ICLR2022������openreview�����
https://openreview.net/pdf?id=TVHS5Y4dNvM
Opensource: https://github.com/tmp-iclr/convmixer.
ժҪ
����CNN������һֱ���Ӿ�����������ܹ�,�������ʵ�����,����Transformer��ģ��,������ViT,��ijЩ�����¿��ܳ��������ܡ�
Ȼ��,����Transformer��Self-attention���η�����ʱ��,ViT��Ҫʹ��patch��ͼ���һС��������ϳɵ�����������,�Ա�Ӧ���ڽϴ��ͼ����������һ������:ViTs��������������ǿ���Transformer�ܹ�,��������ʹ��patch��Ϊ�����ʾ?
�ڱ�����,����Ϊ�����ṩ��һЩ֤��:�������,���������ConvMixer,����һ�������ģ��,������MLP-Mixer��˼��,��ֱ�Ӷ���Ϊ�����patch���в���,����ռ��ͨ����ά��,�������������б�����ͬ�Ĵ�С�ͷֱ��ʡ�Ȼ��,ConvMixer��ʹ�ñ�������ʵ�ֻ�ϲ��衣�������ܼ�,�����Ƿ���,�������ھ�����Ӿ�ģ��(��ResNet)��,ConvMixer�����ƵIJ����������ݼ���Сʱ����ViT��MLP-Mixer����һЩ���塣

1 ���
���,����Transformerģ�͵ļܹ�,����ViT���������������ͨ�����ھ���CNN�ܹ�,�����Ƕ����������ݼ���һ���۵���,����NLP��һ��,Transformer��ΪCV����������ܹ�ֻ��ʱ�����⡣Ȼ��,Ϊ�˽�TransformerӦ����ͼ��,����ı��ʾ��ʽ:Transformer��������η��ĸ��ӶȲ��������ؼ����������ʹ��,һ�����Է��������Ƚ�ͼ��ָ�Ϊ�����patches��,embedding����,Ȼ��Transformer encoderֱ��Ӧ������Щpatch token�ļ��ϡ�
һ�ֹ۵���Ϊ,�����ݼ�Խ��Խ��,CNN�ܹ����ܻ�����ƿ��,��Transformer�ı�ʾ�������ܼ�����ǿ
���������,����̽�ֵ�������,ViT��ǿ�����Ƿ������������ֻ���patches�ı�ʾ,����������transformer�ܹ����������ǿ�����һ�ַdz��ľ����ṹ,���dz�֮Ϊ��ConvMixer��,��Ϊ������������MLP-Mixer����(Tolstikhin����,2021��)������ϵ�ṹ���������Vision Transformer(��MLP Mixer)����:��ֱ����patches�ϲ���,�����в��б�����ͬ�ķֱ��ʺʹ�С�ı�ʾ,���������в������²���,���ҽ���ͨ��(channel-wise)Mixing���롰�ռ�(spatial)Mixing������Ϣ���롣����Vision Transformer��MLP Mixer��ͬ,���ǵ���ϵ�ṹ��ͨ�����������������Щ������

�������dz���(����6�г��ܵ�PyTorch����,����ͼ),���ȴ���ڡ�����������Ӿ�ģ��,�����Ʋ�������ResNet��һЩ��Ӧ��ViT��MLP-Mix���塣�����,������ij�̶ֳ���,patches���������ǡ�Խ�����ܵ���ؼ�����������������ṩ��һ��ǿ��ġ�Conv������patches����baselines,���������������ϵ�ṹ���бȽϡ�
2. ConvMixer

