基于卷积神经网络的图像识别技术从入门到深爱(理论与代码实践齐飞!)
零、前言
本文通过手写数字识别作为神经网络理论与代码实践的入门篇,基于入门篇详细讲解各种神经网络的结构及特点并将其应用于遥感图像分类的实践上,所有神经网络代码实现环境为Tensorflow2.0以上。本文总结参考自B站UP主 tm9161,感谢UP主的无私贡献。文章内容表述可能有些不严谨的地方,欢迎评论区留言指正。
如果对机器学习基础感兴趣的,可以移步到我们机器学习专栏,里面机器学习(一)到机器学习(十二)可以作为本篇文章的基础
一、手写数字识别入门神经网络(入门篇)
1. 手写数字数据集及神经网络数据概念介绍
1.1 手写数字数据集
手写数字数据集是由tensorflow官方提供的数据集,可以通过tf.keras.datasets.mnist.load_data()获取训练数据MNIST。MNIST包含70000张手写数字图像:60000张用于训练;10000张用于测试。每张图片是28x28像素的灰度图。

实战代码
# 1. 加载数据(图片数据:尺寸为28*28 像素值为0-255)
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
1.2 神经网络数据集
神经网络数据集又细分为训练集、验证集和测试集。对于这三个概念举个例子就好理解了, 神经网络就好比是一个学生,这个学生要为考试学习知识,那么他就需要先做大量的练习题去学习知识,然后再根据学习的知识去做模拟题验证自己前期通过练习学习的知识掌握的如何,最后真正拿到考试题参考考试。而训练集就可以理解为练习题,验证集就可以理解为模拟题,测试集就可以理解为考试题。

而对于考上来说如果他每次模拟题都做的很好,也可以得出他在考试中会取得好成绩的结论,因此很多神经网络的训练把验证集和测试集归为一类,最后仅剩下训练集和测试集两类。

1.3 基于tensorflow实现神经神经网络常用的包
import tensorflow as tf # 用于实现神经网络
import numpy as np # 用于数据处理
import pandas as pd # 用于读取本地csv或者excel等数据
import matplotlib.pyplot as plt # 用于绘制图形
1.4 one-hot编码
对于分类问题,比如分为三类,我们一般把第一类标识为数字1,第二类标识为数字2,第三类标识为数字3,但其实这样就有可能让机器误以为1,2,3数字之间存在什么关系,比如1和2“距离”近,它们之间是否有什么关系等等,因此我们将1,2,3用类似二进制的形式表达,使得各类别的标识只是有0和1组成。
如分类为三类的问题中,1转为热编码就是100;2转为热编码就是010;3转为热编码就是001;即第几个位置上的数字为1,那么这个位置就是类别标识。、
pandas包封装了将标识(标签)转为one-hot编码的方法,代码实现如下:
# 1. 加载数据(图片数据:尺寸为28*28 像素值为0-255)
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
train_labels = np.array(pd.get_dummies(train_labels)) #将训练集标签转为one-hot编码,然后再转为numpy数据类型
test_labels = np.array(pd.get_dummies(test_labels)) #将测试标签转为one-hot编码,然后再转为numpy数据类型
2. 基于最邻近分类法实现手写数字识别
2.1 最近邻算法原理
对于某个测试样本,我们计算它距离训练样本集中哪个训练样本的距离最近,那么这个测试样本的类别就和哪个训练样本的类别一样。即训练样本集中每张图片的类别是已知的,对于一张不知道类别的测试样本图片,它距离哪个训练样本图片近,它就和哪个训练样本图片的类别一致。
这里面牵涉到一个距离的概念。距离的度量有很多种方式,我们常用的有曼哈顿距离和欧氏距离。曼哈顿距离即两点之间所经实际各个路段之和,这也是我们生活中常用的距离概念;而欧式距离是两点之间直接相连的直线距离。下图中红线代表曼哈顿距离,绿线代表欧式距离。
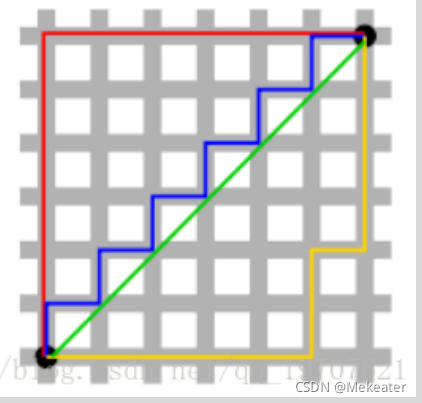
我们采用曼哈顿距离计算两种图片之间的距离,即是两张图片各个对应位置的像素值作差取绝对值,然后再求和。
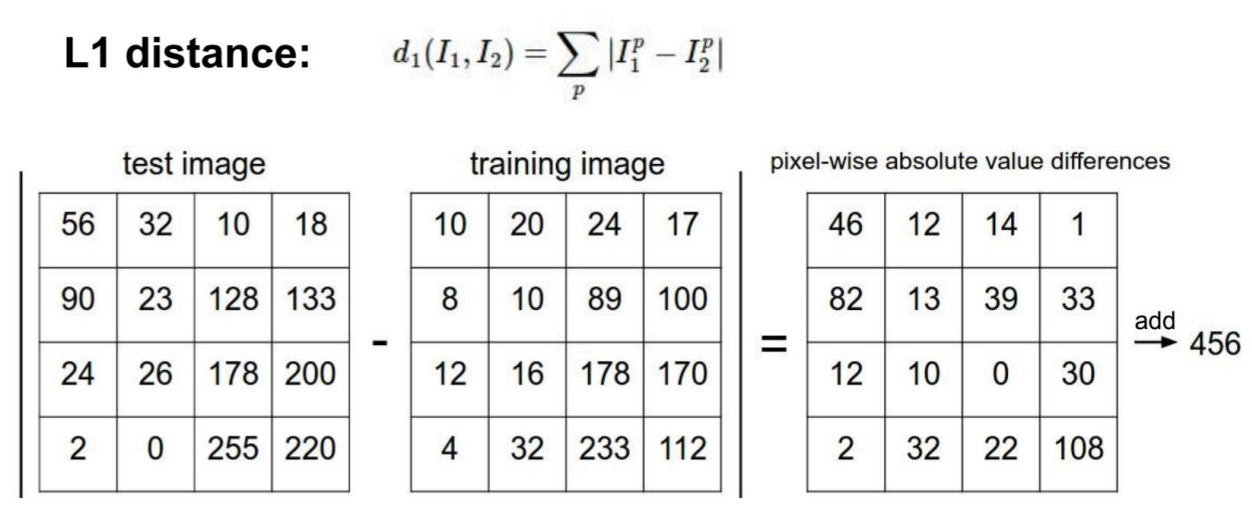
利用numpy包的api实现代码如下:
np.sum(np.abs(test_data-train_data)) # 其中test_data为一张测试图片,而train_data是所有的训练图片,因此,以上计算得到是一个n*1的向量
上面代码得到是一个n*1的向量 ,即测试图片距离每张训练图片的距离大小。我们可以找出其中距离最近的那张训练图片,实现代码如下:
train_index = np.argmin(np.sum(np.abs(test_data-train_data),axis=1)) # 距离该测试图片最近的训练图片是哪张(在train_data中的索引)
可以找出其中距离最近的那张训练图片后,那张训练图片对应的类别(标签)就是测试图片的类别(标签),因为此时图片的标签是one-hot编码,我们需要将其转为真正的类别数字,根据one-hot编码规则,可以通过以下代码获取测试图片的类别:
ont_hotlable = train_labels[train_index] # one-hot类型的标签
predict = np.argmax(ont_hotlable) # 真实的标签
2.2 最近邻手写数字识别代码实现
本算法中,训练集60000张图片,测试集10000张图片。具体每个步骤细节已在2.2讲解,在此不再累赘。
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 加载数据集
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
# 维度变换
train_images = train_images.reshape(60000, 28 * 28)
test_images = test_images.reshape(10000, 28 * 28)
# 归一化
train_images = train_images / 255
test_images = test_images / 255
# 独热编码
train_labels = np.array(pd.get_dummies(train_labels))
test_labels = np.array(pd.get_dummies(test_labels))
# 测试50张测试图片
test = 50
acc = 0
for i in range(test):
test_data = test_images[i] # 当前待预测的图片
train_data = train_images[:20000, :]# 选择使用的训练集数量
# 计算L1距离
distance = np.argmin(np.sum(np.abs(test_data - train_data), axis=1)) # 距离该测试图片最近的训练图片索引
predict = np.argmax(train_labels[distance]) # 获取训练图片标签,即作为该测试图片的标签
real = np.argmax(test_labels[i]) # 获取该测试图片标签
if predict == real: # 比较两个标签是否一致
# 判断真实和预测
acc += 1
# 准确数增加
print("预测:", predict, "真实:", real)
print("准确率:", acc / test)
2.3 算法问题与改进
- 距离不能反应差别
本算很明显的问题是采用简单的曼哈顿距离有时并不能准确的实现图像分类,比如下图本来是同一个人,但因为图片颜色或者少部分的遮盖都会导致像素值的变化,这就会导致距离的计算失去意义,导致不能判定为同一人。

- 算力问题
很明显每张测试图片都要与所有的训练图片进行比较后才能得到结果,时间复杂度为O(n2),这种计算时非常耗时的
因此,我们应该寻找图片中更多不止距离的其它特征,来更加准确的识别图像。这就发展出了神经网络
3. 基于神经网络实现手写数字识别
3.1 神经网络原理
3.1.1 机器学习
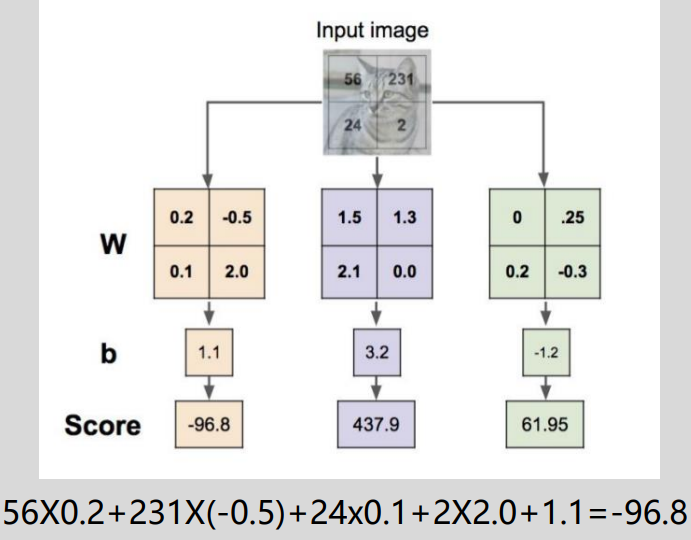
- 对于常规的机器学习,我们可以根据特征变量采用线性分类器实现分类。线性分类器由评分函数(是原始图像数据到类别分值的映射)和损失函数(用来量化预测分类标签的与真实标签的一致性)组成。通过梯度下降思想不断更新评分函数的参数使得损失函数的值达到最小。如对于一张2*2的图片,我们初始化了权重W及偏置b,通过线性分类器即可计算出该张图片属于每个类别对应的得分。如下图,对于第一类别的得分为-96.8
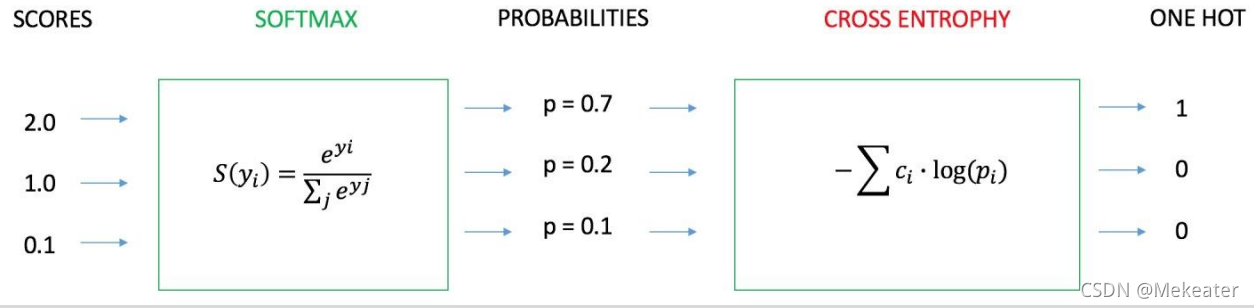
- 但是计算的分数不能更形象的判别图片的类别,线性分类器通常会将这个分数转为属于各个类别的概率值。如SoftMax线性分类器会将计算的分数首先计算为e^score,然后再归一化得到概率值。

- 与softmax分类器对应常用的损失函数是交叉熵损失cross-entropy loss, 它将softmax分类器计算的各个类别的概率值取log,然后分别与one-hot编码值相乘求和再取反。它反映了计算类别与真实类别的误差大小。如下图,softmax计算出的该图片更大概率属于类别3,但实际是类别1,我们利用交叉熵损失公式计算出损失值为
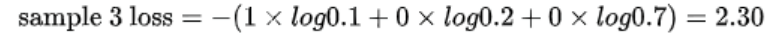
远大于0,因此能反应出计算的分类结果误差较大。
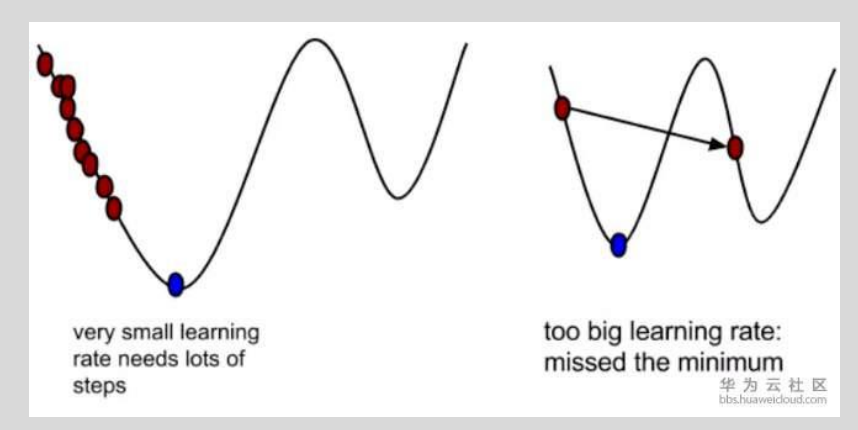
- 梯度下降 Gradient descent就是找到一个方向能降低损失函数的损失值。计算出最陡峭的方向,
就是损失函数的梯度,向着梯度的负方向去更新,降低损失值。 - 学习率是梯度确定损失函数下降的方向。小步长下降稳定但进度慢,大步长进展快但是可能导致错过最优点,让损失值上升。
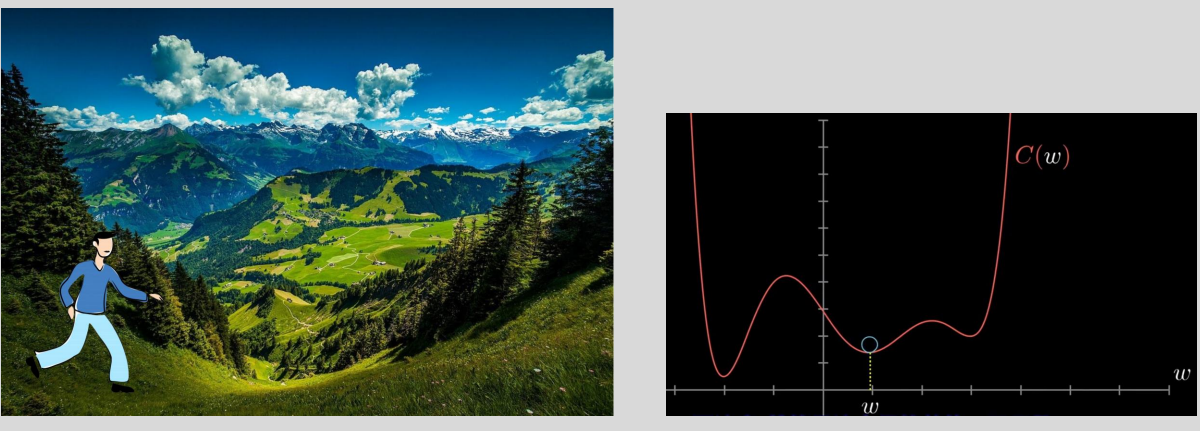
- 对于以上概念,我们用一个故事来解释:从前有一个叫做【评价函数】的人,他每步能走【学习率】的长度,他在群山中不止的探索,他探索的目的是在群山中找到地势最低的那个位置,这个位置名叫【损失函数最低值】。但是群山地势高低起伏,想要找到最低的那个位置并不容易,很容易迷路,为了在群山中不迷路,始终能够朝着最低地势靠近,他就需要一个类似指南针的东西,而【梯度下降】就是这个“指南针”,它能够在很大程度上保证他不断的向地势最低的位置靠近,防止走错方向,在这样的思想下,他终有一天会走到那个最低位置的。以上故事的主人公也就是机器学习,神经网络。
3.1.2 神经网络
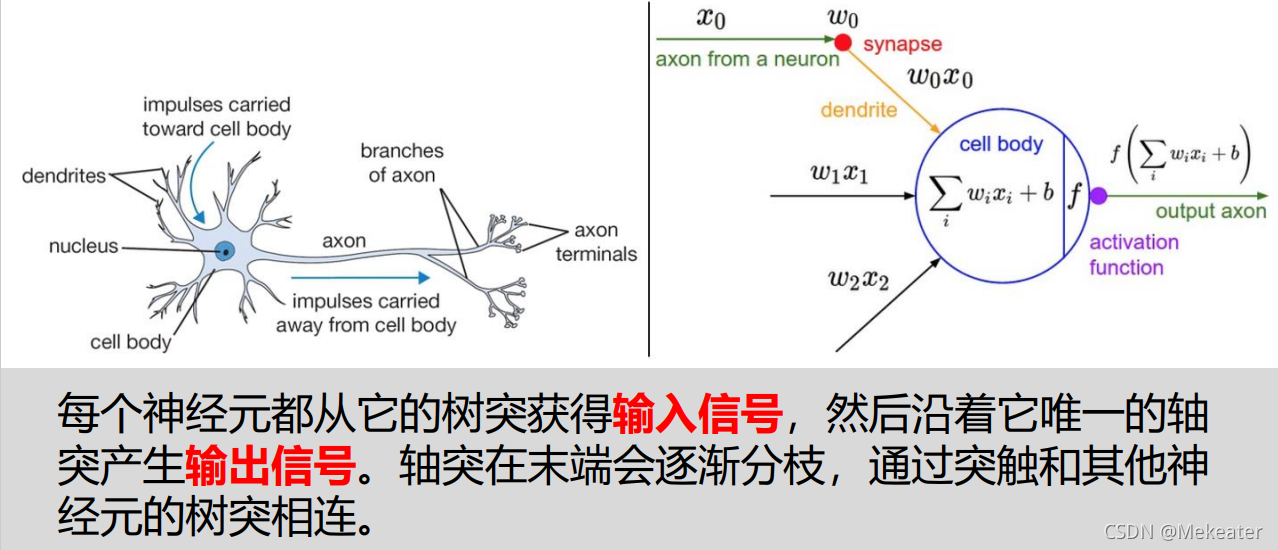
