ХРГц+Ъ§ОнЗжЮі+Ъ§ОнПЩЪгЛЏ
ШчЙћгадЫааСЫБЈДэСЫ,вЊУДЪЧФуздМКаДЕФЪБКђУЛЯрЙиЕФБфСП,вЊУДЪЧЮвЪжДђЕФКЏЪ§ДђДэСЫ,ФуИДжЦЙ§ШЅвВДэСЫ
4.ЙигкВЪЦБЕФЪ§ОнЗжЮі
1.
ЯШЕМШыСНИіПт,дйв§ШыЪ§Он:matplotlibзіГіРДЕФЭМЖМЪЧPNG,зіВЛЕНЖЏЬЌЯьгІЕФЭМЁЃЫљвдЛЙЕУбЇPythonПЩЪгЛЏЩёЦїЁЊЁЊpyechartsЕФГЌЯъЯИЪЙгУжИФЯ!
import pandas as pd #зіЪ§ОнДІРэКЭЗжЮіЁЂЧхЯД
import matplotlib.pyplot as plt #гУРДзіПЩЪгЛЏЕФЙЄОп ЁЊЁЊ>ФмАбЪ§ОнБфГЩЭМБэ
import numpy as np #зіЪ§ОнДІРэЕФ,pandasРяБпОЭгаnumpy
#в§ШыЪ§Он df=pd.read_csv('ЮФМўУћДјЭиеЙУћ')
#ШчЙћЯыднЪБПДвЛЯТ,ПЩвд:print(df)
#в§ШыЪ§Он headers=NoneБэЪОЕквЛааЪ§ОнВЛЪЧБэЭЗ,ЖјЪЧБфГЩСаКХСЫ index_colОЭЪЧФУФФвЛСазїЮЊааЕФЫїв§
#dfДцзХЖСШЁЕФЖЋЮї
df=pd.read_csv('data.csv',headers=None,index_col=0)
# .locЪЧФУЪ§Он :ЕФвтЫМЪЧЫљгаааorСа,етРяЪЧДгЕквЛСаЕНЕкСљСаЕФЫљгаЪ§Он
red_ball=df.loc[:,1:6]
print(red_ball)
#зіЪ§ОнЭГМЦ,ЭГМЦУПИіКХТыГіЯжЕФДЮЪ§
```python
red_ball_count= pd.value_counts(red_ball.values.flatten()) #еыЖдгаЖрааЖрСаЕФЪ§Он!!!flatten()ЪЧАбЖўЮЌБфГЩвЛЮЌЕФЪ§Он
print(red_ball_count) #етЪБКђОЭЛсДђгЁГівЛааааЕФЪ§Он,УПааОЭвЛИіЪ§ОнЕФаХЯЂ:етИіЪ§ОнЪЧЪВУД,ГіЯжСЫМИДЮЁЃЧАБпЕФНаindex,КѓБпЕФНаvalues !!!
# ФЧжЛгавЛСаЕФЦНУцЪ§ОнЕФНсЙЙеІАь?
blue_ball_count=pd.value_counts(blue_ball) #жБНгДЋНјШЅОЭааСЫ
#Ъ§ОнПЩЪгЛЏ
fig,ax=plt.subplots(2,1) #вЛДЮДДНЈКмЖрИіЭМБэ,етРяБэЪОНЋСНИіЭМБэАкГЩСНаавЛСаЕФаЮЪН
#ЮвУЧвЊЕФЭМБэдкaxРяУц
#ЛБ§ЭМ вдred_ball_countЕФЫїв§ИјБ§ЭМУПвЛПщБъЩЯБэЪОЕФЪЧФФИіЪ§ЕФеМБШ radiusЪЧАыОЖ wedgepropsЪЧаЁЩШаЮЕФГЄЖШ,ЫљвдЩшжУКѓгаПЩФмЛсБфГЩвЛИідВЛЗХЖ
ax[0].pie(red_ball_count,labels=red_ball_count.index,radius=1,wedgeprops={'width':0.3})
ax[1].pie(blue_ball_count,labels=blue_ball_count.index,radius=0.5,wedgeprops={'width':0.2})
#ЕЋЪЧЩЯБпЕФбљзгЪЧСНИіЭМБэЗжПЊЕФ,ШчЙћЯыШУСНИідВЛЗЬздквЛЦ№,жЛашвЊШУax[]ЕФЯТБъвЛбљОЭПЩвдЛдкЭЌвЛИіЭМБэРяСЫ
ax[0].pie(red_ball_count,labels=red_ball_count.index,radius=1,wedgeprops={'width':0.3})
ax[0].pie(blue_ball_count,labels=blue_ball_count.index,radius=0.5,wedgeprops={'width':0.2})
plt.show() #ЭМБэеЙЪО
2.
