摘要
??无约束环境下的人脸检测和对齐通常部署在内存有限、计算能力低的边缘设备上。本文提出了一种称为(CenterFace)的单阶段方法,可以实时快速、高精度地同时预测人脸边框和特征点位置。所提出的方法也属于无锚类。这是通过以下方法实现的:(a)通过语义地图学习人脸存在的概率(b)学习边界框、偏移量和可能包含人脸的每个位置的五个特征点。具体地说,该方法可以在单个CPU内核上实时运行,使用NVIDIA 2080TI以200 FPS的速度处理VGA分辨率图像,并且可以同时实现更高的精度(Wider Face Val/Test 简单:0.935/0.932,中等:0.924/0.921,困难:0.875/0.873和FDDB不连续:0.980,连续:0.732)。Center Face Demo可在以下网站获得:https://github.com/Star-Clouds/CenterFace.
1 引言
??人脸检测和对齐是计算机视觉和模式识别的基本问题之一,通常部署在移动和嵌入式设备中。这些设备通常具有有限的内存存储和较低的计算能力。因此,有必要同时预测人脸框和特征点的位置,而且速度和精度都非常好。
??近年来,随着卷积神经网络(CNN)的重大突破,人脸检测取得了显著的进展。以前的人脸检测方法继承了基于锚的通用目标检测框架的范例,可分为两类:两阶段方法(Faster RCNN[15])和一阶段方法(SSD[17])。与两阶段方法相比,一阶段方法具有更高的效率和查全率,但它往往会获得更高的误报率,并损害定位精确。然后,Hu等人[7]对区域建议网络(RPN)[15]采用两阶段方法直接检测人脸,而SSH[8]和S3FD[10]在单个网络中开发了一个尺度不变网络,用于检测不同层的多尺度人脸。
??以前基于锚的方法有一些缺点。一方面,为了提高锚框和真实框之间的重叠,人脸检测器通常需要大量密集锚来实现良好的召回率。例如,对于640×640输入图像,RetinaFace[11]中有超过100k的锚定框。另一方面,锚是一种超参数设计,是从特定数据集统计计算出来的,因此它并不总是适用于其他应用,这违背了一般性
??此外,通过使用VGG16[21]和resnet50/152[22]等大型预训练主干,目前最先进的人脸检测器在基准WIDER FACE[20]上实现了相当高的精度。首先,这些检测器很难在实践中使用,因为网络消耗了太多的时间,而且模型尺寸也太大。其次,如果没有人脸特征点的预测,则不利于人脸识别应用。因此,联合检测和校准以及精度和延迟的更好平衡对于实际应用至关重要。
??受无锚通用目标检测框架[1,3,6,14,15,25,26]的启发,本文提出了一种更简单、更有效的人脸检测和对齐方法CenterFace,该方法不仅轻量级而且功能强大。CenterFace的网络结构如图1所示,可以端到端进行训练。我们使用人脸边界框的中心点来表示人脸,然后人脸框的大小和特征点直接回归到中心位置的图像特征。因此,人脸检测和对齐被转化为标准的关键点估计问题[4,27,28]。热图中的峰值对应于面的中心。每个峰值处的图像特征预测人脸的大小和人脸关键点。对该方法进行了全面评估,并在大量人脸检测基准数据集上显示了最新的检测性能,包括FDDB[24]和WIDER FACE

??总之,这项工作的主要贡献可以概括为四个方面:
-通过引入无锚设计,人脸检测转化为标准的关键点估计问题,与以前的检测器相比,仅使用更大的输出分辨率(输出步长为4)。
-在多任务学习策略的基础上,提出了人脸作为点的设计,以同时预测人脸边框和五个关键点。
-本文提出了一种基于公共层的特征金字塔网络,用于准确快速的人脸检测。
-基于流行基准FDDB和WideFace以及CPU和GPU硬件平台的综合实验结果证明了该方法在速度和精度方面的优越性
2 相关工作
2.1级联CNN方法
??级联卷积神经网络(CNN)[29,30,31]的方法使用级联CNN框架来学习特征,以提高性能和保持效率。然而,基于CNN的级联检测器存在一些问题:1)这些检测器的运行时间与输入图像上的人脸数呈负相关。当人脸数增加时,速度会急剧下降;2) 由于这些方法分别优化每个模块,因此训练过程变得极其复杂。
