题目:Learning Disentangled Representation Implicitly via
Transformer for Occluded Person Re-Identification
作者:Mengxi Jia
一、研究背景
带有遮挡的行人图片会造成图片匹配时的误对齐。
由于遮挡物类型众多且遮挡的位置不固定,会造成行人外观的巨大变化,带来类内匹配错误;与身体部位外观相似的遮挡物会使学到的特征不准确。
目前主流的应对措施是用额外的语义提示或局部特征进行对齐,然而这些对齐方式对噪声敏感且不能很好区分行人躯体和遮挡物。
因此,这篇论文提出了不需要严格对齐和额外监督的DRL-Net(解纠缠表示学习网络),并实现了用遮挡图片的局部特征实现全局推理。
二、研究目标
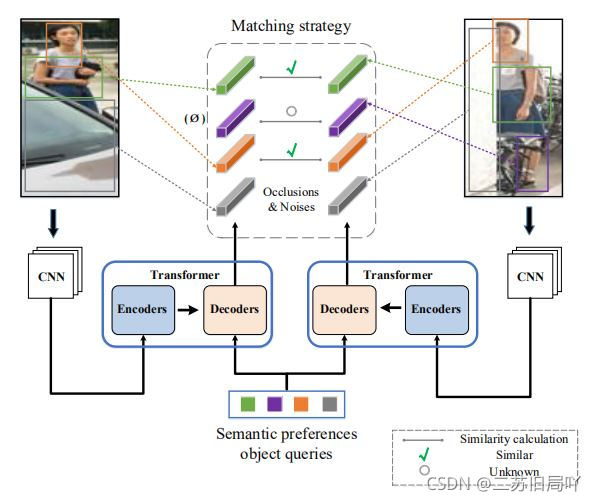
(1)在语义偏好目标序列的指导下,通过对未定义语义成分的特征进行解纠缠,实现图片的相似性度量
(2)设计去相关约束,使目标序列更好地关注不同语义组件
(3)设计对比特征学习(CFL),分离遮挡特征和鉴别性特征,来更好地消除遮挡的影响
三、技术路线
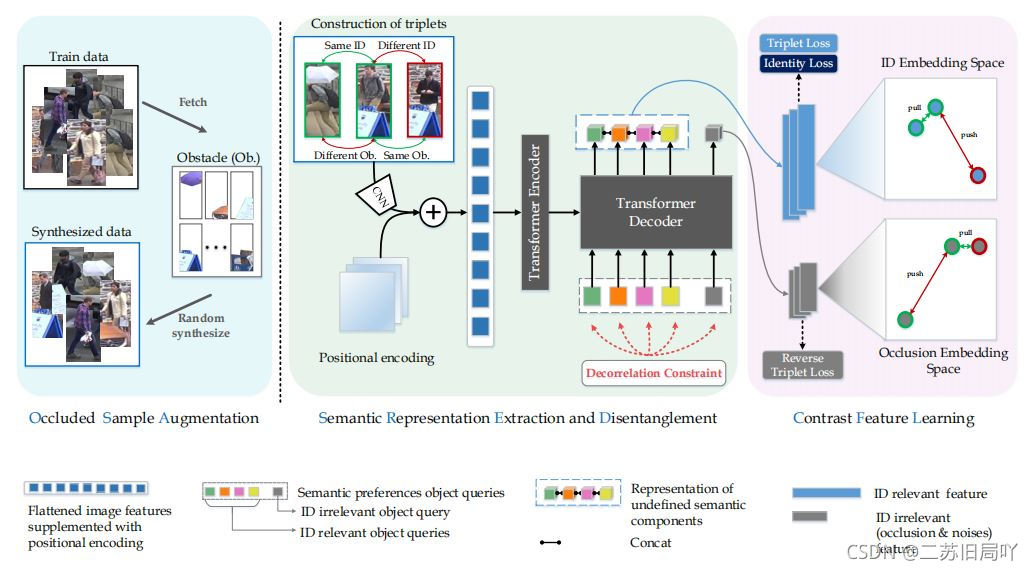
A. Semantic Representation Extraction and Disentanglement
按照语义成分提取特征
(1)CNN特征提取器
(2)encoder:可学习的位置编码
(3)decoder:可学习的输入嵌入(semantic
preferences object queries)



1)identity loss

2)Object Query Decorrelation Constraint

B. Semantic Preferences guided Contrast Feature Learning(语义偏好引导的对比特征学习)
- Occluded Sample Augmentation (OSA):

希望目标序列生成的语义成分只关注身体部位而不受遮挡影响

希望遮挡目标序列只关注遮挡物或噪声

C. Training and Inference


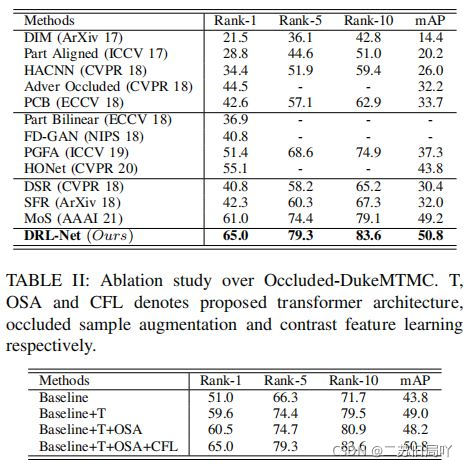
四、实验结果