ЩЯБпЕФДњТыЕНзюКѓУПДЮДђгЁЕФКѓЛсгавЛИіПеАзЕФЖўЮЌзјБъЯЕ,ЫљвддлУЧвЊШЅЕє,дѕУДШЅЕєФи??ДгЩЯЮФЪ§ОнПЩЪгЛЏПЊЪМ,ВЛвЊfigЁЂaxСЫ,жБНг:
plt.pie(red_ball_count,labels=red_ball_count.index,radius=1,wedgeprops={'width':0.3})
plt.pie(blue_ball_count,labels=blue_ball_count.index,radius=0.5,wedgeprops={'width':0.2})
plt.show() #ЭМБэеЙЪО
3.
ШчЙћЯыХЊИќЛЈЕФбеЩЋ,ФЧУДПЩвдевРДФЧаЉбеЩЋЕФзжЗћБэДяЪН,ШЛКѓвЛИіcolorСаБэ(ДЫСаБэдЊЫиЖМЪЧзжЗћ,ВЛЭЌдЊЫижЎМфгУЖККХМфИє) like this:
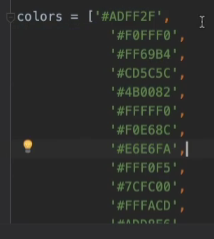
ШЛКѓдкЩЯЮФНєНгзХЕФДњТыПђРяНгзХИФ:
plt.pie(red_ball_count,colors=np.random.choice(colors,len(red_ball_count)),labels=red_ball_count.index,radius=1,wedgeprops={'width':0.3})
#гаЖрЩйИібеЩЋЮвОЭДгcolorsЕФСаБэРяЫцЛњбЁЖрЩйИібеЩЋ
plt.pie(blue_ball_count,colors=np.random.choice(colors,len(red_ball_count)),labels=blue_ball_count.index,radius=0.5,wedgeprops={'width':0.2})
plt.show() #ЭМБэеЙЪО
8.ЙигкЕчгАЦБЗПЕФЪ§ОнЗжЮі
1.
гУ requests ЁЂBeautifulSoupПт
like this:

import requests
from bs4 import BeautifulSoup
# ЭЈЙ§requestsЧыЧѓЕНЕчгАЦБЗПЕФЪзвГ textДцЕФЪЧЭјжЗ
text=requests.get('https://ys.endata.cn/DataMarket/Index').text
#ЪЙгУBeautifulSoupНјааНтЮі
main_page=BeautifulSoup(text,'html.parser') #гУhtmlЕФЙцдђШЅНтЮіtext
гааЉЭјвГЕФЭјжЗИФЖЏЯТетИіФъЗнвВЪЧФмПьЫйфЏРРЕБФъЕФаХЯЂЕФ

2.