���ǵ�ģ�ͳ�ΪConvMixer,��һ��patches��embedding���һ����ȫ��������ظ��ѵ���ɡ����DZ�����patchesǶ��Ŀռ�ṹ,��ͼ2��ʾ������patch size = p =p =p��embedding dims = h =h =h��Ƕ�����ʵ��Ϊ�� c i n c_in ci?n������ͨ���� h h h�����ͨ�����ں�kernel size = p =p =p�Ͳ���stride = p =p =p�ľ���:
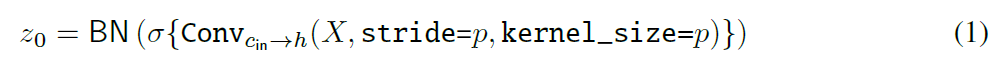
ConvMixer�鱾������Ⱦ���(���������,����������ͨ����h)�͵����(���ں˴�С1��1)��ɡ�������Ⱦ���,ConvMixer�ڷdz����kernel size�¹�������á�ÿ����������һ�������������BatchNorm:
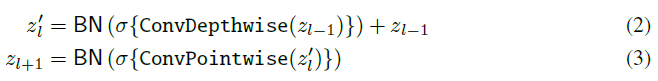
�������
ConvMixer��ʵ����ȡ�����ĸ�����:(1)�����ȡ�����˵����ά�� h h h(��embedding��ά��),(2)��� d d d��ConvMixer����ظ�����,(3)����ģ���ڲ��ֱ��ʵ�patch size p p p,(4)�������kernel size k k k�����ǽ�ԭʼ�����С n n n����patch size p p p��Ϊ�ڲ��ֱ���;������ע��,convMixer֧�ֿɱ��С�����롣
����
���ǵļܹ�����Mixer���������ر��,����ѡ������Ⱦ�������Ͽռ�λ��(spatial locations),ѡ���˵���������ͨ��λ��(channel locations)����ǰ������һ���ؼ�˼����MLP��Self-Attention���Ի��ңԶ�Ŀռ�λ��,Ҳ����˵,���ǿ����������ĸ���Ұ�����,����ʹ�þ��зdz����kernel size�ľ��������ңԶ�Ŀռ�λ����
��Ȼ����ע���MLP�����ϸ����,��������Ľ���������ݸ�֪,�������dz��ʺ��Ӿ�����,�����и�Ч�ʵ����ݼ��㡣ͨ��ʹ������һ�ֱ�����,���ǻ����Կ�������patches�ı�ʾ���������ĵ�����,�����������Ĵ�ͳ�����������²�������γ��˶Աȡ�
3. ��ع���
����ͬ�Խṹ
ViT�����ˡ�����ͬ�ԡ��ܹ����·�ʽ,�������������о�����ͬ��С����״�ļܹ�,��һ��ʹ����ƬǶ�롣��Щģ�Ϳ������������ظ���ѹ����������(Vaswani����,2017��),��ͬ�IJ���ȡ��������ע���MLP����������,MLP��Ƶ��(Tolstikhin����,2021��)�ÿ粻ͬά��Ӧ�õ�MLP(���ռ��ͨ��λ�û�Ƶ��)ȡ��������;ResMLP(Touvron����,2021a)����һ�����һ��������Ч���塣CycleMLP(Chen et al.,2021)��gMLP(Liu et al.,2021)��vision permutator(Hou et al.,2021)�ø����²����滻һ���������顣��Щ���൱��ɫ,��ͨ�������ڲ�������ӱѡ��Ȼ��,�������Ƕ�ConvMixers�ĵ���������������,��Щ�������ܻὫ�²�����Ч����ʹ����ƬǶ���Լ��ɴ˲����ĸ���ͬ�Լܹ���Ч����Ϊһ̸��
��ViT֮ǰ��һ���о������˸���ͬ��(����⡱)�ƶ�����,��������һ������ʵ����patch embedding�����ǵļܹ�ֻ�Ǽ��ظ���һ������ͬ�Ե�MobileNet v3�顣����ȷ���������ǵľ�����ƥ��IJ�����С�;���֮���Ȩ��,��ѵ�������Ƶ�����ģ�͡�Ȼ��,���ǵ�block�����ǵ�blockҪ���ӵöࡣ
Patches Aren��t All You Need
�м�ƪ����ͨ���ò�ͬ�ĸ�ϸ���滻����ƬǶ����������Ӿ�ת����������:Ф����(2021��)��Ԭ����(2021a)ʹ�ñ�������ϸ��,��Ԭ����(2021b)������ϸ�������ƬǶ���Ȼ��,�⽫ʹ����ƬǶ���e�Bect�����Ӿ��������ƵĹ���ƫ��(��ֲ���)��e�Bect��Ϊһ̸��������ͼ���ص���ڲ�����ʹ���ϡ�
CNN meets VIT
����ʵ�鶼��Ϊ�˽�����������������뵽VIT��,��֮��Ȼ������ע�����ģ�����,���ҿ��Գ�ʼ��������Ϊ���ƾ���;��������ֻ����Transformer���Ӿ�������,������²���,�Ը���ͳ�Ľ������ξ������硣�෴,��ע����������ע��IJ������Բ����ȡ��ResNet���ģ���еľ�������Ȼ������Щ���Զ��������������ķ�ʽȡ���˳ɹ�,���������������������,�������Ŀ����ͨ���Խ��ٱ������IJ�����չʾ�����VIT�����еļܹ���Ч����
4. ����
���ǽ�����ConvMixers,����һ��dz���ģ��,����ʹ�ñ��������������ƬǶ��Ŀռ��ͨ��λ�á���Ȼ���ǵ�ģ�ͺ�ʵ�鶼����Ϊ������ȵ���߾��Ȼ��ٶȶ���Ƶ�,��ConvMixer����������Vision Transformer��MLP�����,������ResNet��DeiTs��ResMLP���о�������
�����ṩ��֤�ݱ���,Խ��Խ�ձ�ġ�����ͬ�ԡ���ϵ�ṹ�ͼ�patch embedding�ɱ�������һ��ǿ������ѧϰģ�塣patch embedding����ͬʱ���������²���,�Ӷ����������ڲ��ֱ���,�Ӷ������Ӿ�����Ұ��С,�Ӷ��������Զ����ռ���Ϣ�����ǵı�����Ȼ��Щ����,��ָ����ע���������Ǵ����Դ�����������Ӿ���Ψһ����:��ǻ�����,��ʹ��patch embedding,Ҳ��һ��ǿ�����Ҫ��"����"��
��Ȼ���ǵ�ģ�Ͳ������Ƚ���,�����Ƿ������patch-mixing��������ŷ�������ϣ��ConvMixer������Ϊδ������patch����ϵ�ṹ��baselines��
Future work
�����ֹ۵���Ϊ,��������ʱ���ѵ������������ͳ���������,���и���patch �ĸ����εĻ�Ƶ�������ھ��ȡ�������������֮������������ԡ����ں���Ⱦ����ĵͼ��Ż�����������������������Ƶ�,�����ǵ���ϵ�ṹ����һЩС����ǿ,������ƿ������߱������ķ�����,�����ü��Ի�ȡ���ܡ