����ѧϰ֮���ٰ�Ԥ��
(һ)�������
1.���ⱳ��
���ٰ���Ů������Ķ�������,ռ����Ů��ȷ�ﰩ֢�Ľ�����֮һ,��Ů��֢�����ĵڶ���ԭ�� ���ٰ����鷿��֯ϸ���쳣�����Ľ��,ͨ����Ϊ������ ����������ζ�Ű�֢������������������(�ǰ���)������ǰ(��ǰ)�����(����)�� MRI���鷿X���顢�������ͻ���֯���Ȳ���ͨ��������������е����ٰ���
2.�������
ԭ��:�鷿ϸ����� (FNA) ���Լ������ٰ�(����һ�ֿ����Ҽij���,�ó�����Դ��鷿���������(�顢���������)��ȡ��һЩҺ���ϸ��,�������� Ѫ����)��
ͨ��������ݺͱ�ǩ����ģ��,ʵ�ֶ����ٰ��������з���:
1 = ���� (����)
0 = ���� (�ǰ���)
������,����һ�����������⡣
3.��Ŀ����Ĵ��뼰����
����:https://pan.baidu.com/s/1bS7Ku_PUfcimiVkmLz9Fzw
��ȡ��:0929
(��).��������
1. ��ʶ���ݼ�
���ݼ��е�ǰ���зֱ�洢������Ψһ ID �ź���Ӧ�����(M=����,B=����)��
�� 3-32 �а��� 30 ��ʵֵ����,��Щ�����Ǹ���ϸ���˵����ֻ�ͼ�����ó���,�����ڹ���ģ����Ԥ�����������Ի��Ƕ��ԡ�
Ϊÿ��ϸ���˼���ʮ��ʵֵ����:
a) �뾶(�����ĵ��ܱߵ��ƽ������)
b) ����(�Ҷ�ֵ�ı�ƫ��)
c) �ܳ�
d) ���
e) ƽ����(�뾶���ȵľֲ��仯)
f) ������(�ܳ�^2/��� - 1.0)
g) ����(�������벿�ֵ����س̶�)
h) ����(�������벿�ֵ�����)
i) �Գ���
j) ����ά��(�������߽��ơ� - 1)
2.��������
#load libraries
import matplotlib.pyplot
import matplotlib.pyplot as plt
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
data = pd.read_csv('data/data.csv', index_col=False,)