НјвЛВНФУЕНЭјвГЪ§ОнЧА,РДЕНФПБъЭјвГ,ЪѓБъгвМќКѓ,ЕуЛї МьВщ
ШЛКѓевtableБъЧЉ,зЂвтжЛгаетбљЕФIDEВХФмвЊ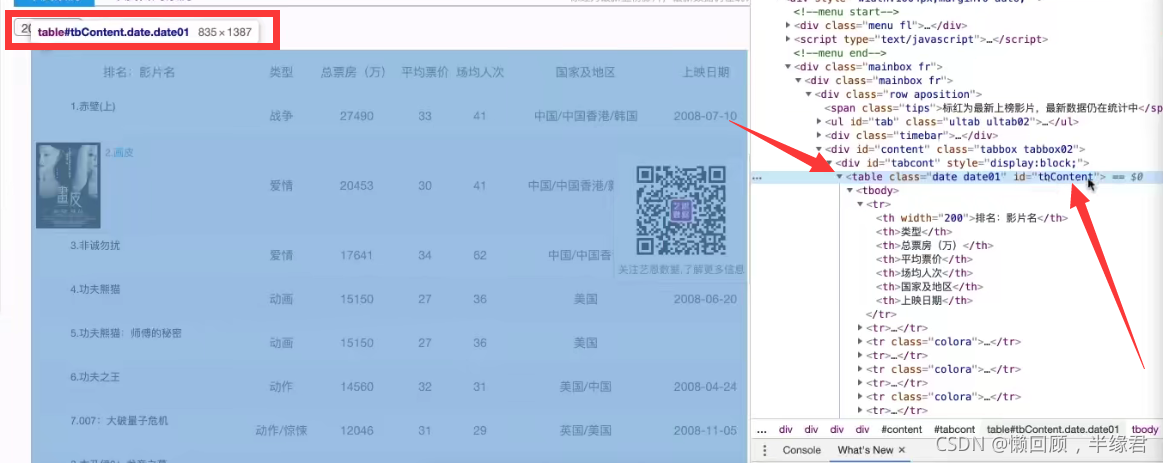
РД,ЩЯДњТы:(НгзХЩЯЮФ,ЖМдквЛИіДњТыДАПк)
# евЕНtable ,ЭЈЙ§ет id жЕРДЗРжЙетИівГУцЦфЫћЕФtableРДИЩШХЮвУЧ
table=main_page.find('table',attrs={'id':'tbContent'})
# findевЕФЪЧвЛИіБъЧЉ,жЛЗЕЛиЕквЛИіевЕНЕФ find_allеввЛЖбБъЧЉ. trsБЃДцУПвЛааБъЧЉ
#ХЊИіЮФМўАбЬсШЁЕНЕФЪ§ОнБЃДцЦ№РД
f=open('ЕчгАЦБЗП.csv',mode='a') #aБэЪО appendзЗМгаДЁЃвђЮЊвЊАбжЎЧАХРЕФЪ§ОнБЃСє
# find_all() ЗЕЛиlist
trs= table.find_all('tr') #вЛЖбtr,ЯТУцАбtrФУГіРД
for tr in trs: #ФУЕНУПвЛИіtr
lst=tr.find_all('td') # евЕНУПвЛИіtd
#ЕЋЪЧЕквЛааЖМЪЧth ,вВОЭЪЧУПСаЕФУћзж(ЪВУДЕчгАУћЁЂВЅЗХСПЩЖЕФ),ЫљвддлВЛвЊ
if len(lst) != 0:
for td in lst: #ФУЕНУПвЛИіtd,ЗЂЯжУПвЛИіtdЖМЪЧПЩвдПДГЩЮФБОЕФ
# print(td.text) # ФУЕНtdБъЧЉжаЕФЮФБОаХЯЂ,ОЭЪЧЮвУЧвЊЕФЕчгАаХЯЂ
f.write(td.text.strip()) #ХРЭъвЛСаЕФвЛИідЊЫиКѓ
f.write(',') #гУЖККХИєПЊ
f.write("\n") # етвЛааЕФЪ§ОнаДЭъКѓ,ЛЛаа
#ЕЋЪЧ,гааЉФкШнБэУцЩЯПДЪЧЮФБО,ЕЋЪЧЪЧГЄСЌНг,ККзжКѓгаПДВЛМћЕФЛЛааЗћ(ШчЯТЭМ)