2.2 锚方法
??受通用目标检测方法[16,17,25,26,35,36,37,38]的启发,人脸检测最近取得了显著的进步[7,8,9,10]。与一般的目标检测不同,人脸比例通常为1:1到1:1.5。最新的方法[9,11]侧重于单阶段设计,即在特征金字塔上密集采样面部位置和比例,显示出良好的前景,与两阶段方法相比,性能和速度更快[18,19]
2.3 无锚方法
??在我们看来,级联CNN方法也是一种无锚方法。然而,该方法使用滑动窗口检测人脸,并依赖于图像金字塔。它具有速度慢、训练过程复杂等缺点。LFFD[12]将RFs视为自然锚,可以覆盖连续的面部尺度,这只是定义锚的另一种方式,但使用两个NVIDIA GTX1080TI,训练时间约为5天。我们的“Center Face”仅通过边界框中心的一个点来表示人脸,然后直接从中心位置的图像特征回归人脸框大小和特征点。因此,人脸检测被转化为一个标准的关键点估计问题。NVIDIA GTX2080TI的训练时间仅为一天。
2.4 多任务方法
??多任务学习使用多个管理标签,通过利用任务之间的相关性来提高每个任务的准确性。联合人脸检测和对齐[27,29]被广泛使用,因为对齐任务与主干并行,为具有人脸点信息的人脸分类任务提供了更好的特征。类似地,Mask RCNN[5]通过添加用于预测对象掩码的分支,显著提高了检测性能。
3 CenterFace
3.1 移动特征金字塔网络
??我们采用Mobilenet v2[32]作为主干,采用特征金字塔网络(FPN)[25]作为后续检测的颈部。通常,FPN使用自上而下的体系结构和横向连接,从单个比例输入构建特征金字塔。CenterFace通过人脸框的中心点表示人脸,然后直接从中心位置的图像特征回归人脸大小和人脸特征点。因此,金字塔中只有一层用于人脸检测和对齐。我们构造了一个具有{P-L},L=3,4,5级的金字塔,其中L表示金字塔级别。Pl具有输入的1/2L分辨率。所有金字塔级别都有C=24个通道。
3.2 人脸作为点
??设
[
x
1
,
y
1
,
x
2
,
y
2
]
[x1,y1,x2,y2]
[x1,y1,x2,y2]为人脸的边界框。面部中心点位于
c
=
[
(
x
1
+
x
2
)
/
2
,
(
y
1
+
y
2
)
/
2
]
c=[(x1+x2)/2,(y1+y2)/2]
c=[(x1+x2)/2,(y1+y2)/2]。设
I
∈
R
W
×
H
×
3
I∈R^{W×H×3}
I∈RW×H×3是宽度W和高度H的输入图像。我们的目标是生成热图
Y
∈
[
0
,
1
]
W
/
R
×
H
/
R
Y∈[0,1]^{W/R×H/R}
Y∈[0,1]W/R×H/R,其中R是输出步幅。我们使用文献[23]中的默认输出步幅R=4。预测Y?x,Y=1对应于面部中心,而Y?x,Y=0是背景。
??人脸分类分支按照Law和Deng[23]进行训练。每一个地面的真相。我们用高斯核表示地面真值来计算等效热图,训练损失是焦距损失的一个变量[26]
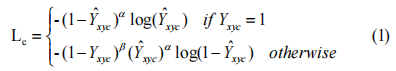
其中α和β是focal loss的超参数,在我们所有的实验中,它们被指定为α=2和β=4。
??为了收集全局信息并减少内存使用,对图像进行卷积下采样,输出的大小通常小于图像。因此,图像中的位置(x,y)被映射到热图中的位置(x/n,y/n),其中n是下采样因子。当我们重新映射从热图到输入图像的位置时,一些像素可能没有对齐,这会极大地影响人脸框的准确性。为了解决此问题,我们预测位置偏移,以便在将中心位置重新映射到输入分辨率之前稍微调整中心位置:
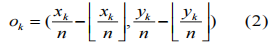
其中ok是偏移量,xk和yk是面中心k的x和y坐标。我们在地面真值中心位置应用L1损失[5]:
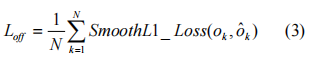
3.3边框和特征点预测
??为了减少计算负担,我们使用了一个单一大小的预测
S
∈
R
W
/
4
?