print("���һ�����ݵ�������:",end="")
print(data.shape)
print("���һ�����ݵ���Ϣ:")
data.info()
data.dtypes.value_counts
#���ȱ�ٵı���
data.isnull().any()
data.diagnosis.unique()
print("���Ĺ�������ݱ��浽��csv�ļ���(����dataframe�ĸ��°汾�Ա���������)")
data.to_csv('data/clean-data.csv')
# �鿴����ǰ����
print(data.head(2))
# �Ա�ǩ����ͳ��
#����:���� ��ԼΪ2:1. �ڻ���ѧϰ���������������1:1,����2:1Ҳ���Խ��������ķ���Ԥ�⡣
data.diagnosis.value_counts().plot(kind = "bar")
plt.title("Show me the ratio of benign to malignant")
matplotlib.pyplot.show()
3.���ݸ���
�ܹ�30������,�ֱ��Ƕ�10��ʵֵ��������,mean, se, worst
diagnosis ��Ϊ��ǩ
������ֵ
(��)EDA ����̽���Է���
̽�������ݷ���(EDA)��һ���dz���Ҫ�IJ���,Ӧ�����κν�ģ֮ǰ�����������Ϊ���ݿ�ѧ���ܹ��ڲ��������������������ݵ����ʡ�����̽����Ҫ������,���ݵĽṹ,ֵ�ķֲ�,�����ݼ����Ƿ�����쳣ֵ,���������ϵ��
��Ҫ����:
������ͳ�Ʒ���
���ݿ��ӻ�
1.������ͳ�Ʒ���
A.�鿴����ά��(������)
���һ�����ݵ�������:(569, 32)
B.����ͳ������(������Ӧ����Ϣ)
���һ�����ݵ���Ϣ:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 569 entries, 0 to 568
Data columns (total 32 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 569 non-null int64
1 diagnosis 569 non-null object
2 radius_mean 569 non-null float64