相比机器学习,神经网络的模型更加复杂,且能够更好的处理非线性问题。神经网络结构如下,包括一层输入层,多层隐藏层和一层输出层。以往的机器学习就好比仅仅是神经网络中的输出层,并不包括输入层和隐藏层。隐藏层采用非线性激活函数(常用的有sigmoid,tanh,ReLu等),其作用是上一层的数据通过激活函数(本质是对原数据进行映射,得到合理的更适用于处理的数据,以达到提高运算效率并且实现非线性特征的处理)计算后得到得值如果如高于某个阈值,那么下一层的神经元将被激活。
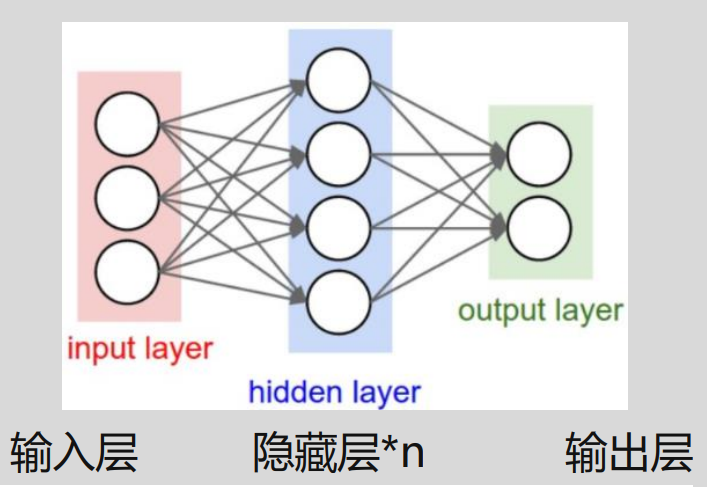
同样,神经网络也需要计算属于每个类别的概率值,以及损失函数值,在神经网络中对应的前向传播就是用来计算概率值的,而反向传播就是用来计算损失函数值的,为了使得损失函数值最小,仍然通过梯度下降思路,不断的调整参数,最终获得最小的损失函数值。
上图三层结构的神经网络,用tensorflow的搭积木方式实现的代码如下:
import tensorflow as tf
model = tf.keras.Sequential()
# 3.1 一层输入层 【将数据展平为一维】
model.add(tf.keras.layers.Flatten(input_shape=(3, 1)))
# 3.2 一层隐藏层 60个神经元 【采用非线性分类器】
model.add(tf.keras.layers.Dense(4, activation='sigmoid'))
# 3.3 一层输出层 10个神经元 【采用线性分类器】
model.add(tf.keras.layers.Dense(2, activation='softmax'))
3.2 基于神经网络的手写数字识别代码实现
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 1. 加载数据(图片数据:尺寸为28*28 像素值为0-255)
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
# 2. 处理数据(归一化--》标签进行one-hot编码(用类似二进制的形式表示类别/标签))
train_images = train_images / 255
test_images = test_images / 255
train_labels = np.array(pd.get_dummies(train_labels))
test_labels = np.array(pd.get_dummies(test_labels))
# 3. 搭建神经网络模型(采用顺序方式,即一块块搭积木);在卷积神经网络中,全连接层就是整个神经网络结构(因为各层神经元全部连接,所以称为全连接层),卷积神经网络是在神经网络之前做了一些处理
model = tf.keras.Sequential()
# 3.1 一层输入层
model.add(tf.keras.layers.Flatten(input_shape=(28, 28)))
# 3.2 一层隐藏层 64个神经元
model.add(tf.keras.layers.Dense(64, activation='sigmoid'))
# 3.3 一层输出层 10个神经元
model.add(tf.keras.layers.Dense(10, activation='softmax'))
# 3.4 模型预览
print(model.summary())
# 4. 设置优化器(自动调节 学习率,定义损失函数,记录正确率等)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['acc'])
# 5. 训练模型
history = model.fit(train_images, train_labels, epochs=5, validation_data=(test_images, test_labels))
# 6. 评估模型
print('模型评估')
print(model.evaluate(test_images, test_labels))
# 绘图
plt.plot(history.epoch, history.history.get('acc'))
plt.plot(history.epoch, history.history.get('val_acc'))
plt.show()
print('模型预测')
print(train_images.shape)
print(model.predict(np.reshape(train_images[0], (1, 28, 28))))
3.3 算法问题与改进
- 像素不能完全反映实际图像内容。
- 图片尺寸的增大、神经元的增加带来的训练参数的增多,训练时间的增加。
因此,基于以上问题,我们应该找到除了像素值之外的其它更多特征,及尽量想办法减少神经元的个数,而卷积神经网络就能解决这个问题。
4. 基于卷积神经网络实现手写数字识别
4.1 卷积神经网络原理
简单理解卷积神经网络就是在神经网络之前加了几层卷积层和下采样层(池化层)而已,在卷积神经网络中,前面讲到的神经网络又称为全连接层。
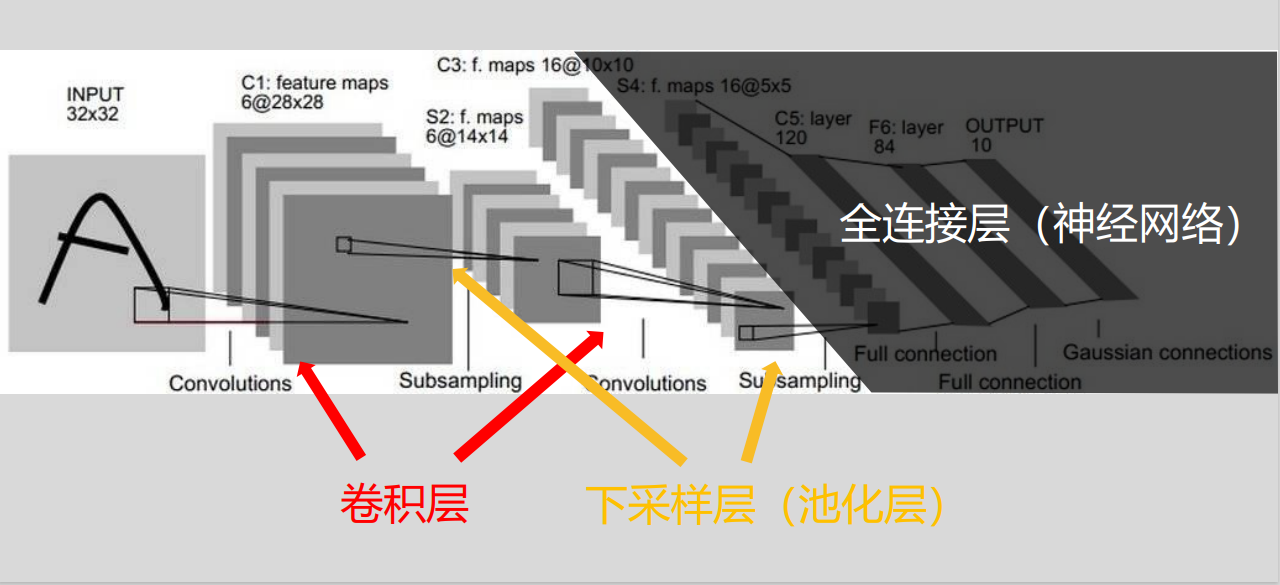
卷积层的意义:通过机器训练卷积层的参数,自动找到图片的主要特征。相比神经网络关注到了像素区域之间的关系(特征)而不仅仅是像素的值。
池化层的意义:在保存图像特征的前提下,降低数据的空间尺寸,减少网络中的参数,以达到节省计算资源的效果。
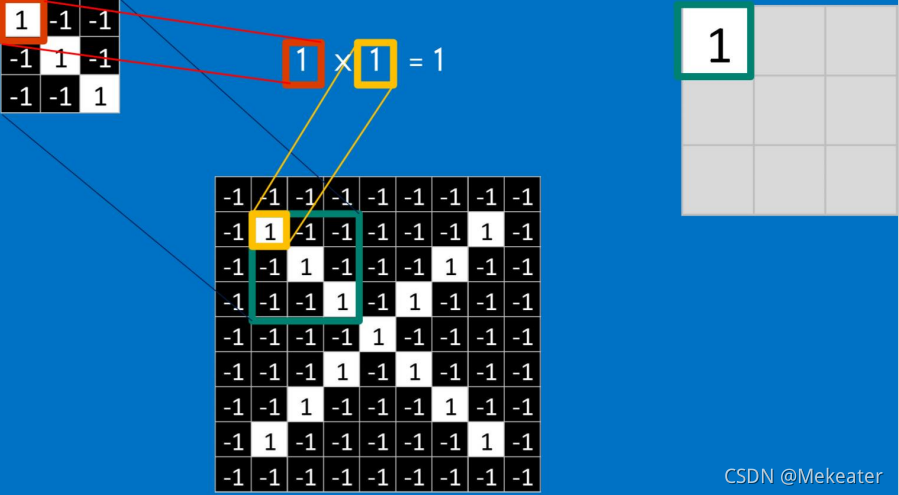
卷积核:一定长宽的矩阵。矩阵中每个元素的值(权重)是由计算机通过不断的训练所得。如下图是3个3*3的卷积核

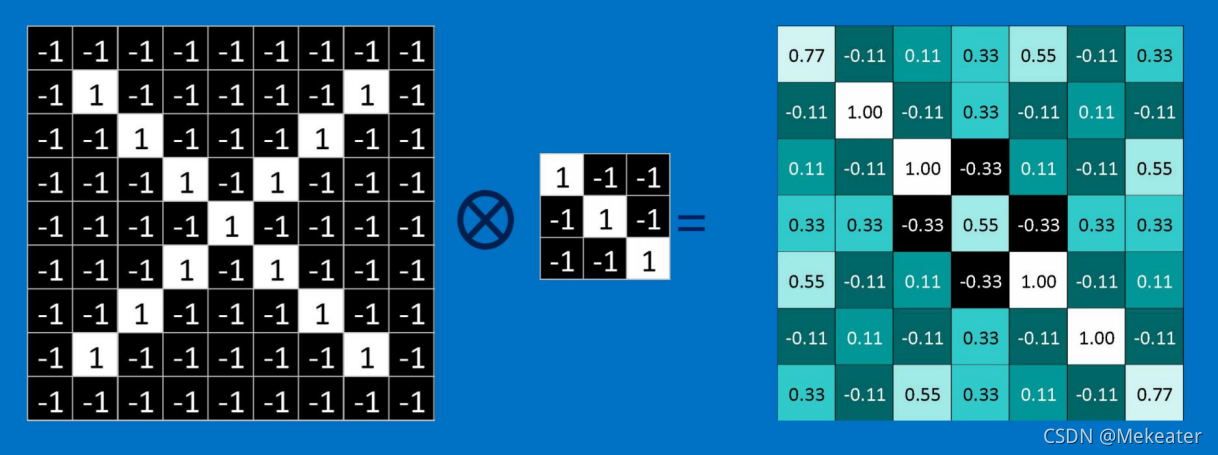
卷积:卷积核上所有作用点依次作用于原始像素点后,相乘再相加,输出结果。通过卷积核对图像的不断卷积会得到更加突出图像特征的数据。
图像(一般宽高一样)经过卷积核卷积后尺寸的变化公式:新的尺寸长为=(原始图像长-卷积核长+加边像素数)/ 步长 + 1。如用3 * 3的卷积核以步长为1进行滑动,对28 * 28的图像进行卷积,卷积后的图像大小为 (28-3+0)/ 1 +1=26,即卷积后图像大小为26 * 26
卷积层训练参数个数计算:多于多通道的图片对应每个通道包含一个相同大小的卷积核,如3通道的3 * 3的卷积核就有三个,每个有9个参数,则3个就有27个参数,再加上一个偏置项,就有28个参数。同时,卷积可以改变图片大小,如下图
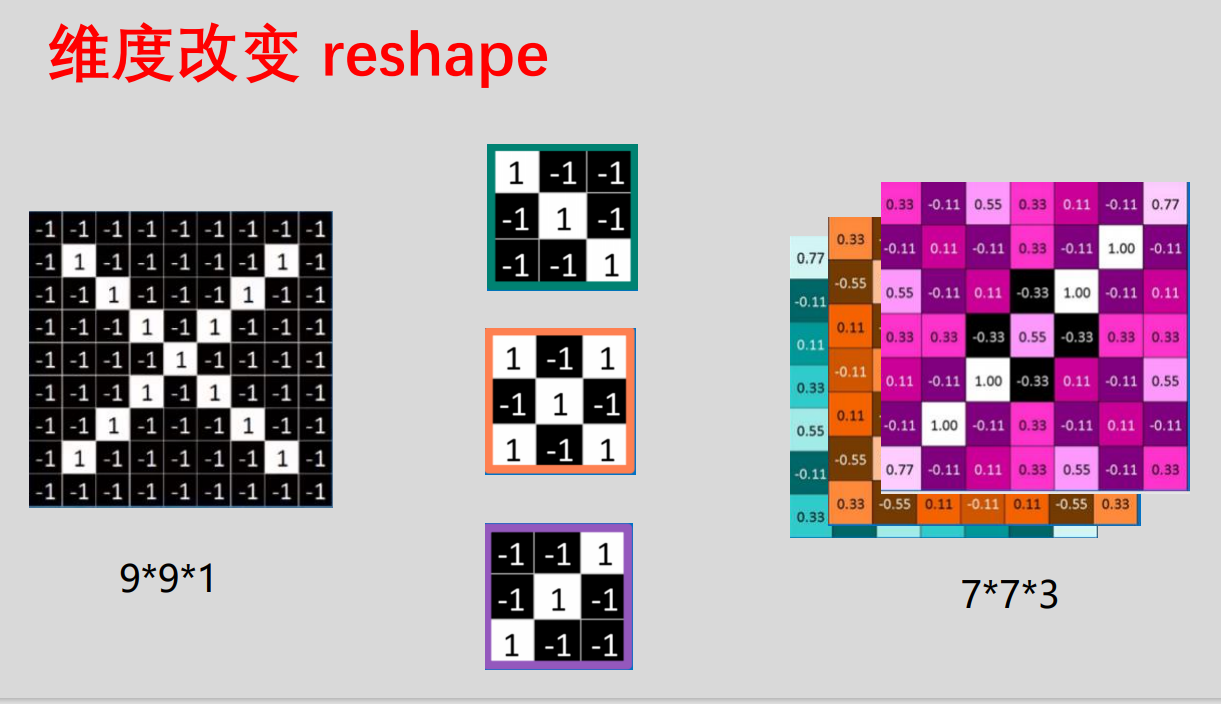
池化层:将输入每一个位置的矩形邻域内的最大值或者平均值作为该位置的输出,降低数据体的空间尺寸,减少网络中的参数,减少计算资源消耗。它不需要训练参数。
总结:
卷积神经网络就是通过卷积层寻找特征,通过池化层降低空间尺寸,最后通过全连接层(神经网络层)根据前面卷积和池化计算的特征(不仅仅是像素值,包括像素之间的关系等特征)进行分类。
4.2 基于自定义的简单卷积神经网络实现手写数字识别的代码
卷积神经网络架构:
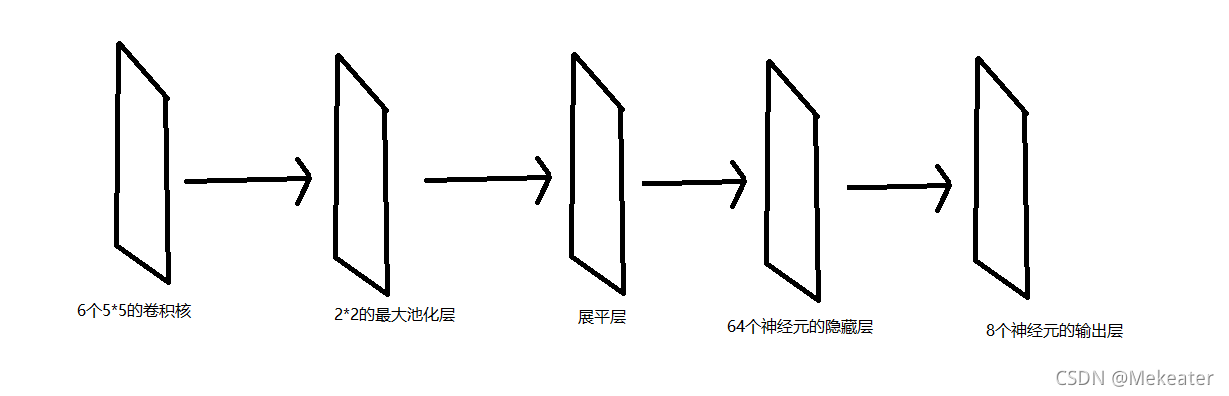
采用tensorflow顺序搭建方式的代码实现
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 1. 加载数据
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
# 2. 数据处理
# 2.1 维度变换:为图片添加厚度维度,因为经过卷积层可能会增加图片的厚度(n个卷积核会得到厚度为n的图片)
train_images = np.reshape(train_images, (60000, 28, 28, 1))
test_images = np.reshape(test_images, (10000, 28, 28, 1))
# 2.2 像素值归一化
train_images = train_images/256
test_images = test_images/256
# 2.3 one-hot编码
train_labels = np.array(pd.get_dummies(train_labels))
test_labels = np.array(pd.get_dummies(test_labels))
# 3. 搭建卷积神经网络(相比神经网络就是在神经网络之前添加卷积层和池化层,
# 卷积层使得图片的局部特征(或者像素之间的位置关系等)被提取,池化层在保证图片特征的情况下减少训练的参数(即使得输出数据长宽变小))
model = tf.keras.Sequential()
# 3.1 添加卷积层(卷积核个数为6, 卷积核大小为5*5,输入图片形状为28*28*1,激活函数为relu, 填充边采用默认, 步长采用默认1)
model.add(tf.keras.layers.Conv2D(filters=6, kernel_size=(5, 5), input_shape=(28, 28, 1), activation=tf.keras.activations.relu))
# 3.2 添加池化层(选择最大池化层,大小为2*2,这会使得输出图形长宽变为一半,减少了参数,但是仍然保存了图片特征,步长采用默认)
model.add(tf.keras.layers.MaxPool2D(pool_size=(2, 2)))
# 3.3 添加全连接层(即神经网络层)
# 3.3.1 添加展平层,即将多维数据展平为一维数据
model.add(tf.keras.layers.Flatten())
# 3.3.2 添加隐藏层(神经元个数为64,激活函数选择sigmod,即通过sigmod函数对原数据进行计算映射,映射值能够反应特征,并且通过sigmod可以实现非线性训练)
model.add(tf.keras.layers.Dense(units=64, activation=tf.keras.activations.sigmoid))
# 3.3.3 添加输出层(神经元个数为10,激活函数为softmax)
model.add(tf.keras.layers.Dense(units=10, activation=tf.keras.activations.softmax))
# 4. 预览卷积神经网络结构(查看经过每层后输出的数据形状,训练的参数个数等)
model.summary()
# 5. 设置优化器(学习率自动调整)、损失函数、记录正确率等
model.compile(optimizer='adam', loss=tf.keras.losses.categorical_crossentropy, metrics=['acc'])
# 6. 拟合训练模型(用训练样本和标签以及验证样本和标签,训练10轮)
model.fit(train_images, train_labels, epochs=10, validation_data=(test_images, test_labels))
# 7. 评估模型(用测试样本) 训练样本就像你平时作业的课后习题,验证样本就像你考试的模拟题,测试样本就像你正式考试的试卷题
model.evaluate(test_images, test_labels)
# 8. 比如预测某张图片类型
probability = model.predict(test_images[0].reshape(1, 28, 28, 1))
