目录
2.2?Crowd region recognizer (CRR)
2.3?Density level estimator (DLE)
论文详情
Coarse- and Fine-grained Attention Network with Background-aware Loss for Crowd Density Map Estimation
标题:基于背景感知丢失的粗细粒度注意力网络人群密度图估计
作者: Liangzi Rong, Chunping Li
出处:Accepted by WACV 2020
论文链接:https://arxiv.org/abs/2011.03721
一、摘要
本文提出了一个新的粗细粒度注意力网络(CFANet)。CFANet通过合并注意力图更好地关注人群区域来生成高质量的人群密度图和人数估计。
1.通过人群区域识别器(CRR)和密度水平估计器(DLE)两个分支,我们设计了一个由粗到细的渐进注意机制,该机制可以减少不相关背景的影响,并根据人群密度水平分配注意权重。这么做的原因是直接生成精确的注意力图通常是困难的。
2.我们采用了多层次的监督机制,以协助梯度的反向传播和减少过拟合。
3.我们提出了基于背景感知的结构损失函数(BSL),以降低错误识别率,同时提高与groundtruth的结构相似性。
CFANet代码链接:https://github.com/rongliangzi/MARUNet
二、正文
1.介绍
近年来,人群密度图的估计作为一项具有挑战性的计算机视觉任务一直受到人们的关注。给定一个人群图像,它的目的是估计密度图和总人数。密度图中每个像素的值反映了图像中相应区域的密度,将所有像素的值进行累加即可得到估计的人数。
一般来说,准确统计人群有三个主要困难:
????????(1) 距离拍摄设备的距离不同,导致一张图像内和不同图像之间的比例变化。
????????(2) 高密度人群场景遮挡严重。
????????(3) 复杂且不相关的背景影响不利于识别人群区域。
解决方法:采用多分支或者多尺度的基于CNN的网络来获取丰富的特征信息。
上述方法的不足在于:
????????(1) 没有考虑背景的影响。把图片所有区域作为潜在人群区域,所以卷积可能在背景区域提取与人群无关的特征,从而导致错误识别。即使估计的总人数接近groundtruth,也可能是由于对人群区域的低估和对背景区域的错误识别造成的。
????????(2) 所有区域都视为相同。事实上,我们看一张人群密集的图片,对不同区域的关注度是不同的。对于高遮挡区域,难以区分每个人的特征,因此更需要被关注。对于低密度区域,更容易区分,因此不值得关注。然而目前的方法对于同一图像中的所有子区域进行相同的关注。
为了解决以上两个问题,我们希望设计一种注意机制,既能抑制背景的影响,减少误认,又能对不同密度区域自适应分配注意权重。
我们不妨假设:在一张注意力图中,背景区域的权重接近于0,而低密度区域的权重相对较低,而高密度区域的权重相对较高。如图1所示:

人眼看图片,首先看人在哪,然后是确定密度和人数。我们设计CNN自然而然遵循这样的范例。判断一个区域是否有人要比判断一个区域的密度水平更容易,所以如果我们从简单的任务开始,我们可以得到更可靠的结果。为此,我们提出了两个模块:?Crowd Region Recognizer (CRR) and Density Level Estimator (DLE)。CRR用来判断某区域是否有人,DLE用来判断密度水平。
更具体地说,CRR生成一个粗粒度注意图(CAM),它的值表示人存在的可能性。DLE生成一个细粒度的注意图(FAM),其值表示每个区域的密度级别。为了利用相对可靠的CAM,我们将FAM与之结合。然后将回归密度图的特征图与FAM多尺度结合,对不同区域进行自适应关注。
为了减少过拟合和便于梯度的反向传播,我们通过在内部层中增加多个输出层,并汇总所有损失函数和反向传播,从而引入多层次监督。
本文还探讨了不同损失函数的影响。我们提出了一种新的有效的损失函数: Background-aware Structural Loss (BSL)。用来考虑结构相似度、计数准确率和误识别率。
2.方法
CFANet结构图如图2所示:?