#ЫљвдгУ.strip() ФЌШЯШЅЕєзѓгвСНЖЫЕФПеАз(ПеИёЁЂЛЛааЗћЁЂжЦБэЗћ)
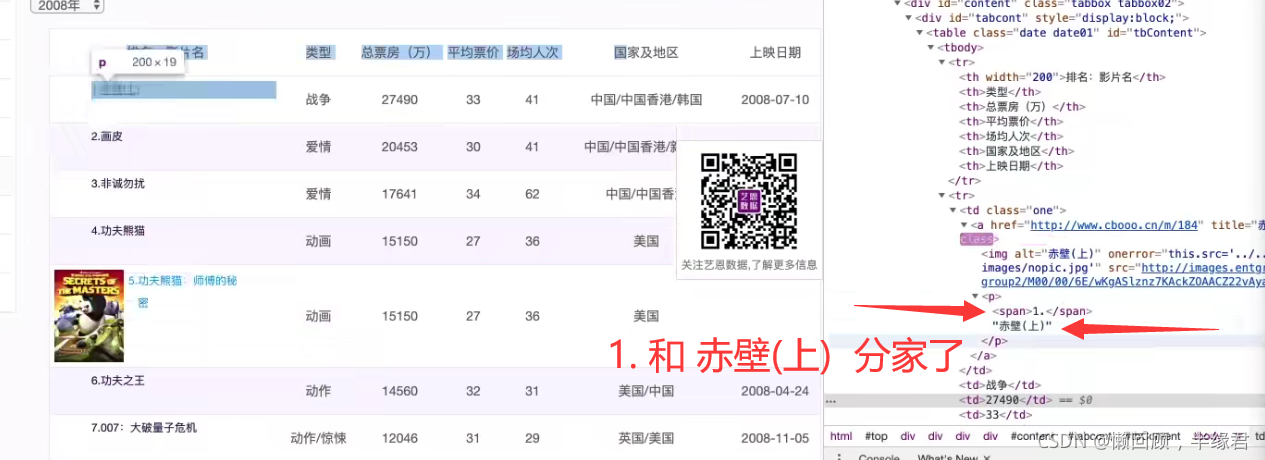
3.ХРШЁзмЕФДњТы(зіГЩКЏЪ§)
ЩЯБпЖМЪЧХЊЕФвЛФъЕФ,вВОЭЪЧ2008Фъ,НгЯТРДвЛДЮадвЊХЊКмЖрФъЕФ
ЖЈвхГЩвЛИіКЏЪ§ОЭааСЫ
import requests
from bs4 import BeautifulSoup
def fowm(year):
text=requests.get('https://www.cbooo.cn/year?year=%s' % year).text
main_page=BeautifulSoup(text,'html.parser') #гУhtmlЕФЙцдђШЅНтЮіtext
table=main_page.find('table',attrs={'id':'tbContent'})
f=open('ЕчгАЦБЗП.csv',mode='a') #aБэЪО appendзЗМгаДЁЃвђЮЊвЊАбжЎЧАХРЕФЪ§ОнБЃСє
trs= table.find_all('tr') #вЛЖбtr,ЯТУцАбtrФУГіРД
for tr in trs: #ФУЕНУПвЛИіtr
lst=tr.find_all('td') # евЕНУПвЛИіtd
#ЕЋЪЧЕквЛааЖМЪЧth ,вВОЭЪЧУПСаЕФУћзж(ЪВУДЕчгАУћЁЂВЅЗХСПЩЖЕФ),ЫљвддлВЛвЊ
if len(lst) != 0:
for td in lst: #ФУЕНУПвЛИіtd,ЗЂЯжУПвЛИіtdЖМЪЧПЩвдПДГЩЮФБОЕФ
# print(td.text) # ФУЕНtdБъЧЉжаЕФЮФБОаХЯЂ,ОЭЪЧЮвУЧвЊЕФЕчгАаХЯЂ
f.write(td.text.strip()) #ХРЭъвЛСаЕФвЛИідЊЫиКѓ
f.write(',') #гУЖККХИєПЊ
f.write("\n") # етвЛааЕФЪ§ОнаДЭъКѓ,ЛЛаа
for year in range(2008,2020):
dowm(year)
4.Ъ§ОнЗжЮі(ЖЏЬЌБ§ЭМ)
дЄВтзуЧђБШШќЕФНсЙћЕУгУЯпадЛиЙщ