这个例子展示了如何使用深度学习过程对声音进行分类。
1、数据集生成
生成1000个白噪声信号、1000个棕色噪声信号和1000个粉色噪声信号。假设采样率为44.1 kHz,每个信号表示0.5秒的持续时间。
fs = 44.1e3;duration = 0.5;N = duration*fs;wNoise = 2*rand([N,1000]) - 1;wLabels = repelem(categorical("white"),1000,1);bNoise = filter(1,[1,-0.999],wNoise);bNoise = bNoise./max(abs(bNoise),[],'all');bLabels = repelem(categorical("brown"),1000,1);pNoise = pinknoise([N,1000]);pLabels = repelem(categorical("pink"),1000,1);
2、数据可视化
听声音信号,并使用melSpectrogram函数将其可视化。
sound(wNoise(:,1),fs)melSpectrogram(wNoise(:,1),fs)title('White Noise')
![]()
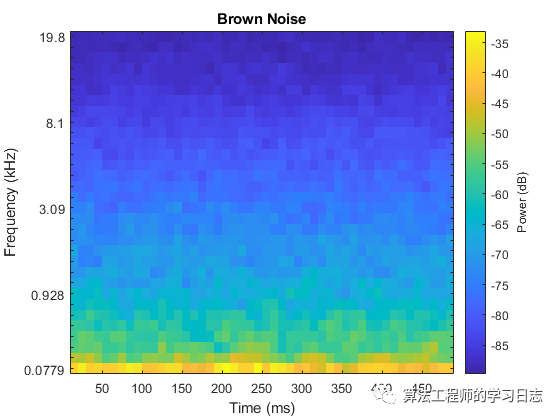
sound(bNoise(:,1),fs)melSpectrogram(bNoise(:,1),fs)title('Brown Noise')
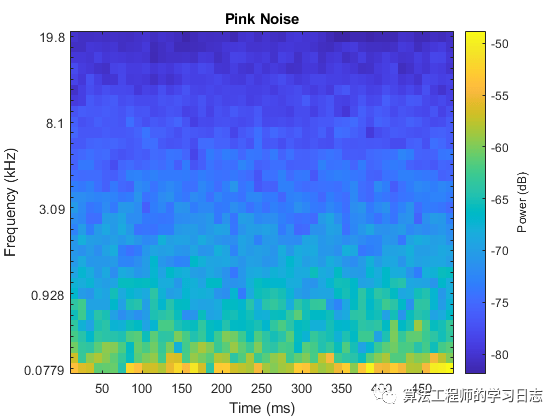
sound(pNoise(:,1),fs)melSpectrogram(pNoise(:,1),fs)title('Pink Noise')
3、将数据集分为训练集和验证集
创建一个由800个白噪声信号、800个棕色噪声信号和800个粉色噪声信号组成的训练集。
audioTrain = [wNoise(:,1:800),bNoise(:,1:800),pNoise(:,1:800)];labelsTrain = [wLabels(1:800);bLabels(1:800);pLabels(1:800)];
使用剩余的200个白噪声信号、200个棕色噪声信号和200个粉色噪声信号创建验证集。
audioValidation = [wNoise(:,801:end),bNoise(:,801:end),pNoise(:,801:end)];labelsValidation = [wLabels(801:end);bLabels(801:end);pLabels(801:end)];
4、信号提取
音频数据是高维的,通常包含冗余信息。通过首先提取特征,然后使用提取的特征训练模型,可以降低维数。创建audioFeatureExtractor对象以提取mel光谱随时间变化的质心和斜率。
aFE = audioFeatureExtractor("SampleRate",fs, ..."SpectralDescriptorInput","melSpectrum", ..."spectralCentroid",true, ..."spectralSlope",true);
调用extract从音频训练数据中提取特征。
featuresTrain = extract(aFE,audioTrain);[numHopsPerSequence,numFeatures,numSignals] = size(featuresTrain)
5、数据准备
在下一步中,您将把提取的特征视为序列,并使用sequenceInputLayer作为深度学习模型的第一层。当使用SequenceInputLayers作为网络中的第一层时,trainNetwork希望将训练和验证数据格式化为序列的单元数组,其中每个序列随时间由特征向量组成。sequenceInputLayer要求时间维度沿第二维度。
featuresTrain = permute(featuresTrain,[2,1,3]);featuresTrain = squeeze(num2cell(featuresTrain,[1,2]));numSignals = numel(featuresTrain)numSignals = 2400[numFeatures,numHopsPerSequence] = size(featuresTrain{1})numFeatures = 2numHopsPerSequence = 42
提取特征
featuresValidation = extract(aFE,audioValidation);featuresValidation = permute(featuresValidation,[2,1,3]);featuresValidation = squeeze(num2cell(featuresValidation,[1,2]));
6、定义和训练网络
定义网络架构。
layers = [ ...sequenceInputLayer(numFeatures)lstmLayer(50,"OutputMode","last")fullyConnectedLayer(numel(unique(labelsTrain)))softmaxLayerclassificationLayer];
要定义train选项,请使用option选项(深度学习工具箱)。
options = trainingOptions("adam", ..."Shuffle","every-epoch", ..."ValidationData",{featuresValidation,labelsValidation}, ..."Plots","training-progress", ..."Verbose",false);
要训练网络,请使用trainNetwork(深度学习工具箱)。
net = trainNetwork(featuresTrain,labelsTrain,layers,options);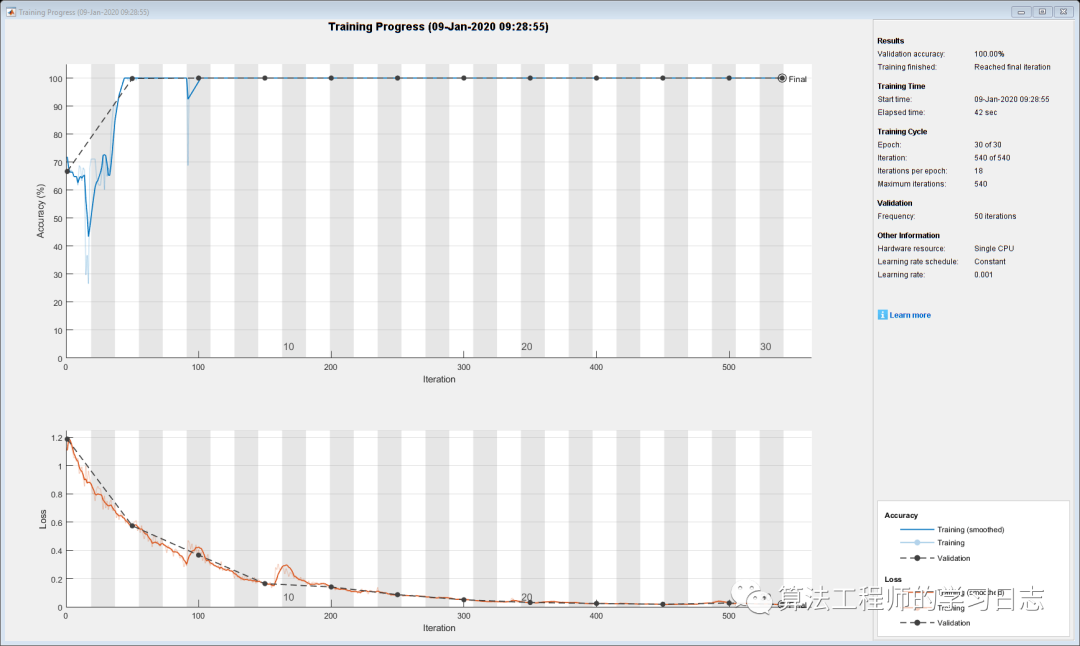
7、验证网络
使用经过训练的网络对新的白噪声、棕色噪声和粉色噪声信号进行分类。
wNoiseTest = 2*rand([N,1]) - 1;classify(net,extract(aFE,wNoiseTest)')ans = categoricalwhitebNoiseTest = filter(1,[1,-0.999],wNoiseTest);bNoiseTest= bNoiseTest./max(abs(bNoiseTest),[],'all');classify(net,extract(aFE,bNoiseTest)')ans = categoricalbrownpNoiseTest = pinknoise(N);classify(net,extract(aFE,pNoiseTest)')ans = categoricalpink

?