print('预测结果:', np.argmax(probability))
# 9. 显示上面预测的测试图片进行对比
plt.imshow(test_images[0].reshape(28, 28))
plt.show()
4.3 基于LeNet-5卷积神经网络的手写数字识别代码实现
- LeNet-5网络结构图
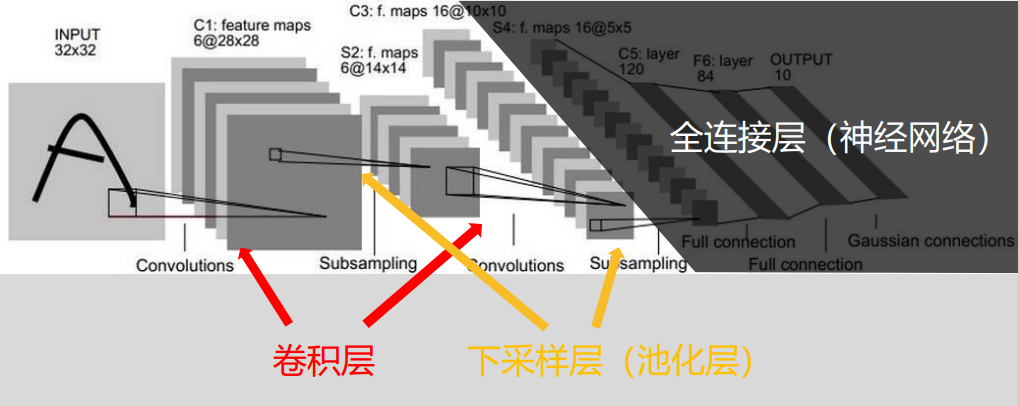
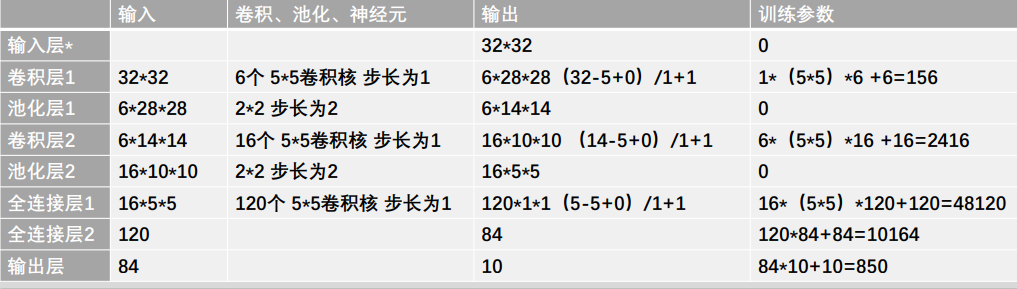
- LeNet-5网络结构每层详解
- LeNet-5网络中图片维度变化:
32 * 32 ==》6 * 28 * 28 ==》6 * 14 * 14 ==》 16 * 10 * 10 ==》 16 * 5 * 5 ==》 120 ==》 84 ==》 10 - 以卷积层1解释维度变化计算:原始图片是1个通道32 * 32像素大小,卷积层1 有6个大小为5 * 5的卷积核以步长为1进行滑动,那么卷积后可以理解为变成6个通道(特征),再根据计算公式:卷积后尺寸 =(输入-卷积核+加边像素数)/步长 +1 ,可得卷积后尺寸为(32 - 5 + 0)/ 1 + 1 = 28,则卷积层1卷积后输出的数据维度为 6 * 28 * 28 【第一个数字代表通道数,第二个数字代表宽度,第三个数字代表高度】
- 以卷积层1解释参数个数的计算:卷积层参数个数=卷积核中的参数+偏置项(每个卷积核带一个偏置项)。对于卷积层1有6个5 * 5大小的卷积核,那么每个卷积核有25个参数和一个偏置项,6个卷积核就有 25 * 6 + 6=156个参数。
- 由于LetNet-5网络的输入图片数据大小是32 * 32 经过一层卷积后变成 6 * 28 * 28,而我们的手写图片数据大小是28 *28,为了和网络架构维度一致,我们在第一次卷积的时候设置padding为same,这样能够保证卷积后输出的图片维度大小不变,就能间接实现经过28 * 28大小的图片经过第一层卷积后输出大小为6 * 28 * 28,这样就与LeNet-5网络架构一样了。
- 基于tensorflow顺序搭建方式的LeNet-5网络代码实现
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 1. 读取数据
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
# 2. 数据预处理
# 2.1 维度变换:为图片添加厚度维度,因为经过卷积层可能会增加图片的厚度(n个卷积核会得到厚度为n的图片)
train_images = np.reshape(train_images, (60000, 28, 28, 1))
test_images = np.reshape(test_images, (10000, 28, 28, 1))
# 2.2 像素值归一化
train_images = train_images/256
test_images = test_images/256
# 2.3 one-hot编码
train_labels = np.array(pd.get_dummies(train_labels))
test_labels = np.array(pd.get_dummies(test_labels))
# 3. 搭建LeNet5网络(输入图片大小是32*32,经过第一层卷积层输出大小为28*28)
model = tf.keras.Sequential()
# 3.1 卷积层(输入层)
model.add(tf.keras.layers.Conv2D(filters=6, kernel_size=(5, 5), input_shape=(28, 28, 1), padding='same', activation='sigmoid'))
# 3.2 平均池化层
model.add(tf.keras.layers.AveragePooling2D(pool_size=(2, 2)))
# 3.3 卷积层
model.add(tf.keras.layers.Conv2D(filters=16, kernel_size=(5, 5), activation='sigmoid'))
# 3.4 平均池化层
model.add(tf.keras.layers.AveragePooling2D(pool_size=(2, 2)))
# 3.5 卷积层
model.add(tf.keras.layers.Conv2D(filters=120, kernel_size=(5, 5), activation='sigmoid'))
# 3.6 全连接层
# 3.6.1 展平层(输入层)
model.add(tf.keras.layers.Flatten())
# 3.6.2 隐藏层
model.add(tf.keras.layers.Dense(84, activation='sigmoid'))
# 3.6.3 输出层
model.add(tf.keras.layers.Dense(10, activation='softmax'))
model.summary()
# 4. 选择优化器、损失函数、记录准确率等设置
model.compile(optimizer='adam', loss=tf.keras.losses.categorical_crossentropy, metrics=['acc'])
# 5. 采用训练样本和标签及验证样本与标签,拟合训练LeNet网络
model.fit(train_images, train_labels, epochs=10, validation_data=(test_images, test_labels))
# 6. 采用测试样本和标签,评估训练的模型
model.evaluate(test_images, test_labels)
# 7. 保存模型,供后续预测使用
model.save('mnist.h5')
二、遥感图像分类吃透各种卷积神经网络模型(提升篇)
1. LeNet-5实现遥感图像分类
1.1 遥感图像数据集介绍
遥感图像为单通道的大小为28 * 28的汽车,飞机等相关图像,采用csv进行存储,一行记录中第一列为该图像的标签,其余列为图像的像素值。训练集有68161行记录即68161张训练图片;测试集有8529行记录即8529张测试图片。
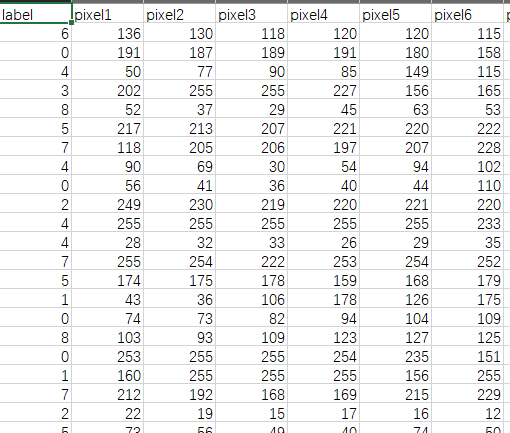
数据下载通道
提取码:esif
1.2 LeNet-5卷积神经网络代码实现
LeNet-5的网络结构上面已经介绍,在此不在赘述。
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 1. 读取csv格式的图片数据(本质就是将图片的像素值展平放到csv中的一行)
train = pd.read_csv('sat/train.csv')
test = pd.read_csv('sat/test.csv')
# 2. 读取的数据格式转为np数组
train = np.array(train)
test = np.array(test)
# 3. 提取图片信息(将展平的图片像素值还原)
train_images = train[:, 1:] # 获取所有行从第1列开始的数据
test_images = test[:, 1:]
# 4. 提取标签信息
train_labels = train[:, :1]
test_labels = test[:, :1]
# 5. 将图片数据和标签数据的维度修改为卷积神经网络需要的数据格式
train_images = train_images.reshape(68161, 28, 28, 1)
test_images = test_images.reshape(8529, 28, 28, 1)
train_labels = train_labels.reshape(68161)
test_labels = test_labels.reshape(8529)
# 6. 图片数据归一化
train_images = train_images/255
test_images = test_images/255
# 7. 标签数据 one-hot编码(独热编码)
train_labels = np.array(pd.get_dummies(train_labels))
test_labels = np.array(pd.get_dummies(test_labels))
# 8. 搭建LeNet-5网络 控制输入输出方法)
# 8.1 输入层
input_image = tf.keras.layers.Input(shape=(28, 28, 1))
# 8.2 对上一步的input_image进行卷积,输出为x
x = tf.keras.layers.Conv2D(filters=6, kernel_size=(5, 5), padding='same', activation='sigmoid')(input_image)
# 8.3 对上一步的x进行平均池化,输出为x
x = tf.keras.layers.AveragePooling2D(pool_size=(2, 2))(x)
# 8.4 对上一步的x进行据卷积,输出为x
x = tf.keras.layers.Conv2D(filters=16, kernel_size=(5, 5), activation='sigmoid')(x)
# 8.5 对上一步的x进行平均池化,输出为x
x = tf.keras.layers.AveragePooling2D(pool_size=(2, 2))(x)
# 8.6 对上一步的x进行据卷积,输出为x
x = tf.keras.layers.Conv2D(filters=120, kernel_size=(5, 5), activation='sigmoid')(x)
# 8.7 对上一步的x进行据展平,输出为x
x = tf.keras.layers.Flatten()(x)
# 8.8 同理进行全连接层
x = tf.keras.layers.Dense(84, activation='sigmoid')(x)
x = tf.keras.layers.Dense(10, activation='sigmoid')(x)
# 8.9 根据以上组织的起始输入和最终输出,定义最终模型
model = tf.keras.models.Model(inputs=input_image, outputs=x)
#9. 预览搭建的网络
model.summary()
# 10. 设置优化器,损失函数,记录准确率
model.compile(optimizer='adam', loss=tf.keras.losses.categorical_crossentropy, metrics=['acc'])
# 11. 拟合训练
history = model.fit(train_images, train_labels, validation_data=(test_images, test_labels), epochs=10)
# 12. 绘制训练准确率和验证准确率图
plt.plot(history.epoch, history.history.get('acc'))
plt.plot(history.epoch, history.history.get('val_acc'))
plt.show()
# 13. 评估模型
model.evaluate(test_images, test_labels)
# 14. 保存模型
model.save('test.h5')
下面是训练10次的一个结果图
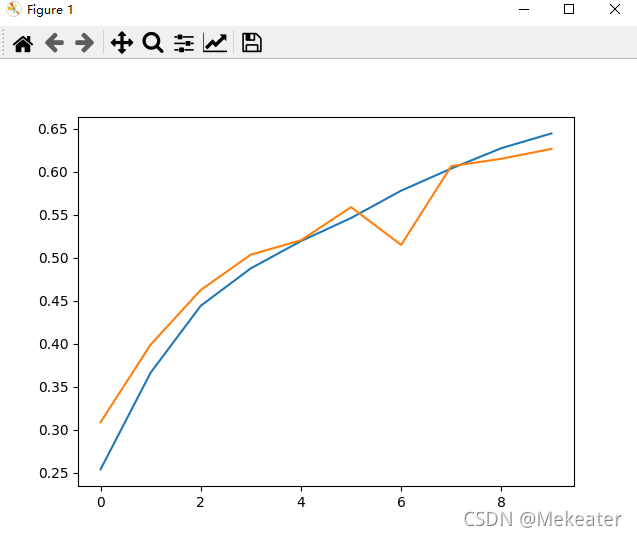
2. AlexNet实现遥感图像分类
2.1 数据集介绍
NWPU-RESISC45数据集
包含45类,每类700张,共31500张土地利用类型的遥感影像,影像图片为256 * 256像素的彩色图。
提取自Google Earth
由西北工业大学于2016年发布。

本文训练采用其中的5类,划分每类630张为训练集,70张为测试集。本文训练数据下载链接
提取码:jk8y
2.2 AlexNet网络创新
- 之前我们讲到神经网络(把它看做一个人)在高低起伏的山中通过梯度下降思想不断向地势最低的位置靠近,而梯度下降思想受到激活函数的影响,随着神经网络走的越来越深,我们上面用到的Sigmoid激活函数不能避免梯度消失的现象,即神经网络只能走到局部地势最低的位置,而达不到真正的全局地势最低的位置。而AlexNet网络解决了这个问题,它提出了ReLu这个新的激活函数,这个激活函数使模型收敛速度快,避免梯度消失;计算简单,运算速度快
- 由于全连接层每层神经元数量很多,即模型参数过多,这在一定程度程度上会造成过拟合现象的发现,而AlexNet提出每次训练都随机让一定神经元停止参与运算,增加模型的泛化能力、稳定性和鲁棒性,避免过拟合。
- 总之,AlexNet相比LeNet-5网络有两大改进,第一,采用ReLu激活函数避免梯度消失并提升计算速度;第二,每次训练随机让一定数量比例的神经元不参与运算,避免过拟合现象。
2.3 AlexNet网络架构
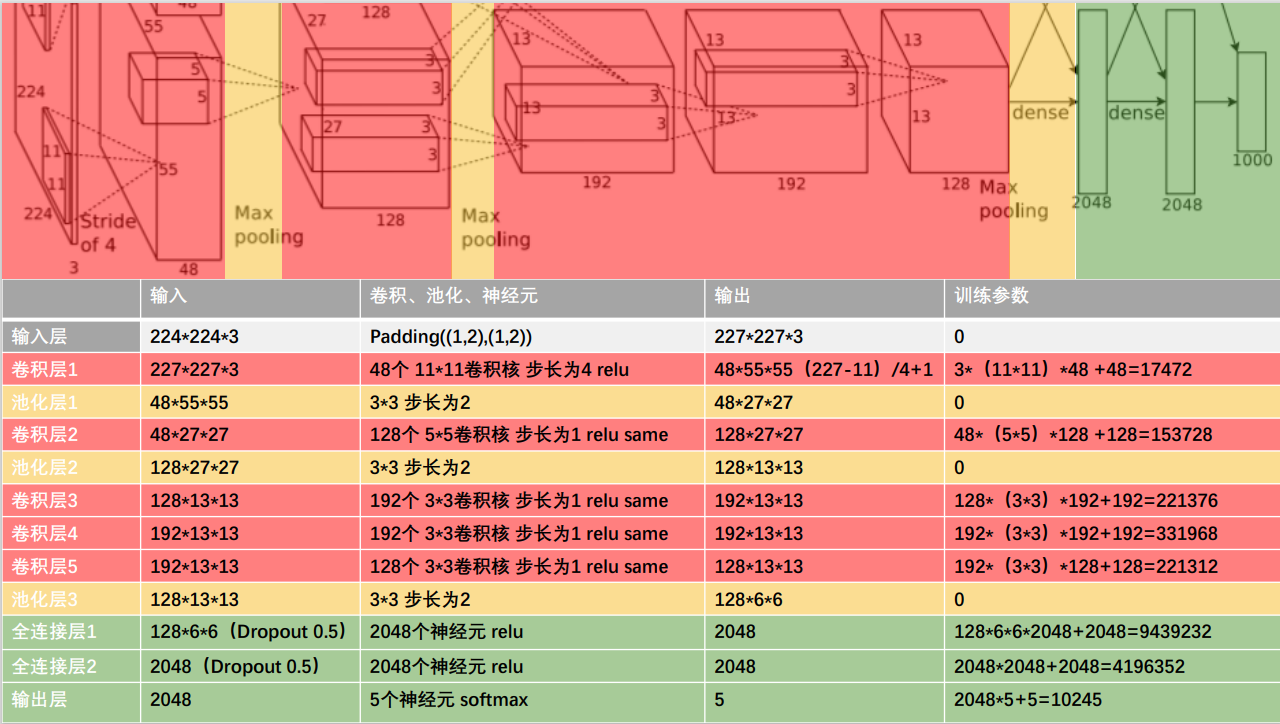
2.4 AlexNet网络训练遥感图像分类的代码实现
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 0. 如果用GPU跑,先配置GPU内存
gpus = tf.config.list_physical_devices(device_type='GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(device=gpu, enable=True)
# 1. 定义后面所需参数的变量
train_dir = 'sat1/train' # 训练集文件夹,该文件夹下包含不同类别的各个子文件夹
val_dir = 'sat1/val' # 验证集文件夹(因为没有测试数据,所以也把验证集当做测试集用了,一般都把测试集和验证集当做一样对待),同样该文件夹下包含不同类别的各个子文件夹
img_size = 224 # AlexNet网络要求的图片大小
batch_size = 32 # 每次处理图片的个数(建议不要低于16,最好是32),这个值越大,梯度下降计算越好,但是占用显存等越大;越小的话,梯度下降最终可能落入局部最小值
# 2. 定义tensorflow的预处理类ImageDataGenerator,设置缩放(归一化)比例和是否翻转图片
train_images = ImageDataGenerator(rescale=1 / 255, horizontal_flip=True)
test_images = ImageDataGenerator(rescale=1 / 255)
# 3. 读取文件夹图片(设置batch数,即每次处理文件夹中图片的个数;是否随机读取图片;读取图片的目标大小,即可以将原始图片修改为目标图片的大小;指定分类问题,),获取样本数据和标签数据
# 总之,flow_from_directory实现批量从文件夹读取数据(同时完成了对样本数据和标签数据的预处理);当然你不用这个函数,一张张的读取图片数据,设置one-hot样本数据也是可以的
train_gen = train_images.flow_from_directory(directory=train_dir, # 读取图片的文件夹路径
batch_size=batch_size, # 每次读取图片的个数
shuffle=True, # 随机读取图片
target_size=(img_size, img_size), # 可以将原始图像缩放到我们需要的尺寸
class_mode='categorical') # 指定我们的分类是多分类问题(会自动把我们的标签转为热编码的形式)
val_gen = train_images.flow_from_directory(directory=val_dir, # 读取图片的文件夹路径
batch_size=batch_size, # 每次读取图片的个数
shuffle=False, # 随机读取图片
target_size=(img_size, img_size), # 可以将原始图像缩放到我们需要的尺寸
class_mode='categorical') # 指定我们的分类是多分类问题(会自动把我们的标签转为热编码的形式)
# 4. 查看自动定义的类别索引
classIndex = train_gen.class_indices
print(classIndex)
# 5. 搭建AlexNet网络
model = tf.keras.Sequential()
# 5.1 因为AlexNet网络经过第一层卷积后输出形状为 55*55*48,为了达到这个形状,根据维度公式:(原始图片宽度 - 卷积核宽度 - 填边宽度)/ 步长 + 1,首先需要对原始图像进行填充边宽度为3,高度为3
model.add(tf.keras.layers.ZeroPadding2D(((1, 2), (1, 2)), input_shape=(224, 224, 3))) # 采用全部填充0的加边方法
# 5.2 卷积层 (全部采用relu激活函数,可以更好的避免梯度消失问题,这是AlexNet网络的一大创新点)
model.add(tf.keras.layers.Conv2D(filters=48, kernel_size=(11, 11), strides=4, activation='relu'))
# 5.3 最大池化层
model.add(tf.keras.layers.MaxPooling2D(pool_size=(3, 3), strides=2))
# 5.4 卷积层
model.add(tf.keras.layers.Conv2D(filters=128, kernel_size=(5, 5), padding='same', activation='relu')) # padding='same'保证输出后长宽不变
# 5.5 最大池化层
model.add(tf.keras.layers.MaxPooling2D(pool_size=(3, 3), strides=2))
# 5.6 卷积层
model.add(tf.keras.layers.Conv2D(filters=192, kernel_size=(3, 3), padding='same', activation='relu'))
# 5.7 卷积层
model.add(tf.keras.layers.Conv2D(filters=192, kernel_size=(3, 3), padding='same', activation='relu'))
# 5.8 卷积层
model.add(tf.keras.layers.Conv2D(filters=128, kernel_size=(3, 3), padding='same', activation='relu'))
# 5.9 最大池化层
model.add(tf.keras.layers.MaxPooling2D(pool_size=(3, 3), strides=2))
# 5.10 全连接层
# 5.10.1 展平层
model.add(tf.keras.layers.Flatten())
# 5.10.2 神经元随机连接百分比层,减少神经元连接个数,避免过拟合(这也是AlexNet网络的一大创新点)
model.add(tf.keras.layers.Dropout(0.5))
# 5.10.3 隐藏层
model.add(tf.keras.layers.Dense(2048, activation='relu'))
# 5.10.4 神经元随机连接百分比层
model.add(tf.keras.layers.Dropout(0.5))
# 5.10.3 隐藏层
model.add(tf.keras.layers.Dense(2048, activation='relu'))
# 5.10.4 输出层(AlexNet网络输出类别是1000,我们的数据是分为5类,因此输出5个神经元,采用softmax激活函数获取各个类别的概率)
model.add(tf.keras.layers.Dense(5, activation='softmax'))
# 6. AlexNet网络预览(每层是什么层;每层输出数据形状;每层需要训练参数)
model.summary()
# 7. 设置优化器(会自动选择合适的学习率);损失函数;记录准确率
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.0005), loss=tf.keras.losses.categorical_crossentropy, metrics=['acc']) # 发现adam默认的0.001学习率效果不好,手动设置为0.0005相关较好
# 8. 用训练样本和验证样本进行拟合训练
history = model.fit(train_gen, epochs=15, validation_data=val_gen)
# 9. 绘制训练精度与验证精度图
plt.plot(history.epoch, history.history.get('acc'))
plt.plot(history.epoch, history.history.get('val_acc'))
plt.show()
# 10. 用测试样本进行模型评估
model.evaluate(val_gen)
# 11. 保存训练模型的框架及参数
model.save('sat2.h5')
3. VGGNet实现遥感图像分类
3.1 数据集介绍
与AlexNet网络中使用的数据集一样
3.2 VGGNet网络创新
VGGNet是一个简单而优雅的架构,VGGNet提出了用 堆叠两个3 * 3卷积核替代一个5 * 5卷积核;堆叠三个3 * 3卷积核替代一个7 * 7卷积核。这种用多个小的卷积核代替一个大的卷积核可以在保证相同感受视野的情况下,使得训练参数量减少,并增加模型的非线性表达能力。
3.3 VGGNet网络架构
下图是VGG-16的网络架构图
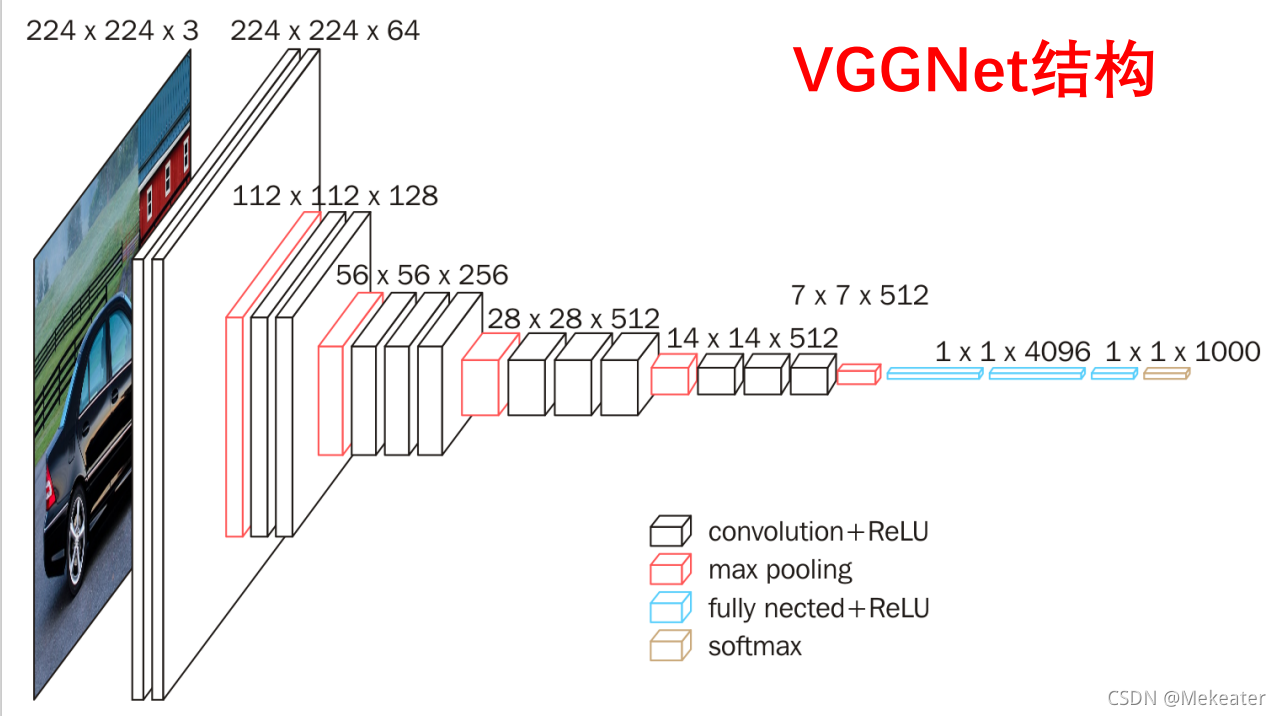
下表每列代表一种VGG网络的结构组成:
