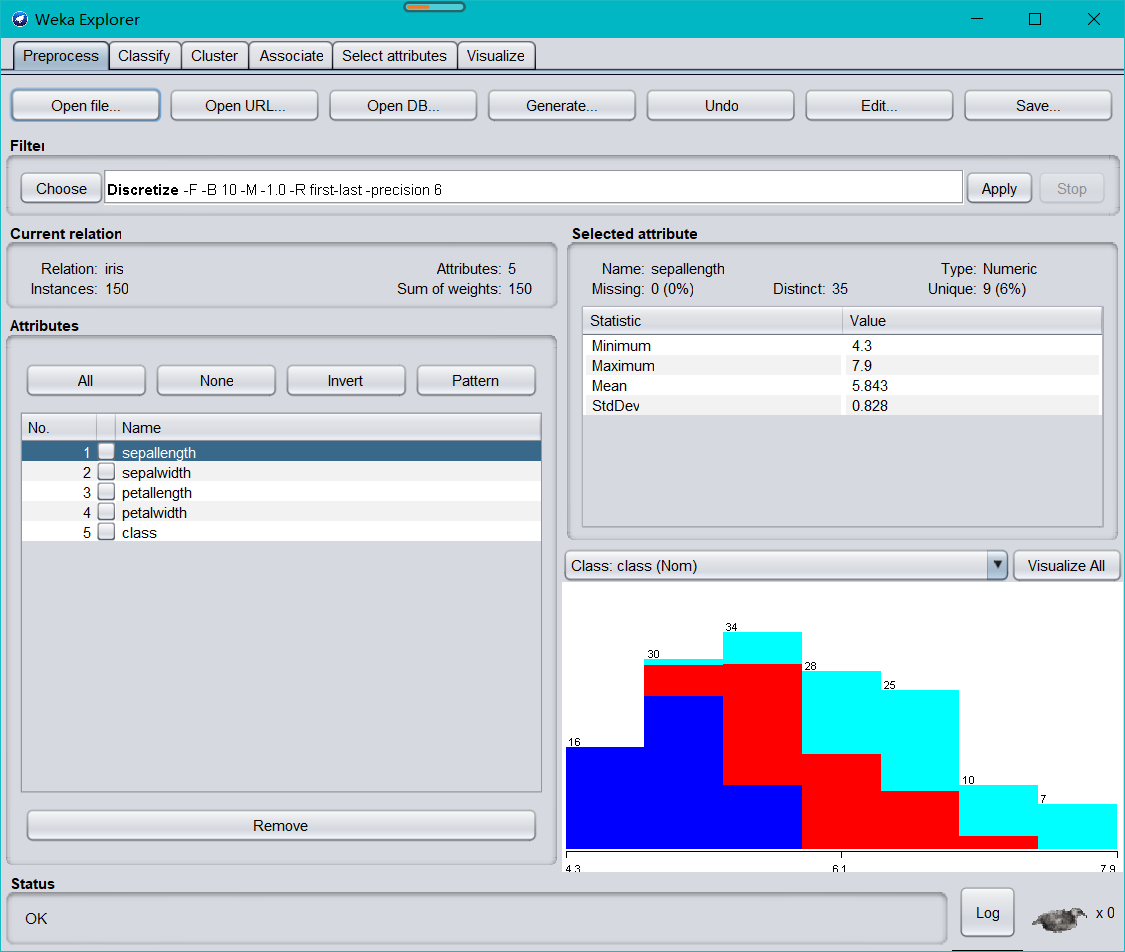
依次点开choose―>weka―>filters―>supervised―>attribute―>Discretize,点击 Apply,,打开可视化窗口,发现各个属性的取值范围如下: