词表征
・词表征就是如何用向量的方式来表示一个词的特征,让计算机能够对词进行处理,常用的两种词表征的方法:
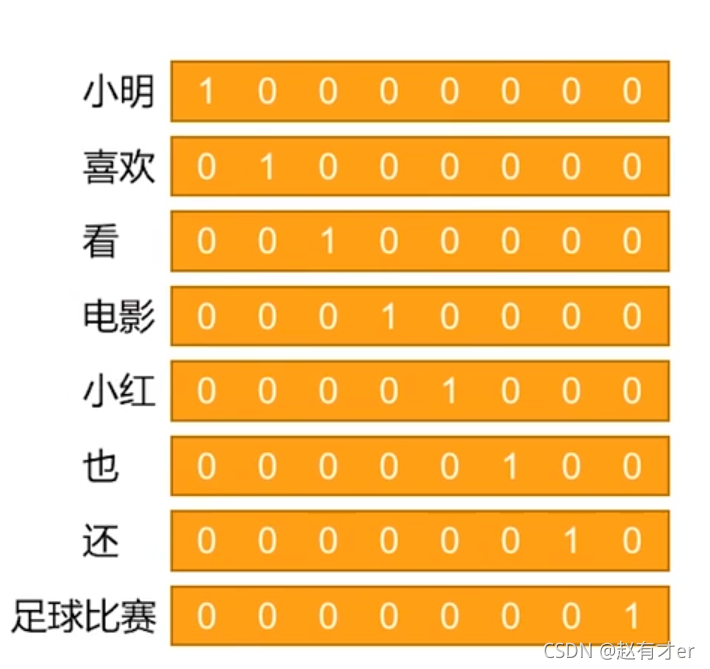
・词袋模型:一个词也可以理解为是一篇最简单的文档,所以它可以用词袋来表示他的特征,这个时候的词袋就是一个独热编码。
独热编码举例:
?
・词向量模型:
词向量:又叫词嵌入,这种方法可以解决词袋模型的稀核心思想是:每一个词映射到一个多维空间中,成为空间中的一个向量,一般这个多维空间的维数不会太高,在几百个的量级,这几百维的特征向量是稠密的,向量中的每一个成员都是非零的。
由于词向量由几百个维度构成,所以也被称为分布式表征。词向量模型是通过对原始文本建模训练学习得到的。
由于词向量把每一个词映射到了一个高维空间中,并用向量表示,响亮的生成是基于词与词之间的相关性得来,可以理解为相关的词在空间中的位置比较靠近,所以词向量有一个非常有趣的特征,那就是类比。
・中心词:就是每一个待分析的词
・邻居词:在文档语料中,出现在中心词,周围某个小窗口内的关联词
・窗口大小c:就是指寻找邻居词的时候需要观察中心词的前后c个词
举例说明:“我家/猫/是/我/养/的/第一/只/宠物”这句话中,如果把“猫”当成当前正在分析的中心词,如果窗口大小c=3,那么,“猫”的邻居词是:我家,是,我,养。
词向量模型的核心原理就是用邻居词的概率分布来作为中心词的向量表示。
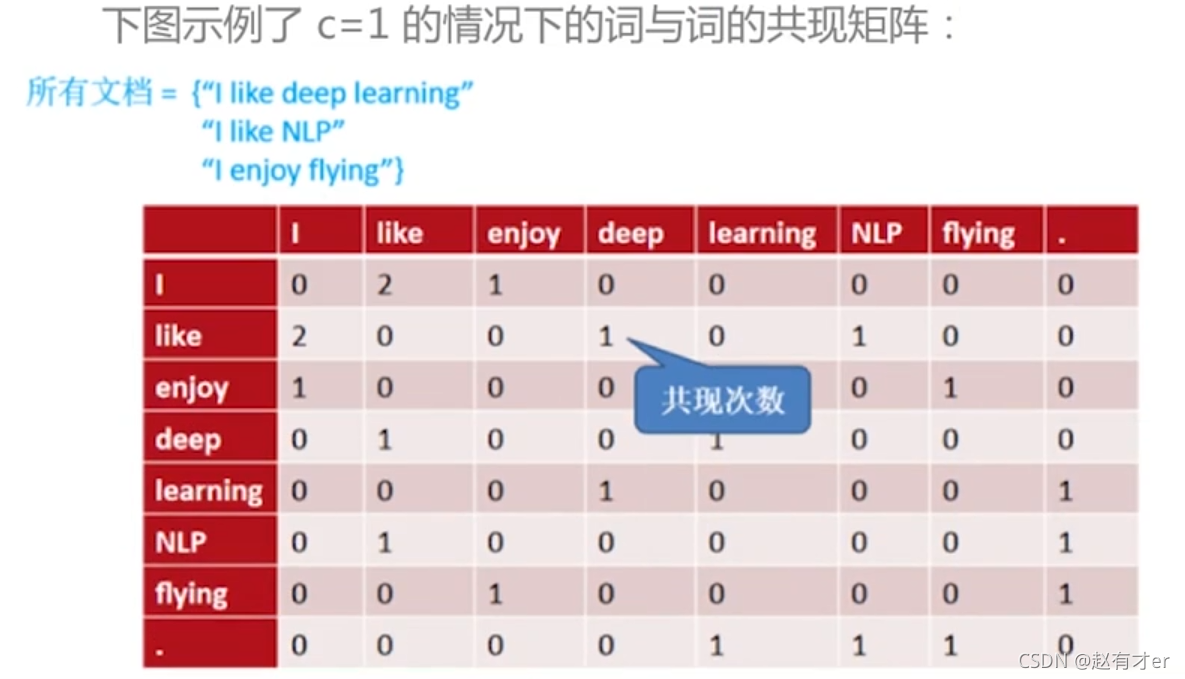
1.基于邻居词共现矩阵分解法
?2.神经网络训练:通过构建两种类型的预测模型,然后使用网络的隐藏层输出作为词向量表征,这两种预测模型是
CBOW:利用中心词和邻居词预测中心词
Skip-gram:利用中心词来预测邻居词
不管是哪种类型的神经网络,它的本质都是希望发现中心词和邻居词之间的相关关系,词向量就是隐藏在这个相关关系中的隐特征。
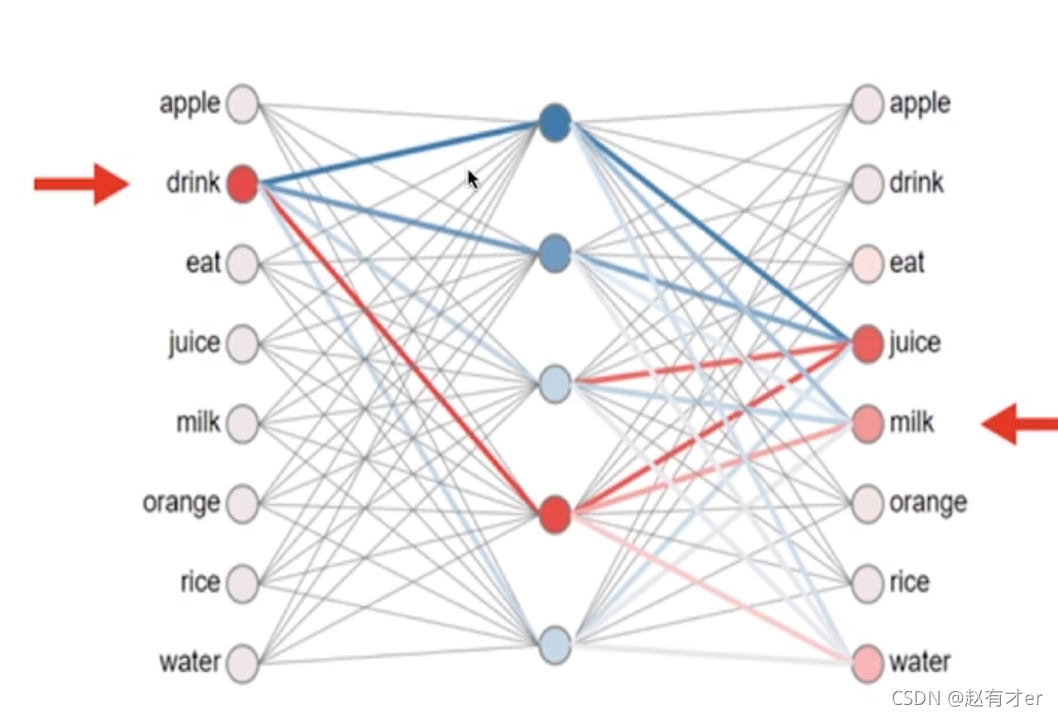
?从上图的示例中可以看到:输入是中心词(或者是邻居词),输出是邻居词(或者中心词)。神经网络中间有一个隐藏层,他的神经元个数要显著小于词的个数(一般就只有几百个),通过预测模型的训练学习,我们会得到网络的连接权重,例如”drink“这个词会和隐藏层的所有神经元都有连接权重,依据这个权重就可以得到drink这个词的词向量,向量的长度就是隐藏层的神经元个数,向量的数值就是神经元之间的连接权重。再看图的右边,与drink连接权重较高的神经元,他的右边又连接了一些词,这些词可以理解为就是drink的邻居词,例如juice,milk之类的词。
词向量只是对词的特征表征,如果要对一篇文档进行特征表征,有以下几种方法
・直接使用文档中所有词的词向量的平均值
・使用文档中每个词的TF-IDF值做为权重,与每个词的词向量进行加权平均
・根据文档中每个词的词向量对文档进行聚类,使用聚类后包含词最多的那个类的中心点作为文档特征向量
・使用doc2vec模型,这是个类似word2vec的模型,不过他是直接对doc来建模
以下为训练word2vec的代码及一些参数的讲解
创建输出目录 用来保存训练好的词向量
output_dir='output_word2vec'
import os
if not os.path.exists(output_dir):
os.mkdir(output_dir)导入数据
import numpy as np
import pandas as pd
?查看训练数据
train_data=pd.read_csv('sohu_train.txt',sep='\t',header=None,dtype=np.str_,encoding='utf8',names=['频道','文章'])
train_data.info()・输出结果
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 12000 entries, 0 to 11999
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 频道 12000 non-null object
1 文章 12000 non-null object
dtypes: object(2)
memory usage: 187.6+ KB载入停用词
stopwords = set()
with open('stopwords.txt', 'r',encoding='utf8') as infile:
for line in infile:
line = line.rstrip('\n')
if line:
stopwords.add(line.lower())分词
import jieba
article_words=[]
# 遍历每篇文章
for article in train_data[u'文章']:
curr_words=[]
# 遍历文章中的每个词
for word in jieba.cut(article):
# 去除停用词
if word not in stopwords:
curr_words.append(word)
article_words.append(curr_words)・输出结果
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\10248\AppData\Local\Temp\jieba.cache
Loading model cost 0.530 seconds.
Prefix dict has been built successfully.分词结果存储到文件
seg_word_file=os.path.join(output_dir,'seg_words.txt')
with open(seg_word_file,'wb') as outfile:
for words in article_words:
outfile.write(u' '.join(words).encode('utf8') + b'\n')
print('分词结果保存到文件:{}'.format(seg_word_file))・输出结果
分词结果保存到文件:output_word2vec\seg_words.txt预训练word2vec模型
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
from gensim.models import KeyedVectors创建一个句子迭代器,一行为一个句子,词和词之间用空格分开
这里我们把一篇文章当作一个句子
sentences=LineSentence(seg_word_file)预训练word2vec模型
参数说明:
?sentences: 包含句子的list,或迭代器
size: 词向量的维数,size越大需要越多的训练数据,同时能得到更好的模型
alpha: 初始学习速率,随着训练过程递减,最后降到 min_alpha
window: 上下文窗口大小,即预测当前这个词的时候最多使用距离为window大小的词
max_vocab_size: 词表大小,如果实际词的数量超过了这个值,过滤那些频率低的
workers: 并行度
iter: 训练轮数
min_count: 忽略出现次数小于该值的词
model=Word2Vec(sentences=sentences,min_count=20)保存模型
model_file = os.path.join(output_dir, 'model.w2v')
model.save(model_file)测试预训练模型
读取模型
model_file = os.path.join(output_dir, 'model.w2v')
model2=Word2Vec.load(model_file)查找语义相近的词
def invest_similar(*args,**kwargs):
res=model2.wv.most_similar(*args,**kwargs)
print('\n'.join(['{}:{}'.format(x[0],x[1]) for x in res]))
invest_similar(u'摄影', topn=5)・输出结果
刘晓科:0.7663402557373047
刘建东:0.7626208066940308
评语:0.7005037069320679
作曲:0.6986984014511108
璇:0.67718505859375女人 + 先生 - 男人 = 女士
先生 - 女士 = 男人 - 女人,这个向量的方向就代表了性别!?
invest_similar(positive=[u'女人', u'先生'], negative=[u'男人'], topn=1)・输出结果
蔡:0.6899486184120178计算两个词的相似度
model2.wv.similarity('摄影','摄像')・输出结果
0.6245521查询某个词的词向量
model2.wv[u'摄影'].shape・输出结果
(100,)model2.wv[u'摄影']・输出结果
array([ 1.12402821e+00, -1.43426090e-01, 1.27216709e+00, -1.03221321e+00,
-1.87992001e+00, 5.13237119e-01, -1.13613218e-01, 4.65803176e-01,
2.23834977e-01, -5.68113267e-01, -1.13676023e+00, 6.05148017e-01,
1.92878091e+00, 1.35197982e-01, 4.71386909e-01, 3.13203558e-02,
-4.88490194e-01, -5.21153510e-01, -3.16076130e-01, -4.14293671e+00,
-1.09550381e+00, 2.31205606e+00, 3.80034757e+00, -8.64517391e-01,
8.61354887e-01, -4.89337295e-01, -3.63620043e-01, 2.25580406e+00,
-9.07084405e-01, 7.68696427e-01, 8.44246987e-03, -4.67379779e-01,
2.23277569e+00, -1.60536277e+00, -1.76252687e+00, 2.04124570e+00,
-5.92672646e-01, -1.79212022e+00, -8.45354021e-01, 1.63020134e-01,
-4.94004756e-01, 7.84639716e-02, 2.46292621e-01, 3.91405135e-01,
2.69702244e+00, 1.12125501e-01, -3.00367903e-02, 3.96094732e-02,
-7.09702730e-01, 2.72683471e-01, 1.63493916e-01, 3.45271856e-01,
-7.32331157e-01, -1.10088050e+00, 7.25350261e-01, 1.89776182e-01,
-1.67757552e-03, -1.81457877e+00, -2.36800209e-01, 5.88630319e-01,
-1.17891036e-01, 1.70819044e+00, -2.11411715e-01, 4.82740730e-01,
2.90950954e-01, -6.00913882e-01, 6.11816823e-01, 3.15804314e-03,
-9.11727548e-01, 1.11618125e+00, 5.53577483e-01, 9.87007380e-01,
1.19754769e-01, -4.53332961e-02, 1.14017117e+00, 5.29826954e-02,
-6.54554486e-01, -1.82963490e+00, 1.63241223e-01, -6.50338531e-01,
1.28191340e+00, 1.39220166e+00, -3.26665908e-01, 7.38676339e-02,
-2.12200940e-01, 6.16843961e-02, -1.28452039e+00, -1.28339744e+00,
-1.09384215e+00, -1.32426918e+00, 1.16123927e+00, -3.39918613e-01,
1.30219662e+00, 3.30029815e-01, 1.47671258e+00, 4.75448519e-01,
6.79319859e-01, -2.00764275e+00, 8.49902809e-01, -4.79526490e-01],
dtype=float32)完整训练word2vec模型
创建输出目录
import os
output_dir = u'output_w2v'
if not os.path.exists(output_dir):
os.mkdir(output_dir)加载数据
import numpy as np
import pandas as pd查看训练数据
train_data = pd.read_csv('sohu_train.txt', sep='\t', header=None, dtype=np.str_, encoding='utf8', names=[u'频道', u'文章'])
train_data.head()载入停用词
stopwords = set()
with open('stopwords.txt', 'r',encoding='utf8') as infile:
for line in infile:
line = line.rstrip('\n')
if line:
stopwords.add(line.lower())计算每个文章的词向量
加载训练好的Word2Vec模型
需要预训练的执行结果
from gensim.models import Word2Vec
w2v = Word2Vec.load('output_word2vec/model.w2v')使用文章中所有词的平均词向量作为文章的向量
import jieba
def compute_doc_vec_single(article):
vec = np.zeros((w2v.layer1_size,), dtype=np.float32)
n = 0
for word in jieba.cut(article):
if word in w2v.wv:
vec += w2v.wv[word]#求所有词向量的和
n += 1#计算词的个数
return vec / n#求平均值
def compute_doc_vec(articles):
return np.row_stack([compute_doc_vec_single(x) for x in articles])
x = compute_doc_vec(train_data[u'文章'])训练分类器
编码目标变量
from sklearn.preprocessing import LabelEncoder
y_encoder = LabelEncoder()
y = y_encoder.fit_transform(train_data[u'频道'])划分训练测试数据
from sklearn.model_selection import train_test_split
# 根据y分层抽样,测试数据占20%
train_idx, test_idx = train_test_split(range(len(y)), test_size=0.2, stratify=y)
train_x = x[train_idx, :]
train_y = y[train_idx]
test_x = x[test_idx, :]
test_y = y[test_idx]训练逻辑回归模型
常用参数说明
penalty: 正则项类型,l1还是l2
C: 正则项惩罚系数的倒数,越大则惩罚越小
fit_intercept: 是否拟合常数项
max_iter: 最大迭代次数
multi_class: 以何种方式训练多分类模型
? ? ovr = 对每个标签训练二分类模型
? ? multinomial = 直接训练多分类模型,仅当solver={newton-cg, sag, lbfgs}时支持
solver: 用哪种方法求解,可选有{liblinear, newton-cg, sag, lbfgs}
? ? 小数据liblinear比较好,大数据量sag更快
? ? 多分类问题,liblinear只支持ovr模式,其他支持ovr和multinomial
? ? liblinear支持l1正则,其他只支持l2正则
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(multi_class='multinomial', solver='lbfgs')
model.fit(train_x, train_y)模型效果评估
from sklearn.metrics import confusion_matrix, precision_recall_fscore_support在测试集上计算模型的表现
test_y_pred = model.predict(test_x)计算混淆矩阵
pd.DataFrame(confusion_matrix(test_y, test_y_pred), columns=y_encoder.classes_, index=y_encoder.classes_)・输出结果
体育 健康 女人 娱乐 房地产 教育 文化 新闻 旅游 汽车 科技 财经
体育 184 0 2 0 0 3 1 4 6 0 0 0
健康 0 158 11 0 0 3 3 11 2 1 2 9
女人 1 5 149 13 0 0 16 4 6 2 4 0
娱乐 1 0 18 145 2 2 26 1 2 1 2 0