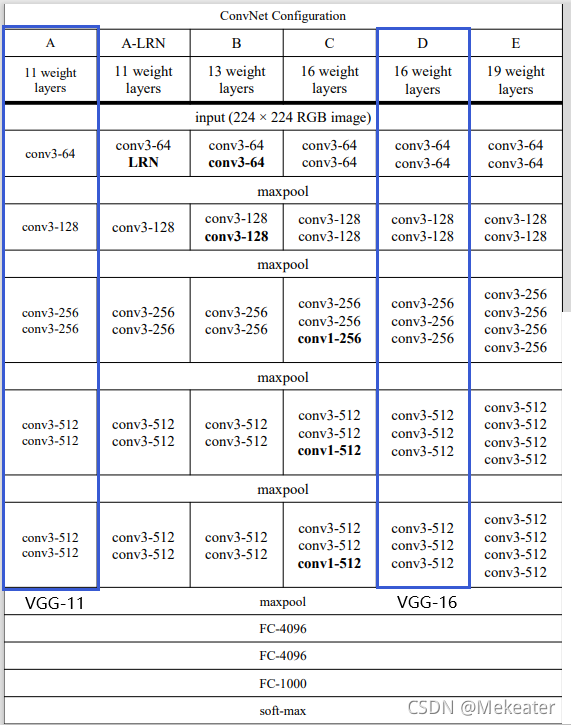
上图中用蓝线框住的两列分别为VGG-11和VGG-16的网络结构组成。我们以VGG-11为例,讲解表格中表示的网络结构。
- cov3-64中第一个数字3代表卷积核的大小即3 * 3,第二个数字64代表卷积核的个数。
- 那么第一列表达的VGG-11的网络结构解释如下:
- 输入图像为244 * 244 * 3的彩色图像==》经过1层卷积(由于padding设置为same,因此卷积完图像大小不变,仍然为224 * 224,其它卷积层同理) ==》经过一层最大池化(图像大小减半,变为112 * 112,其它池化层同理) ==》经过一层卷积 ==》经过一层最大池化 ==》 经过两层卷积 ==》经过一层最大池化 ==》经过两层卷积 ==》经过一层最大池化 ==》经过两层卷积 ==》经过一层最大池化 ==》展平层展平为4096个神经元 ==》隐藏层4096个神经元 ==》输出层1000个神经元 ==》采用softmax进行分类。
3.4 代码实现
由于我们的样本只有3250个,不足以支持VGG-16那样庞大的网络(这也算VGG的一个缺点,虽然减少了参数,但是规模变大了,小的训练集不足以与它匹配 ),我们采用VGG-11,并且对全连接层(神经网络)的神经元个数进行了一定数量的减少,输入层为1024,隐藏层为1024,输出层因为我们是分为5类,因此采用5个神经元。
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 1. 设置下面用的相关参数变量
train_dir = 'sat1/train'
test_dir = 'sat1/val'
batch_size = 32
img_size = 224
# 2. 读取文件夹数据
train_gen = ImageDataGenerator(rescale=1 / 255, horizontal_flip=True)
test_gen = ImageDataGenerator(rescale=1 / 255)
train_images = train_gen.flow_from_directory(directory=train_dir,
target_size=(img_size, img_size),
batch_size=batch_size,
shuffle=True,
class_mode='categorical') # 指定为多分类问题,并自动对类别进行编号和转为热编码
test_images = train_gen.flow_from_directory(directory=test_dir,
target_size=(img_size, img_size),
batch_size=batch_size,
shuffle=False,
class_mode='categorical') # 指定为多分类问题,并自动对类别进行编号和转为热编码
# 3. 查看自动给每个类别(子文件夹)赋予的索引
classes = train_images.class_indices
print("===============================类别索引============================")
print(classes)
# 4. 搭建VGGNet-11/16网络:
# 由于我们的样本只有3250个,不足以支持VGG-16那样庞大的网络(这也算VGG的一个缺点,虽然减少了参数,但是规模变大了,小的训练集不足以与它匹配 ),我们采用VGG-11,并且对全连接层(神经网络)的神经元个数进行了一定数量的减少
# VGG-11 和VGG-16,后面的数字是代表网络的层数
# 下面的搭建如果把注释的层打开就是一个VGG-16的网络
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(input_shape=(224, 224, 3), filters=64, kernel_size=(3, 3), padding='same',
activation='relu'))
# model.add(tf.keras.layers.Conv2D(filters=64, kernel_size=(3, 3), padding='same',
# activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Conv2D(filters=128, kernel_size=(3, 3), padding='same',
activation='relu'))
# model.add(tf.keras.layers.Conv2D(filters=128, kernel_size=(3, 3), padding='same',
# activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Conv2D(filters=256, kernel_size=(3, 3), padding='same',
activation='relu'))
model.add(tf.keras.layers.Conv2D(filters=256, kernel_size=(3, 3), padding='same',
activation='relu'))
# model.add(tf.keras.layers.Conv2D(filters=256, kernel_size=(3, 3), padding='same',
# activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Conv2D(filters=512, kernel_size=(3, 3), padding='same',
activation='relu'))
model.add(tf.keras.layers.Conv2D(filters=512, kernel_size=(3, 3), padding='same',
activation='relu'))
# model.add(tf.keras.layers.Conv2D(filters=512, kernel_size=(3, 3), padding='same',
# activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Conv2D(filters=512, kernel_size=(3, 3), padding='same',
activation='relu'))
model.add(tf.keras.layers.Conv2D(filters=512, kernel_size=(3, 3), padding='same',
activation='relu'))
# model.add(tf.keras.layers.Conv2D(filters=512, kernel_size=(3, 3), padding='same',
# activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(1024, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(1024, activation='relu'))
model.add(tf.keras.layers.Dense(5, activation='softmax'))
# 5. 预览网络
model.summary()
# 6. 训练网络
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.0005), loss=tf.keras.losses.categorical_crossentropy,
metrics=['acc'])
result = model.fit(train_images, epochs=10, validation_data=test_images)
# 7. 绘制精度图
plt.plot(result.epoch, result.history.get('acc'))
plt.plot(result.epoch, result.history.get('val_acc'))
print("===============================模型评估============================")
model.evaluate(test_images)
# 8. 保存模型
model.save('sat3.h')
plt.show()
3.5 迁移学习
因为卷积过程提取的特征,具有一定的通用性,因此我们可以采用别的相关领域通过大量训练集已经训练好的卷积层的参数,然后我们仅仅去训练我们自己的神经网络层即可。迁移学习的优势是速度快,使得小数据集也能使用复杂的模型。
之前我们的学习是载入预训练模型,训练所有参数。而迁移学习是载入预训练模型,固定部分训练参数(这部分参数别人已经训练好了,我们下载下来直接使用),训练部分参数。
VGG-16迁移学习代码实现
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 1. 设置下面用的相关参数变量
train_dir = 'sat1/train'
test_dir = 'sat1/val'
batch_size = 32
img_size = 224
# 2. 读取文件夹数据
train_gen = ImageDataGenerator(rescale=1 / 255, horizontal_flip=True)
test_gen = ImageDataGenerator(rescale=1 / 255)
train_images = train_gen.flow_from_directory(directory=train_dir,
target_size=(img_size, img_size),
batch_size=batch_size,
shuffle=True,
class_mode='categorical') # 指定为多分类问题,并自动对类别进行编号和转为热编码
test_images = train_gen.flow_from_directory(directory=test_dir,
target_size=(img_size, img_size),
batch_size=batch_size,
shuffle=False,
class_mode='categorical') # 指定为多分类问题,并自动对类别进行编号和转为热编码
# 3. 查看自动给每个类别(子文件夹)赋予的索引
classes = train_images.class_indices
print("===============================类别索引============================")
print(classes)
# 4. 迁移学习:获取别人已经训练好的VGG的卷积层框架和参数,我们仅仅训练剩余的神经网络参数
vgg = tf.keras.applications.VGG16(include_top=False, weights='imagenet', input_shape=(224, 224, 3)) # 第一次会从网上下载前人训练好的参数
