�����Ķ��ʼ�:Masked Autoencoders Are Scalable Vision Learners
arXiv:2111.06377v1
Author: Kaiming He; Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollar, Ross Girshick
ժҪ
����֤����,��CV������,Masked Autoencoders(MAE)��һ��scalable���Լලѧϰ����
MAE�����ܼ�:�������mask������ͼ���patches���ؽ��ⲿ�ֶ�ʧ�����ء�
����������������ơ�����,���ǿ�����һ���ǶԳ���encoder-decoder�ṹ,����,encoder���ڿɼ���(��û�б�mask��)patches�Ӽ�������,ͬʱ����һ��������decoder,���ڴ�DZ�ڱ�ʾ��masked tokens�ؽ�ԭʼͼ�����,���Ƿ��ָ߱���mask������ͼ��(��75%)�����һ���ƽ��������������Լල������������ƵĽ��ʹ�����ܹ���Ч��ѵ������ģ��:���Ǽӿ�ѵ���ٶ�(3�������)�����ȷ�ԡ����ǵĿ���չ��������ѧϰ��������ͨ���Եĸ�����ģ��:����,�ڽ�ʹ��ImageNet-1K���ݵķ�����,vanilla ViT����ģ�͵ľ�ȷ�����(87.8%)�����������е�Ǩ�����������мල��Ԥѵ��,�������õ�scaling��

����
����GPT���Իع����Խ�ģ��BERT�е�Masked Autoencoders�Ľ�������ڸ����Ϻܼ�:����ɾ���������ݲ�ѧϰԤ��ɾ�������ݡ���Щ�������ڿ���ѵ����������1000�ڸ������Ŀ��ƹ�NLPģ�͡�
Masked Autoencoders��һ�ָ�һ���ȥ�뷽ʽ,�����뷨����Ȼ,Ҳ�����ڼ�����Ӿ�����ʵ��,���Ӿ�������ص��о�[49,39]����BERT��Ȼ��,��������BERT�ijɹ�,���Ƕ���һ�뷨�����˼������Ȥ,���Ӿ����Զ����뷽���Ľ�չȴ�����NLP��������:��ʲô��Masked Autoencoders���Ӿ�������֮��������ͬ?������ͼ�����½ǶȻش��������:
- ֱ�����,�ܹ����Dz�ͬ�ġ����Ӿ���,���������ڹ�ȥʮ����ռ������λ������ͨ���ڹ�������������,����ָʾ������masked token��positional embedding���ɵ����������в������ס�Ȼ��,����ViT������,��һ��ϵ�ṹ����Ѿ��õ��˽��,���Ҳ�����һ���ϰ���
- ���Ժ��Ӿ�����Ϣ�ܶ��Dz�ͬ�ġ�����������������ź�,���и߶ȵ��������Ϣ�ܶȡ���ѵ��һ��ģ����Ԥ��ÿ��������ֻ�м�����©�ĵ���ʱ,��������ƺ��ᵼ�¸��ӵ��������⡣�෴,ͼ���Ǿ��и߶ȿռ��������Ȼ�ź�,����,ȱʧ��patches���Դ�����patches�����¸���,���Ծֲ�������ͳ����ĸ߲��������١�Ϊ�˿˷����ֲ��첢����ѧϰ���õ�����,����չʾ��һ�ּIJ����ڼ�����Ӿ��к���Ч:���mask��patches����һ���Դ�����������,��������һ��������ս�Ե����Ҽල����,��Ҫ�Եͼ�ͼ��ͳ��֮�������������

- AE��decoder��DZ�ڱ�ʾӳ�������,���ؽ��ı���ͼ��֮�����Ų�ͬ�����á����Ӿ���,�������ؽ�����,�������������弶�������ͨʶ���������������෴,��������,������Ԥ������ḻ������Ϣ��ȱʧ���ʡ���Ȼ��BERT��,decoder�������������(��һ��MLP),�����Ƿ���,����ͼ��,decoder�������ȷ��ѧϰ����DZ�ڱ�ʾ������ˮƽ�������Źؼ����á�
��������������ƶ���,���������һ�ּ���Ч������չ��MAE,�����Ӿ�����ѧϰ�����ǵ�MAE������ͼ�������mask tokens,�������ؿռ����ؽ���Щtokens������һ���ǶԳƵı��������ơ����ǵı�����ֻ�ڿɼ���patches�Ӽ�������,���ǵĽ���������������,����DZ�ڱ�ʾ��������masked tokensһ���ؽ�(ͼ1)�������ǵķǶԳƱ�����-��������,��masked tokensת�Ƶ�С�ͽ�����������ټ������������������,�dz��ߵ�mask��(��75%)����ʵ��˫Ӯ:���Ż��˾���,ͬʱ�����˱�����������,ʹ�������һС����(��25%)����������Խ�����Ԥѵ��ʱ�����3�������,ͬ�����Լ����ڴ�����,ʹ�����ܹ����ɵؽ�MAE��չ������ģ�͡�
ʵ��
���ǵ�MAE��һ�ּ��Զ����뷽��,������ԭʼ�źŵ��ٲ��ֹ۲�ֵ�ؽ�ԭʼ�źš������е��Զ�������һ��,���ǵķ�����һ�����������۲쵽���ź�ӳ�䵽DZ�ڱ�ʾ,����һ����������DZ�ڱ�ʾ�ع�ԭʼ�źš��뾭����Զ���������ͬ,���Dz�����һ�ַǶԳ����,�������������Բ��ֹ۲��ź�(��������)���в���,������һ��������������,��DZ�ڱ�ʾ�����������¹��������źš�ͼ1˵����������ܵ��뷨��
MASKING
����ViT[16],���ǽ�ͼ��Ϊ����ķ��ص���patches��Ȼ��,���Ƕ�һ���Ӽ���patches���в���,��MASK(���Ƴ�)ʣ�����Ƭ�����ǵIJ������Ժܼ�:�����ڲ��滻�������,���վ��ȷֲ������patches���в��������Ǽس�֮Ϊ�������������
���и��ڱ��ʵ���������ںܴ�̶�������������,��˲�����һ����ͨ���ӿɼ�������Ƭ���������ɽ�������������ȷֲ��ɷ�ֹDZ�ڵ�����ƫ��(��,ͼ�����ĸ�����mask����)�����,�߶�ϡ�������Ϊ��Ƹ�Ч�����������˻��ᡣ
MAE������
���ǵı�����ʹ��ViT,���������ڿɼ��ġ�û��mask��patches�������ڱ�ViT��һ��,���ǵı�����ͨ������positional embeddings��Linear Projection���õ�embedded patches,Ȼ��ͨ��һϵ��transformer block�����������Ȼ��,���ǵı�����ֻ���������ϵ�һС���������С�**ȥ��masked patches;��ʹ��mask tokens��(Ҳ����˵ֱ��ȥ�����������ֵ)**��ʹ�����ܹ�ѵ���dz���ı�����,ֻ��Ҫ������ڴ��һ���֡�֮��,����������������������������
MAE������
MAE����������������:(i)����encoder����Ŀɼ�patches;(ii)masked tokens,��ͼ1��ÿ��masked tokens����һ��������ѧϰ����,��ʾҪԤ���ȱʧpatches��������������������е�����tokens����positional embedding��������������һϵ��Transformerģ�顣
MAE����������Ԥѵ���ڼ�����ִ��ͼ���ع�����(��������������������ʶ���ͼ���ʾ)�����,�����������Զ����ڱ�������Ƶķ�ʽ������ơ�����ʹ�÷dz�С�Ľ���������ʵ��,�ȱ�������խ����dz������,����������,���ǵ�Ĭ�Ͻ�����ÿ��token�ļ�����С��10%��ͨ�����ַǶԳ����,ȫ��tokens��������������������,���������Ԥѵ��ʱ�䡣
�ع�Ŀ��
���ǵ�MAEͨ��Ԥ��ÿ��masked patches������ֵ���ع�����ֵ������������е�ÿ��Ԫ�ض��DZ�ʾpatches������ֵ�����������������һ����һ��linear projection,�����ͨ������������ÿ��patch�а���������������������������γ��ع�ͼ����ʧ�����������ؿռ����ؽ�ͼ���ԭʼͼ��֮��ľ������(MSE):ֻ���㱻mask��patches����ʧ,������BERT��
���ǻ��о���һ�ֱ���,���ؽ�Ŀ����ÿ��masked patches�Ĺ�һ������ֵ��������˵,���Ǽ���ÿ��patches���������ص�ƽ��ֵ�ͱ�ƫ��,��ʹ���������淶��patches�������ǵ�ʵ����,ʹ�ù�һ��������Ϊ�ع�Ŀ������˱�ʾ������
��ʵ��
���ǵ�MAEԤѵ�����Ա���Чʵ��,������Ҫ�κ�ר�ŵ�ϡ�軯����������,����Ϊÿ������patch����һ����Ӧtoken(����һ��positional embedding��Linear projection,����ViT����������)��������,�������shuffle��Щtoken���б�,������dropout rateɾ���б�������Dz��֡��˹���Ϊencoder����һС����(δ��mask)��token,���������������patches�������,���ǽ�masked token�б����ӵ��ѱ����patch�б���,��unshuffle�������б�,�Խ�����token����Ŀ����롣������Ӧ������������ġ�������poisitional embedding���б�����ǰ����,�ⲻ��Ҫϡ�����,�������˿ɺ��Բ��ƵĿ���,��Ϊshuffle��unshuffle�IJ����ٶȺܿ졣
�� ImageNet �ϵļ���
������ImageNet-1Kѵ�����Ͻ����ԼලԤѵ����Ȼ�������ٽ����мලѵ��,�ö˵���������������������ѧϰ����representations��
Baseline: ViT-Large
������ViT-Large/16��Ϊbackbone��������ʵ�顣ViT-L�dz���(��ResNet-50��һ��������),����������ϡ������Ǵ��㿪ʼѵ����ViT-L�����Ϊbaseline��MAE����fine-tune�õ���ViT-L֮��ıȽ�:
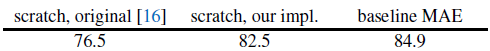
����ע�,�����е�(scatch)ѵ���мල��ViT-L��Ҫһ��ǿ����(76.5%��82.5%)����ʹ���,���ǵ�MAEԤѵ��Ҳ�кܴ�ĸĽ���������,��ʹ����50��epoch(����ͷ��ʼ��Ҫ200��),����ζ����ô�ߵ�ȷ���ںܴ�̶���ȡ����MAEԤѵ����
��Ҫ�ṹ
����ʹ�ñ�1�е����ý�������ʵ�顣�۲쵽һЩ��Ȥ�����ʡ�

Masking Ratio
ͼ5��ʾ��Masking Ratio��Ӱ�졣��ѵ�dropout rate�������ϵظ�:75%������������fine-tune���кô�������BERT�෴,BERT�еľ����dropout rateΪ15%�����ǵ�Masking RatioҲԶ���ڼ�����Ӿ���ع����е�20%��50%��

��ģ���ƶ�ȱʧ��patches�������ͬ���ƺ��������������������������ͳ����ĸ�ʽ��(gestalt),���ⲻ�ܼ�ͨ��������������������ɡ����Ǽ�������������������Ϊ��ѧϰ���õı����йء�
ͼ5����������̽����������ѭ��ͬ�����ơ���������̽��,���������ڱ��ʵ����Ӷ��ȶ�����,ֱ���ﵽ��͵�:���Ȳ��ﵽ��20%(54.6%��73.5%)��������,����Ա��ʵ����жȽϵ�,���Ҵ�Χ���ڱ���(40�C80%)�������á�ͼ5�е���������������ڴ�ͷ��ʼ��ѵ��(82.5%)��
Decoder design
���ǵ�MAE����������������,���1��a-b��ʾ��
��1a˵���㹻��Ľ������dz���Ҫ�������ͨ�������ؽ������ʶ������֮��IJ��������:AE�е�����ר�������ع�,����ʶ���ء�һ��������ȵĽ��������Ե����ع���������,ʹDZ�ڵı�ʾ���ڸ�����IJ�Ρ�������ƿ���ʹ����̽�����8%(��1a,��lin��)������,���ʹ����,�����������һ����Խ��е�������Ӧʶ������������ȶԸ�������Ӱ���С(��1a,��ft��)��
��Ȥ����,����ʹ�õ���Transformer���ɵĽ�������Ȼ��������(84.8%)ʱ���ֳ�ɫ������С�ͽ��������Խ�һ���ӿ�ѵ���ٶȡ�
�ڱ�1b��,�����о��˽���������(�ŵ���)������Ĭ��ʹ��512-d,������������̽���б������á�
�ܵ���˵,����Ĭ�ϵ�MAE���������������ġ�����8����,����Ϊ512-d(��1��Ϊ��ɫ)����ViT-L(24����,1024-d)���,����ÿ��tokenֻ��Ҫ9%��