房地产 0 0 1 1 173 0 1 8 4 3 1 8
教育 0 2 5 1 1 169 5 9 3 0 3 2
文化 2 3 12 35 2 1 118 14 9 0 4 0
新闻 6 8 4 3 4 9 4 134 7 3 6 12
旅游 1 2 8 0 4 0 9 7 158 1 3 7
汽车 1 3 1 0 0 1 0 1 3 185 3 2
科技 0 5 3 0 2 4 1 5 2 3 162 13
财经 1 2 4 0 12 0 1 13 1 7 19 140计算各项评价指标
def eval_model(y_true, y_pred, labels):
# 计算每个分类的Precision, Recall, f1, support
p, r, f1, s = precision_recall_fscore_support(y_true, y_pred)
# 计算总体的平均Precision, Recall, f1, support
tot_p = np.average(p, weights=s)
tot_r = np.average(r, weights=s)
tot_f1 = np.average(f1, weights=s)
tot_s = np.sum(s)
res1 = pd.DataFrame({
u'Label': labels,
u'Precision': p,
u'Recall': r,
u'F1': f1,
u'Support': s
})
res2 = pd.DataFrame({
u'Label': [u'总体'],
u'Precision': [tot_p],
u'Recall': [tot_r],
u'F1': [tot_f1],
u'Support': [tot_s]
})
res2.index = [999]
res = pd.concat([res1, res2])
return res[[u'Label', u'Precision', u'Recall', u'F1', u'Support']]
eval_model(test_y, test_y_pred, y_encoder.classes_)・输出结果
0 体育 0.934010 0.92000 0.926952 200
1 健康 0.840426 0.79000 0.814433 200
2 女人 0.683486 0.74500 0.712919 200
3 娱乐 0.732323 0.72500 0.728643 200
4 房地产 0.865000 0.86500 0.865000 200
5 教育 0.880208 0.84500 0.862245 200
6 文化 0.637838 0.59000 0.612987 200
7 新闻 0.635071 0.67000 0.652068 200
8 旅游 0.778325 0.79000 0.784119 200
9 汽车 0.898058 0.92500 0.911330 200
10 科技 0.775120 0.81000 0.792176 200
11 财经 0.725389 0.70000 0.712468 200
999 总体 0.782105 0.78125 0.781278 2400模型保存
# 保存模型到文件
import dill
import pickle
model_file = os.path.join(output_dir, u'model.pkl')
with open(model_file, 'wb') as outfile:
pickle.dump({
'y_encoder': y_encoder,
'lr': model
}, outfile)对新文档预测
from gensim.models import Word2Vec
import dill
import pickle
import jieba把预测相关的逻辑封装在一个类中,使用这个类的实例来对新文档进行分类预测
class Predictor(object):
def __init__(self, w2v_model_file, lr_model_file):
self.w2v = Word2Vec.load(w2v_model_file)
with open(lr_model_file, 'rb') as infile:
self.model = pickle.load(infile)
def predict(self, articles):
x = self._compute_doc_vec(articles)
y = self.model['lr'].predict(x)
y_label = self.model['y_encoder'].inverse_transform(y)
return y_label
def _compute_doc_vec(self, articles):
return np.row_stack([compute_doc_vec_single(x) for x in articles])
def _compute_doc_vec_single(self, article):
vec = np.zeros((w2v.layer1_size,), dtype=np.float32)
n = 0
for word in jieba.cut(article):
if word in w2v:
vec += w2v[word]
n += 1
return vec / n加载新文档数据
new_data = pd.read_csv('sohu_test.txt', sep='\t', header=None, dtype=np.str_, encoding='utf8', names=[u'频道', u'文章'])
new_data.head()加载模型
predictor = Predictor('output_word2vec/model.w2v', model_file)预测前10000篇的分类
new_y_pred = predictor.predict(new_data[u'文章'][:10000])对比预测
pd.DataFrame({u'预测频道': new_y_pred, u'实际频道': new_data[u'频道'][:10000]})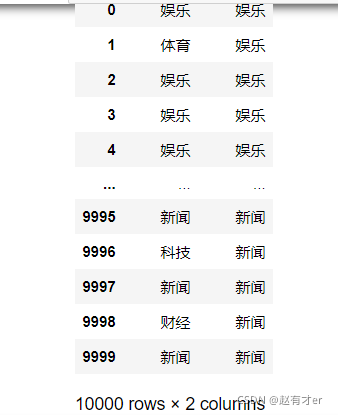
?