vgg.trainable = False # 将卷积层冻结,即不再训练卷积层,直接用前人已经训练好的参数
# #迁移学习 去掉全连接层 加载权重 输入尺寸
# #迁移学习也是参考人类可以总结以往经验,然后直接利用以往的经验去解决新的问题
model = tf.keras.Sequential()
model.add(vgg) # 加载去掉全连接层的VGG-16网络
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(1024, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(1024, activation='relu'))
model.add(tf.keras.layers.Dense(5, activation='softmax'))
# 5. 预览网络
model.summary()
# 6. 训练网络
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.0005), loss=tf.keras.losses.categorical_crossentropy,
metrics=['acc'])
result = model.fit(train_images, epochs=10, validation_data=test_images)
# 7. 绘制精度图
plt.plot(result.epoch, result.history.get('acc'))
plt.plot(result.epoch, result.history.get('val_acc'))
print("===============================模型评估============================")
model.evaluate(test_images)
# 8. 保存模型
model.save('sat4.h')
plt.show()
4. GoogleNet实现遥感图像分类
4.1 数据集介绍
与AlexNet网络中使用的数据集一样
4.2 GoogleNet网络创新
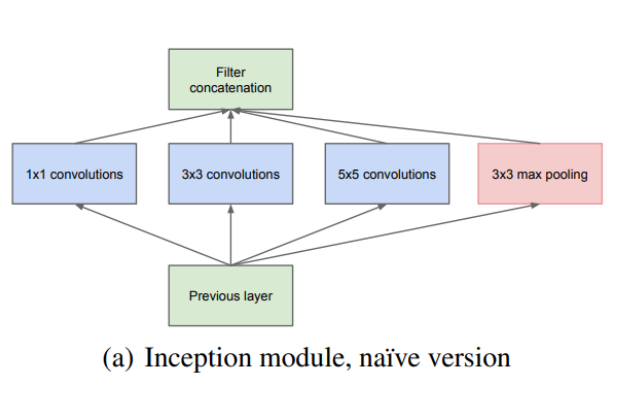
AlexNet、VGG等结构都是通过增大网络的深度来获得更好的训练效果,存在计算资源消耗大和梯度消失等问题,GoogLeNet提出的inception模块,融合不同尺度的特征信息。其次GoogleNet网络不仅仅只有最终一个分类输出,它再中间也有两个辅助分类输出,更进一步提高训练精度。
-
原始inception模块结构
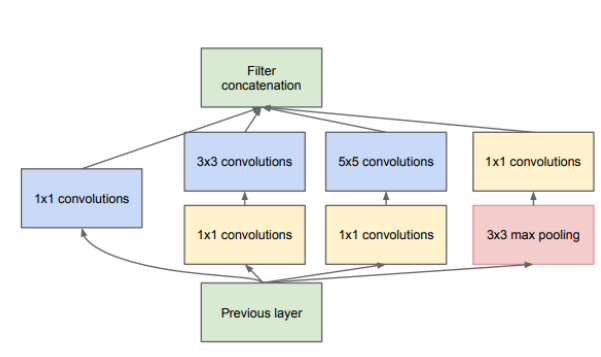
-
改进后的inception模块结构
-
都是在一层用了不同大小的卷积核实现融合不同尺度的特征信息,但是改进后inception模块的参数要比原始的少很多,以5 * 5卷积不考虑偏置项为例计算改进前后的参数个数:
原始输入为28 * 28 * 192,直接32个5 * 5卷积参数:5 * 5 * 192 * 32=105600;
而先使用16个1 * 1卷积降维,再使用32个5 * 5卷积参数:1 * 1 * 192 * 16 + 5 * 5 * 16 * 32=15872
很明显改进后的先卷积降维再卷积的参数量少很多。 -
改进后的inception模块具体卷积核信息
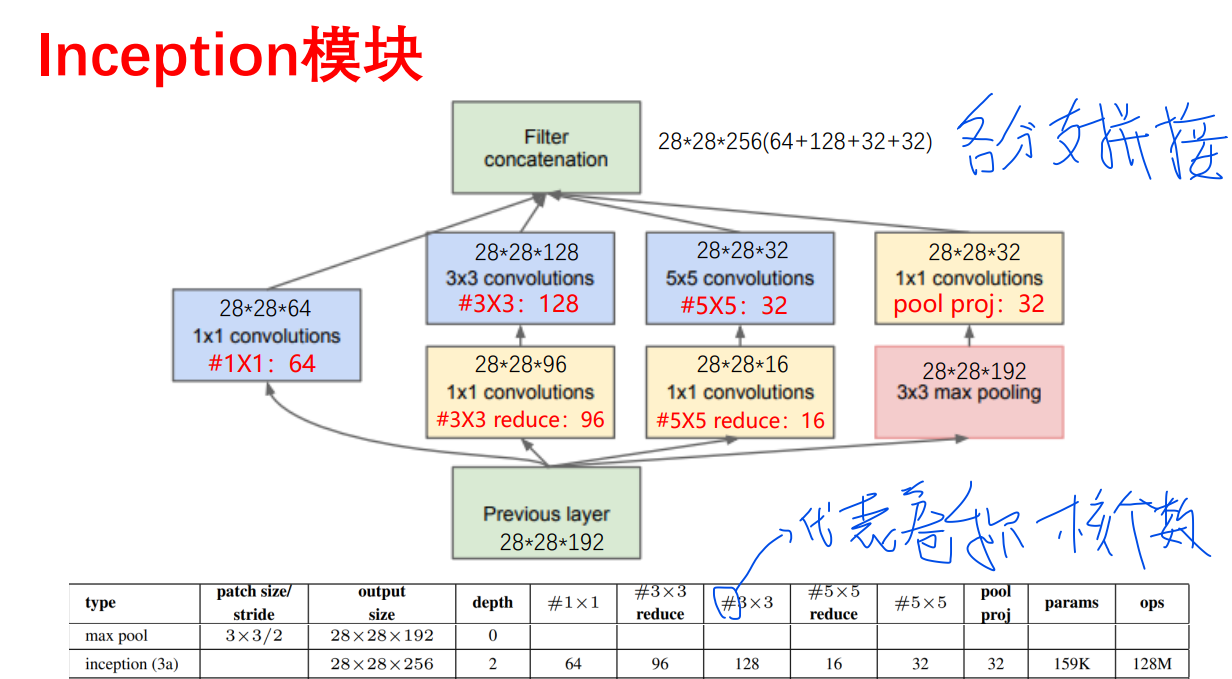
-
上图中Inception模块图与表的对应理解。上表中每行代表一层信息,带#列的每个数字代表卷积核的个数即Inception模块的参数信息,如上图中Inception模块层结构为:输入28 * 28 * 192的图片,首选,经过64个大小为1 * 1的卷积核的卷积层;其次,先经过96个大小为3 * 3的卷积核的卷积层降维,再经过128个大小为3 * 3的卷积核的卷积层;然后,先经过16个大小为 5 * 5的卷积核的卷积层降维,再经过32个大小为5 * 5的卷积核的卷积层;最后,先经过192个大小为 3 * 3的最大池化层,再经过32个大小为1 * 1的卷积核的卷积层;然后再将上面四个部分进行拼接。
-
代码小知识:TensorFlow中 padding = ‘same’时,输出图像的长和宽=输入图像 / 步长 (结果向上取整),因此,如果步长为1,卷积、池化操作不改变图像的长宽
-
辅助分类器结构
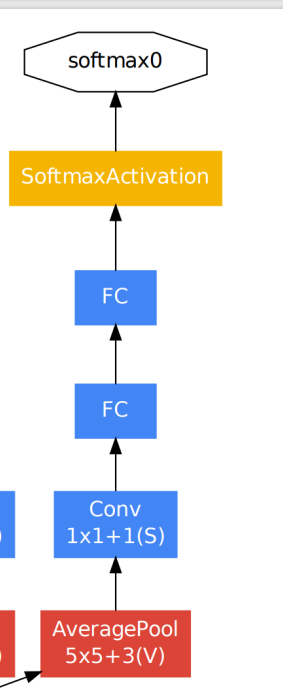
4.3 GoogleNet网络结构
- 网络结构图
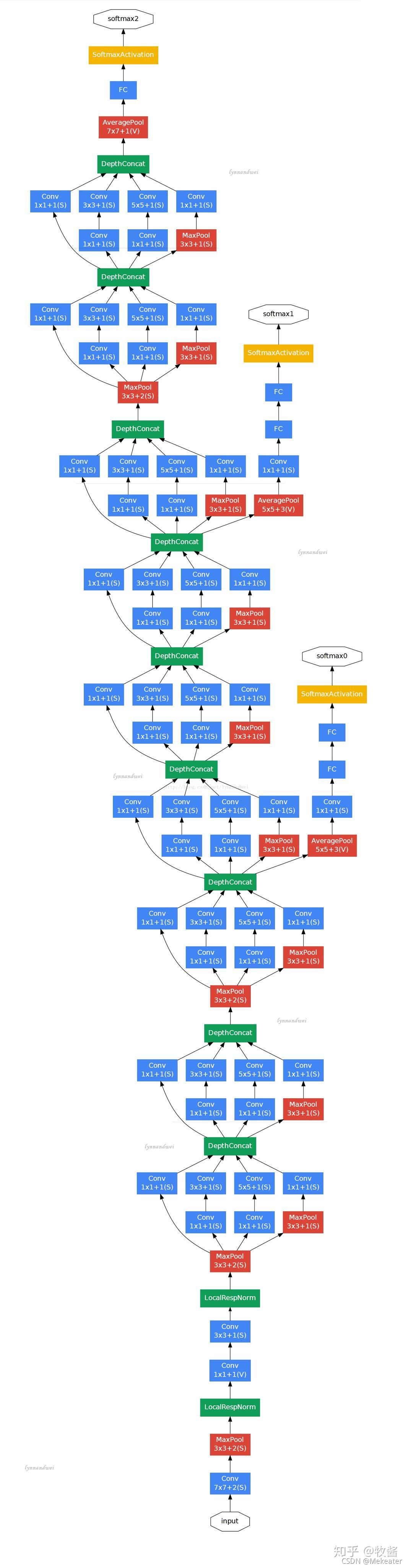
- 表格形式的网络结构表示
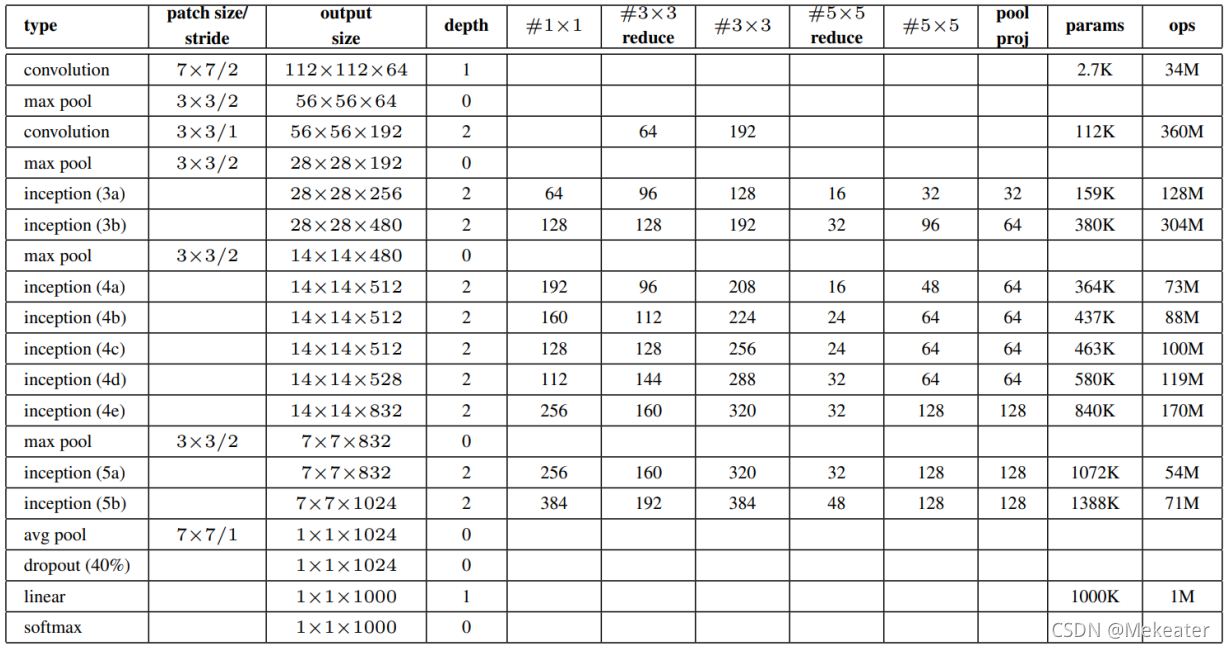
4.4 GoogleNet代码实现
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 1. 设置下面用的相关参数变量
train_dir = 'sat1/train'
test_dir = 'sat1/val'
batch_size = 32
img_size = 224
# 2. 读取文件夹数据
train_gen = ImageDataGenerator(rescale=1 / 255, horizontal_flip=True)
test_gen = ImageDataGenerator(rescale=1 / 255)
train_images = train_gen.flow_from_directory(directory=train_dir,
target_size=(img_size, img_size),
batch_size=batch_size,
shuffle=True,
class_mode='categorical') # 指定为多分类问题,并自动对类别进行编号和转为热编码
test_images = train_gen.flow_from_directory(directory=test_dir,
target_size=(img_size, img_size),
batch_size=batch_size,
shuffle=False,
class_mode='categorical') # 指定为多分类问题,并自动对类别进行编号和转为热编码
# 3. 查看自动给每个类别(子文件夹)赋予的索引
classes = train_images.class_indices
print("===============================类别索引============================")
print(classes)
# 4. 定义GoogleNet Inception 模块函数
def Inception(con1x1, con3x3reduce, con3x3, con5x5reduce, con5x5, pool_proj, input_):
inputs = tf.keras.layers.Input(shape=input_.shape[1:])
x1 = tf.keras.layers.Conv2D(filters=con1x1, kernel_size=(1, 1), activation='relu')(inputs)
x21 = tf.keras.layers.Conv2D(filters=con3x3reduce, kernel_size=(1, 1), activation='relu')(inputs)
x22 = tf.keras.layers.Conv2D(filters=con3x3, kernel_size=(3, 3), padding='same', activation='relu')(x21)
x31 = tf.keras.layers.Conv2D(filters=con5x5reduce, kernel_size=1, activation='relu')(inputs)
x32 = tf.keras.layers.Conv2D(filters=con5x5, kernel_size=5, padding='same', activation='relu')(x31)
x41 = tf.keras.layers.MaxPooling2D(pool_size=(3, 3), padding='same', strides=1)(inputs)
x42 = tf.keras.layers.Conv2D(filters=pool_proj, kernel_size=1, activation='relu')(x41)
# 将几个卷积模块在最后一个维度拼接
outputs = tf.concat((x1, x22, x32, x42), axis=-1)
return tf.keras.Model(inputs=inputs, outputs=outputs)
# 5. 定义GoogleNet 辅助分类器函数 (GoogleNet最终会有3个输出,2个辅助分类器输出,一个主输出)
def InceptionAux(num_classes, input_):
inputs = tf.keras.layers.Input(shape=input_.shape[1:])
x = tf.keras.layers.AvgPool2D(pool_size=5, strides=3)(inputs)
x = tf.keras.layers.Conv2D(128, kernel_size=1, activation="relu")(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dropout(rate=0.7)(x)
x = tf.keras.layers.Dense(1024, activation="relu")(x)
x = tf.keras.layers.Dropout(rate=0.7)(x)
x = tf.keras.layers.Dense(num_classes)(x)
return tf.keras.Model(inputs=inputs, outputs=x)
# 6. 搭建GoogleNet网络
def GoogleNet():
input_image = tf.keras.layers.Input(shape=(224, 224, 3))
x = tf.keras.layers.Conv2D(filters=64, kernel_size=7, strides=2, padding='same', activation='relu')(input_image)
x = tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding="same")(x)
x = tf.keras.layers.Conv2D(64, kernel_size=1, activation="relu")(x)
x = tf.keras.layers.Conv2D(192, kernel_size=3, padding="same", activation="relu")(x)
x = tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding="same")(x)
# 3a
x = Inception(64, 96, 128, 16, 32, 32, x)(x)
# 3b
x = Inception(128, 128, 192, 32, 96, 64, x)(x)
x = tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding="same")(x)
# 4a
x = Inception(192, 96, 208, 16, 48, 64, x)(x)
# aux1 辅助分类器(第一个输出)
aux11 = InceptionAux(5, x)(x)
aux1 = tf.keras.layers.Softmax(name="aux_1")(aux11)
# 4b
x = Inception(160, 112, 224, 24, 64, 64, x)(x)
# 4c
x = Inception(128, 128, 256, 24, 64, 64, x)(x)
# 4d
x = Inception(112, 144, 288, 32, 64, 64, x)(x)
# aux2 辅助分类器(第二个输出)
aux22 = InceptionAux(5, x)(x)
aux2 = tf.keras.layers.Softmax(name="aux_2")(aux22)
# 4e
x = Inception(256, 160, 320, 32, 128, 128, x)(x)
x = tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding="same")(x)
# 5a
x = Inception(256, 160, 320, 32, 128, 128, x)(x)
# 5b
x = Inception(384, 192, 384, 48, 128, 128, x)(x)
x = tf.keras.layers.AvgPool2D(pool_size=7, strides=1)(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dropout(rate=0.4)(x)
x = tf.keras.layers.Dense(5)(x)
# aux3 第三个最终输出
aux3 = tf.keras.layers.Softmax(name="aux_3")(x)
model = tf.keras.models.Model(inputs=input_image, outputs=[aux1, aux2, aux3])
return model
# 7. 网络预览
modelNet = GoogleNet()
# modelNet.summary()
# 8. 网络训练
modelNet.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.0005),
loss='categorical_crossentropy',
metrics=['acc'])
history = modelNet.fit(train_images, epochs=20, validation_data=test_images)
# 9. 绘制精度图
plt.plot(history.epoch, history.history.get('aux_3_acc'))
plt.plot(history.epoch, history.history.get('val_aux_3_acc'))
# 10. 模型评估(打印最后的模型训练精度及验证精度)
modelNet.evaluate(test_images)
# 11. 保存模型
modelNet.save('sat5.h5')
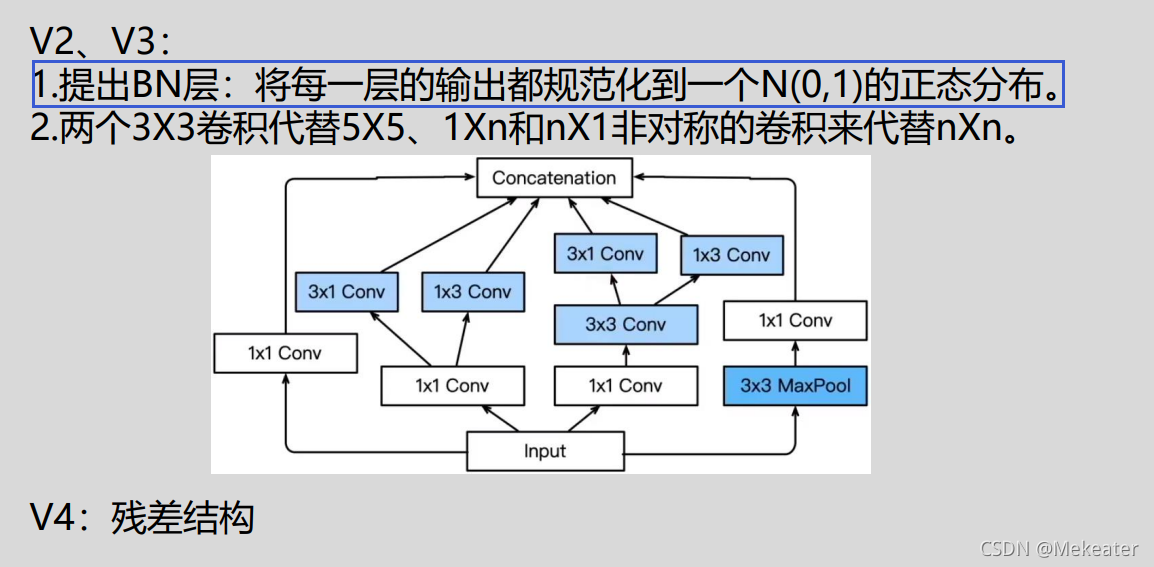
4.5 GoogleNet网络的发展(Inception V2 V3 V4)
5. ResNet实现遥感图像分类
5.1 数据集介绍
与AlexNet网络中使用的数据集一样
5.2 ResNet网络创新
第一. 该网络发现了通过残差结构避免网络退化现象,神经网络的“深度”首次突破了100层。
第二. 采用Batch Normalization 批量归一化,避免梯度消失和爆炸,使得训练更稳定。
- Batch Normalization 批量归一化:每一层输入的时候,先做一个归一化处理,然后再进入网络的下一层。这个输入值的分布强行拉回到均值为0方差为1。避免梯度消失和爆炸,训练更稳定。
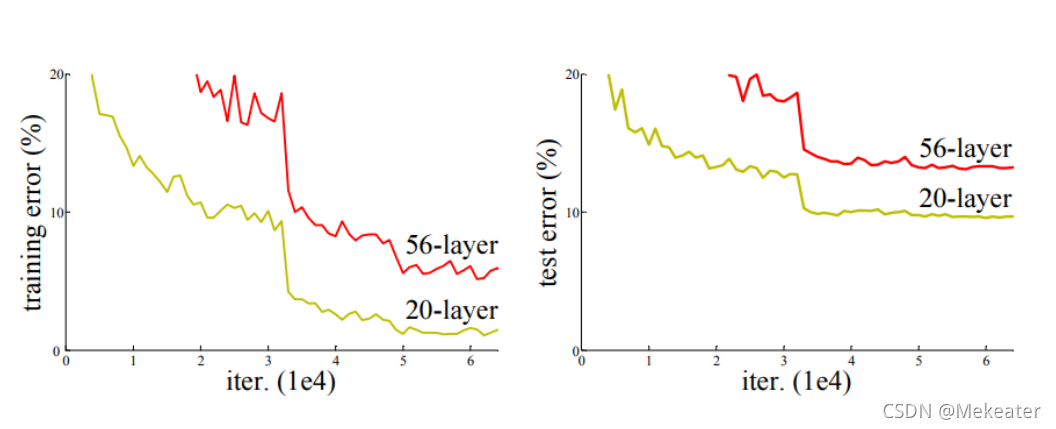
- 退化现象:网络层数的增多,训练集loss逐渐下降,然后趋于饱和。当你再增加网络深度的话,训练集loss反而增大。
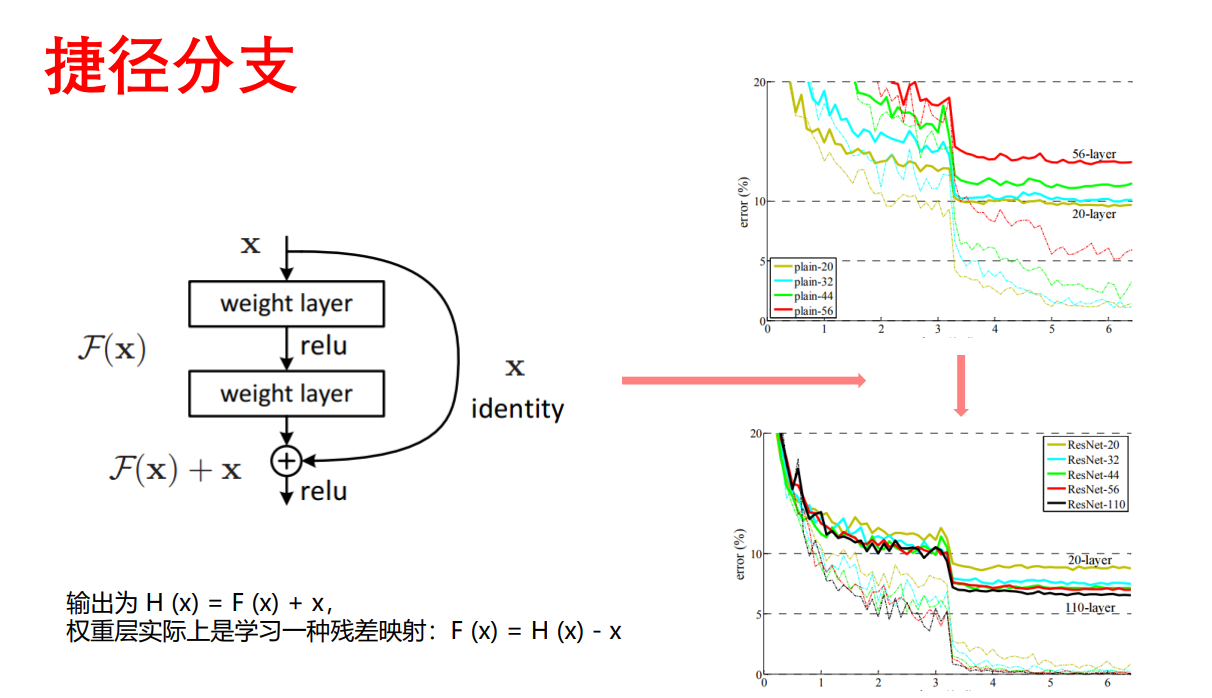
- 捷径分支:输入层与输出层进行求和,这样能够避免网络退化现象(我的理解是,求和后间接的是得到整体的残差,即将输入和输出之间无用的层给去掉了)
- 基于捷径分支的思想,ResNet18 和ResNet34的残差模块结构如下
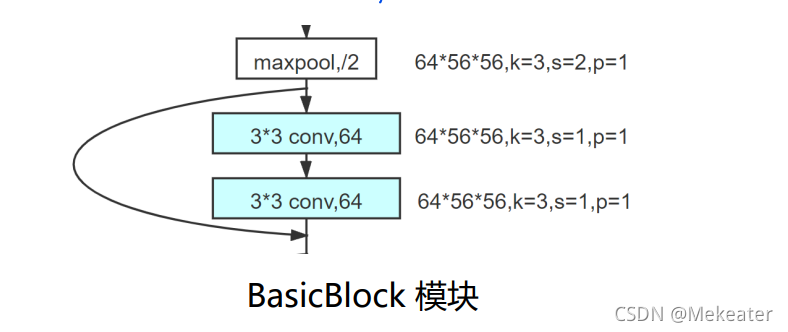
上图残差结构具体代码实现
# ResNet18 基本残差模块
def BasicBlock(filter_num, strides, _inputs):
x = tf.keras.layers.Conv2D(filters=filter_num, kernel_size=3, strides=strides, padding='same')(_inputs)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Activation('relu')(x)
x = tf.keras.layers.Conv2D(filter_num, kernel_size=3, strides=1, padding='same')(x)
x = tf.keras.layers.BatchNormalization()(x)
if strides != 1: # 如果步长不为1,则输出的大小会发生变化,则输入的大小也要变化,采用执行最后的求和操作
y = tf.keras.layers.Conv2D(filters=filter_num, kernel_size=1, strides=strides)(_inputs)
y = tf.keras.layers.BatchNormalization()(y)
else:
y = _inputs
output = tf.keras.layers.add([x, y])
output = tf.keras.layers.Activation('relu')(output)
return output
- 基于捷径分支的思想,ResNet50和ResNet101及ResNet152的残差模块结构如下

上图残差结构具体代码实现
# ResNet50 基本残差模块
def BottleNeck(filter_num, strides, _inputs, down=False):
x = tf.keras.layers.Conv2D(filters=filter_num, kernel_size=1, strides=1, padding='same')(_inputs)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Activation('relu')(x)
x = tf.keras.layers.Conv2D(filters=filter_num, kernel_size=3, strides=strides, padding='same')(x)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Activation('relu')(x)
x = tf.keras.layers.Conv2D(filters=filter_num * 4, kernel_size=1, strides=1, padding='same')(x)
x = tf.keras.layers.BatchNormalization()(x)
if strides != 1 or down == True:
y = tf.keras.layers.Conv2D(filters=filter_num * 4, kernel_size=1, strides=strides)(_inputs)
y = tf.keras.layers.BatchNormalization()(y)
else:
y = _inputs
output = tf.keras.layers.add([x, y])
output = tf.keras.layers.Activation('relu')(output)
return output
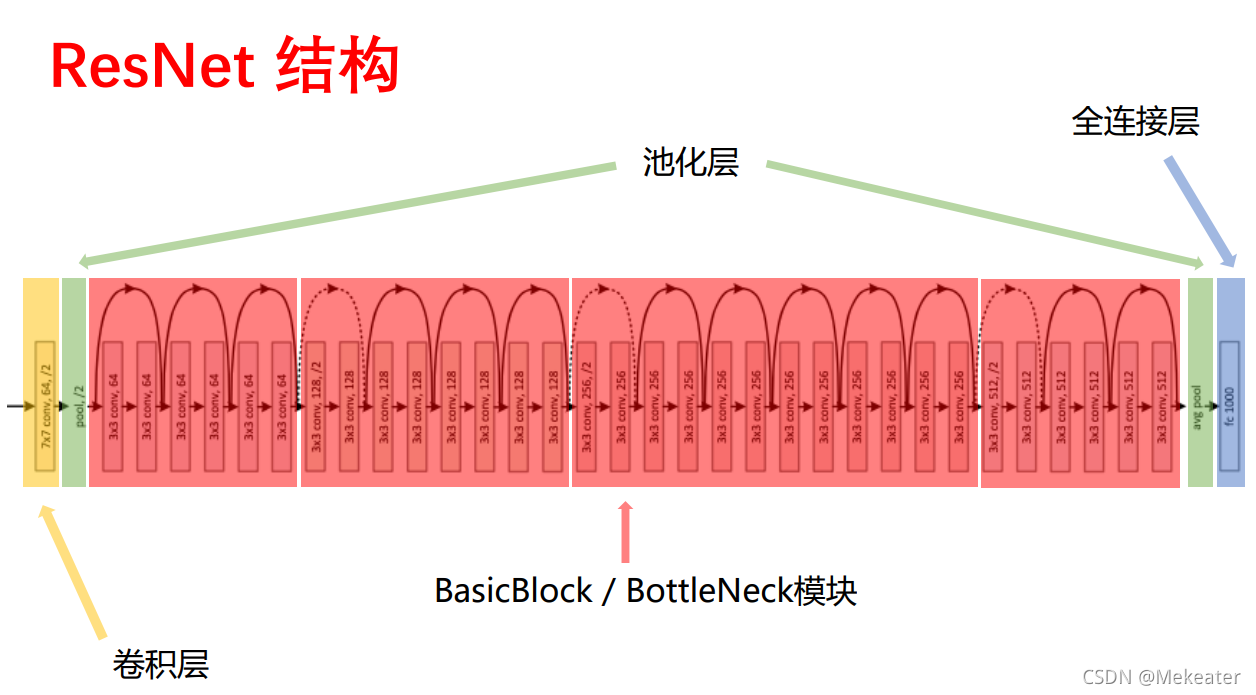
5.3 ResNet网络结构
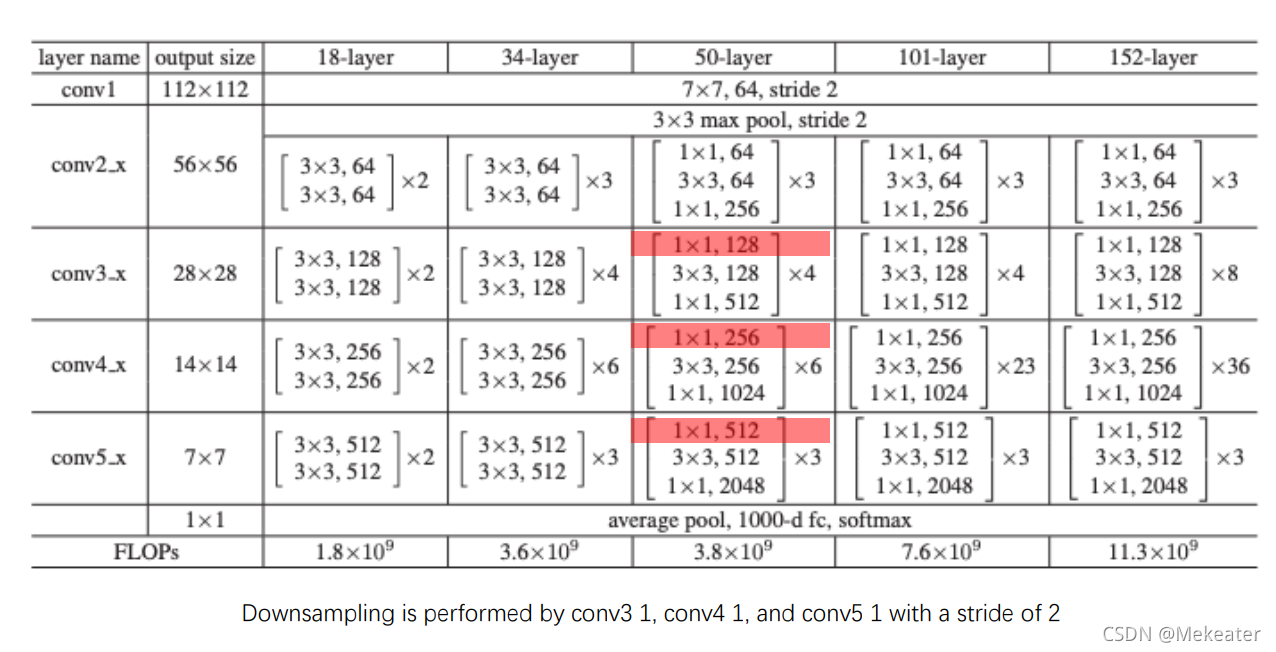
上表解释:
- 无论是ResNet18(有18层网络),还是其它都先经过一层卷积(卷积核大小为7 * 7,卷积核个数为64个,步长为2);然后再经过一层最大池化层。
- 然后每一个大括号代表一个残差结构(有2个或者3个卷积操作组成),大括号旁边的数字代表该残差结构重复的个数,同时要注意cov3_x,cov4_x,cov5_x中的第一层卷积的步长为2,其余全为1
- 最后再经过一层均值池化和全连接层,完成分类
如ResNet18的网络结构实现代码
input_image = tf.keras.layers.Input(shape=(224, 224, 3))
# 1. 一层卷积
x = tf.keras.layers.Conv2D(64, kernel_size=7, strides=2, padding="same")(input_image)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Activation('relu')(x)
# 2. 一层最大池化
x = tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding="same")(x)
# 3. 2个残差结构
x = BasicBlock(64, strides=1, _inputs=x)
x = BasicBlock(64, strides=1, _inputs=x)
# 4. 2个残差结构
x = BasicBlock(128, strides=2, _inputs=x)
x = BasicBlock(128, strides=1, _inputs=x)
# 5. 2个残差结构
x = BasicBlock(256, strides=2, _inputs=x)
x = BasicBlock(256, strides=1, _inputs=x)
