咋说呢,这本来是我们统计老师给的一个小期中作业,方法并不详尽,我找了几个简单的,看个乐就行。泰坦尼克号数据集的使用是因为之前做过它的一系列分析,所以图个方便。其他数据文件由于缺失值比较少甚至没有缺失值,我就人为的制造缺失值,建议用代码实现这一过程。
目录
1、删除元组
(1)删除存在缺失值的个案
举例:通过观察泰坦尼克数据集可以发现,数据的年龄Age这一变量存在部分缺失,可以尝试删除变量Age缺失的纪录
图为泰坦尼克数据集

import pandas as pd
import numpy as np
#读入数据
data=pd.read_csv('C:/Users/24580/Desktop/数据挖掘/train.csv')
data.head(30)
data1_1=data.dropna(subset=['Age'])
data1_1.head(20)

(2)删除含特殊值的特征
举例:通过观察泰坦尼克数据集可以发现,数据的Cabin这一变量大部分数据都未知,可以尝试将Cabin这一特征变量给删除
#(基于1.1的数据)
data1_2=data.drop(columns=['Cabin'])
data1_2.head(20)
2、不处理
不处理,就直接进行下一步,贼佛系的做法,但总有一定依据
3、缺失值插补
有多种方式补齐数据,以下只简单罗列了5种方法
(1)人工补齐数据,适用于规模小,缺失少的数据
举例:在成绩表student中,由于小张的语文试卷不慎丢失,老师按照他上课的表现进行打分
import pandas as pd
import numpy as np
#读入数据
data=pd.read_excel('C:/Users/24580/Desktop/社会网络/student.xlsx')
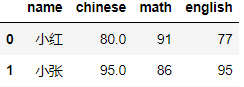
data=data.fillna(95)
data
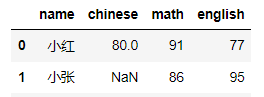 ??
??
(2)用平均数补齐数据
举例:通过观察泰坦尼克数据集可以发现,数据的Age这一变量存在部分缺失,用平均数来插补缺失的Age值
#(基于1.1的数据)
#填充age(平均数)
data['Age']=data['Age'].fillna(data['Age'].median())
data3_2=data
data3_2.head(10)

(3)用众数补齐数据
举例:通过观察泰坦尼克数据集可以发现,数据的Embarked这一变量存在部分缺失,用众数来插补缺失的Embarked值
#(基于1.1的数据)
#填充embarked
cishu=data['Embarked'].value_counts()#计数
index_max=cishu.idxmax()
print(index_max)
data['Embarked']=data['Embarked'].fillna(index_max)
data3_3=data
data3_3.head(10)
(4)回归建模填充数据
举例:在Salary_Data.csv数据文件中包含两个变量,一个是工作年龄YearsExperience,一个是薪资水平Salary,其中Salary有部分数据缺失,鉴于YearsExperience与Salary有强烈的线性相关关系,故拟采用线性回归的方法进行数据填充
import pandas as pd
import numpy as np
import seaborn as sns
import statsmodels.api as sm
import matplotlib.pyplot as plt
#读入数据
data=pd.read_csv('C:/Users/24580/Desktop/社会网络/Salary_Data.csv')
data.head(10)
print(data.isna().sum())
#画散点图
sns.lmplot(x='YearsExperience',y='Salary',data=data,ci=None)
plt.show()
#有缺失的记录,建立需预测的子集
data_pred=data[np.isnan(data['Salary'])]
X_pred=pd.DataFrame(data_pred)
y_pred=data_pred['Salary']
#无缺失值的记录,即训练子集
data_train=data.dropna(subset=['Salary'],axis=0)
#建模
fit=sm.formula.ols('Salary~YearsExperience',data=data_train).fit()
print(fit.params)
#预测
y_pred=fit.predict(X_pred)
print(y_pred)
data_pred['Salary']=y_pred
print(data_pred)
#数据合并
data=data_train.append(data_pred)
data.head(10)
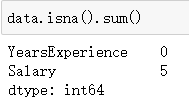 ? 共5个缺失值
? 共5个缺失值
 ??散点图表示两者存在明显线性关系
??散点图表示两者存在明显线性关系
 ?回归方程系数
?回归方程系数
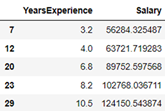 ??为预测的缺失部分的估计值,将数据合并即可
??为预测的缺失部分的估计值,将数据合并即可
(5)K最近邻算法,最近k个样本的均值进行数据填补
举例:CCPP数据集中,前四个变量是自变量,最后一列为连续的因变量PE,表示高炉的发电量,其中PE列存在数据缺失,拟通过KNN模型进行预测填补
其中最佳的临近个数设置为7,是通过10重交叉验证所选取的最佳K值
(本代码段未包含交叉验证的代码)
import pandas as pd
import numpy as np
from sklearn import neighbors
from sklearn.preprocessing import minmax_scale
#读入数据
data=pd.read_excel('C:/Users/24580/Desktop/社会网络/CCPP.xlsx')
data.head(10)
predictors=data.columns[:-1]#自变量名称
X=minmax_scale(data[predictors])#标准化
print(data.isna().sum()) #缺失值个数
#有缺失的记录,建立需预测的子集
data_pred=data[np.isnan(data['PE'])]
x_test=pd.DataFrame(data_pred[predictors])
y_test=data_pred['PE']
#无缺失值的记录,即训练子集
data_train=data.dropna(subset=['PE'],axis=0)
y_train=data_train['PE']
x_train=data_train[predictors]
#建模
knn=neighbors.KNeighborsRegressor(n_neighbors=7,weights='distance')
knn.fit(x_train,y_train)
#预测
pred=knn.predict(x_test)
print(pred)
data_pred['PE']=pred
print(data_pred)
#数据合并
data=data_train.append(data_pred)
data.head(10)
原数据
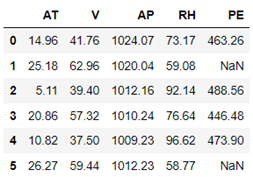 ??
??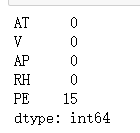 ?共15个缺失
?共15个缺失
预测的15个缺失值,将数据合并即可

?总结一下:
?其他方法:
1、针对时间序列可以通过建模进行预测,然后填补数据
2、多重插补
3、热卡填充……
还有很多方法可以使用,按我的拙见是:只要能进行预测的模型,按理都可以预测缺失值,只是模型的准确率会有所不同
方法总结:
大致梳理一下回归和KNN进行预测的步骤,其他有的模型也可参照这样:
1、观察数据,选择所需模型或方法
2、将有缺失的数据记录从原数据集中提取出来,形成测试集test
(如果需要将自变量、因变量数据拆分,则拆分为x_test,y_test)
剩余部分形成训练集train
(同理,训练集可能也需要拆分)
3、对训练集train进行建模
4、对测试集test进行模型的预测,得到估计值
5、将估计值与原数据合并
(总感觉自己说的废话,hhh,看看就行)