����Ŀ¼
����:
��ƪ�ʼ�������־����ʦд�ġ�����ѧϰ��ǰ���½��и�����,��αʼǽ���ֻ�Ǵ������Ҹ��˵Ŀ���,������д�IJ��õĵط���ϣ������ܹ�ָ��,�Ժ�������,��ȡ���������
��һ��:����
1.1��������:
������Ϊ��,�ռ���һЩ�й����ϵ����ݡ�(ɫ��=����;����=����;����=���졭��)���ǰ�ɫ��,����,������֮Ϊ����,���Ե�ȡֵ��������,����,�����֮Ϊ����ֵ�������ųɵĿռ����Ǿͳ�Ϊ:�����Կռ䡱,�������ռ䡱������ռ䡱��

��ͼ,�����һ�����Կռ䡣
һ��,��D={X1,X2,X3����,Xm}������m�����ݼ�,��ÿ�����ݼ����ܰ���d����������,Xi����dά�����ռ��е�X��һ��������,��Xij��X�ڵ�i���ϵ�j����������,d�ͳ�Ϊ����Xi��ά����
��������ѧ��ģ���̳�Ϊ��ѧϰ�����ߡ�ѵ����,�������һ����Ҫ�㷨������ʵ�֡���������Ҫһ��ģ�����ж��Ƿ���һ���ù�,��������Ҫ�õ�ѵ�������ĺܶࡰ�������Ϣ(ɫ��=�����̡�,����=��������,����=�����족,�ù�!)����Ϊ���,�û��������б���Ƿ��Ǻùϡ�
ģ��֮��,ʹ��ģ�ͽ���Ԥ��Ĺ��̳�Ϊ�����ԡ�(testing),��Ԥ���������Ϊ��������������
���Ƕ����Ͻ��С����ࡱ,����ѵ�����е����Ϸ�Ϊ������,ÿ���Ϊһ�����ء�,ÿ����ܶ�ӦһЩDZ�ڵĸ����,��:��dzɫ�ϡ�,����ɫ�ϡ���
ע��:dzɫ�Ϻ���ɫ����Щ�������DZ����Dz�֪����,��ϵͳ�Լ����ɳ�����
���Ǹ���ѵ�������Ƿ��б����Ϣ,���Է�Ϊ����:���ලѧϰ���͡��ලѧϰ��,����ͻع���ǰ�ߵĴ���,�������Ǻ��ߵĴ�����
���ǵ�Ŀ����ʹѧ�õ�ģ���ܺܺõ������ڡ���������,���������С���������������ʹֻ��һС�������ռ�,��ֻҪ�к�ǿ�ķ�������,��ȻҲ����Ӧ�����ռ�����ԡ�
1.2����ռ�:
���ɺ������ǿ�ѧ��������������ֶΡ�����������ѧϰ����Ȼ��һ������ѧϰ�Ĺ��̡�
����ѧϰ��������Dz�������ѧϰ,�����벻��,��ʾΪ0/1�IJ���ֵ�ĸ���Ŀ��ѧϰ����:
| ��� | ɫ�� | ���� | ���� | �ù� |
|---|---|---|---|---|
| 1 | ���� | ���� | ���� | �� |
| 2 | �ں� | ���� | ���� | �� |
| 3 | ���� | Ӳͦ | ��� | �� |
| 4 | �ں� | ���� | ���� | �� |
�˴�Ҫѧϰ��Ŀ���ǡ��ùϡ�,������Ҫ�жϡ�ɫ�����١������������������ء���ȷ�����Dz��Ǻù�,Ҳ����˵�ùϵȼ���(ɫ��=?) ^ (����=?) ^(����=?),���Ǿ���ͨ��ѧϰ��?��ֵ������ȷ��������
����,���ǽ����ǡ���ס������ǡ����ġ���,���������һ��δ��������,�Ǿ�������ˡ���:ɫ��=���ڡ�
���ǰ�ѧϰ�Ĺ����п�����һ���ڼ���ռ���������Ĺ���,����ƥ���ҵ���ȷ�ļ���,�����ѧϰ������ı�ʾһ��ȷ��,��ô���Ĺ�ģҲ��ȷ����,��,�˴����Ǽ���ռ���(ɫ��=?) ^ (����=?) ^(����=?)��������ȷ�������ɫ��ȡʲôֵ������,���Ǿͽ���������*������:(ɫ��= *) ^ (����=?) ^(����=?)�����������û�кù�,���Ǿ���?����ʾ������:��������ļ���ռ�
1.3����ռ�
�����ùϡ��ı��ٴ�������,��:(ɫ��=����) ^ (����=����) ^(����=����),������úùϵȼ���(ɫ��= *) ^ (����=����) ^(����= *)���ǻ�����жϳɺù�,�������������������ѡ��,��Ϊ�ùϡ���ô�ò����ĸ�ģ����?
���������Ҿٸ�����: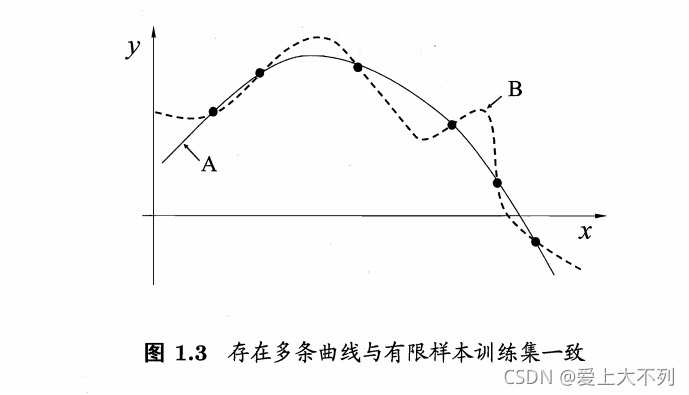
��,A,B����������,��Ϊ���Ƶ�����Ӧ�����Ƶ����,��������ΪA�DZ�B�õĹϡ���û��һ���Ե�ԭ��������ʲô�Ǻù���?��Ȼ���еİ�
���¿�ķ�굶�� ԭ�� :���ж��������۲�һ��,����ѡ������Ǹ�
A��B �Ƚ�,��Ȼ��A��
����,���¿�ķ�굶������Ψһ����ԭ��,���Լ�Ҳ����ì�ܵ�,��:(ɫ��= *) ^ (����=?) ^(����= *) �� (ɫ��= ?) ^ (����= *) ^(����= *),�������ĸ�������?��,�����ì����,����˵������Ⲣ����,���ǽ����������ơ�

������㷨,��ʾA��B������ֵ����ͬ�ġ�Ҳ����˵A��Bһ������������û����ѵ���͡����������NFL�����ˡ�(�ð�,˵ʵ��,������Ҳ��һͷ��ˮ,��������,ȸ���Ѱ�,����Х��!!#��ͷ����)
�ڶ���:����ģ����ѡ��
2.1�������������:
ͨ�����ǰѷ������ռ���������ı�����Ϊ�������ʡ�,���m����������a������,��ô������ E= a/m,���� = 1-E.ѧϰ����ѵ�����ϵ�����Ϊ��ѵ�������ߡ�����������Ȼ,����ϣ������Dz���ԽСԽ����?����,�dz��ź�,��ʵ��������ԸΥ��
������ϣ����,�����������ϱ��ֵĺܺõ�ѧϰ���������ǰ�ѧϰ��ѵ����̫�õ�ʱ��,���ͻ��ѵ����������һЩ�ص㵱������DZ�����������е�һ������,���dz�֮Ϊ������ϡ�,�෴���ǡ�Ƿ��ϡ���
��ͼ:

2.2��������
ͨ��,���ǿ�ͨ��ʵ���������ѧϰ���ķ�������������������ѡ��Ϊ��,������Ҫ�����Լ�������������,��������Ҳ��Ҫ��ѵ����������ѧϰ����ѵ��,Ҫע����Dz�������������Ҫ��ѵ�����г��֡�
������ֻ��һ������m�����������ݼ� D={(x1,y1),(x2,y2)����(Xm,Ym)}��Ҫѵ��,��Ҫ����ʱ,���Ǿ���������Ǻ�?�����м��ֳ����ķ���:
2.2.1������
�������ǽ�����D����Ϊ��������ļ���,ѵ����S����Լ�T,�� D = S��T,S��T=?��
����D ����1000������,S=700,T=300,Sѵ��֮��,T����90������,������E = 90 / 300 = 30%��������Ϊ70%��
���Ǵ˴���һ����:����S���������������,��ôT�ͽ���,���ԵĽ�����ܲ���ȷ����T�������������,��Sѵ���Ĺ���,��������ģ����D�нϴ�IJ��,������õ������ǽ���Լ2 / 3 ���� 4/5����������ѵ��,������ԡ�
2.2.2������֤��
��������֤���������ݷ�Ϊk����С���ƵĻ����Ӽ�,��D = D1��D2��D3������Dk,Di��Dj = ?����k���Ӽ���Ϊѵ����,���µ���Ϊ���Լ���
��ͼ:
�ٶ����ݼ�D����m������,��k=m,��õ��˽�����֤��������:��һ�����ɼ�,��һ����������������ֵ�Ӱ��,������һ���ı�Ҳ�Զ�����,�Ǿ���̫��Ǯ��,�����ء������ݰ���100w��ģ��,����Ҫѵ��100��w(��ȱw��?ˮ̫��,����ղ�ס,����������� #��ͷ)��
2.2.3������
����������������Ϊ����,��D��m������,���Dz�������ΪD��,�����һ������D����,�ڽ������D�С������ظ�ִ��m�Ρ���ȻD������һ���ֻ���D���г���,��һ�����ᡣ����m�β����в����ĸ���Ϊ(1-1/m)^m,ȡ����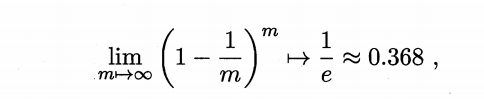
Ҳ����˵������0.368�����ݲ��ᱻ�ɵ���
���������������ݼ���С,���ݼ��ϴ���ʹ���������ͽ�����֤����
2.2.4����������ģ��
������㷨���в�����Ҫ�趨,���ò�ͬ,ѧ�õ�ģ�����ܾͻ��в��졣���������Ҫ��������,����:�����Ρ���
����[0,0.2]�Ĺ�������0.05Ϊ����,��ʵ����5������,��5����ѡ������ֵ������,����ͨ����ѧ�õ�ģ����ʵ��ʹ�������������ݳ�Ϊ���������ݡ�,Ϊ������,ģ��������ѡ���������������Ե����ݼ�����Ϊ����֤������
2.3���ܶ���
��ѧϰ���ķ������ܽ�������,����Ҫ��ʵ����Ʒ���,ҲҪ�к�������ģ�͵����۱�,��������ܶ�����
��Ԥ��������, D={(x1,y1),(x2,y2)����(Xm,Ym)}����,Yi��Xi����ʵ��ǡ�
������õ��Ǿ�����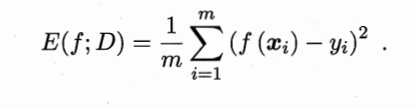
����,�������ݷֲ�D�����ܶȺ���p,�����������Ϊ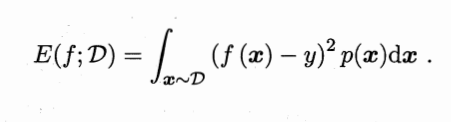
����Ϊ���ܷ��������г��õ����ܶ���
2.3.1�������뾫��
�����ʵĶ���Ϊ: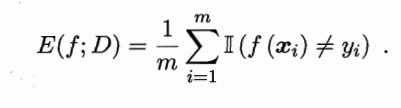
��������Ϊ: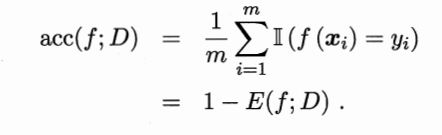
�������ݷֲ�D�����ܶȺ���p,�������뾫������Ϊ:
2.3.2���ʡ���ȫ����F1
�������뾫���䳣��,�����������������⡣��Ҫ�������ܶ�����
�Զ���������,�ɻ���Ϊ,������,������,�淴��,�ٷ�����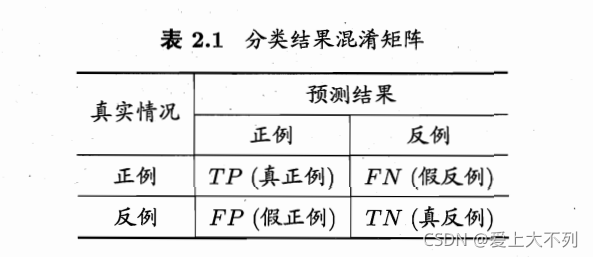
����P���ȫ��R�Ķ���Ϊ: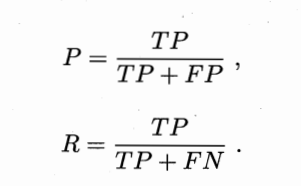
�������ȫ��һ����ì�ܱ���,��ǰ�߸�ʱ,������Ȼ�͡�
�ܶ������,���ǻ��Ѳ��ʺͲ�ȫ�ʽ���������,��P-R���ߡ�
��ͼ: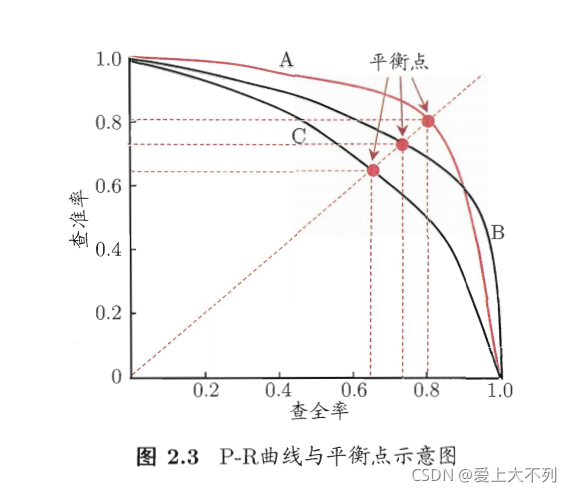
ƽ����������ۺϿ��Dz���,��ȫ�ʵ�һ�����ܶ���,���BEP��
����BEP���Ǵ����,һ�㶼��F1������(F1=(B+R)/2)