3 texture_mean 569 non-null float64
4 perimeter_mean 569 non-null float64
5 area_mean 569 non-null float64
6 smoothness_mean 569 non-null float64
7 compactness_mean 569 non-null float64
8 concavity_mean 569 non-null float64
9 concave points_mean 569 non-null float64
10 symmetry_mean 569 non-null float64
11 fractal_dimension_mean 569 non-null float64
12 radius_se 569 non-null float64
13 texture_se 569 non-null float64
14 perimeter_se 569 non-null float64
15 area_se 569 non-null float64
16 smoothness_se 569 non-null float64
17 compactness_se 569 non-null float64
18 concavity_se 569 non-null float64
19 concave points_se 569 non-null float64
20 symmetry_se 569 non-null float64
21 fractal_dimension_se 569 non-null float64
22 radius_worst 569 non-null float64
23 texture_worst 569 non-null float64
24 perimeter_worst 569 non-null float64
25 area_worst 569 non-null float64
26 smoothness_worst 569 non-null float64
27 compactness_worst 569 non-null float64
28 concavity_worst 569 non-null float64
29 concave points_worst 569 non-null float64
30 symmetry_worst 569 non-null float64
31 fractal_dimension_worst 569 non-null float64
dtypes: float64(30), int64(1), object(1)
C.�鿴������Ϣ(ͳ��ѧ��Ϣ)
���һ�¶����ݵ�ͳ������:
radius_mean texture_mean ... symmetry_worst fractal_dimension_worst
count 569.000000 569.000000 ... 569.000000 569.000000
mean 14.127292 19.289649 ... 0.290076 0.083946
std 3.524049 4.301036 ... 0.061867 0.018061
min 6.981000 9.710000 ... 0.156500 0.055040
25% 11.700000 16.170000 ... 0.250400 0.071460
50% 13.370000 18.840000 ... 0.282200 0.080040
75% 15.780000 21.800000 ... 0.317900 0.092080
max 28.110000 39.280000 ... 0.663800 0.207500
[8 rows x 30 columns]
D.ȱʧ����
#���ȱ�ٵı���
data.isnull().any()
data.diagnosis.unique()
2.���ݿ��ӻ�
A.���ݷֲ����
����:���� ��ԼΪ2:1. �ڻ���ѧϰ���������������1:1,����2:1Ҳ���Խ��������ķ���Ԥ�⡣
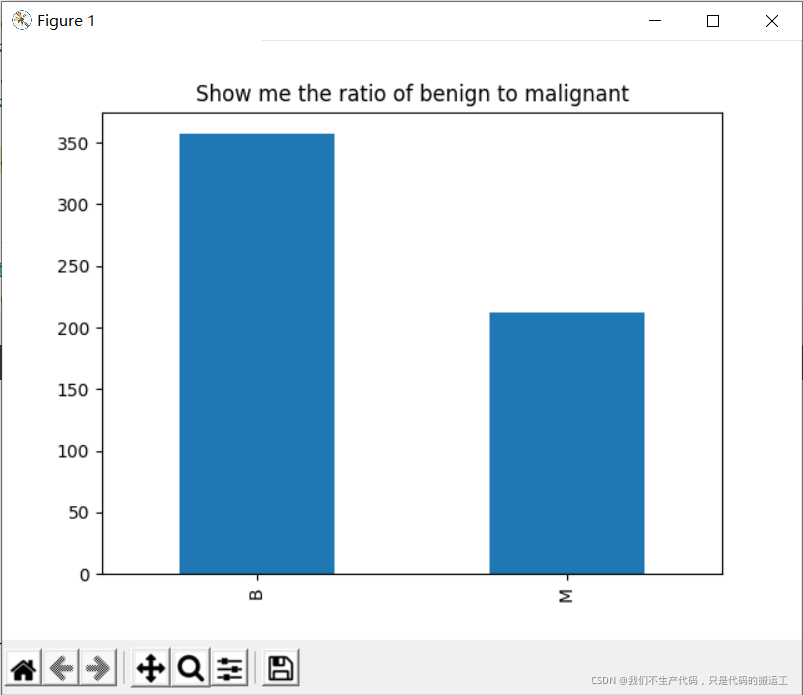
���ݿ��ӻ�����ֱ��ͼ
�����������ӻ� �C ֱ��ͼ
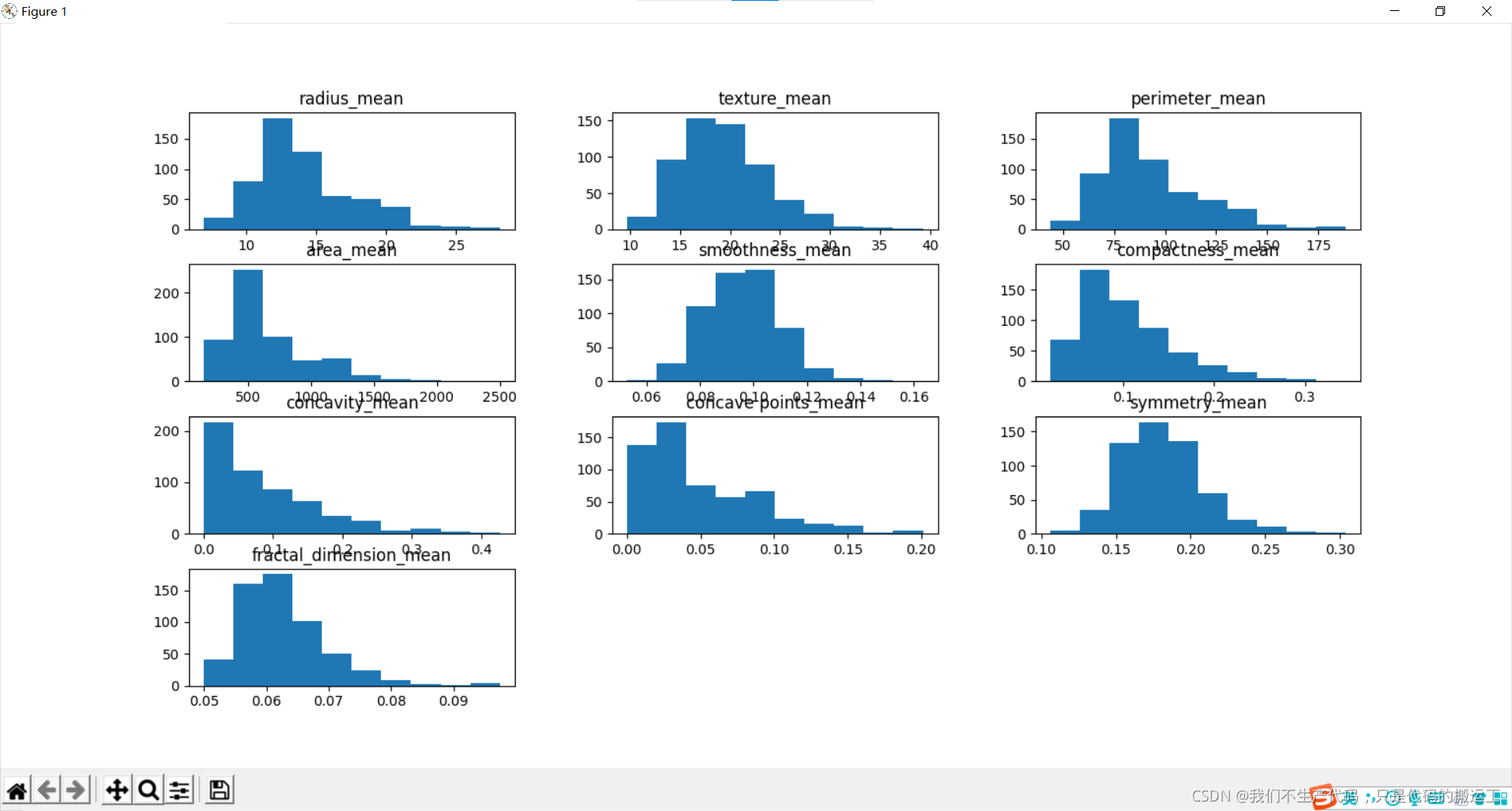
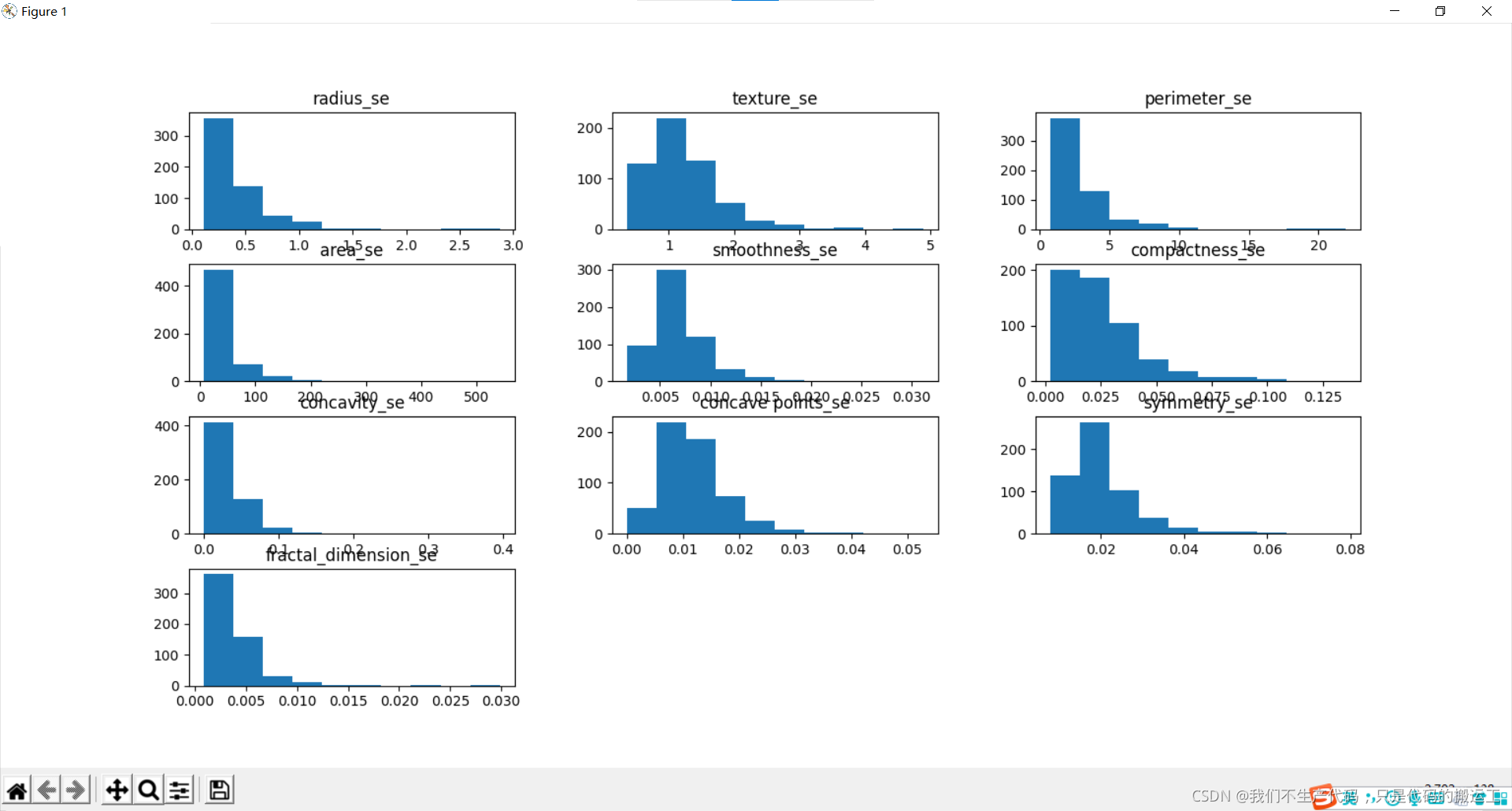
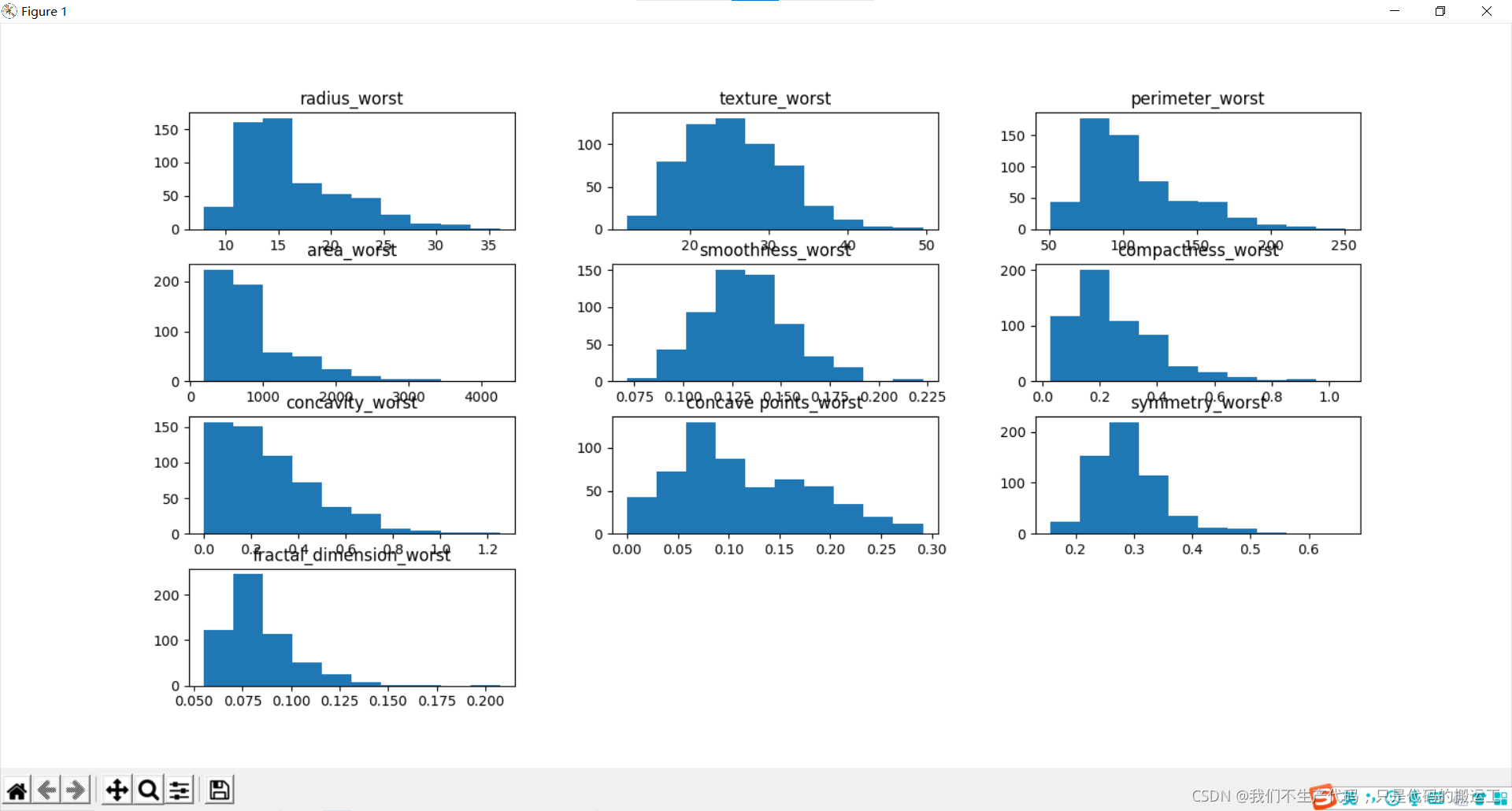 ���ǿ��Կ���,Ҳ������ ����, ���� ���ܾ���ָ���ֲ��� ���ǻ����Կ���,����,ƽ��,�Գ����Կ��ܾ��и�˹��ӽ���˹�ֲ����������ѧϰ����������������ĸ�˹�������ֲ���
���ǿ��Կ���,Ҳ������ ����, ���� ���ܾ���ָ���ֲ��� ���ǻ����Կ���,����,ƽ��,�Գ����Կ��ܾ��и�˹��ӽ���˹�ֲ����������ѧϰ����������������ĸ�˹�������ֲ���
���ݿ��ӻ����������ܶ�ͼ
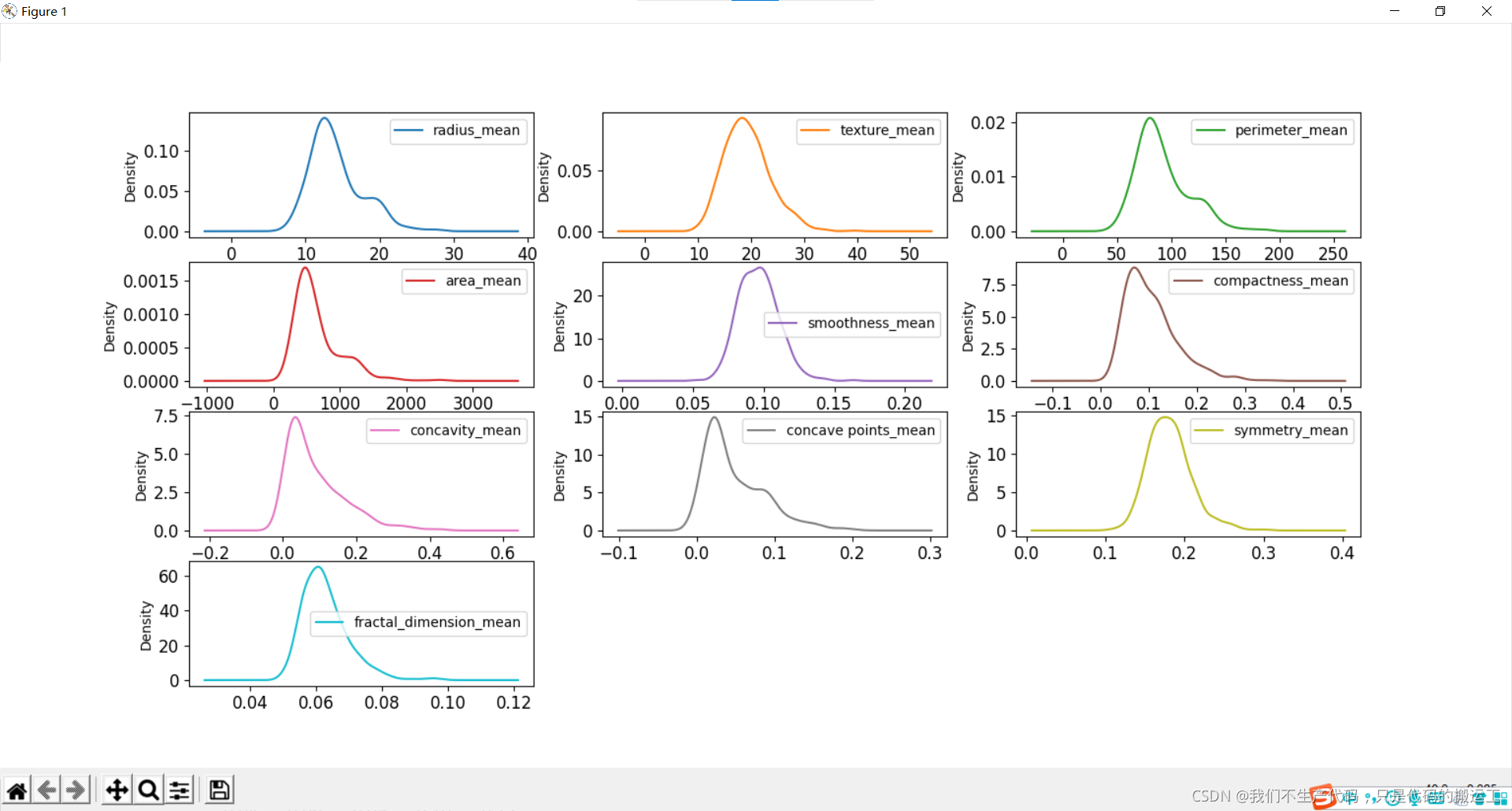
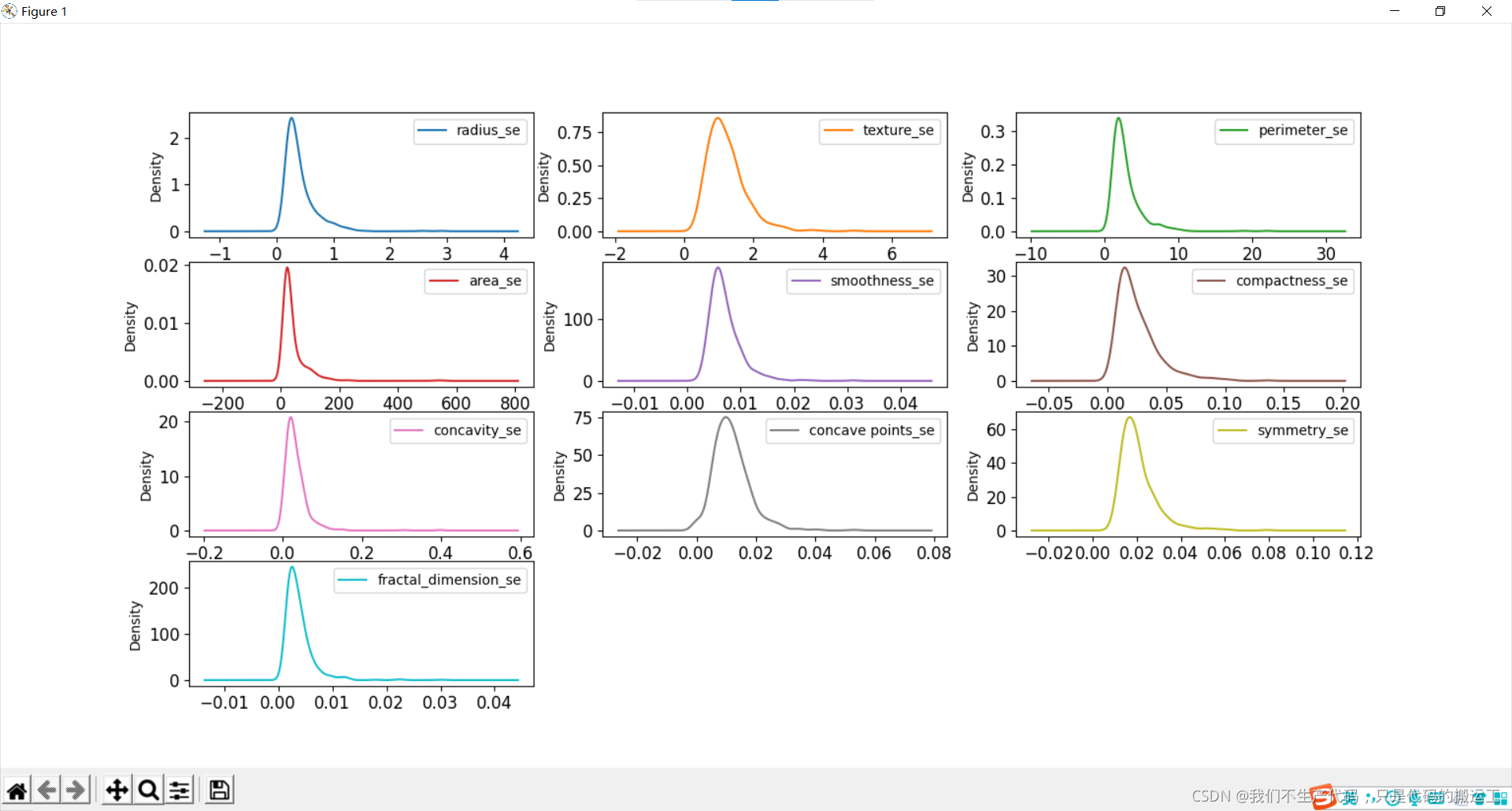
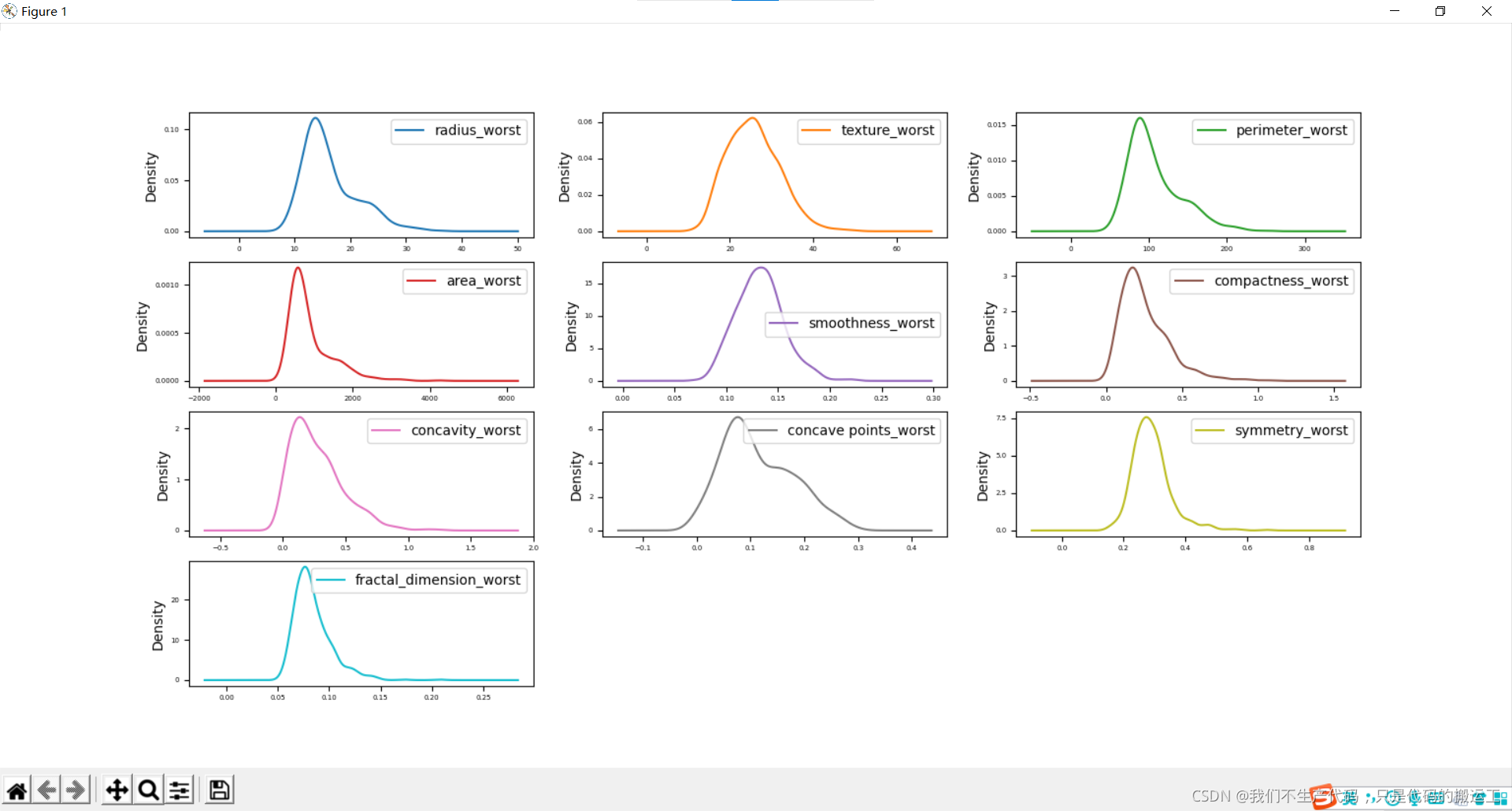 �ܳ����뾶����������ȡ��ܶȿ��ܾ���ָ���ֲ�; ������ƽ�����Գ����Կ��ܾ��и�˹��ӽ���˹�ֲ���
�ܳ����뾶����������ȡ��ܶȿ��ܾ���ָ���ֲ�; ������ƽ�����Գ����Կ��ܾ��и�˹��ӽ���˹�ֲ���
���ļ������������ǵ������������������ʱ,�����ķֲ���ӽ���̬�ֲ�,����Щ���������ķֲ��Ͳ�����̬��,��ô����һЩ����̬����ļ���,���Ƶ�ģ����˵,����Ҫ���ȶԱ������ֲ��任
��һ���漫���С��ֵ�����任�������ֵ�����С,�����˼�ֵ��ģ�͵��Ŷ�
���ݿ��ӻ���������ͼ
ͨ������ͼ���ӻ����ݷֲ�������쳣ֵ
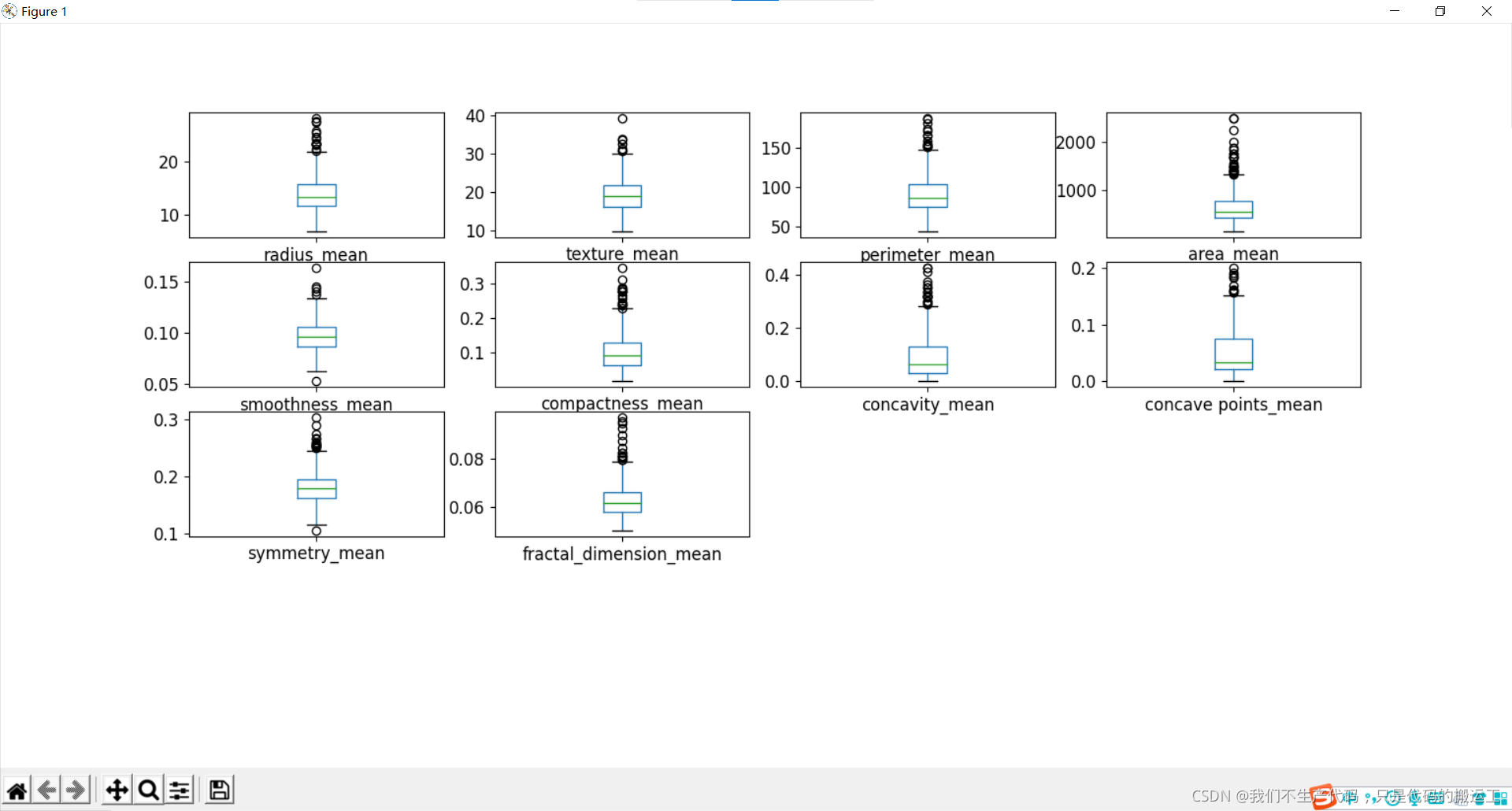
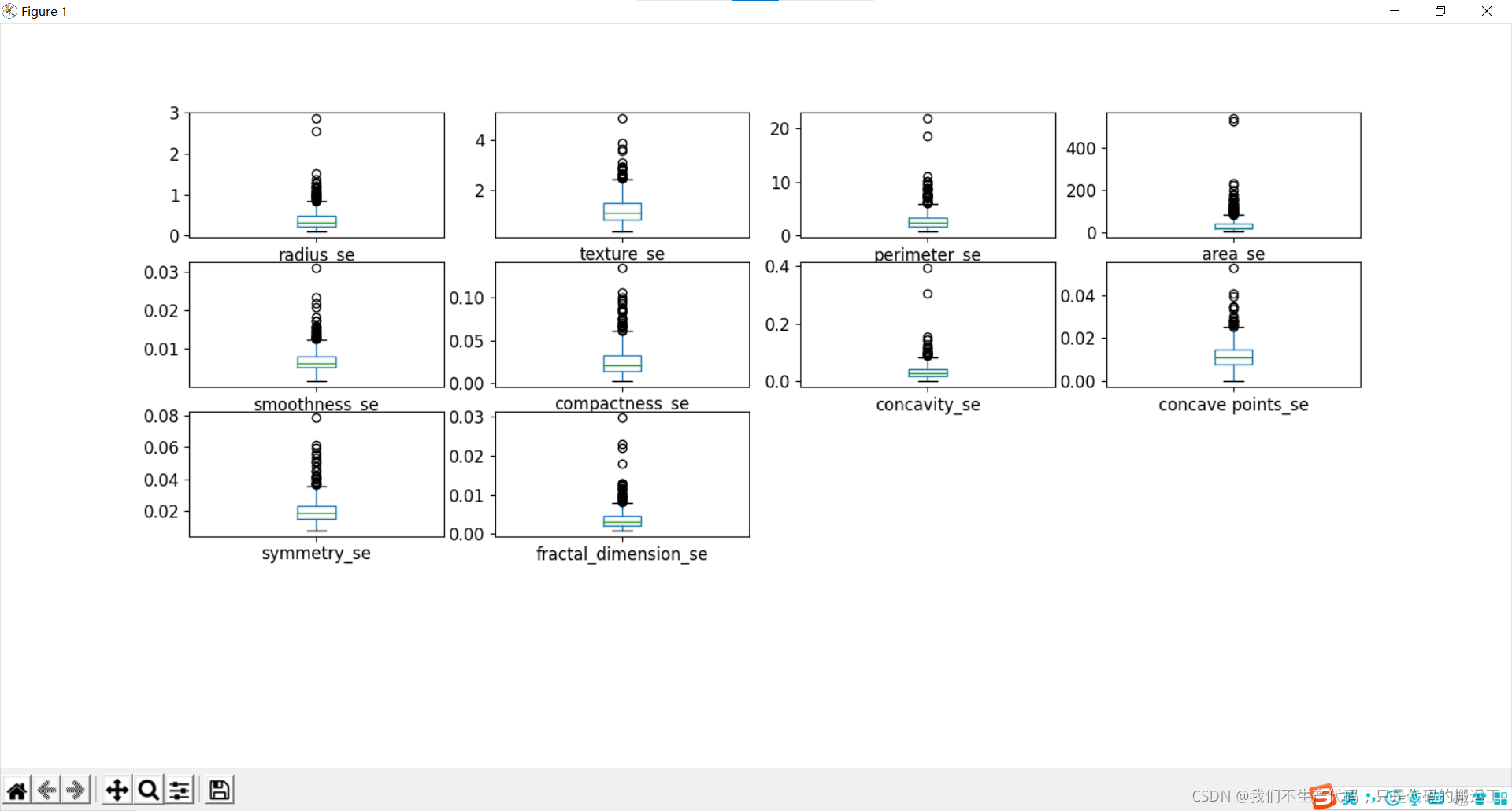
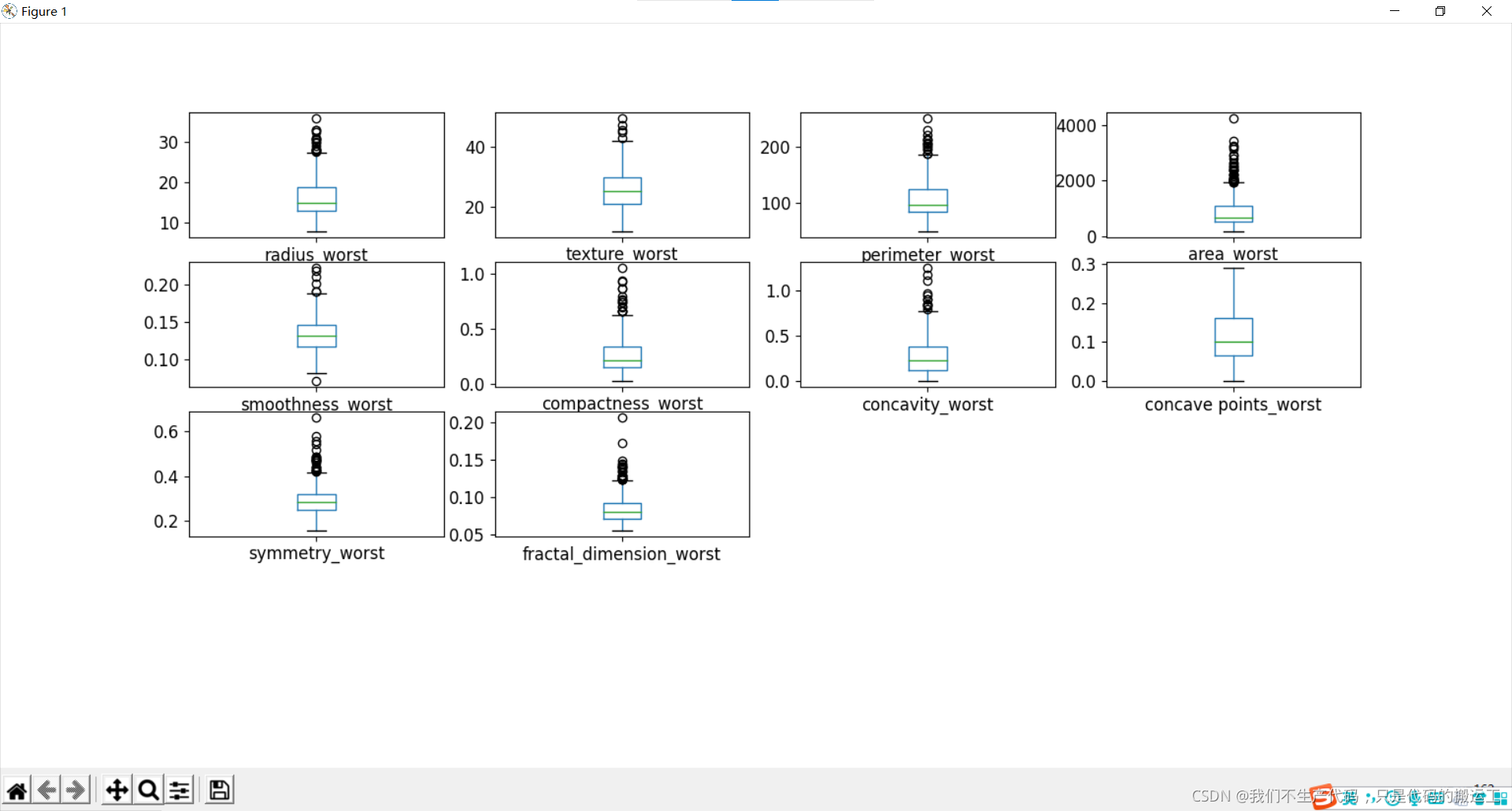
��:
ϸ���뾶���ܳ�����������ܶȡ����ȺͰ����ƽ��ֵ�����ڰ�֢�ķ��ࡣ ��Щ�����Ľϴ�ֵ��������ʾ���������������ԡ�
�ʵء�ƽ���ȡ��Գ��Ի��ά����ƽ��ֵ��δ��ʾ���Ϻõ����ƫ�á�
���κ�ֱ��ͼ��,��û�����Ե��쳣ֵ��Ҫ��һ������
(��).Ԥ��������������
1.�������ݼ�
print("�������ݼ�")
#Assign predictors to a variable of ndarray (matrix) type
X = data.iloc[:,2:32]#�ӵڶ��е���32��
y = data.iloc[:,1].apply(lambda x: 1 if x == "M" else 0)#��һ�е�����
##Split data set in train 70% and test 30%
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=7)