# 6. 2个残差结构
x = BasicBlock(512, strides=2, _inputs=x)
x = BasicBlock(512, strides=1, _inputs=x)
# 7. 一层均值池化
x = tf.keras.layers.GlobalAveragePooling2D()(x)
# 8. 一层全连接层
x = tf.keras.layers.Dense(5, activation='softmax')(x)
model = tf.keras.models.Model(inputs=input_image, outputs=x)
return model
5.4 ResNet代码实现
ResNet-18和ResNet-50代码实现,其它ResNet代码实现类似
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
train_dir = 'sat1/train'
test_dir = 'sat1/val'
im_size = 224
batch_size = 32
train_images = ImageDataGenerator(rescale=1 / 255, horizontal_flip=True)
test_images = ImageDataGenerator(rescale=1 / 255)
train_gen = train_images.flow_from_directory(directory=train_dir,
batch_size=batch_size,
shuffle=True,
target_size=(im_size, im_size),
class_mode='categorical')
val_gen = test_images.flow_from_directory(directory=test_dir,
batch_size=batch_size,
shuffle=False,
target_size=(im_size, im_size),
class_mode='categorical')
# ResNet18 基本残差模块
def BasicBlock(filter_num, strides, _inputs):
x = tf.keras.layers.Conv2D(filters=filter_num, kernel_size=3, strides=strides, padding='same')(_inputs)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Activation('relu')(x)
x = tf.keras.layers.Conv2D(filter_num, kernel_size=3, strides=1, padding='same')(x)
x = tf.keras.layers.BatchNormalization()(x)
if strides != 1: # 如果步长不为1,则输出的大小会发生变化,则输入的大小也要变化,采用执行最后的求和操作
y = tf.keras.layers.Conv2D(filters=filter_num, kernel_size=1, strides=strides)(_inputs)
y = tf.keras.layers.BatchNormalization()(y)
else:
y = _inputs
output = tf.keras.layers.add([x, y])
output = tf.keras.layers.Activation('relu')(output)
return output
def ResNet18(): # 2 2 2 2
input_image = tf.keras.layers.Input(shape=(224, 224, 3))
x = tf.keras.layers.Conv2D(64, kernel_size=7, strides=2, padding="same")(input_image)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Activation('relu')(x)
x = tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding="same")(x)
x = BasicBlock(64, strides=1, _inputs=x)
x = BasicBlock(64, strides=1, _inputs=x)
x = BasicBlock(128, strides=2, _inputs=x)
x = BasicBlock(128, strides=1, _inputs=x)
x = BasicBlock(256, strides=2, _inputs=x)
x = BasicBlock(256, strides=1, _inputs=x)
x = BasicBlock(512, strides=2, _inputs=x)
x = BasicBlock(512, strides=1, _inputs=x)
x = tf.keras.layers.GlobalAveragePooling2D()(x)
x = tf.keras.layers.Dense(5, activation='softmax')(x)
model = tf.keras.models.Model(inputs=input_image, outputs=x)
return model
# ResNet50 基本残差模块
def BottleNeck(filter_num, strides, _inputs, down=False):
x = tf.keras.layers.Conv2D(filters=filter_num, kernel_size=1, strides=1, padding='same')(_inputs)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Activation('relu')(x)
x = tf.keras.layers.Conv2D(filters=filter_num, kernel_size=3, strides=strides, padding='same')(x)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Activation('relu')(x)
x = tf.keras.layers.Conv2D(filters=filter_num * 4, kernel_size=1, strides=1, padding='same')(x)
x = tf.keras.layers.BatchNormalization()(x)
if strides != 1 or down == True:
y = tf.keras.layers.Conv2D(filters=filter_num * 4, kernel_size=1, strides=strides)(_inputs)
y = tf.keras.layers.BatchNormalization()(y)
else:
y = _inputs
output = tf.keras.layers.add([x, y])
output = tf.keras.layers.Activation('relu')(output)
return output
def ResNet50(): # 3 4 6 3
input_image = tf.keras.layers.Input(shape=(224, 224, 3))
x = tf.keras.layers.Conv2D(64, kernel_size=7, strides=2, padding="same")(input_image)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding="same")(x)
x = BottleNeck(filter_num=64, strides=1, _inputs=x, down=True)
x = BottleNeck(filter_num=64, strides=1, _inputs=x)
x = BottleNeck(filter_num=64, strides=1, _inputs=x)
x = BottleNeck(filter_num=128, strides=2, _inputs=x)
x = BottleNeck(filter_num=128, strides=1, _inputs=x)
x = BottleNeck(filter_num=128, strides=1, _inputs=x)
x = BottleNeck(filter_num=128, strides=1, _inputs=x)
x = BottleNeck(filter_num=256, strides=2, _inputs=x)
x = BottleNeck(filter_num=256, strides=1, _inputs=x)
x = BottleNeck(filter_num=256, strides=1, _inputs=x)
x = BottleNeck(filter_num=256, strides=1, _inputs=x)
x = BottleNeck(filter_num=256, strides=1, _inputs=x)
x = BottleNeck(filter_num=256, strides=1, _inputs=x)
x = BottleNeck(filter_num=512, strides=2, _inputs=x)
x = BottleNeck(filter_num=512, strides=1, _inputs=x)
x = BottleNeck(filter_num=512, strides=1, _inputs=x)
x = tf.keras.layers.GlobalAveragePooling2D()(x)
x = tf.keras.layers.Dense(5, activation='softmax')(x)
model = tf.keras.models.Model(inputs=input_image, outputs=x)
return model
# 训练ResNet 18
model = ResNet18()
model.summary()
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.0005),
loss='categorical_crossentropy',
metrics=['acc'])
history = model.fit(train_gen, epochs=10, validation_data=val_gen)
plt.plot(history.epoch, history.history.get('acc'))
plt.plot(history.epoch, history.history.get('val_acc'))
model.evaluate(val_gen)