前言
开始学习聚类算法,在菜菜老师的课件基础上进行一些标注等
一、无监督学习与聚类算法
决策树,随机森林,逻辑回归,他们虽然有着不同的功能,但却都属于“有监督学习”的一部分,即是说,模型在训练的时候,即需要特征矩阵X,也需要真实标签y。机器学习当中,还有相当一部
分算法属于“无监督学习”,无监督的算法在训练的时候只需要特征矩阵X,不需要标签。PCA降维算法就是无监督学习中的一种,聚类算法,也是无监督学习的代表算法之一。
聚类算法又叫做“无监督分类”,其目的是将数据划分成有意义或有用的组(或簇)。这种划分可以基于我们的业务需求或建模需求来完成,也可以单纯地帮助我们探索数据的自然结构和分布。比如在商业中,如果我们手头有大量的当前和潜在客户的信息,我们可以使用聚类将客户划分为若干组,以便进一步分析和开展营销活动,最有名的客户价值判断模型RFM,就常常和聚类分析共同使用。再比如,聚类可以用于降维和矢量量化(vectorquantization),可以将高维特征压缩到一列当中,常常用于图像,声音,视频等非结构化数据,可以大幅度压缩数据量。
- 聚类vs分类



二、sklearn中的聚类算法
聚类算法在sklearn中有两种表现形式,一种是类(和我们目前为止学过的分类算法以及数据预处理方法们都一样),需要实例化,训练并使用接口和属性来调用结果。另一种是函数(function),只需要输入特征矩阵和超参数,即可返回聚类的结果和各种指标。
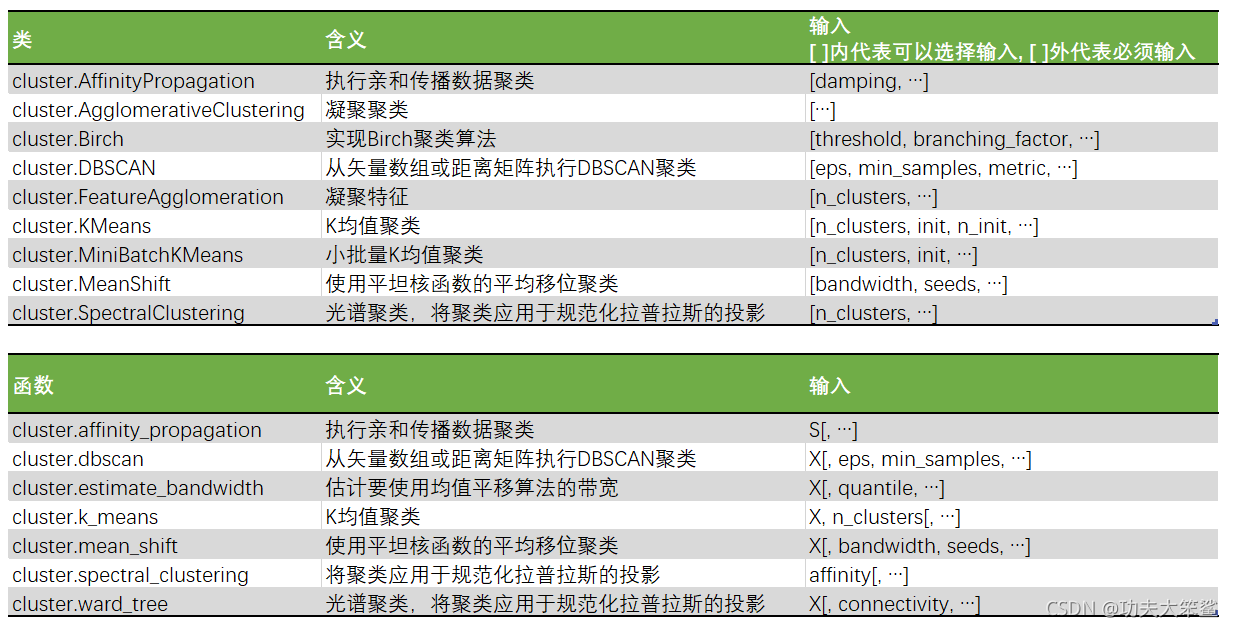
- 输入数据
需要注意的一件重要事情是,该模块中实现的算法可以采用不同类型的矩阵作为输入。 所有方法都接受形状[n_samples,n_features]的标准特征矩阵,这些可以从sklearn.feature_extraction模块中的类中获得。对于亲和力传播,光谱聚类和DBSCAN,还可以输入形状[n_samples,n_samples]的相似性矩阵,我们可以使用sklearn.metrics.pairwise模块中的函数来获取相似性矩阵。
总结
聚类算法是无监督学习