#��ʵ���Ǹ���������ı��,����Ҫ�ظ������ʱ��,��֤�õ�һ��һ�����������
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape)
2.���ݱ�������
print("���ݱ���(��������(��0Ϊ���IJ���������������))")
scaler =StandardScaler()
Xs = scaler.fit_transform(X)
print(Xs)
3.PCA��ά
print("PCA��ά(��ά����֮�������)")
# �� 30ά ���� 10ά
pca = PCA(n_components=10)
fit = pca.fit(Xs)
X_pca = pca.transform(Xs)
PCA_df = pd.DataFrame()
PCA_df['PCA_1'] = X_pca[:,0]
PCA_df['PCA_2'] = X_pca[:,1]
print(PCA_df['PCA_1'] )
print(PCA_df['PCA_2'] )
## ���ӻ�
plt.figure(figsize=(10,6))
#��һ�½�ά��Ķ��� ���Ե�ͼ
plt.plot(PCA_df['PCA_1'][data.diagnosis == 'M'],
PCA_df['PCA_2'][data.diagnosis == 'M'],
'o', alpha = 0.7, color = 'r')
plt.plot(PCA_df['PCA_1'][data.diagnosis == 'B'],
PCA_df['PCA_2'][data.diagnosis == 'B'],
'o', alpha = 0.7, color = 'b')
plt.xlabel('PCA_1')
plt.ylabel('PCA_2')
plt.title("View the discrimination of features after dimensionality reduction")
plt.legend(['Malignant','Benign'])
plt.show()
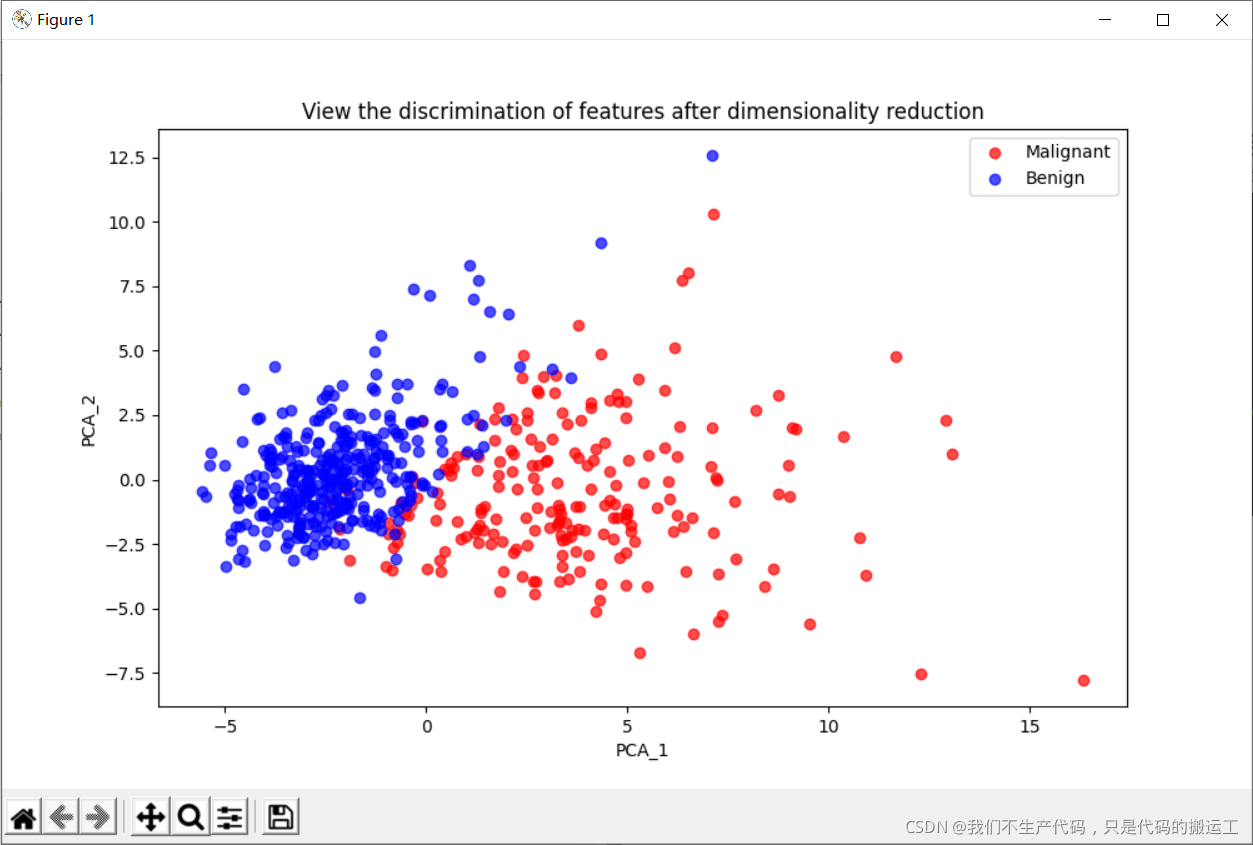
4. ��һ�½�ά��Ķ��� ���Ե�ͼ
#��һ�½�ά��Ķ��� ���Ե�ͼ
plt.plot(PCA_df['PCA_1'][data.diagnosis == 'M'],
PCA_df['PCA_2'][data.diagnosis == 'M'],
'o', alpha = 0.7, color = 'r')
plt.plot(PCA_df['PCA_1'][data.diagnosis == 'B'],
PCA_df['PCA_2'][data.diagnosis == 'B'],
'o', alpha = 0.7, color = 'b')
plt.xlabel('PCA_1')
plt.ylabel('PCA_2')
plt.title("View the discrimination of features after dimensionality reduction")
plt.legend(['Malignant','Benign'])
plt.show()
#ÿ��PC���͵IJ�����
var = pca.explained_variance_ratio_
### ͨ���յ�ȷ��ѡ��ǰ����PC
plt.plot(var)
plt.title('Scree Plot')
plt.xlabel('Principal Component')
plt.ylabel('Eigenvalue')
#дһ�±�ǩ������
leg = plt.legend(['Eigenvalues from PCA'],
loc='best',
borderpad=0.3,
shadow=False,
markerscale=0.4)
leg.get_frame().set_alpha(0.4)
leg.set_draggable(state=True)
plt.show()
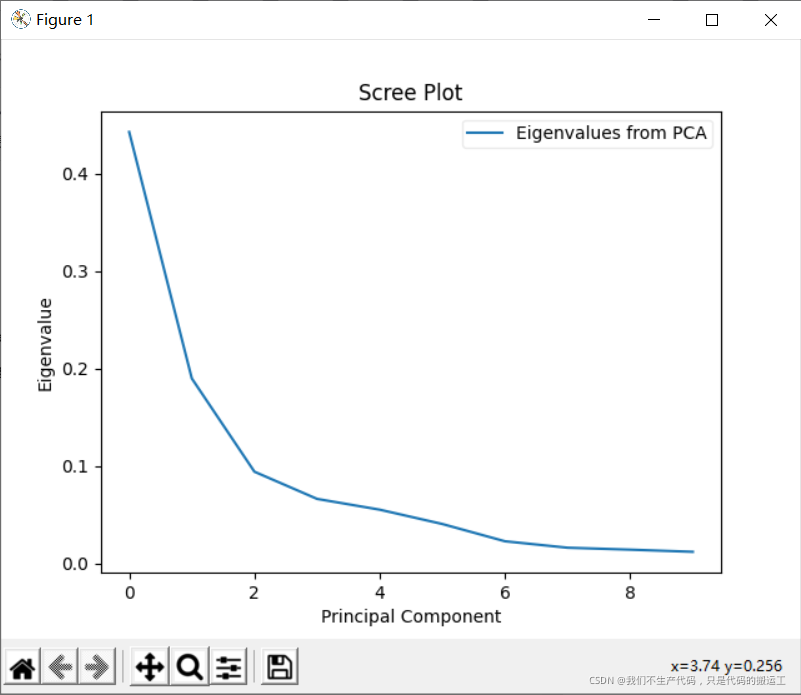
(��).��ͬģ��֮��ıȽ�
1.��������,ѵ�������Լ�����(ʹ���˽�����֤)
data = pd.read_csv('data/data.csv')
print("����Ԥ����:")
# ����һ�������ͱ�ǩ
X = data.iloc[:,2:32] # ����
y = data.iloc[:,1] # ��ǩ
# �����ǩ����ԭʼ�ַ�����ʾ(M��B)ת��Ϊ����
le = LabelEncoder()
y = le.fit_transform(y)
print(y)
# ��������(��0���IJ���������������)��
scaler =StandardScaler()
Xs = scaler.fit_transform(X)
print("������֤:(������֤ѵ����:���Լ� = 7:3)")
# 5.���ֲ��Լ���ѵ����
#stratify��Ϊ�˱���splitǰ��ķֲ�
#��stratify=X���ǰ���X�еı�������
#��stratify=y���ǰ���y�еı�������
X_train, X_test, y_train, y_test = train_test_split(Xs, y, stratify=y,#Xs������ y�DZ�ǩ
test_size=0.3,
random_state=33)
2.���ö���ģ�ͽ���Ԥ��
# �㷨���
models = {}
models['LR'] = LogisticRegression()
models['LDA'] = LinearDiscriminantAnalysis()
models['KNN'] = KNeighborsClassifier()
models['CART'] = DecisionTreeClassifier()
models['NB'] = GaussianNB()
models['SVM'] = SVC()
num_folds = 10
seed = 7
kfold = KFold(n_splits=num_folds, shuffle=True, random_state=seed)
#kf = KFold(n_splits=7, shuffle=True, random_state=0)
# �����㷨
results = []
for name in models:
result = cross_val_score(models[name], X_train, y_train, cv=kfold, scoring='accuracy')
results.append(result)
msg = '%s: %.3f (%.3f)' % (name, result.mean(), result.std())
print(msg)
# ͼ����ʾ
fig = plt.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(models.keys())
plt.show()

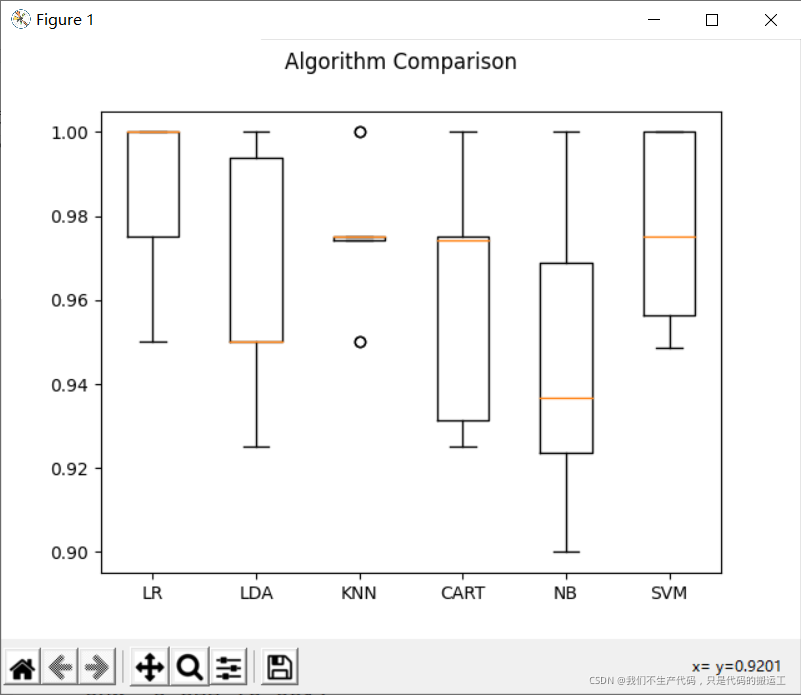
���Է���,CART(�����������㷨)�������ݵ��Ƿ������Ӱ��
LDA(�����б����),NB(��Ҷ˹�����㷨) �㷨 ����Ӱ��
LR(���ع��㷨), KNN(����ڷ����㷨),SVM(֧���������㷨) �ڽ��н�ģ֮ǰ,����Ҫ���к��������ݱ���,��Ϊ�����ģ��ѵ���кܴ��Ӱ��.