H
/
4
S∈R^{W/4*H/4}
S∈RW/4?H/4用于面部框和特征点。每个地面真值边界框指定为G=(x1,y1,x2,y2)。我们的目标是学习将网络位置输出(h^,w^)映射到特征映射中的中心位置(x,y)的转换:
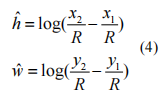
与边框回归不同,五个面部标志点的回归采用基于中心位置的目标归一化方法:
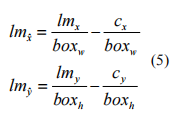
我们还使用平滑L1损失对人脸框和中心位置的地标进行预测
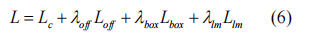
其中λoff,λbox,λlm用于衡量损耗。我们在所有实验中分别使用1,0.1,0.1
3.4 训练细节
??数据集。该方法在WIDER FACE基准训练集上进行训练,包括12880张图像,其中超过150000张有效的人脸在尺度、姿势、表情、遮挡和光照方面。RetinaFace[11]介绍了人脸图像质量的五个级别,并注释了人脸上的五个特征点。
??数据扩充。数据扩充对于提高泛化能力具有重要意义。我们使用随机翻转、随机缩放[33]、颜色抖动和从原始图像中随机裁剪方形面片,并将这些人脸调整为800*800,以生成更大的训练人脸。小于8像素的面将直接丢弃。
??训练参数。我们使用Adam Optimizer对Center Face进行训练,批量大小为8,学习率为5e-4,持续140个epochs,学习率分别在90和120个epochs下降10倍。MobilenetV2的下采样层用ImageNet pretrain初始化,上采样层随机初始化。使用一台NVIDIA GTX2080TI,训练时间约为一天
4 实验
??在本节中,我们首先介绍CenterFace的运行效率,然后在常用的人脸检测基准上对其进行评估。
4.1运行效率
现有的CNN人脸检测器可以通过GPU进行加速,但在大多数实际应用中,尤其是基于CPU的应用中,它们的速度不够快。如下所述,我们的中心面效率足以满足实际要求,其型号尺寸仅为7.2MB。在表1中,与其他检测器相比,通过使用单个NVIDIA GTX2080TI,我们的方法可以在不同分辨率下超过实时运行速度(>100 FPS)。
??由于DSFD、PyramidBox、S3FD和SSH在CPU平台上运行时速度太慢,因此我们仅评估CPU上VGA分辨率图像的建议的CenterFace, FaceBoxes,MTCNN和CasCNN,地图表示FDDB上1000次误报时的真阳性率。如表2所示,我们的中心面可以在CPU上以30 FPS的速度运行,具有最先进的精度。

4.2对基准的评价
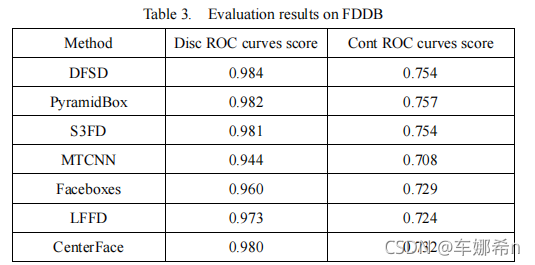
??FDDB数据集。FDDB包含从雅虎新闻网站收集的2845张图像和5171张无约束的脸。我们在FDDB上对我们的人脸检测器与其他最先进的方法进行了对比评估,结果分别如表3和图2所示。我们还添加了DFSD、金字塔盒和S3FD检测器。然而,由于主干更大,锚更密集,这些探测器的速度要慢得多。我们的中心面在不连续和连续ROC曲线上也能获得良好的性能,即当误报数等于1000时,其性能分别为98.0%和72.9%,明显优于LFFD、Facebox和MTCNN

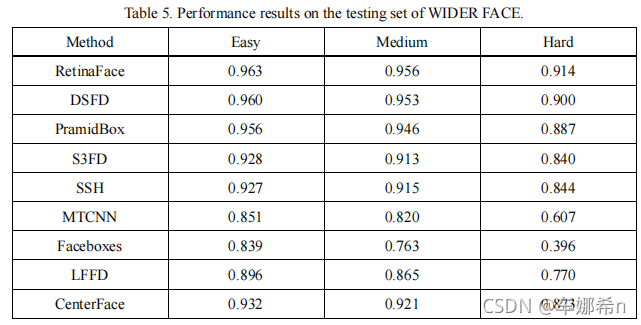
??WIDER FACE数据集。到目前为止,WIDER FACE是最广泛使用的人脸检测基准。通过从61个场景类别中随机抽样,将宽脸数据集分为训练(40%)、验证(10%)和测试(50%)子集。所有比较的方法都在训练集上进行训练。对于宽面测试,我们遵循[11]的标准实践,采用翻转和多尺度策略。框投票[13]使用0.4的IoU阈值应用于预测面框的并集。我们在表4和表5中分别报告了验证和测试集的结果。所提出的方法中心面对于验证集达到0.935(容易)、0.924(中等)和0.875(难),对于测试集达到0.932(容易)、0.921(中等)和0.873(难)。虽然它与最先进的方法有差距,但始终优于SSH(使用VGG16作为主干)、LFFD、Facebox和MTCNN。此外,CenterFace优于S3FD,S3FD使用VGG16作为主干,并在硬部件上使用密集锚固件。

??此外,我们还对WIDER FACE的人脸进行了测试,不仅使用原始图像,而且使用单个推断,我们的中心面在两个验证集的所有子集中都产生了良好的平均精度(AP),即验证集的平均精度为92.2%(容易)、91.1%(中等)和78.2%(困难)。
5 结论
??本文介绍了一种Center Face方法,该方法具有所提出方法的优点,在速度和精度上都有很好的表现,可以同时预测人脸框和特征点位置。我们提出的方法通过将人脸检测和对齐转化为一个标准的关键点估计问题,克服了以前基于锚的方法的缺点。CenterFace通过人脸框的中心点表示人脸,然后直接从中心位置的图像特征回归人脸大小和人脸地标。为了充分分析所提出的方法,进行了全面而广泛的实验。最后的实验结果表明,该方法可以在较小的模型尺寸下实现实时速度和高精度,是大多数人脸检测和对齐应用的理想选择