2.1 Feature map extractor
用于提取一般特征,这里采用VGG-16的特征提取部分。保留了前10个卷积层和3个池化层。从每个阶段得到大小为1、1/2、1/4、1/8的feature map。
2.2?Crowd region recognizer (CRR)
CRR生成的粗粒度注意图 (CAM)把特征图中的每个像素分成两类:人群和背景区域。
CRR详细配置:C(256,3)-U-C(128, 3)-U-C(128, 3)-U-C(64, 3)-C(1, 3)。C为卷积,U为rate=2的双线性上采样层。
在CRR的每个阶段,特征图都被输入3×3卷积层来回归粗粒度的注意图,然后在DLE中被输入相应的阶段。
对多阶段计算的损失进行求和反向传播。表示为图2中的灰色箭头。
2.3?Density level estimator (DLE)
DLE模块的目标是将人群区域进一步划分为不同的密度级别。与CRR类似,这个模块也应该尝试减少背景对结果的影响。
根据统计得到的阈值将所有像素划分为k类别,即k类分类问题。这个过程产生groundtruth记为?FAM。k类分类后,不同的注意力权重被相应地分配。将分类为0的像素作为背景,将注意力权重设为0。对于其他密度级别,我们将(0,1]的范围划分为k-1类。
比如说:
? ? ? ? k=6时,类1-5分别对应0.2、0.4、0.6、0.8和1。
我们对类别数量进行了消融实验,证明k=6时表现最好。
DLE详细配置:C(256,3)-U-C(256, 3)-U-C(128, 3)-U-C(64, 3)-C(k,3)。其中C为卷积层,U为双线性上采样层。
在DLE的每个阶段,特征图被输入3×3卷积层,并回归一个细粒度的注意图。
对多阶段计算的损失进行求和反向传播。表示为图2中的绿色箭头。
利用上个阶段CRR生成的CAM来改善FAM:
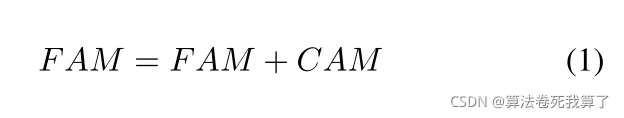
?然后FAM被送入下一部分的相应阶段。
2.4 Density map estimator
这个模块的配置与一开始的特征映射提取器几乎是对称的。
DME详细配置:C(512, 3)-U-C(256, 3)-U-C(256, 3)-U-C(64, 3)-C(1, 1)。其中C为卷积,U为双线性上采样层。我们将所有卷积层的膨胀率设为2以扩大感受野。
我们使用注意力图来更好地关注人群。之前这方面的研究的如图三所示:
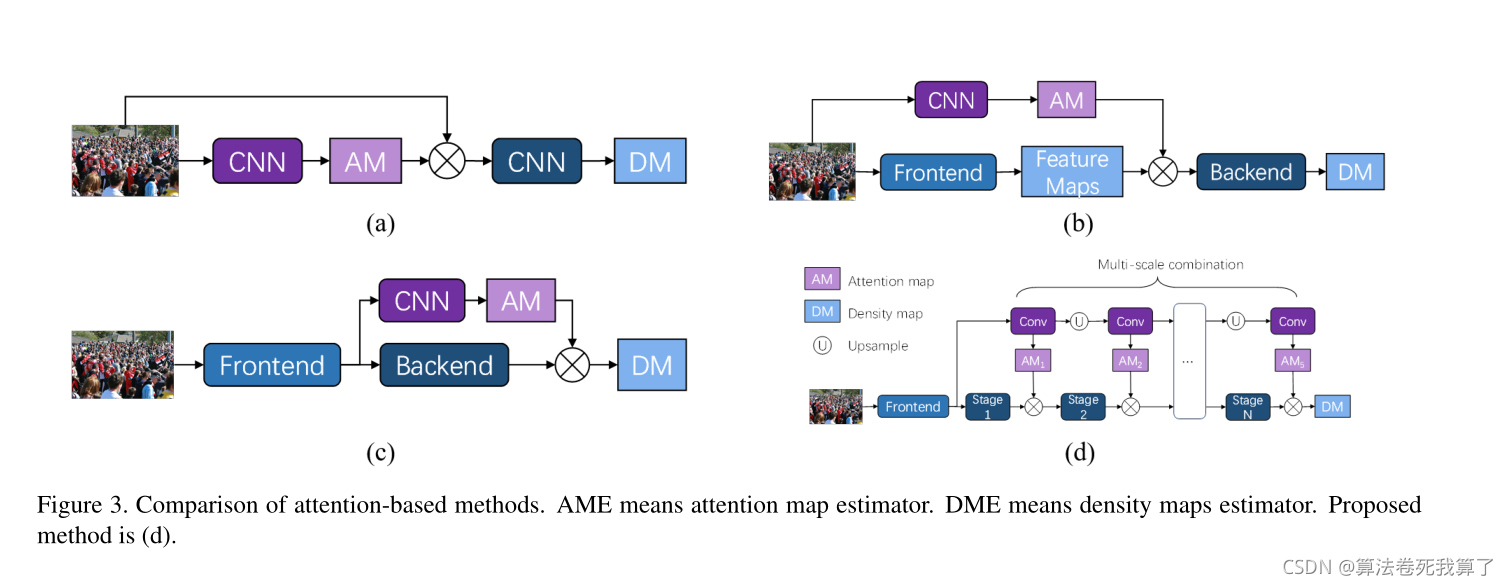
(a):将输入图像与预测的注意力图相乘,然后使用它进行回归。
(b):将前端提取的特征图与预测的注意力图相乘。
(c):在最后一个卷积层之前插入一个注意力分支来预测注意力地图。密度图与预测的注意力图相乘作为最终输出。
(c)中估计的注意地图分配给背景区域的权重不等于0,所以一次性组合不能完全减轻背景的影响。因此我们提出了(d)方案。
(d):在这个模块的每个阶段,feature map (FM)和来自DLE的细粒度attention map (FAM)都以一种残差的方式进行组合。
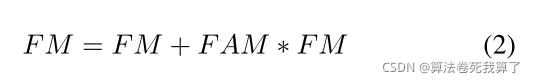
我们还实行了多层次监督机制。每个阶段的特征图将被上采样到输入图像的大小,并送入3×3卷积层来回归密度图。如图2中的蓝色箭头所示。因此,对于每一个输入图像,CFANet将产生4个密度图,并对4个loss进行求和并反向传播。一般来说,越深的网络表达能力越强,所以我们将最后一层的输出作为最终输出

?2.5?Loss function
我们首先引入一个结构损失函数(SL),它同时考虑结构相似性和计算精度。定义如下:
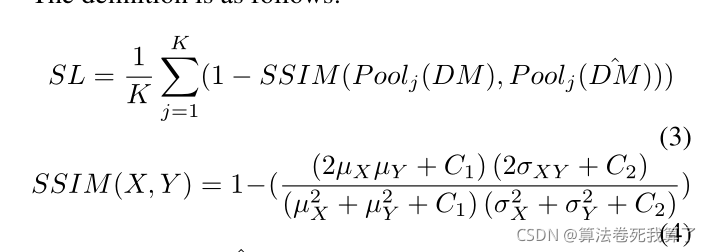
为了降低错误识别率,我们增加了背景感知loss(BL)

密度图优化的损失函数(BSL)是SL和BL的和。为了优化粗粒度和细粒度的注意力图,我们使用交叉熵作为损失函数。最后的损失函数是多个阶段的密度图和注意图损失函数的加权和。
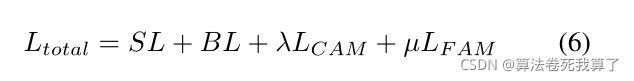
由于将图像划分为背景和人群是最容易的任务,而密度多分类难度中等,回归每个像素的精确密度值是最困难的,因此我们在损失函数中采用了动态权值调整策略。
动态权值调整策略:在初始训练阶段,网络无法准确捕获分布特征。因此,我们更多地关注简单的任务,并将二值分类和多类分类的权重设得较大。随着训练过程的进行,网络的代表性能力不断提高,能够更好地捕捉特征。此时,将密度图损失的权重调整为较大。如图4所示:

三、总结
本文提出了一种用于高质量人群密度地图生成和人口统计的粗细粒度注意网络模型(CFANet)。结合人群区域识别器(CRR)和密度水平估计器(DLE)对粗粒度和细粒度注意图进行估计,在多尺度上细化用于密度图回归的特征图,使网络更好地聚焦于人群区域。我们还采用了多层次监督,以帮助促进梯度的反向传播和减少过拟合。此外,我们提出了一种新的有效的损失函数,即背景感知结构损失(BSL),该函数可以达到更好的计数精度,增强结构相似度,降低错误识别率。将CFANet与BSL相结合可以在大多数常用数据集上优于目前最先进的方法。